Ultra-M UCS 240M4伺服器中的主機板更換 — CPS
下載選項
無偏見用語
本產品的文件集力求使用無偏見用語。針對本文件集的目的,無偏見係定義為未根據年齡、身心障礙、性別、種族身分、民族身分、性別傾向、社會經濟地位及交織性表示歧視的用語。由於本產品軟體使用者介面中硬式編碼的語言、根據 RFP 文件使用的語言,或引用第三方產品的語言,因此本文件中可能會出現例外狀況。深入瞭解思科如何使用包容性用語。
關於此翻譯
思科已使用電腦和人工技術翻譯本文件,讓全世界的使用者能夠以自己的語言理解支援內容。請注意,即使是最佳機器翻譯,也不如專業譯者翻譯的內容準確。Cisco Systems, Inc. 對這些翻譯的準確度概不負責,並建議一律查看原始英文文件(提供連結)。
目錄
簡介
本文檔介紹在託管CPS虛擬網路功能(VNF)的Ultra-M設定中更換有故障的伺服器主機板所需的步驟。
背景資訊
Ultra-M是經過預先打包和驗證的虛擬化移動資料包核心解決方案,旨在簡化VNF的部署。OpenStack是適用於Ultra-M的虛擬化基礎架構管理員(VIM),由以下節點型別組成:
- 計算
- 對象儲存磁碟 — 計算(OSD — 計算)
- 控制器
- OpenStack平台 — 導向器(OSPD)
Ultra-M的高級體系結構及涉及的元件如下圖所示:
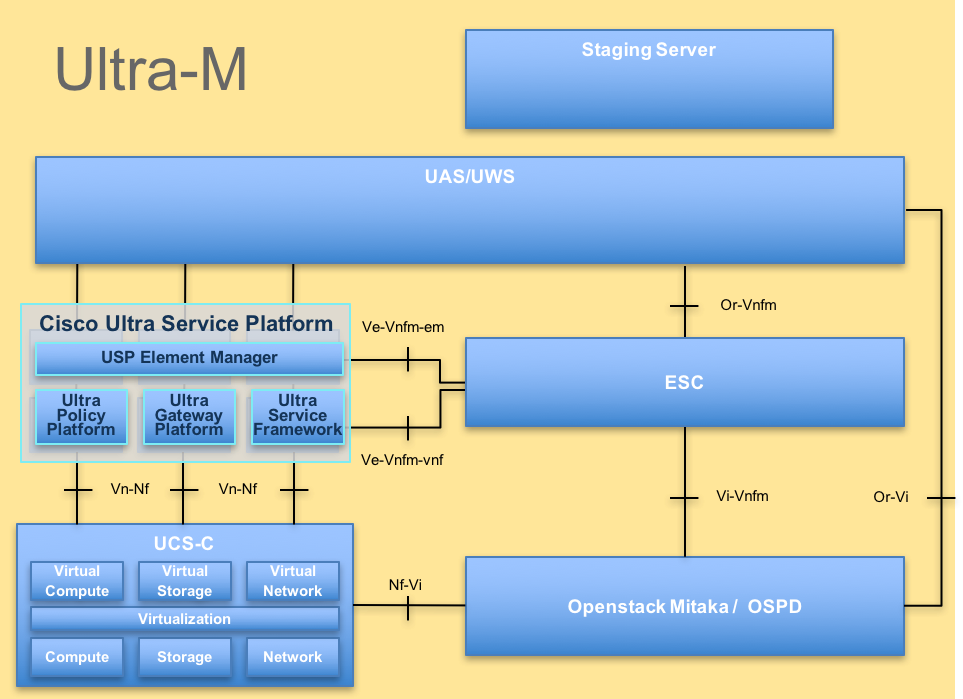
本文檔面向熟悉Cisco Ultra-M平台的思科人員,詳細介紹在伺服器中更換主機板時,在OpenStack和StarOS VNF級別需要執行的步驟。
附註:Ultra M 5.1.x版本用於定義本文檔中的過程。
縮寫
| VNF | 虛擬網路功能 |
| ESC | 彈性服務控制器 |
| 澳門幣 | 程式方法 |
| OSD | 對象儲存磁碟 |
| 硬碟 | 硬碟驅動器 |
| 固態硬碟 | 固態驅動器 |
| VIM | 虛擬基礎架構管理員 |
| 虛擬機器 | 虛擬機器 |
| EM | 元素管理器 |
| UAS | Ultra自動化服務 |
| UUID | 通用唯一識別符號 |
MoP的工作流程
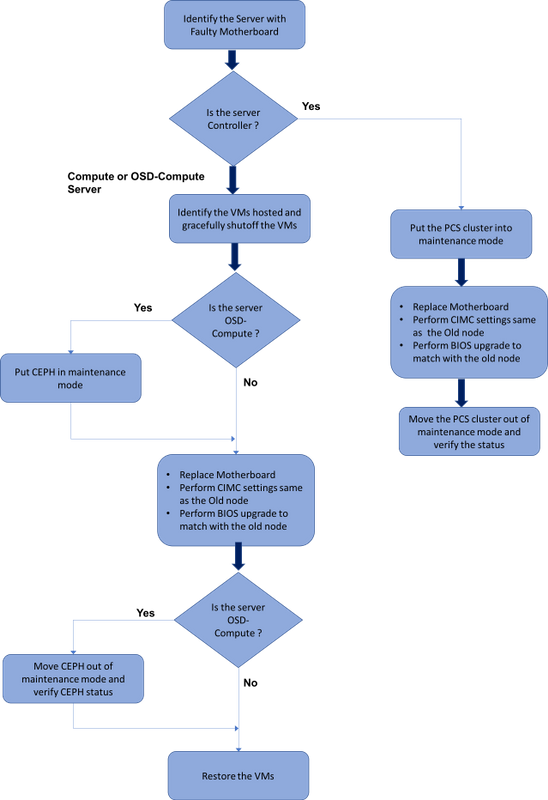
Ultra-M設定中的主機板更換
在Ultra-M設定中,在以下伺服器型別中可能需要更換主機板:計算、OSD計算和控制器。
附註:更換主機板後,會更換安裝有openstack的啟動盤。因此,無需將節點重新新增到超雲中。一旦伺服器在更換活動之後通電,它將自行註冊回重疊雲堆疊。
計算節點中的主機板更換
在活動之前,託管在「計算」節點中的VM會正常關閉。更換主機板後,VM將恢復回來。
確定計算節點中託管的VM
確定託管在計算伺服器上的虛擬機器。
計算伺服器包含CPS或彈性服務控制器(ESC)虛擬機器:
