Campus ATM Switch로 LFI(Link Fragmentation and Interleaving) 구성
다운로드 옵션
편견 없는 언어
본 제품에 대한 문서 세트는 편견 없는 언어를 사용하기 위해 노력합니다. 본 설명서 세트의 목적상, 편견 없는 언어는 나이, 장애, 성별, 인종 정체성, 민족 정체성, 성적 지향성, 사회 경제적 지위 및 교차성에 기초한 차별을 의미하지 않는 언어로 정의됩니다. 제품 소프트웨어의 사용자 인터페이스에서 하드코딩된 언어, RFP 설명서에 기초한 언어 또는 참조된 서드파티 제품에서 사용하는 언어로 인해 설명서에 예외가 있을 수 있습니다. 시스코에서 어떤 방식으로 포용적인 언어를 사용하고 있는지 자세히 알아보세요.
이 번역에 관하여
Cisco는 전 세계 사용자에게 다양한 언어로 지원 콘텐츠를 제공하기 위해 기계 번역 기술과 수작업 번역을 병행하여 이 문서를 번역했습니다. 아무리 품질이 높은 기계 번역이라도 전문 번역가의 번역 결과물만큼 정확하지는 않습니다. Cisco Systems, Inc.는 이 같은 번역에 대해 어떠한 책임도 지지 않으며 항상 원본 영문 문서(링크 제공됨)를 참조할 것을 권장합니다.
목차
소개
이 문서에서는 Frame Relay Forum(Frame Relay Forum) 또는 FRF.8 계약에 따라 정의된 IWF(Frame Relay to ATM Interworking) 연결에 대한 LFI(Link Fragmentation and Interleaving)의 기술 개요와 WAN 클라우드에서 IWF 디바이스로 LS1010 또는 Catalyst 8500을 사용하기 위한 샘플 컨피그레이션을 제공합니다. LFI는 ATM 및 Frame Relay를 통한 MLPPP(multilink point-to-point protocol) 캡슐화의 내장형 프래그먼트화 기능을 사용하여 최대 768kbps의 대역폭으로 저속 링크용 엔드 투 엔드 프래그먼트화 및 인터리빙 솔루션을 제공합니다.
사전 요구 사항
요구 사항
이 문서에서는 다음 사항을 이해해야 합니다.
-
일반적인 FRF.8 환경 및 FRF.8 투명/변환 모드 - FRF.8로 투명/변환 모드 이해를 참조하십시오.
-
LS1010 및 Catalyst 8500 구성 명령 및 Channelized E1 Frame Relay Port Adapter 또는 Channelized DS3 Frame Relay Port Adapter가 Frame Relay 엔드포인트와 ATM 엔드포인트 간의 상호 연동을 수행하는 방법에 익숙합니다.
-
직렬화 지연 및 지터. QoS(Quality of Service)(LLQ/IP RTP Priority, LFI, cRTP)가 포함된 VoIP over PPP 링크 및 QoS(Quality of Service)(프래그먼트화, 트래픽 셰이핑, IP RTP Priority)가 포함된 VoIP over Frame Relay를 참조하십시오.
사용되는 구성 요소
이 문서는 특정 소프트웨어 및 하드웨어 버전으로 한정되지 않습니다.
표기 규칙
문서 규칙에 대한 자세한 내용은 Cisco 기술 팁 표기 규칙을 참조하십시오.
MLPPP over ATM and Frame Relay를 사용해야 하는 이유
프래그먼트화는 실시간 및 비실시간 트래픽을 모두 전송하는 저속 링크에서 직렬화 지연 및 지연 변화를 제어하는 핵심 기술입니다. 직렬화 지연은 음성 또는 데이터 프레임을 네트워크 인터페이스에 클럭킹하는 데 필요한 고정 지연이며, 트렁크의 클럭 속도와 직접적으로 관련됩니다. 클록 속도가 낮고 프레임 크기가 작은 프레임을 분리하려면 추가 플래그가 필요합니다.
LFI는 MLPPP의 내장된 조각화 기능을 사용하여 비교적 작은 음성 패킷 사이에 가변 크기의 큰 패킷이 대기함으로써 발생하는 지연 및 지터(지연의 변화)를 방지합니다. LFI를 사용하면 구성된 프래그먼트 크기보다 큰 패킷이 MLPPP 헤더에 캡슐화됩니다. RFC 1990은 MLPPP 헤더와 다음을 정의합니다.
-
(B) 시작 프래그먼트 비트는 PPP 패킷에서 파생된 첫 번째 프래그먼트에 대해 1로 설정된 1비트 필드이며, 동일한 PPP 패킷에서 파생된 다른 모든 프래그먼트에 대해 0으로 설정됩니다.
-
(E)Ding fragment bit는 마지막 프래그먼트에서 1로 설정된 1비트 필드이며 다른 모든 프래그먼트에 대해 0으로 설정됩니다.
-
시퀀스 필드는 전송되는 모든 프래그먼트에 대해 증가되는 24 비트 또는 12 비트 수이다. 기본적으로 시퀀스 필드의 길이는 24비트이지만, 아래에서 설명하는 LCP 컨피그레이션 옵션을 사용하여 12비트만 되도록 협상할 수 있습니다.
프래그먼트화 외에도 지연에 민감한 패킷은 큰 패킷의 프래그먼트 간에 적절한 우선 순위에 따라 스케줄링되어야 합니다. 프래그먼트화를 사용하면 WFQ(Weighted Fair Queueing)는 패킷이 프래그먼트의 일부인지 또는 프래그먼트화되지 않았는지를 "인식"하게 됩니다. WFQ는 도착하는 각 패킷에 시퀀스 번호를 지정한 다음 이 번호를 기준으로 패킷을 예약합니다.
