Nexus 7000 Supervisor 2/2E精簡型快閃記憶體故障復原
下載選項
無偏見用語
本產品的文件集力求使用無偏見用語。針對本文件集的目的,無偏見係定義為未根據年齡、身心障礙、性別、種族身分、民族身分、性別傾向、社會經濟地位及交織性表示歧視的用語。由於本產品軟體使用者介面中硬式編碼的語言、根據 RFP 文件使用的語言,或引用第三方產品的語言,因此本文件中可能會出現例外狀況。深入瞭解思科如何使用包容性用語。
關於此翻譯
思科已使用電腦和人工技術翻譯本文件,讓全世界的使用者能夠以自己的語言理解支援內容。請注意,即使是最佳機器翻譯,也不如專業譯者翻譯的內容準確。Cisco Systems, Inc. 對這些翻譯的準確度概不負責,並建議一律查看原始英文文件(提供連結)。
目錄
簡介
本檔案介紹CSCus22805軟體缺陷中記錄的Nexus 7000 Supervisor 2/2E精簡型快閃記憶體失敗問題、所有可能的失敗情形以及復原步驟。
在任何解決方法之前,強烈建議物理訪問裝置,以防需要物理重新拔插。 對於某些重新載入升級,可能需要控制檯訪問,並且始終建議通過控制檯訪問Supervisor來執行這些解決方法,以觀察引導過程。
如果解決方法中的任何步驟失敗,請與Cisco TAC聯絡以獲取其他可能的恢複選項。
背景
每個N7K Supervisor 2/2E都配備2個eUSB快閃記憶體裝置(採用RAID1配置)、一個主裝置和一個映象。它們一起為啟動映像、啟動配置和持久應用程式資料提供非易失性儲存庫。
在服務數月或數年的時間內,其中一個裝置可能會從USB匯流排斷開,從而導致RAID軟體從配置中刪除該裝置。裝置仍可使用1/2裝置正常工作。但是,當第二個裝置從陣列中退出時,bootflash將重新裝載為只讀,這意味著您不能將配置或檔案儲存到bootflash中,也不能允許備用裝置在重新載入時同步到主用裝置。
在雙快閃記憶體故障狀態下運行的系統不會受到操作影響,但是需要重新載入受影響的Supervisor才能從該狀態恢復。此外,對運行配置所做的任何更改都不會反映在啟動中,並且會在電源中斷時丟失。
症狀
出現以下症狀:
- 快閃記憶體診斷故障
switch# show diagnostic result module 5
Current bootup diagnostic level: complete
Module 5: Supervisor module-2 (Standby)
Test results: (. = Pass, F = Fail, I = Incomplete,
U = Untested, A = Abort, E = Error disabled)
1) ASICRegisterCheck-------------> .
2) USB---------------------------> .
3) NVRAM-------------------------> .
4) RealTimeClock-----------------> .
5) PrimaryBootROM----------------> .
6) SecondaryBootROM--------------> .
7) CompactFlash------------------> F <=====
8) ExternalCompactFlash----------> .
9) PwrMgmtBus--------------------> U
10) SpineControlBus---------------> .
11) SystemMgmtBus-----------------> U
12) StatusBus---------------------> U
13) StandbyFabricLoopback---------> .
14) ManagementPortLoopback--------> .
15) EOBCPortLoopback--------------> .
16) OBFL--------------------------> .