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
註:此處顯示的輸出中,第一列對應於通用唯一識別符號(UUID),第二列為VM名稱,第三列為VM所在的主機名。此輸出的引數將在後續章節中使用。
正常斷電
計算節點承載CPS/ESC虛擬機器
步驟1.登入到與VNF對應的ESC節點並檢查VM的狀態。
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
步驟2.使用虛擬機器名稱逐一停止CPS VM。(VM名稱在識別計算節點中託管的VM部分中註記)。
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
步驟3.停止後,VM必須進入SHUTOFF狀態。
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
步驟4.登入到計算節點中託管的ESC並檢查它是否處於主狀態。如果是,將ESC切換到備用模式:
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
ESC備份
步驟1. ESC在UltraM解決方案中具有1:1冗餘。2在UltraM中部署了ESC VM並支援單個故障。即,如果系統中存在單個故障,系統會恢復。
附註:如果出現多個故障,則不受支援,可能需要重新部署系統。
ESC備份詳細資訊:
- 運行配置
- ConfD CDB DB
- ESC日誌
- 系統日誌配置
步驟2. ESC資料庫備份的頻率很棘手,在ESC監視和維護所部署的各種VNF虛擬機器的各種狀態機時,需要仔細處理該頻率。建議這些備份在給定的VNF/POD/站點中的後續活動之後執行。
步驟3.檢驗ESC的運行狀況是否適合使用health.sh指令碼。
[root@auto-test-vnfm1-esc-0 admin]# escadm status
0 ESC status=0 ESC Master Healthy
[root@auto-test-vnfm1-esc-0 admin]# health.sh
esc ui is disabled -- skipping status check
esc_monitor start/running, process 836
esc_mona is up and running ...
vimmanager start/running, process 2741
vimmanager start/running, process 2741
esc_confd is started
tomcat6 (pid 2907) is running... [ OK ]
postgresql-9.4 (pid 2660) is running...
ESC service is running...