레이어-2 프래그먼트화는 "큰 패킷 문제"를 해결하는 데 있어 다른 모든 접근 방식에 비해 뛰어난 솔루션을 제공합니다. 다음 표에는 다른 잠재적 솔루션의 장단점이 나열되어 있습니다.
| 잠재적 솔루션 | 장점 | 단점 |
|---|---|---|
| 큰 패킷의 전송을 중단하고 지연 감지 트래픽 뒤에 다시 대기합니다. |
|
|
| 네트워크 레이어 프래그먼트화 기술을 사용하여 큰 패킷을 프래그먼트화합니다. |
|
|
| 링크 레이어 기술을 사용하여 패킷을 프래그먼트화합니다. |
|
|
MLPPPoATM(multilink point-to-point protocol over ATM)의 이상적인 프래그먼트 크기는 프래그먼트가 ATM 셀의 정확한 배수에 맞도록 해야 합니다. 프래그먼트화 값 선택에 대한 지침은 Link Fragmentation and Interleaving for Frame Relay and ATM Virtual Circuit을 참조하십시오.
MLPPPoA 및 MLPPPoFR 헤더
FRF.8의 일반적인 구성은 다음과 같습니다.
-
프레임 릴레이 엔드포인트
-
ATM 엔드포인트
-
IWF(interworking) 디바이스
각 엔드포인트는 레이어 2 캡슐화 헤더에 데이터 및 음성 패킷을 캡슐화합니다. 이 헤더는 프레임 또는 셀에서 캡슐화되어 전송되는 프로토콜을 통신합니다. Frame Relay 및 ATM은 모두 NLPID(Network Layer Protocol ID) 캡슐화 헤더를 지원합니다. ISO/IEC(International Electrotechnical Commission) TR 9577 문서는 일부 프로토콜의 잘 알려진 NLPID 값을 정의합니다. 0xCF 값이 PPP에 할당됩니다.
RFC 1973은 프레임 릴레이의 PPP 및 MLPPPoFR 헤더를 정의하는 반면, RFC 2364는 PPP over AAL5 및 MLPPPoA 헤더를 정의합니다. 두 헤더 모두 PPP를 캡슐화된 프로토콜로 식별하기 위해 NLPID 값 0xCF를 사용합니다.
이러한 각 헤더는 아래 그림 1에 나와 있습니다.
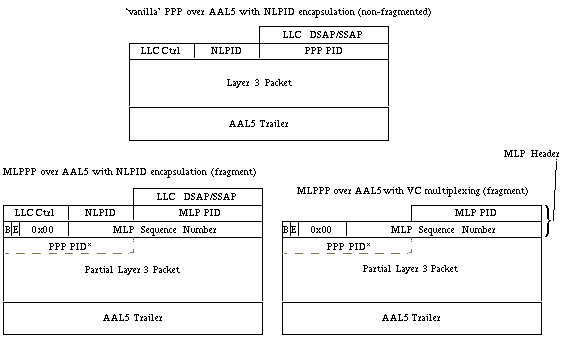
그림 1. PPP over AAL5 헤더, NLPID 캡슐화가 포함된 MLPPPoA 헤더, VC 멀티플렉싱이 포함된 MLPPPoA 헤더
참고: MLPPPoFR 헤더에는 1바이트 플래그 필드 0x7e도 포함되어 있습니다. 이는 그림 1에 표시되지 않습니다. 헤더 뒤에 바이트 번호 5가 PPP 또는 MLPPP 프로토콜 필드를 시작합니다.
표 1 - FRF.8 투명 대 FRF.8 변환

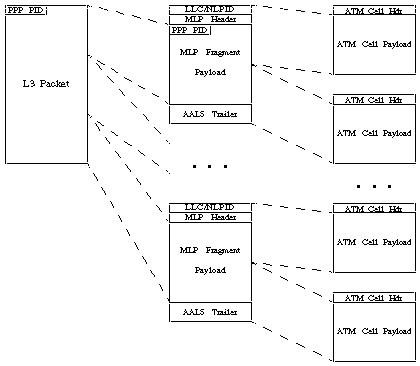
그림 2. NLPID를 사용하여 MLPPPoATM 패킷이 프래그먼트화되는 방법.
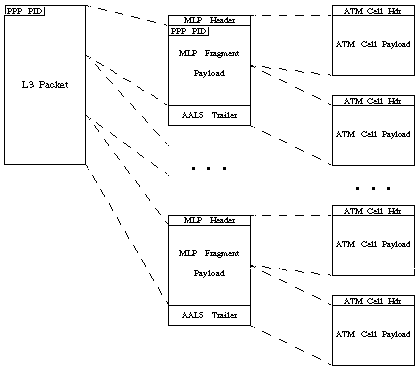
그림 3. VC 멀티플렉싱을 사용하여 MLPPPoATM 패킷이 프래그먼트화되는 방법.
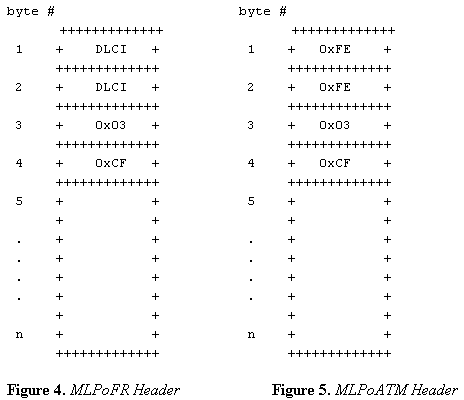
바이트 값의 의미는 다음과 같습니다.
-
0xFEFE - LLC(Logical Link Control) 헤더에서 대상 및 소스 SAP(Service Access Point)를 식별합니다. 0xFEFE 값은 다음에 오는 것이 NLPID 값이 정의된 프로토콜과 함께 사용되는 짧은 형식의 NLPID 헤더임을 나타냅니다.