- 無法執行「複製運行開始」
dcd02.ptfrnyfs# copy running-config startup-config
[########################################] 100%
Configuration update aborted: request was aborted
- eUSB變為只讀或無響應
switch %MODULE-4-MOD_WARNING: Module 2 (Serial number: JAF1645AHQT) reported warning
due to The compact flash power test failed in device DEV_UNDEF (device error 0x0)
switch %DEVICE_TEST-2-COMPACT_FLASH_FAIL: Module 1 has failed test CompactFlash 20
times on device Compact Flash due to error The compact flash power test failed
- ISSU故障,通常在嘗試故障切換到備用Supervisor時
診斷
要診斷快閃記憶體卡的當前狀態,您需要使用這些內部命令。請注意,該命令不會解析出,並且必須完整鍵入該命令:
switch# show system internal raid | grep -A 1 "當前RAID狀態資訊"
switch# show system internal file /proc/mdstat
如果機箱中有兩個管理引擎,您需要檢查備用管理引擎的狀態並確定您面臨的故障情況。檢查此情況,方法是使用「slot x」關鍵字在命令前新增前置語句,其中「x」是待命Supervisor的插槽編號。這允許您在備用模式下遠端運行命令。
switch# slot 2 show system internal raid | grep -A 1 "當前RAID狀態資訊"
switch# slot 2 show system internal file /proc/mdstat
這些命令將提供大量RAID統計資訊和事件,但您只關注當前RAID資訊。
在「CMOS的RAID資料」行中,您要檢視0xa5之後的十六進位制值。 這將顯示當前面臨問題的閃爍次數。
例如:
switch# show system internal raid | grep -A 1 "Current RAID status info"
Current RAID status info:
RAID data from CMOS = 0xa5 0xc3
在此輸出中,您要檢視0xa5旁的編號,即0xc3。 然後,您可以使用這些鍵來確定主快閃記憶體或輔助快閃記憶體是否發生故障,或者兩者都發生故障。上面的輸出顯示0xc3,它告訴我們主壓縮閃光和輔助壓縮閃光都發生了故障。
| 0xf0 | 未報告失敗 |
| 0xe1 | 主快閃記憶體失敗 |
| 0xd2 | 備用(或映象)快閃記憶體失敗 |
| 0xc3 | 主要和備用均失敗 |
在「/proc/mdstat」輸出中,確保所有磁碟都顯示為「U」,即「U」p:
switch# slot 2 show system internal file /proc/mdstat
Personalities : [raid1]
md6 : active raid1 sdc6[0] sdb6[1]
77888 blocks [2/1] [_U]
md5 : active raid1 sdc5[0] sdb5[1]
78400 blocks [2/1] [_U]
md4 : active raid1 sdc4[0] sdb4[1]
39424 blocks [2/1] [_U]
md3 : active raid1 sdc3[0] sdb3[1]
1802240 blocks [2/1] [_U]
在此案例中,您會看到主快閃記憶體未啟動[_U]。正常輸出會將所有塊顯示為[UU]。
附註:兩個輸出都需要顯示為正常(0xf0和[UU])才能診斷主控引擎是否正常。因此,如果您在CMOS資料中看到0xf0輸出,但在/proc/mdstat中看到[_U],則該框將不正常。
案例
要確定您面臨的方案,您需要使用上述「Diagnostics」部分中的命令與下面的方案信相關。 使用列,匹配每個Supervisor上失敗壓縮閃爍的數量。
例如,如果您在作用中Supervisor上看到代碼為0xe1,在備用上,代碼為0xd2,則在作用中為「1 Fail」,在備用上,代碼為「1 Fail」,即方案字母「D」。
單主管:
| 情境信函 | 活動的管理引擎 | 活動主管代碼 |
| A | 1失敗 | 0xe1或0xd2 |
| B | 2個失敗 | 0xc3 |
雙管理引擎:
| 情境信函 | 活動的管理引擎 | 備用管理引擎 | 活動主管代碼 | 備用管理引擎代碼 |
| 思 | 0失敗 | 1失敗 | 0xf0 | 0xe1或0xd2 |
| D | 1失敗 | 0失敗 | 0xe1或0xd2 | 0xf0 |