Active VIM = OPENSTACK
ESC Operation Mode=OPERATION
/opt/cisco/esc/esc_database is a mountpoint
============== ESC HA (MASTER) with DRBD =================
DRBD_ROLE_CHECK=0
MNT_ESC_DATABSE_CHECK=0
VIMMANAGER_RET=0
ESC_CHECK=0
STORAGE_CHECK=0
ESC_SERVICE_RET=0
MONA_RET=0
ESC_MONITOR_RET=0
=======================================
ESC HEALTH PASSED
步驟4.備份Running配置並將檔案傳輸到備份伺服器。
[root@auto-test-vnfm1-esc-0 admin]# /opt/cisco/esc/confd/bin/confd_cli -u admin -C
admin connected from 127.0.0.1 using console on auto-test-vnfm1-esc-0.novalocal
auto-test-vnfm1-esc-0# show running-config | save /tmp/running-esc-12202017.cfg
auto-test-vnfm1-esc-0#exit
[root@auto-test-vnfm1-esc-0 admin]# ll /tmp/running-esc-12202017.cfg
-rw-------. 1 tomcat tomcat 25569 Dec 20 21:37 /tmp/running-esc-12202017.cfg
備份ESC資料庫
步驟1.登入到ESC VM並在進行備份之前運行此命令。
[admin@esc ~]# sudo bash
[root@esc ~]# cp /opt/cisco/esc/esc-scripts/esc_dbtool.py /opt/cisco/esc/esc-scripts/esc_dbtool.py.bkup
[root@esc esc-scripts]# sudo sed -i "s,'pg_dump,'/usr/pgsql-9.4/bin/pg_dump," /opt/cisco/esc/esc-scripts/esc_dbtool.py
#Set ESC to mainenance mode
[root@esc esc-scripts]# escadm op_mode set --mode=maintenance
步驟2.檢查ESC模式並確保它處於維護模式。
[root@esc esc-scripts]# escadm op_mode show
步驟3.使用ESC中提供的資料庫備份還原工具備份資料庫。
[root@esc scripts]# sudo /opt/cisco/esc/esc-scripts/esc_dbtool.py backup --file scp://
:
@
:
步驟4.將ESC設定回操作模式並確認模式。
[root@esc scripts]# escadm op_mode set --mode=operation
[root@esc scripts]# escadm op_mode show
步驟5.導航到scripts目錄並收集日誌。
[root@esc scripts]# /opt/cisco/esc/esc-scripts
sudo ./collect_esc_log.sh
步驟6.建立ESC的快照,首先關閉ESC。
shutdown -r now
步驟7.從OSPD建立映像快照。
-
nova image-create --poll esc1 esc_snapshot_27aug2018
步驟8.驗證是否已建立快照
openstack image list | grep esc_snapshot_27aug2018
步驟9.從OSPD啟動ESC
nova start esc1
步驟10.在備用ESC VM上重複相同過程,並將日誌傳輸到備份伺服器。
步驟11.收集兩個ESC VM上的系統日誌配置備份,並將它們傳輸到備份伺服器。
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
更換主機板
步驟1.更換UCS C240 M4伺服器中主機板的步驟可從以下網址獲得:
步驟2.使用CIMC IP登入到伺服器。
步驟3.如果韌體與以前使用的推薦版本不一致,請執行BIOS升級。BIOS升級步驟如下:
恢復虛擬機器
計算節點主機CPS、ESC
恢復ESC虛擬機器
步驟1。如果VM處於錯誤或關閉狀態,請執行硬重新啟動以啟動受影響的VM,則ESC VM可恢復。運行以下步驟以恢復ESC。
步驟2.識別出處於ERROR或Shutdown狀態的VM,一旦識別出此狀態,請硬重新啟動ESC VM。在本示例中,重新啟動auto-test-vnfm1-ESC-0。
[root@tb1-baremetal scripts]# nova list | grep auto-test-vnfm1-ESC-
| f03e3cac-a78a-439f-952b-045aea5b0d2c | auto-test-vnfm1-ESC-0 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.57.12.11; auto-testautovnf1-uas-management=172.57.11.3 |
| 79498e0d-0569-4854-a902-012276740bce | auto-test-vnfm1-ESC-1 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.57.12.15; auto-testautovnf1-uas-management=172.57.11.5 |
[root@tb1-baremetal scripts]# [root@tb1-baremetal scripts]# nova reboot --hard f03e3cac-a78a-439f-952b-045aea5b0d2c\
Request to reboot server <Server: auto-test-vnfm1-ESC-0> has been accepted.
[root@tb1-baremetal scripts]#
步驟3.如果刪除ESC VM,需要再次啟動。
[stack@pod1-ospd scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.168.11.14; vnf1-UAS-uas-management=172.168.10.4 |
[stack@pod1-ospd scripts]$ nova delete vnf1-ESC-ESC-1
Request to delete server vnf1-ESC-ESC-1 has been accepted.