-
0x03 - HDLC(High Level Data Link Control)를 비롯한 여러 캡슐화에 사용되는 제어 필드입니다. 또한 패킷의 내용이 번호가 지정되지 않은 정보로 구성됨을 나타냅니다.
-
0xCF - PPP에 대해 잘 알려진 NLPID 값입니다.
FRF.8 투명 모드 vs 변환 모드
FRF.8 계약은 IWF 장치에 대한 두 가지 운영 모드를 정의합니다.
-
Transparent(투명) - IWF 디바이스는 캡슐화 헤더를 변경하지 않고 전달합니다. 어떤 프로토콜 헤더 매핑, 단편화 또는 재조합도 수행하지 않습니다.
-
변환 - IWF 디바이스는 캡슐화 유형 간의 작은 차이를 설명하기 위해 두 캡슐화 헤더 간에 프로토콜 헤더 매핑을 수행합니다.
Cisco ATM 캠퍼스 스위치 또는 PA-A3 ATM 포트 어댑터가 있는 7200 Series 라우터일 수 있는 IWF 장치에 구성된 모드는 상호 연동 링크의 ATM 및 프레임 릴레이 세그먼트에서 레이어-2 헤더 바이트의 수를 변경합니다. 이 간접비를 좀 더 자세히 살펴보자.
다음 두 표에는 데이터 패킷 및 VoIP(Voice over IP) 패킷의 오버헤드 바이트가 나와 있습니다.
표 2 - FRF.8 링크를 통한 데이터 패킷의 데이터 링크 오버헤드(바이트)입니다.
| FRF.8 모드 | 투명 | 번역 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 트래픽 방향 | ATM에 프레임 릴레이 | ATM-프레임 릴레이 | ATM에 프레임 릴레이 | ATM-프레임 릴레이 | |||||||||
| PVC의 프레임 릴레이 또는 ATM 레그 | 프레임 릴레이 | ATM | ATM | 프레임 릴레이 | 프레임 릴레이 | ATM | ATM | 프레임 릴레이 | |||||
| 프레임 플래그(0x7e) | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | |||||
| 프레임 릴레이 헤더 | 2 | 0 | 0 | 2 | 2 | 0 | 0 | 2 | |||||
| LLC DSAP/SSAP(0xfefe) | 0 | 0 | 2 | 2 | 0 | 2 | 2 | 0 | |||||
| LLC 컨트롤(0x03) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| NLPID(PPP의 경우 0xcf) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||||
| MLP 프로토콜 ID(0x003d) | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | |||||
| MLP 시퀀스 번호 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | |||||
| PPP 프로토콜 ID(첫 번째 프래그먼트만 해당) | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | |||||
| 페이로드(레이어 3+) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |||||
| ATM Adaptation Layer (AAL)5 | 0 | 8 | 8 | 0 | 0 | 8 | 8 | 0 | |||||
| FCS(Frame Check Sequence) | 2 | 0 | 0 | 2 | 2 | 0 | 0 | 2 | |||||
| 총 오버헤드(바이트) | 15 | 18 | 20 | 17 | 15 | 20 | 20 | 15 | |||||
표 3 - FRF.8 링크를 통한 VoIP 패킷의 데이터 링크 오버헤드(바이트)입니다.
| FRF.8 모드 | 투명 | 번역 | 프레임 릴레이에서 프레임 릴레이로 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 트래픽 방향 | ATM에 프레임 릴레이 | ATM-프레임 릴레이 | ATM에 프레임 릴레이 | ATM-프레임 릴레이 | |||||
| PVC의 프레임 릴레이 또는 ATM 레그 | 프레임 릴레이 | ATM | ATM | 프레임 릴레이 | 프레임 릴레이 | ATM | ATM | 프레임 릴레이 | |
| 프레임 플래그(0x7e) | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 |
| 프레임 릴레이 헤더 | 2 | 0 | 0 | 2 | 2 | 0 | 0 | 2 | 2 |
| LLC DSAP/SSAP(0xfefe) | 0 | 0 | 2 | 2 | 0 | 2 | 2 | 0 | 0 |
| LLC 컨트롤(0x03) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| NLPID(PPP의 경우 0xcf) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| PPP ID | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 0 |
| 페이로드(IP+사용자 데이터그램 프로토콜(UDP)+RTP+음성) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AAL5 | 0 | 8 | 8 | 0 | 0 | 8 | 8 | 0 | 0 |
| FCS | 2 | 0 | 0 | 2 | 2 | 0 | 0 | 2 | 2 |
| 총 오버헤드(바이트) | 9 | 12 | 14 | 11 | 9 | 14 | 14 | 9 | 7 |
위 표를 검토할 때 다음 사항에 유의하십시오.
-
지정된 조각화 크기보다 작은 패킷은 MLPPP 헤더가 아닌 PPP 헤더에서만 캡슐화됩니다. 마찬가지로, 지정된 프래그먼트화 크기보다 큰 패킷은 PPP 헤더 및 MLPPP 헤더 모두에서 캡슐화됩니다. 따라서 VoIP 패킷은 최대 8바이트 적은 오버헤드를 갖습니다.
-
첫 번째 MLP(Multilink PPP) 프래그먼트만 PPP Protocol ID 필드를 포함합니다. 따라서, 첫 번째 조각은 두 개의 추가적인 오버헤드를 운반한다.
-
투명 모드에서 캡슐화 헤더는 IWF 디바이스를 통해 변경되지 않고 전달됩니다. 따라서 각 방향과 각 세그먼트에서 오버헤드가 달라집니다. 특히 MLPPPoA 헤더는 0xFEFE의 짧은 형식의 NLPID 헤더로 시작합니다. 투명 모드에서 이 헤더는 IWF 디바이스에 의해 ATM 세그먼트에서 프레임 릴레이 세그먼트로 변경되지 않고 전달됩니다. 그러나 Frame Relay to ATM(프레임 릴레이에서 ATM 방향)에서는 두 세그먼트 중 투명 모드에서 그러한 헤더가 존재하지 않습니다.