| E | 1失敗 | 1失敗 | 0xe1或0xd2 | 0xe1或0xd2 |
| 思 | 2個失敗 | 0失敗 | 0xc3 | 0xf0 |
| G | 0失敗 | 2個失敗 | 0xf0 | 0xc3 |
| H | 2個失敗 | 1失敗 | 0xc3 | 0xe1或0xd2 |
| I | 1失敗 | 2失敗 | 0xe1或0xd2 | 0xc3 |
| J | 2個失敗 | 2個失敗 | 0xc3 | 0xc3 |
每個情景的復原程式
單個Supervisor故障場景
案例A(1在作用中發生故障)
恢複方案:
1在活動狀態下失敗
解決步驟:
1.載入快閃記憶體恢復工具以修復bootflash。您可以在N7000平台的實用程式下從CCO下載恢復工具,或使用以下連結:
它包裝在tar gz壓縮檔案中,請解壓縮它以找到.gbin恢復工具和.pdf自述檔案。檢視自述檔案,將.gbin工具載入到N7K的bootflash中。雖然此恢復設計為無影響,並且可以即時執行,但TAC建議您在維護視窗中執行此恢復,以防出現任何意外問題。檔案位於bootflash上後,您可以使用以下方式執行復原工具:
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the fixed state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
案例B(2在作用中發生故障)
恢複方案:
2在活動時失敗
解決步驟:
附註:在出現雙快閃記憶體故障時,通常會出現軟體重新載入無法完全恢復RAID的情況,而且可能需要運行恢復工具或後續重新載入才能恢復。幾乎每次出現時,都通過物理重新拔插Supervisor模組解決了此問題。因此,如果可以對裝置進行物理訪問,請在外部備份配置之後,通過在準備重新載入裝置時重新物理地安裝Supervisor,嘗試快速恢復,這種恢復成功的可能性最大。這將完全斷開Supervisor的電源,並且應該允許恢復RAID中的兩個磁碟。如果物理重新拔插恢復只是部分恢復,請繼續執行步驟3;如果系統未完全啟動,則繼續執行步驟4。
雙管理引擎故障場景
場景C(0在活動模式上失敗,1在備用模式上失敗)
故障場景:
0在活動時失敗
1在待機時失敗
解決步驟:
在雙Supervisor設定的情況下,如果活動上無快閃記憶體故障,而備用上無單個故障,則可以執行無影響的恢復。
1.由於主用裝置沒有故障,而備用裝置只有單個故障,因此可以將快閃記憶體恢復工具載入到主用裝置上並執行。運行該工具後,它將自動將其自身複製到備用陣列並嘗試重新同步陣列。 恢復工具可從以下站點下載:
下載工具、解壓縮該工具並將其上傳到盒子的bootflash後,您需要執行以下命令開始恢復:
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
該工具將開始運行並檢測斷開連線的磁碟,並嘗試使用RAID陣列重新同步這些磁碟。
可以使用以下命令檢查恢復狀態:
# show system internal file /proc/mdstat
驗證恢復是否正在繼續,可能需要幾分鐘才能完全修復所有磁碟至[UU]狀態。操作中的恢復示例如下所示:
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
恢復完成後,應如下所示:
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
所有磁碟都位於[UU]中後,RAID陣列將完全備份,同時同步兩個磁碟。
2.如果快閃記憶體恢復工具未成功,因為主用磁碟都已啟動,則備用磁碟應該能夠在重新載入時成功同步到主用磁碟。
因此,在計畫的視窗中,對備用Supervisor執行「out-of-service module x」,建議讓控制檯訪問備用,以便在出現任何意外問題時觀察引導過程。Supervisor關閉後,等待幾秒鐘,然後對備用模組執行「no power off module x」。等待備用裝置完全引導至「ha-standby」狀態。
備份備用磁碟後,使用「slot x show system internal raid」和「slot x show system internal file /proc/mdstat」檢查RAID。
如果在重新載入後兩個磁碟均未完全備份,請再次運行恢復工具。
3.如果重新載入和恢復工具未成功,建議嘗試在視窗中物理重新拔插備用模組以嘗試清除該情況。 如果物理重新拔插不成功,請嘗試從交換機引導模式中執行「init system」,方法是在引導過程中執行密碼恢復步驟以進入此模式。 如果仍失敗,請聯絡TAC嘗試手動恢復。
案例D(1在主動發生故障,0在備用發生故障)
恢複方案:
1在活動狀態下失敗
0在待機時失敗
解決步驟:
在雙Supervisor設定的情況下,如果活動狀態有1個快閃記憶體故障,備用狀態無故障,則可以使用快閃記憶體恢復工具執行無影響的恢復。
1.由於備用裝置沒有故障,而主用裝置只有單個故障,因此可以將快閃記憶體恢復工具載入到主用裝置上並執行。運行該工具後,它將自動將其自身複製到備用陣列並嘗試重新同步陣列。 恢復工具可從以下站點下載:
下載工具、解壓縮該工具並將其上傳到活動程式的bootflash後,您需要執行以下命令開始恢復:
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
該工具將開始運行並檢測斷開連線的磁碟,並嘗試使用RAID陣列重新同步這些磁碟。
可以使用以下命令檢查恢復狀態:
# show system internal file /proc/mdstat
驗證恢復是否正在繼續,可能需要幾分鐘才能完全修復所有磁碟至[UU]狀態。操作中的恢復示例如下所示:
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
恢復完成後,應如下所示:
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
所有磁碟都位於[UU]中後,RAID陣列將完全備份,同時同步兩個磁碟。
2.如果Flash Recovery Tool不成功,下一步將是執行「系統切換」以在維護視窗中故障切換Supervisor模組。
因此,在計畫的視窗中,執行「system switchover」,建議使用控制檯訪問,以便在出現任何意外問題時觀察引導過程。 等待備用裝置完全引導至「ha-standby」狀態。
備份備用磁碟後,使用「slot x show system internal raid」和「slot x show system internal file /proc/mdstat」檢查RAID。
如果在重新載入後兩個磁碟均未完全備份,請再次運行恢復工具。
3.如果重新載入和恢復工具未成功,建議嘗試在視窗中物理重新拔插備用模組以嘗試清除該情況。 如果物理重新拔插不成功,請嘗試從交換機引導模式中執行「init system」,方法是在引導過程中執行密碼恢復步驟以進入此模式。 如果仍失敗,請聯絡TAC嘗試手動恢復。
案例E(1在主動發生故障,1在備用發生故障)
恢複方案:
1在活動狀態下失敗
1在待機時失敗
解決步驟:
如果主用和備用快閃記憶體上均發生單快閃記憶體故障,仍可實現無影響的解決方法。
1.由於沒有管理引擎處於只讀狀態,第一步是嘗試使用快速恢復工具。
恢復工具可從以下站點下載:
下載工具、解壓縮該工具並將其上傳到活動程式的bootflash後,您需要執行以下命令開始恢復:
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
它將自動檢測活動磁碟上斷開的磁碟並嘗試修復,並自動將自身複製到備用磁碟並檢測和糾正其中的故障。
可以使用以下命令檢查恢復狀態:
# show system internal file /proc/mdstat
驗證恢復是否正在繼續,可能需要幾分鐘才能完全修復所有磁碟至[UU]狀態。操作中的恢復示例如下所示:
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
恢復完成後,應如下所示:
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
所有磁碟都位於[UU]中後,RAID陣列將完全備份,同時同步兩個磁碟。
如果兩個管理引擎均恢復到[UU]狀態,則恢復完成。 如果恢復是部分恢復或未成功,請轉至步驟2。
2.如果恢復工具未成功,請確定模組上RAID的當前狀態。如果兩台交換機上仍有一個快閃記憶體故障,則嘗試進行「系統切換」,這將重新載入當前主用裝置並強製備用裝置成為主用裝置。
將上一個主用驅動器重新載入回「ha-standby」後,檢查其RAID狀態,因為在重新載入期間應將其恢復。
如果Supervisor在切換後成功恢復,您可以再次嘗試運行快閃記憶體恢復工具以嘗試修復當前活動Supervisor上的單個磁碟故障,或者嘗試另一個「系統切換」以重新載入當前活動,並強制將之前已修復的活動和當前備用狀態恢復為活動角色。驗證重新載入的Supervisor是否再次修復了兩個磁碟,如有必要,請重新運行恢復工具。
3.如果在此過程中切換未修復RAID,請對備用模組執行「服務中斷模組x」,然後「no power off module x」以完全移除並重新為該模組通電。
如果未成功停止服務,嘗試物理重新拔插待機。
如果在運行恢復工具後,一個管理引擎恢復其RAID,而另一個管理引擎仍存在故障,則強制發生單一故障的管理引擎備用,並在必要時執行「系統切換」。如果具有單個故障的管理引擎是
已處於待機狀態,請對備用模組執行「服務外模組x」和「無電源模組x」,以完全移除並重新為模組供電。如果仍然無法恢復,請嘗試對模組進行物理重新拔插。如果重新拔插無法修復,
使用密碼復原程式進入交換器開機提示符,並執行「init system」以重新初始化bootflash。如果仍失敗,請讓TAC嘗試手動復原。
附註:如果任一時刻備用裝置停滯在「通電」狀態而不是「ha-standby」狀態,則如果無法通過上述步驟使備用裝置完全啟動,則需要重新載入機箱。
案例 F(2在活動狀態發生故障,0在備用狀態發生故障)
恢複方案:
2在活動時失敗
0在待機時失敗
解決步驟:
如果主用管理引擎上有2個故障,備用管理引擎上有0個故障,則可能實現無影響的恢復,具體取決於由於備用管理引擎無法將其運行配置與主用管理引擎同步而新增了多少運行配置。
恢復過程將是:將當前運行配置從活動Supervisor複製,故障切換到健康的備用Supervisor,將缺少的運行配置複製到新的活動Supervisor,手動使以前的活動聯機,然後運行恢復工具。
2. 將運行配置從活動Supervisor複製出來後,最好將其與啟動配置進行比較,以檢視自上次儲存後發生了什麼變化。 可從show startup-configuration中看到這種情況。 不同之處當然完全取決於環境,但最好知道當備用裝置以活動狀態聯機時可能缺少什麼。 最好在記事本中複製這些差異,以便在切換後快速將其新增到新的活動Supervisor。
3. 評估差異之後,您需要執行管理引擎切換。 TAC建議在維護時段期間完成此操作,因為可能會發生不可預見的問題。 用於執行到備用裝置的故障切換的命令將是「系統切換」。
4. 切換應會很快進行,新的備用裝置將開始重新啟動。 在此期間,您需要將所有缺失的配置新增回新的活動配置。 這可以通過從TFTP伺服器複製配置(或以前儲存的任何位置)或只在CLI中手動新增配置來完成。 在大多數情況下,缺少的配置非常短,而CLI選項是最可行的。
5. 一段時間後,新的備用管理引擎可能會以「ha-standby」狀態重新聯機,但通常會出現的情況是它將停滯在「powered-up」狀態。 可以使用「show module」命令並參考模組旁邊的「Status」列來檢視狀態。
如果新的備用裝置處於「通電」狀態,則需要手動使其重新聯機。 這可以通過發出以下命令來完成,其中「x」是停滯在「通電」狀態的備用模組:
(config)# out-of-service module x
(config)#no power off module x
6. 一旦備用裝置在「ha-standby」狀態下重新聯機,則需要運行恢復工具以確保恢復完成。 可通過以下連結下載該工具:
下載工具、解壓縮該工具並將其上傳到盒子的bootflash後,您需要執行以下命令開始恢復:
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
該工具將開始運行並檢測斷開連線的磁碟,並嘗試使用RAID陣列重新同步這些磁碟。
可以使用以下命令檢查恢復狀態:
# show system internal file /proc/mdstat
驗證恢復是否正在繼續,可能需要幾分鐘才能完全修復所有磁碟至[UU]狀態。操作中的恢復示例如下所示:
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
恢復完成後,應如下所示:
switch# show system internal file /proc/mdstat
Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
所有磁碟都位於[UU]中後,RAID陣列將完全備份,同時同步兩個磁碟。
案例G(0在主動發生故障,2在備用發生故障)
0在活動模式中發生故障,2在備用模式中發生故障
恢複方案:
0在活動時失敗
2在待機時失敗
解決步驟:
如果主用管理引擎上發生故障0,備用管理引擎上發生故障2,則可能實現無影響的恢復。
恢復過程將執行備用裝置的重新載入。
1.在雙快閃記憶體故障的管理引擎中,通常可以看到,軟體「reload module x」只能部分修復RAID,或者在重新引導時使其陷入通電狀態。
因此,建議以物理方式重新拔插雙快閃記憶體故障的Supervisor以完全卸下並重新接通模組的電源,或者您可以執行以下操作(x表示備用插槽號):
# out-of-service module x
# no poweroff module x
如果您看到備用裝置一直停滯在通電狀態,並最終在上面的步驟之後保持電源循環,這可能是由於主用裝置重新載入備用裝置導致無法及時啟動所致。
這可能是因為啟動備用嘗試重新初始化其bootflash/RAID(可能需要10分鐘),但它在完成之前一直被活動狀態重置。
要解決此問題,請使用「x」對停留在通電狀態的備用插槽#進行以下配置:
(config)# system standby manual-boot
(config)# reload module x force-dnld
上述操作將使主用裝置不會自動重置備用裝置,然後重新載入備用裝置並強制其從主用裝置同步其映像。
等待10-15分鐘,檢視備用裝置是否最終能夠進入ha-standby狀態。處於ha-standby狀態後,使用以下命令重新啟用備用裝置的自動重新啟動:
(config)# system no standby manual-boot
6. 一旦備用裝置在「ha-standby」狀態下重新聯機,則需要運行恢復工具以確保恢復完成。 可通過以下連結下載該工具:
https://software.cisco.com/download/release.html?mdfid=284472710&flowid=&softwareid=282088132&relind=AVAILABLE&rellifecycle=&reltype=latest
