La restauración de la base de datos de configuración falla en la configuración de DR de vManage Cluster
Opciones de descarga
-
ePub (180.7 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (195.8 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Introducción
Este documento describe un problema con fallas de restauración de la base de datos de configuración en la configuración de DR del clúster vManage.
Problema
Restaure vManage NMS desde la copia de seguridad: la restauración de la base de datos de configuración falla en la configuración de DR del clúster de administración
Desde la CLI, utilice el comando request nms configuration-db restore path. Este comando restaura la base de datos de configuración del archivo buscar datapath. En este ejemplo, el destino es el vManage NMS en espera. Ejecute estos comandos en el vManage NMS en espera:
vmanage-1# request nms configuration-db restore path /home/admin/cluster-backup.tar.gz
Configuration database is running in a cluster mode
!
!
!
line omitted
!
!
!
.................... 80%
.................... 90%
.................... 100%
Backup complete.
Finished DB backup from: 30.1.1.1
Stopping NMS application server on 30.1.1.1
Stopping NMS application server on 30.1.1.2
Stopping NMS application server on 30.1.1.3
Stopping NMS configuration database on 30.1.1.1
Stopping NMS configuration database on 30.1.1.2
Stopping NMS configuration database on 30.1.1.3
Reseting NMS configuration database on 30.1.1.1
Reseting NMS configuration database on 30.1.1.2
Reseting NMS configuration database on 30.1.1.3
Restoring from DB backup: /opt/data/backup/staging/graph.db-backup
cmd to restore db: sh /usr/bin/vconfd_script_nms_neo4jwrapper.sh restore /opt/data/backup/staging/graph.db-backup
Successfully restored DB backup: /opt/data/backup/staging/graph.db-backup
Starting NMS configuration database on 30.1.1.1
Waiting for 10s before starting other instances...
Starting NMS configuration database on 30.1.1.2
Waiting for 120s for the instance to start...
NMS configuration database on 30.1.1.2 has started.
Starting NMS configuration database on 30.1.1.3
Waiting for 120s for the instance to start...
NMS configuration database on 30.1.1.3 has started.
NMS configuration database on 30.1.1.1 has started.
Updating DB with the saved cluster configuration data
Successfully reinserted cluster meta information
Starting NMS application-server on 30.1.1.1
Waiting for 120s for the instance to start...
Starting NMS application-server on 30.1.1.2
Waiting for 120s for the instance to start...
Starting NMS application-server on 30.1.1.3
Waiting for 120s for the instance to start...
Removed old database directory: /opt/data/backup/local/graph.db-backup
Successfully restored database
vmanage-1#
Paso 1. Config-db debe restaurarse con esos registros, pero hay un escenario en el que el respaldo config_db falla con estos mensajes de error.
vmanage-1# request nms configuration-db restore path /home/admin/cluster-backup.tar.gz
Configuration database is running in a cluster mode
!
!
line ommited
!
!
2020-08-09 17:13:48.758+0800 INFO [o.n.k.i.s.f.RecordFormatSelector] Selected RecordFormat:StandardV3_2[v0.A.8] record format from store /opt/data/backup/local/graph.db-backup
2020-08-09 17:13:48.759+0800 INFO [o.n.k.i.s.f.RecordFormatSelector] Format not configured. Selected format from the store: RecordFormat:StandardV3_2[v0.A.8]
.................... 10%
.................... 20%
.................... 30%
.................... 40%
.................... 50%
.................... 60%
.................... 70%
...............Checking node and relationship counts
.................... 10%
.................... 20%
.................... 30%
.................... 40%
.................... 50%
.................... 60%
.................... 70%
.................... 80%
.................... 90%
.................... 100% Backup complete.
Finished DB backup from: 30.1.1.1
Stopping NMS application server on 30.1.1.1
Stopping NMS application server on 30.1.1.2
Could not stop NMS application-server on 30.1.1.2
Failed to restore the database
Paso 2. En la falla mencionada, escenario En la página administración del clúster en vmanage, navegue hasta Administrador > Administración del clúster > Seleccionar control de vecino (...) > Editar

Mientras se edita el vManage en la administración del clúster, el error recibido es: "Error al obtener una lista de ips configurados - Error de autenticación"'
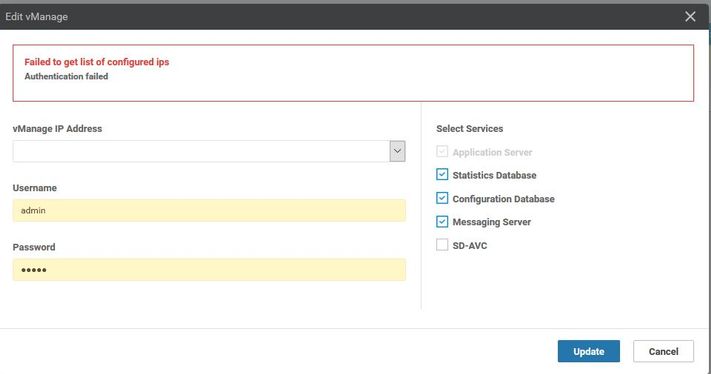
Solución
Durante la operación de restauración de config-db en un clúster vManage, es necesario iniciar/detener servicios en los nodos remotos. Esto se realiza mediante solicitudes Netconf realizadas al nodo remoto del clúster.