-
변환 모드에서 IWF 디바이스는 캡슐화 헤더를 변경합니다. 따라서 각 세그먼트에서 어느 방향으로든 오버헤드가 동일합니다. 특히 ATM-프레임 릴레이 방향에서 ATM 엔드포인트는 패킷을 MLPPPoA 헤더에 캡슐화합니다. IWF 장치는 나머지 프레임을 프레임 릴레이 세그먼트에 전달하기 전에 NLPID 헤더를 제거한다. ATM 방향으로 프레임 릴레이에서, IWF 디바이스는 프레임을 다시 조작하고, 세그먼트화된 프레임을 ATM 엔드포인트에 전달하기 전에 NLPID 헤더를 추가한다.
-
MLP로 FRF 링크를 설계할 때는 데이터 링크 오버헤드 바이트의 올바른 수를 고려해야 합니다. 이러한 오버헤드는 각 VoIP 통화에 사용되는 대역폭의 양에 영향을 줍니다. 최적의 MLP 프래그먼트 크기를 결정하는 역할도 수행한다. 특히 마지막 셀을 48바이트의 짝수 배수로 패딩하는 데 상당한 양의 대역폭이 낭비될 수 있는 저속 PVC에서는 ATM 셀의 정수 수에 맞게 프래그먼트 크기를 최적화하는 것이 중요합니다.
명확한 설명을 위해, 패킷이 투명 모드로 Frame Relay to ATM 방향으로 이동할 때 패킷 캡슐화 프로세스의 단계를 살펴보겠습니다.
-
프레임 릴레이 엔드포인트는 MLPPPoFR 헤더에 패킷을 캡슐화합니다.
-
IWF 장치는 DLCI(Data Link Connection Identifier)가 포함된 2바이트 프레임 릴레이 헤더를 제거합니다. 그런 다음 나머지 패킷을 IWF의 ATM 인터페이스로 전달합니다. 이 인터페이스는 패킷을 셀로 분할하고 ATM 세그먼트 전체에 전달합니다.
-
ATM 엔드포인트는 수신된 패킷의 헤더를 검사합니다. 수신된 패킷의 처음 2바이트가 0x03CF인 경우 ATM 엔드포인트는 패킷을 유효한 MLPPPoA 패킷으로 간주합니다.
-
ATM 엔드포인트의 MLPPP 기능은 추가 처리를 수행합니다.
패킷이 ATM에서 투명 모드의 프레임 릴레이 방향으로 이동할 때 패킷 캡슐화 프로세스를 살펴봅니다.
-
ATM 엔드포인트는 패킷을 MLPPPoA 헤더에 캡슐화합니다. 그런 다음 패킷을 셀로 분할하고 ATM 세그먼트에서 전달합니다.
-
IWF는 패킷을 수신하여 해당 Frame Relay 인터페이스에 전달하며, 2바이트 Frame Relay 헤더를 추가합니다.
-
프레임 릴레이 엔드포인트는 수신된 패킷의 헤더를 검사합니다. 2바이트 Frame Relay 헤더 뒤의 처음 4바이트가 0xfefe03cf이면 IWF는 해당 패킷을 올바른 MLPPPoFR 패킷으로 취급합니다.
-
Frame Relay 엔드포인트의 MLPPP 기능은 추가 처리를 수행합니다.
다음 그림에서는 MLPPPoA 및 MLPPPoFR 패킷의 형식을 보여 줍니다.
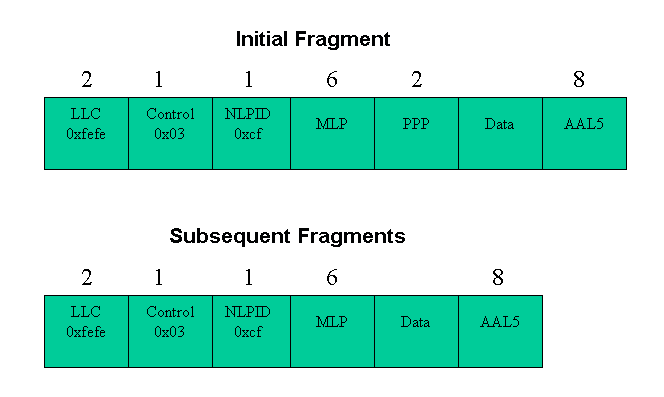
그림 6. MLPPPoA 오버헤드. 첫 번째 프래그먼트만 PPP 헤더를 전달합니다.
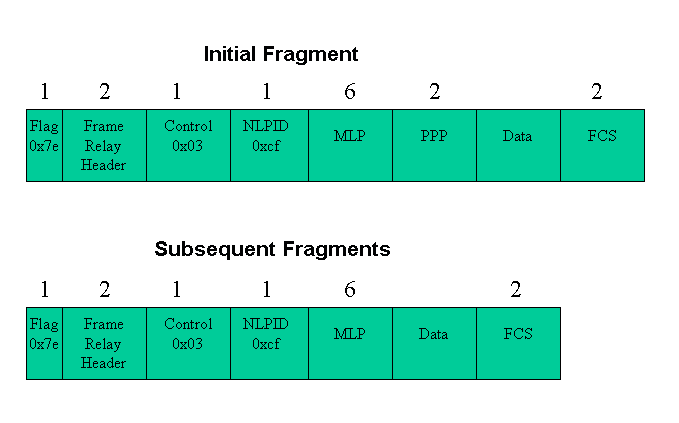
그림 7. MLPPPoFR 오버헤드. 첫 번째 프래그먼트만 PPP 헤더를 전달합니다.