步驟4.在OSPD中,檢查新的ESC VM是否處於活動/運行狀態:
[stack@pod1-ospd ~]$ nova list|grep -i esc
| 934519a4-d634-40c0-a51e-fc8d55ec7144 | vnf1-ESC-ESC-0 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.168.11.13; vnf1-UAS-uas-management=172.168.10.3 |
| 2601b8ec-8ff8-4285-810a-e859f6642ab6 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.168.11.14; vnf1-UAS-uas-management=172.168.10.6 |
#Log in to new ESC and verify Backup state. You may execute health.sh on ESC Master too.
…
####################################################################
# ESC on vnf1-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@esc-1 ~]$ health.sh
============== ESC HA (BACKUP) =================
=======================================
ESC HEALTH PASSED
[admin@esc-1 ~]$ cat /proc/drbd
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
1: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r-----
ns:0 nr:504720 dw:3650316 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
步驟5.如果ESC VM不可恢復並且需要還原資料庫,請從以前備份中還原資料庫。
步驟6.對於ESC資料庫還原,必須在還原資料庫之前確保esc服務已停止;對於ESC HA,先在輔助VM中執行,然後在主VM中執行。
# service keepalived stop
步驟7.檢查ESC服務狀態,並確保在HA的主和輔助VM中一切都已停止
# escadm status
步驟8.執行指令碼以恢複資料庫。作為將資料庫恢復到新建立的ESC例項的一部分,該工具還將將其中一個例項升級為主ESC,將其資料庫資料夾裝載到驅動器裝置並將啟動PostgreSQL資料庫。
# /opt/cisco/esc/esc-scripts/esc_dbtool.py restore --file scp://
:
@
:
步驟9.重新啟動ESC服務以完成資料庫還原。
對於在兩個虛擬機器中執行的HA,請重新啟動keepalive服務
# service keepalived start
步驟10.VM成功恢復並運行後;確保從以前成功的已知備份還原所有系統日誌特定配置。確保它在所有ESC虛擬機器中恢復
[admin@auto-test-vnfm2-esc-1 ~]$
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
步驟11.如果需要從OSPD快照重建ESC,請使用下面的命令使用備份過程中拍攝的快照。
nova rebuild --poll --name esc_snapshot_27aug2018 esc1
步驟12.檢查重建完成後ESC的狀態。
nova list --fileds name,host,status,networks | grep esc
步驟13.使用下面的命令檢查ESC健康狀況。
health.sh
Copy Datamodel to a backup file
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli get esc_datamodel/opdata > /tmp/esc_opdata_`date +%Y%m%d%H%M%S`.txt
恢復CPS虛擬機器
CPS VM在新星清單中處於錯誤狀態:
[stack@director ~]$ nova list |grep VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d | ERROR | - | NOSTATE |
從ESC恢復CPS虛擬機器:
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
監控yangesc.log:
admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d].
當ESC無法啟動VM時
步驟1。在某些情況下,ESC由於意外狀態而無法啟動VM。解決方法是重新啟動主ESC來執行ESC切換。ESC切換將需要大約一分鐘。 在新的主ESC上執行health.sh以驗證它是否啟動。當ESC成為主時,ESC可能會修復VM狀態並啟動VM。由於此操作已計畫,您必須等待5-7分鐘才能完成。
步驟2.您可以監控/var/log/esc/yangesc.log和/var/log/esc/escmanager.log。如果您在5-7分鐘之後沒有看到虛擬機器被恢復,則使用者將需要手動恢復受影響的虛擬機器。
步驟3.VM成功恢復並運行後;確保從以前成功的已知備份還原所有系統日誌特定配置。確保它在所有ESC虛擬機器中恢復。
root@autotestvnfm1esc2:/etc/rsyslog.d# pwd
/etc/rsyslog.d
root@autotestvnfm1esc2:/etc/rsyslog.d# ll
total 28
drwxr-xr-x 2 root root 4096 Jun 7 18:38 ./
drwxr-xr-x 86 root root 4096 Jun 6 20:33 ../]
-rw-r--r-- 1 root root 319 Jun 7 18:36 00-vnmf-proxy.conf
-rw-r--r-- 1 root root 317 Jun 7 18:38 01-ncs-java.conf
-rw-r--r-- 1 root root 311 Mar 17 2012 20-ufw.conf
-rw-r--r-- 1 root root 252 Nov 23 2015 21-cloudinit.conf
-rw-r--r-- 1 root root 1655 Apr 18 2013 50-default.conf
root@abautotestvnfm1em-0:/etc/rsyslog.d# ls /etc/rsyslog.conf
rsyslog.conf
OSD計算節點中的主機板更換
在活動之前,Compute節點中託管的VM將正常關閉,CEPH將進入維護模式。更換主機板後,VM會恢復回來,CEPH會移出維護模式。
將CEPH置於維護模式
步驟1.驗證伺服器中的ceph osd樹狀態是否為up