下載工具、解壓縮該工具並將其上傳到盒子的bootflash後,您需要執行以下命令開始恢復:
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
該工具將開始運行並檢測斷開連線的磁碟,並嘗試使用RAID陣列重新同步這些磁碟。
可以使用以下命令檢查恢復狀態:
# show system internal file /proc/mdstat
驗證恢復是否正在繼續,可能需要幾分鐘才能完全修復所有磁碟至[UU]狀態。操作中的恢復示例如下所示:
switch# show system internal file /proc/mdstat
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
恢復完成後,應如下所示:
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
所有磁碟都位於[UU]中後,RAID陣列將完全備份,同時同步兩個磁碟。
案例H(2在作用中發生故障,1在備用中發生故障)
2在活動模式中發生故障,1在備用模式中發生故障
恢複方案:
2在活動時失敗
1在待機時失敗
解決步驟:
如果主用管理引擎上有2個故障,備用管理引擎上有1個故障,則根據備用管理引擎無法將其運行配置與主用管理引擎同步後所新增的運行配置數量,可以進行無影響的恢復。
恢復過程將是:將當前運行配置從活動Supervisor備份,故障切換到健康的備用Supervisor,將缺少的運行配置複製到新的活動,手動使以前的活動聯機,然後運行恢復工具。
1. 使用「copy running-config tftp:vdc-all」。 請注意,發生雙快閃記憶體故障時,由於系統重新載入為只讀而導致的配置更改不會出現在啟動配置中。您可以檢視受影響模組的「show system internal raid」,以確定第二個磁碟出現故障的時間,即系統以只讀方式運行的位置。從這裡您可以檢視每個VDC的「show accounting log」,以確定在雙快閃記憶體故障後進行了哪些更改,這樣您就知道重新載入後如果啟動配置繼續存在,該新增哪些內容。
請注意,在雙快閃記憶體故障的Supervisor重新載入時,啟動配置可能會被擦除,因此必須在外部備份配置。
2. 將運行配置從活動Supervisor複製出來後,最好將其與啟動配置進行比較,以檢視自上次儲存後發生了什麼變化。 可從「show startup-configuration」中看到這種情況。 不同之處當然完全取決於環境,但最好知道當備用裝置以活動狀態聯機時可能缺少什麼。 最好在記事本中複製這些差異,以便在切換後快速將其新增到新的活動Supervisor。
3. 評估差異之後,您需要執行管理引擎切換。 TAC建議在維護時段期間完成此操作,因為可能會發生不可預見的問題。 用於執行到備用裝置的故障切換的命令將是「系統切換」。
4. 切換應會很快進行,新的備用裝置將開始重新啟動。 在此期間,您需要將所有缺失的配置新增回新的活動配置。 這可以通過從TFTP伺服器複製配置(或以前儲存的任何位置),或者只在CLI中手動新增配置,不直接從tftp複製到運行配置,先複製到bootflash,再複製到運行配置。 在大多數情況下,缺少的配置非常短,而CLI選項是最可行的。
5. 一段時間後,新的備用管理引擎可能會以「ha-standby」狀態重新聯機,但通常會出現的情況是它將停滯在「powered-up」狀態。 可以使用「show module」命令並參考模組旁邊的「Status」列來檢視狀態。
如果新的備用裝置處於「通電」狀態,則需要手動使其重新聯機。 這可以通過發出以下命令來完成,其中「x」是停滯在「通電」狀態的備用模組:
(config)#服務外模組
(config)#no power off module x
如果您看到備用裝置一直停滯在通電狀態,並最終在上面的步驟之後保持電源循環,這可能是由於主用裝置重新載入備用裝置導致無法及時啟動所致。
這可能是因為啟動備用嘗試重新初始化其bootflash/RAID(可能需要10分鐘),但它在完成之前一直被活動狀態重置。
要解決此問題,請使用「x」對停留在通電狀態的備用插槽#進行以下配置:
(config)# system standby manual-boot
(config)# reload module x force-dnld
上述操作將使主用裝置不會自動重置備用裝置,然後重新載入備用裝置並強制其從主用裝置同步其映像。
等待10-15分鐘,檢視備用裝置是否最終能夠進入ha-standby狀態。處於ha-standby狀態後,使用以下命令重新啟用備用裝置的自動重新啟動:
(config)# system no standby manual-boot
6. 一旦備用磁碟以「ha-standby」狀態重新聯機,則需要運行恢復工具以確保恢復完成並修復活動磁碟上的單個磁碟故障。 可通過以下連結下載該工具:
https://software.cisco.com/download/release.html?mdfid=284472710&flowid=&softwareid=282088132&relind=AVAILABLE&rellifecycle=&reltype=latest