VoIP 대역폭 요건
VoIP에 대한 대역폭을 프로비저닝할 때 데이터 링크 오버헤드가 대역폭 계산에 포함되어야 합니다. 표 4는 코덱 및 압축된 RTP(Real-time Transport Protocol) 사용에 따라 VoIP에 대한 통화당 대역폭 요건을 보여줍니다. 표 4의 계산에서는 cRTP(RTP 헤더 압축), 즉 UDP 체크섬이나 전송 오류가 없는 최상의 시나리오를 가정합니다. 그런 다음 헤더는 40바이트에서 2바이트로 일관되게 압축됩니다.
표 4 - VoIP당 통화 대역폭 요구 사항(kbps)
| FRF.8 모드 | 투명 | 번역 | 프레임 릴레이에서 프레임 릴레이로 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 트래픽 방향 | ATM에 프레임 릴레이 | ATM-프레임 릴레이 | ATM에 프레임 릴레이 | ATM-프레임 릴레이 | |||||
| PVC의 프레임 릴레이 또는 ATM 레그 | 프레임 릴레이 | ATM | ATM | 프레임 릴레이 | 프레임 릴레이 | ATM | ATM | 프레임 릴레이 | |
| G729 - 20ms 샘플 - cRTP 없음 | 27.6 | 42.4 | 42.4 | 28.4 | 27.6 | 42.4 | 42.4 | 27.6 | 26.8 |
| G729 - 20ms 샘플 - cRTP | 12.4 | 21.2 | 21.2 | 13.2 | 12.4 | 21.2 | 21.2 | 12.4 | 11.6 |
| G729 - 30ms 샘플 - cRTP 없음 | 20.9 | 28.0 | 28.0 | 21.4 | 20.9 | 28.0 | 28.0 | 20.9 | 20.3 |
| G729 - 30ms 샘플 - cRTP | 10.8 | 14.0 | 14.0 | 11.4 | 10.8 | 14.0 | 14.0 | 10.8 | 10.3 |
| G711 - 20ms 샘플 - cRTP 없음 | 83.6 | 106.0 | 106.0 | 84.4 | 83.6 | 106.0 | 106.0 | 83.6 | 82.8 |
| G711 - 20ms 샘플 - cRTP | 68.4 | 84.8 | 84.8 | 69.2 | 68.4 | 84.8 | 84.8 | 68.4 | 67.6 |
| G711 - 30ms 샘플 - cRTP 없음 | 76.3 | 97.9 | 97.9 | 76.8 | 76.3 | 97.9 | 97.9 | 76.3 | 75.8 |
| G711 - 30ms 샘플 - cRTP | 66.3 | 84.0 | 84.0 | 66.8 | 66.3 | 84.0 | 84.0 | 66.3 | 65.7 |
PVC의 각 레그에 따라 오버헤드가 다르므로 최악의 시나리오에 맞게 설계하는 것이 좋습니다. 예를 들어, 투명 PVC에서 20 msec 샘플링 및 cRTP를 사용하는 G.279 통화의 경우를 가정해보겠습니다. 프레임 릴레이 레그에서 대역폭 요건은 한 방향으로 12.4kbps이고 다른 방향으로 13.2kbps입니다. 따라서 통화당 3.2kbps를 기반으로 프로비저닝하는 것이 좋습니다.
비교를 위해 이 표에는 FRF.12 프래그먼트화로 구성된 엔드 투 엔드 프레임 릴레이 PVC의 VoIP 대역폭 요구 사항도 나와 있습니다. 표에 나와 있는 것처럼 PPP는 추가 캡슐화 헤더 바이트를 지원하기 위해 통화당 0.5kbps에서 0.8kbps의 추가 대역폭을 소비합니다. 따라서 엔드 투 엔드 프레임 릴레이 VC와 함께 FRF.12를 사용하는 것이 좋습니다.
ATM을 통한 압축 RTP(cRTP)에는 Cisco IOS® Software Release 12.2(2)T가 필요합니다. cRTP가 MLPoFR 및 MLPoATM에서 활성화되면 TCP/IP 헤더 압축이 자동으로 활성화되며 비활성화할 수 없습니다. 이러한 제한은 RFC 2509에서 발생하며, TCP 헤더 압축도 협상하지 않고 RTP 헤더 압축의 PPP 협상을 허용하지 않습니다.
Cisco 장치에 대한 번역 및 투명한 지원
원래 LFI는 IWF 장치가 투명 모드를 사용하도록 요구했습니다. 더 최근에는 Frame Relay Forum에서 번역 모드를 지원하기 위해 FRF.8.1을 도입했습니다. Cisco는 다음 버전의 Cisco IOS Software에서 FRF.8.1 및 변환 모드에 대한 지원을 도입했습니다.
-
4CE1 FR-PAM(CSCdt39211)이 포함된 LS1010 및 Catalyst 8500 시리즈용 12.0(18)W5(23)
-
ATM 인터페이스가 있는 Cisco IOS 라우터(예: PA-A3(CSCdt70724)의 12.2(3)T 및 12.2(2)
일부 통신 사업자는 아직 FRF.8 디바이스에서 PPP 변환을 지원하지 않습니다. 이러한 경우 제공자는 투명 모드를 위해 PVC를 구성해야 합니다.
하드웨어 및 소프트웨어
이 컨피그레이션에서는 다음 하드웨어 및 소프트웨어를 사용합니다.
-
ATM 엔드포인트 - Cisco IOS Software Release 12.2(8)T를 실행하는 7200 Series 라우터의 PA-A3-OC3. (참고: LFI는 PA-A3-OC3 및 PA-A3-T3에서만 지원됩니다. IMA 및 ATM OC-12 포트 어댑터에서는 지원되지 않습니다.
-
IWF 장치 - Channelized T3 포트 어댑터 모듈이 있는 LS1010 및 Cisco IOS Software 릴리스 12.1(8)EY.