[heat-admin@pod1-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
步驟2.登入OSD Compute節點並將CEPH置於維護模式。
[root@pod1-osd-compute-1 ~]# sudo ceph osd set norebalance
[root@pod1-osd-compute-1 ~]# sudo ceph osd set noout
[root@pod1-osd-compute-1 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e194: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v584865: 704 pgs, 6 pools, 531 GB data, 344 kobjects
1585 GB used, 11808 GB / 13393 GB avail
704 active+clean
client io 463 kB/s rd, 14903 kB/s wr, 263 op/s rd, 542 op/s wr
附註:刪除CEPH後,VNF HD RAID進入「已降級」狀態,但hd-disk必須仍然可以訪問
確定Osd-Compute節點中託管的VM
確定OSD計算伺服器上託管的VM。
計算伺服器包含彈性服務控制器(ESC)或CPS虛擬機器
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
附註:此處顯示的輸出中,第一列對應於通用唯一識別符號(UUID),第二列是VM名稱,第三列是存在VM的主機名。此輸出的引數將在後續章節中使用。
正常斷電
案例1. OSD計算節點主機ESC
無論ESC或CPS VM是託管在計算節點還是OSD-Compute節點中,其優雅的電源運行過程都是相同的。
按照「Compute Node中的主機板更換」中的步驟正常關閉VM。
更換主機板
步驟1.更換UCS C240 M4伺服器中主機板的步驟可從以下網址獲得:
步驟2.使用CIMC IP登入到伺服器
3.如果韌體與以前使用的推薦版本不一致,請執行BIOS升級。BIOS升級步驟如下:
將CEPH移出維護模式
登入到OSD Compute節點並將CEPH從維護模式中移出。
[root@pod1-osd-compute-1 ~]# sudo ceph osd unset norebalance
[root@pod1-osd-compute-1 ~]# sudo ceph osd unset noout
[root@pod1-osd-compute-1 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e196: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v584954: 704 pgs, 6 pools, 531 GB data, 344 kobjects
1585 GB used, 11808 GB / 13393 GB avail
704 active+clean
client io 12888 kB/s wr, 0 op/s rd, 81 op/s wr
恢復虛擬機器
案例1. OSD計算節點託管ESC或CPS虛擬機器
恢復CF/ESC/EM/UAS VM的過程相同,無論這些VM是託管在Compute節點還是OSD-Compute節點中。
按照「案例2.計算節點主機CF/ESC/EM/UAS」中的步驟恢復VM。
控制器節點中的主機板更換
驗證控制器狀態並將群集置於維護模式
從OSPD登入到控制器並驗證pc是否處於正常狀態 — 所有三個控制器都處於聯機狀態,且所有三個控制器都顯示為主控制器。
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 00:46:10 2017 Last change: Wed Nov 29 01:20:52 2017 by hacluster via crmd on pod1-controller-0
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-0 pod1-controller-1 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-0
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-0
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
將群集置於維護模式。
[heat-admin@pod1-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 00:48:24 2017 Last change: Mon Dec 4 00:48:18 2017 by root via crm_attribute on pod1-controller-0
3 nodes and 22 resources configured
Node pod1-controller-0: standby
Online: [ pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-1 pod1-controller-2 ]
Stopped: [ pod1-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-1 pod1-controller-2 ]
Slaves: [ pod1-controller-0 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-1 ]
Stopped: [ pod1-controller-0 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-2
更換主機板
步驟1.更換UCS C240 M4伺服器中主機板的步驟可從以下網址獲得:
步驟2.使用CIMC IP登入到伺服器。
步驟3.如果韌體與以前使用的推薦版本不一致,請執行BIOS升級。BIOS升級步驟如下:
還原群集狀態
登入受影響的控制器,通過設定unstandby移除待機模式。驗證控制器是否與群集聯機,並且galera將全部三個控制器顯示為主控制器。這可能需要幾分鐘時間。
[heat-admin@pod1-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 01:08:10 2017 Last change: Mon Dec 4 01:04:21 2017 by root via crm_attribute on pod1-controller-0
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-0 pod1-controller-1 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-2
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enable
由思科工程師貢獻
- Nitesh Bansal
- Rishi Shekhar思科高級服務
 意見
意見