Si la conexión de control está presente entre los administradores del clúster, entonces vmanage intenta autenticar el nodo remoto con la clave pública del nodo remoto para autenticar la solicitud de Netconf, que es similar a controlar las conexiones entre los dispositivos. Si no está allí, vuelve a las credenciales almacenadas en la tabla de base de datos que se utilizó para formar el clúster.
El problema que hemos encontrado es que la contraseña obtuvo cambios a través de CLI, sin embargo la contraseña de administración del clúster en la base de datos no se actualizó. Por lo tanto, cada vez que cambiamos la contraseña de la cuenta netadmin que se utiliza para crear el clúster inicialmente, necesita actualizar la contraseña con la ayuda de la operación editar de administración del clúster también. Estos son los pasos adicionales que debe seguir.
- Inicie sesión en cada interfaz gráfica de usuario de administración.
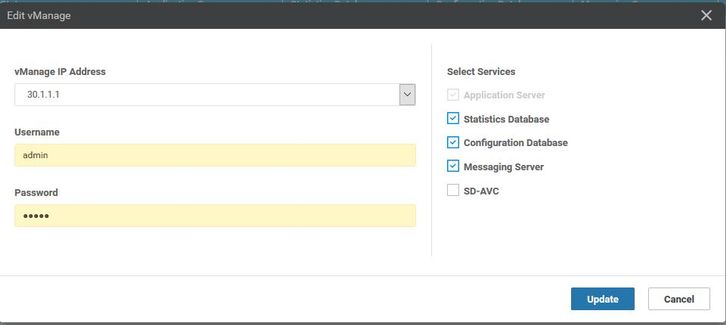
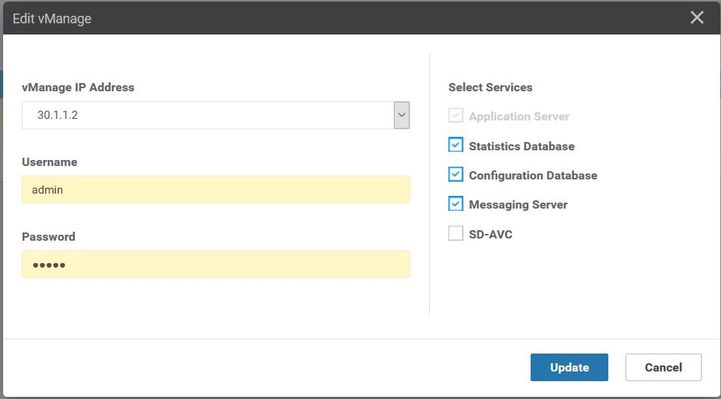
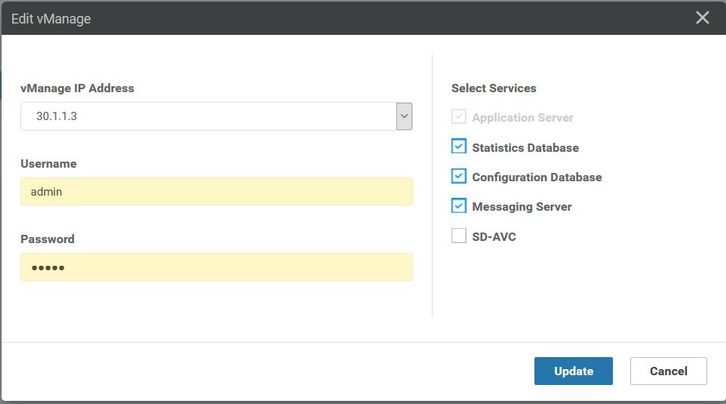
- Navegue hasta Administrador > Administración de clústeres > Seleccione los respectivos vManage (...) > Editar , como se muestra en la imagen.
- Actualizar contraseña equivalente a CLI.
- vManage1 30.1.1.1
- vManage 30.1.1.2
- vManage3 30.1.1.3
Nota: La devolución de la contraseña desde CLI no es factible en este escenario desde la CLI.
Práctica recomendada
La mejor práctica para cambiar la contraseña de vManage en el clúster es navegar a Administrator > Manage users > update password.
Este procedimiento actualiza la contraseña en los 3 vManages del clúster, así como la contraseña de administración del clúster.
Información Relacionada
- https://www.cisco.com/c/en/us/td/docs/routers/sdwan/configuration/sdwan-xe-gs-book/manage-cluster.html
- https://www.cisco.com/c/dam/en/us/td/docs/routers/sdwan/knowledge-base/disaster_recovery_technote.pdf
- https://www.cisco.com/c/dam/en/us/solutions/collateral/enterprise-networks/sd-wan/white-paper-c11-741440.pdf
Con la colaboración de ingenieros de Cisco
- Vijeth KumarCisco TAC Engineer
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)