-
Cisco IOS Software Release 12.2(8)T를 실행하는 7200 Series 라우터의 프레임 릴레이 엔드포인트 - PA-MC-T3.
토폴로지 다이어그램
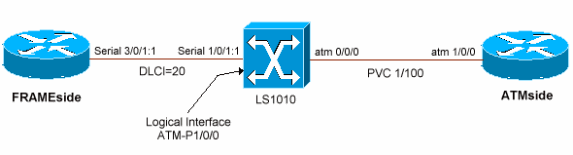
설정
이 섹션에서는 투명 모드에서 FRF.8 링크를 통해 LFI 기능을 구성하는 방법을 보여줍니다. MLP 번들의 가상 액세스 인터페이스가 복제된 두 라우터 엔드포인트에서 가상 템플릿을 사용합니다. LFI는 MLPPP의 프로토콜 레이어 매개변수를 지정하기 위해 다이얼러 인터페이스 및 가상 템플릿을 지원합니다. Cisco IOS Software 릴리스 12.2(8)T는 라우터당 구성할 수 있는 고유한 가상 템플릿의 수를 200개로 늘립니다. 이전 버전에서는 라우터당 최대 25개의 가상 템플릿만 지원합니다. 모든 PVC에 고유한 IP 주소가 필요한 경우 이 제한은 ATM 배포 라우터의 확장 문제일 수 있습니다. 이를 해결하려면 IP를 번호가 지정되지 않은 링크로 사용하거나 번호가 지정된 링크에서 가상 템플릿을 다이얼러 인터페이스로 교체합니다.
Cisco IOS Release 12.1(5)T에서는 MLPPP 번들당 하나의 멤버 링크에서만 LFI를 지원합니다. 따라서 이 컨피그레이션에서는 각 엔드포인트에서 단일 VC만 사용합니다. Cisco IOS의 향후 릴리스에서는 번들당 여러 VC를 지원할 계획입니다.
| 프레임 릴레이 엔드포인트 |
|---|
|
| LS1010 구성 |
|---|
|
| ATM 엔드포인트 |
|---|
|
show 및 debug 명령
ATM 엔드포인트
ATM 엔드포인트에서 다음 명령을 사용하여 LFI가 올바르게 작동하는지 확인합니다. debug 명령을 사용하기 전에 debug 명령에 대한 중요한 정보를 참조하십시오.
-
show ppp multilink - LFI는 두 개의 가상 액세스 인터페이스를 사용합니다. 하나는 PPP용이고, 다른 하나는 MLP 번들입니다. show ppp multilink를 사용하여 두 링크를 구별합니다.
ATMside#show ppp multilink Virtual-Access2, bundle name is FRAMEside !--- The bundle interface is assigned to VA 2. Bundle up for 01:11:55 Bundle is Distributed 0 lost fragments, 0 reordered, 0 unassigned 0 discarded, 0 lost received, 1/255 load 0x1E received sequence, 0xA sent sequence Member links: 1 (max not set, min not set) Virtual-Access1, since 01:11:55, last rcvd seq 00001D 187 weight !--- The PPP interface is assigned to VA 1. -
show interface virtual-access 1 - virtual-access 인터페이스가 가동/가동 중인지 확인하고 입력 및 출력 패킷 카운터를 늘립니다.
ATMside#show int virtual-access 1 Virtual-Access1 is up, line protocol is up Hardware is Virtual Access interface Internet address is 1.1.1.1/24 MTU 1500 bytes, BW 150 Kbit, DLY 100000 usec, reliability 255/255, txload 1/255, rxload 1/255 Encapsulation PPP, loopback not set DTR is pulsed for 5 seconds on reset LCP Open, multilink Open Bound to ATM1/0/0.1 VCD: 1, VPI: 1, VCI: 100 Cloned from virtual-template: 1 Last input 01:11:30, output never, output hang never Last clearing of "show interface" counters 2w1d Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0 Queueing strategy: fifo Output queue :0/40 (size/max) 5 minute input rate 0 bits/sec, 0 packets/sec 5 minute output rate 0 bits/sec, 0 packets/sec 878 packets input, 13094 bytes, 0 no buffer Received 0 broadcasts, 0 runts, 0 giants, 0 throttles 0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort 255073 packets output, 6624300 bytes, 0 underruns 0 output errors, 0 collisions, 0 interface resets 0 output buffer failures, 0 output buffers swapped out 0 carrier transitions -
show policy-map int virtual-access 2 - QoS 서비스 정책이 MLPPP 번들 인터페이스에 바인딩되어 있는지 확인합니다.
ATMside#show policy-map int virtual-access 2 Virtual-Access2 Service-policy output: example queue stats for all priority classes: queue size 0, queue limit 27 packets output 0, packet drops 0 tail/random drops 0, no buffer drops 0, other drops 0 Class-map: call-control (match-all) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: access-group 103 queue size 0, queue limit 3 packets output 0, packet drops 0 tail/random drops 0, no buffer drops 0, other drops 0 Bandwidth: 10%, kbps 15 Class-map: voice (match-all) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: ip rtp 16384 16383 Priority: kbps 110, burst bytes 4470, b/w exceed drops: 0 Class-map: class-default (match-any) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: any queue size 0, queue limit 5 packets output 0, packet drops 0 tail/random drops 0, no buffer drops 0, other drops 0 Fair-queue: per-flow queue limit 2 -
debug ppp packet 및 debug atm packet - 모든 인터페이스가 가동/가동 중이지만 ping을 끝까지 수행할 수 없는 경우 이 명령을 사용합니다. 또한 아래 그림과 같이 이러한 명령을 사용하여 PPP 킵얼라이브를 캡처할 수 있습니다.
2w1d: Vi1 LCP-FS: I ECHOREQ [Open] id 31 len 12 magic 0x52FE6F51 2w1d: ATM1/0/0.1(O): VCD:0x1 VPI:0x1 VCI:0x64 DM:0x0 SAP:FEFE CTL:03 Length:0x16 2w1d: CFC0 210A 1F00 0CB1 2342 E300 0532 953F 2w1d: 2w1d: Vi1 LCP-FS: O ECHOREP [Open] id 31 len 12 magic 0xB12342E3 !--- This side received an Echo Request and responded with an outbound Echo Reply. 2w1d: Vi1 LCP: O ECHOREQ [Open] id 32 len 12 magic 0xB12342E3 2w1d: ATM1/0/0.1(O): VCD:0x1 VPI:0x1 VCI:0x64 DM:0x0 SAP:FEFE CTL:03 Length:0x16 2w1d: CFC0 2109 2000 0CB1 2342 E300 049A A915 2w1d: Vi1 LCP-FS: I ECHOREP [Open] id 32 len 12 magic 0x52FE6F51 2w1d: Vi1 LCP-FS: Received id 32, sent id 32, line up !--- This side transmitted an Echo Request and received an inbound Echo Reply.
프레임 릴레이 엔드포인트
Frame Relay 엔드포인트에서 다음 명령을 사용하여 LFI가 올바르게 작동하는지 확인합니다. debug 명령을 사용하기 전에 debug 명령에 대한 중요한 정보를 참조하십시오.
-
show ppp multilink - LFI는 두 개의 가상 액세스 인터페이스를 사용합니다. 하나는 PPP용이고, 다른 하나는 MLP 번들입니다. show ppp multilink를 사용하여 두 링크를 구별합니다.
FRAMEside#show ppp multilink Virtual-Access2, bundle name is ATMside Bundle up for 01:15:16 0 lost fragments, 0 reordered, 0 unassigned 0 discarded, 0 lost received, 1/255 load 0x19 received sequence, 0x4B sent sequence Member links: 1 (max not set, min not set) Virtual-Access1, since 01:15:16, last rcvd seq 000018 59464 weight -
show policy-map interface virtual-access - QoS 서비스 정책이 MLPPP 번들 인터페이스에 바인딩되어 있는지 확인합니다.
FRAMEside#show policy-map int virtual-access 2 Virtual-Access2 Service-policy output: example Class-map: voice (match-all) 0 packets, 0 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: ip rtp 16384 16383 Weighted Fair Queueing Strict Priority Output Queue: Conversation 264 Bandwidth 110 (kbps) Burst 2750 (Bytes) (pkts matched/bytes matched) 0/0 (total drops/bytes drops) 0/0 Class-map: class-default (match-any) 27 packets, 2578 bytes 5 minute offered rate 0 bps, drop rate 0 bps Match: any Weighted Fair Queueing Flow Based Fair Queueing Maximum Number of Hashed Queues 256 (total queued/total drops/no-buffer drops) 0/0/0 -
debug frame packet 및 debug ppp packet - 모든 인터페이스가 가동/가동 중이지만 엔드 투 엔드 ping을 수행할 수 없는 경우 이 명령을 사용합니다.
FRAMEside#debug frame packet Frame Relay packet debugging is on FRAMEside# FRAMEside#ping 1.1.1.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 1.1.1.1, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 36/36/40 ms FRAMEside# 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 28 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 28 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 28 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52 2w1d: Serial3/0/1:1.1(o): dlci 20(0x441), NLPID 0x3CF(MULTILINK), datagramsize 52
큐잉 및 LFI
MLPPPoA 및 MLPPPoFR은 다이얼러 인터페이스 또는 가상 템플릿에서 2개의 가상 액세스 인터페이스를 복제합니다. 이러한 인터페이스 중 하나는 PPP 링크를 나타내고 다른 하나는 MLP 번들 인터페이스를 나타냅니다. 각 기능에 사용되는 특정 인터페이스를 확인하려면 show ppp multilink 명령을 사용합니다. 이 쓰기를 마치면 번들당 하나의 VC만 지원되므로 show ppp multilink 출력의 bundle-member 목록에 하나의 가상 액세스 인터페이스만 나타나야 합니다.
두 개의 가상 액세스 인터페이스 외에도 각 PVC는 기본 인터페이스 및 하위 인터페이스와 연결됩니다. 이러한 인터페이스는 각각 몇 가지 대기열 처리 형식을 제공합니다. 그러나 번들 인터페이스를 나타내는 가상 액세스 인터페이스만 적용된 QoS 서비스 정책을 통한 일반 대기열 처리를 지원합니다. 다른 3개의 인터페이스에는 FIFO 큐잉이 있어야 합니다. 가상 템플릿에 service-policy를 적용할 때 라우터는 다음 메시지를 표시합니다.
cr7200(config)#interface virtual-template 1 cr7200(config)#service-policy output Gromit Class Base Weighted Fair Queueing not supported on interface Virtual-Access1
참고: 클래스 기반 가중치 공정 큐잉은 MLPPP 번들 인터페이스에서만 지원됩니다.
이 메시지는 정상입니다. 첫 번째 메시지는 서비스 정책이 PPP 가상 액세스 인터페이스에서 지원되지 않음을 알리는 것입니다. 두 번째 메시지는 서비스 정책이 MLP 번들 가상 액세스 인터페이스에 적용되었음을 확인합니다. MLP 번들 인터페이스의 대기열 메커니즘을 확인하려면 show interface virtual-access, show queue virtual-access 및 show policy-map interface virtual-access 명령을 사용합니다.
MLPPPoFR에서는 물리적 인터페이스에서 FRTS(Frame Relay Traffic Shaping)를 활성화해야 합니다. FRTS는 VC당 큐를 활성화합니다. 7200, 3600, 2600 Series와 같은 플랫폼에서 FRTS는 다음 두 명령으로 구성됩니다.
-
기본 인터페이스에서 프레임 릴레이 트래픽 셰이핑
-
map-class를 모든 셰이핑 명령과 함께 사용합니다.
FRTS 없이 MLPPoFR이 적용된 경우 최신 버전의 Cisco IOS에서는 다음 경고 메시지를 인쇄합니다.
"MLPoFR not configured properly on Link x Bundle y"
이 경고 메시지가 표시되면 FRTS가 물리적 인터페이스에 구성되어 있고 QoS 서비스 정책이 가상 템플릿에 연결되어 있는지 확인합니다. 컨피그레이션을 확인하려면 show running-config serial interface 및 show running-config virtual-template 명령을 사용합니다. MLPPPoFR이 구성되면 인터페이스 큐잉 메커니즘이 듀얼 FIFO로 변경됩니다(아래 그림 참조). 우선 순위가 높은 큐는 LMI(Local Management Interface)와 같은 음성 패킷과 제어 패킷을 처리하며, 우선 순위가 낮은 큐는 조각난 패킷(데이터 또는 비음성 패킷)을 처리합니다.
Router#show int serial 6/0:0
Serial6/0:0 is up, line protocol is down
Hardware is Multichannel T1
MTU 1500 bytes, BW 64 Kbit, DLY 20000 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation FRAME-RELAY, crc 16, Data non-inverted
Keepalive set (10 sec)
LMI enq sent 236, LMI stat recvd 0, LMI upd recvd 0, DTE LMI down
LMI enq recvd 353, LMI stat sent 0, LMI upd sent 0
LMI DLCI 1023 LMI type is CISCO frame relay DTE
Broadcast queue 0/64, broadcasts sent/dropped 0/0, interface broadcasts 0
Last input 00:00:02, output 00:00:02, output hang never
Last clearing of "show interface" counters 00:39:22
Queueing strategy: dual fifo
Output queue: high size/max/dropped 0/256/0
!--- high-priority queue
Output queue 0/128, 0 drops; input queue 0/75, 0 drops
!--- low-priority queue
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0 packets/sec
353 packets input, 4628 bytes, 0 no buffer
Received 0 broadcasts, 0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort
353 packets output, 4628 bytes, 0 underruns
0 output errors, 0 collisions, 0 interface resets
0 output buffer failures, 0 output buffers swapped out
0 carrier transitions
no alarm present
Timeslot(s) Used:12, subrate: 64Kb/s, transmit delay is 0 flags
LFI는 두 가지 대기열 계층을 사용합니다. MLPPP 번들 레벨은 고급 대기열 처리를 지원하며 PVC 레벨은 FIFO 대기열 처리만 지원합니다. 번들 인터페이스는 자체 대기열을 유지 관리합니다. 모든 MLP 패킷은 Frame Relay 또는 ATM 레이어보다 먼저 MLP 번들 및 가상 액세스 레이어를 통과합니다. LFI는 멤버 링크의 하드웨어 큐 크기를 모니터링하고 패킷이 원래 값 2였던 임계값 아래로 떨어지면 하드웨어 큐로 패킷을 뺍니다. 그렇지 않으면 패킷이 MLP 번들 대기열에 추가됩니다.
트러블슈팅 및 알려진 문제
다음 표에는 LFI over FRF 링크의 알려진 문제가 나열되어 있으며, 증상을 해결된 버그로 격리하기 위해 수행할 트러블슈팅 단계에 중점을 둡니다.
| 증상 | 문제 해결 단계 | 해결된 버그 |
|---|---|---|
| ATM 레그 또는 프레임 릴레이 레그의 처리량 감소 |
|
CSCdt59038 - 1500바이트 패킷 및 프래그먼트화가 100바이트로 설정된 경우 프래그먼트화된 패킷이 15개 있습니다. 여러 수준의 큐잉으로 인해 지연이 발생했습니다. CSCdu18344 - FRTS를 사용하는 경우 패킷이 예상보다 느린 속도로 대기열에서 제거됩니다. MLPPP 번들 디큐 기능은 트래픽 셰이퍼 큐의 큐 크기를 확인합니다. FRTS가 이 대기열을 지우는 속도가 너무 느렸습니다. |
| 비순차적 패킷 |
|
CSCdv89201 - 물리적 ATM 인터페이스가 혼잡할 경우 MLP 프래그먼트가 원격 끝에서 삭제되거나 순서가 바뀌었습니다. 이 문제는 2600 및 3600 Series의 ATM 네트워크 모듈에만 영향을 미칩니다. 이는 인터페이스 드라이버가 고속 경로(예: 고속 스위칭 또는 Cisco Express Forwarding)에서 패킷을 잘못 스위칭한 결과로 발생합니다. 구체적으로, 현재 패킷의 두 번째 프래그먼트는 다음 패킷의 첫 번째 프래그먼트 이후에 전송되었다 |
| 3600 Series가 투명 모드에서 IWF를 수행할 경우 엔드 투 엔드 연결 손실 |
|
CSCdw11409 - CEF가 올바른 바이트 위치를 확인하여 MLPPP 패킷의 캡슐화 헤더 처리를 시작하는지 확인합니다. |
관련 정보
- Frame Relay 및 ATM Virtual Circuits를 위한 Link Fragmentation 및 Interleaving 구성
- 프레임 릴레이 및 ATM을 통한 멀티링크 PPP 설계 및 구축
- RFC2364, PPP Over AAL5, 1998년 7월
- RFC1973, PPP in Frame Relay, 1996년 6월
- RFC1717, The PPP MP(Multilink Protocol), 1994년 11월
- 프레임 릴레이 / ATM PVC 서비스 상호 연동 구현 계약 FRF.8
- 추가 ATM 정보
- 툴 및 리소스 - Cisco Systems
- 기술 지원 및 문서 − Cisco Systems
개정 이력
| 개정 | 게시 날짜 | 의견 |
|---|---|---|
1.0 |
28-May-2002 |
최초 릴리스 |
 피드백
피드백