下載工具、解壓縮該工具並將其上傳到盒子的bootflash後,您需要執行以下命令開始恢復:
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
該工具將開始運行並檢測斷開連線的磁碟,並嘗試使用RAID陣列重新同步這些磁碟。
可以使用以下命令檢查恢復狀態:
# show system internal file /proc/mdstat
驗證恢復是否正在繼續,可能需要幾分鐘才能完全修復所有磁碟至[UU]狀態。操作中的恢復示例如下所示:
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
恢復完成後,應如下所示:
switch# show system internal file /proc/mdstat Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
所有磁碟都位於[UU]中後,RAID陣列將完全備份,同時同步兩個磁碟。
如果恢復工具無法恢復具有單個故障的當前活動,則嘗試另一個「系統切換」,確保當前待機處於「ha-standby」狀態。 如果仍無法成功,請聯絡Cisco TAC
案例I(1在主動發生故障,2在備用發生故障)
恢複方案:
1在活動狀態下失敗
2在待機時失敗
解決步驟:
在雙Supervisor場景中,主用Supervisor上有1個故障,備用Supervisor上有2個故障,因此可以執行無影響恢復,但在許多情況下可能需要重新載入。
此過程將首先備份所有正在運行的配置,然後嘗試使用恢復工具恢復主用上的故障快閃記憶體,如果成功,您將手動重新載入備用快閃記憶體並再次運行恢復工具。 如果初始恢復嘗試無法恢復活動上的失敗快閃記憶體,則必須與TAC聯絡,以嘗試使用debug外掛進行手動恢復。
1. 使用「copy running-config tftp:vdc-all」。 如果環境中未設定TFTP伺服器,您也可以將運行配置複製到本地USB盤中。
2. 備份當前的運行配置後,您需要運行恢復工具來嘗試恢復活動上的故障快閃記憶體。 可通過以下連結下載該工具:
下載工具、解壓縮該工具並將其上傳到盒子的bootflash後,您需要執行以下命令開始恢復:
# load bootflash:n7000-s2-flash-recovery-tool.10.0.2.gbin
該工具將開始運行並檢測斷開連線的磁碟,並嘗試使用RAID陣列重新同步這些磁碟。
可以使用以下命令檢查恢復狀態:
# show system internal file /proc/mdstat
驗證恢復是否正在繼續,可能需要幾分鐘才能完全修復所有磁碟至[UU]狀態。操作中的恢復示例如下所示:
switch# show system internal file /proc/mdstat \
Personalities : [raid1]
md6 : active raid1 sdd6[2] sdc6[0]
77888 blocks [2/1] [U_] <-- "U_" represents the broken state
resync=DELAYED
md5 : active raid1 sdd5[2] sdc5[0]
78400 blocks [2/1] [U_]
resync=DELAYED
md4 : active raid1 sdd4[2] sdc4[0]
39424 blocks [2/1] [U_]
resync=DELAYED
md3 : active raid1 sdd3[2] sdc3[0]
1802240 blocks [2/1] [U_]
[=>...................] recovery = 8.3% (151360/1802240) finish=2.1min s peed=12613K/sec
unused devices: <none>
恢復完成後,應如下所示:
switch# show system internal file /proc/mdstat
Personalities : [raid1]
md6 :active raid1 sdd6[1] sdc6[0]
77888 blocks [2/2] [UU] <-- "UU" represents the correct state
md5 :active raid1 sdd5[1] sdc5[0]
78400 blocks [2/2] [UU]
md4 :active raid1 sdd4[1] sdc4[0]
39424 blocks [2/2] [UU]
md3 :active raid1 sdd3[1] sdc3[0]
1802240 blocks [2/2] [UU]
unused devices: <none>
所有磁碟都位於[UU]中後,RAID陣列將完全備份,同時同步兩個磁碟。
3. 如果在步驟2中運行恢復工具後,您無法在活動Supervisor上恢復失敗的快閃記憶體,則必須聯絡TAC,嘗試使用linux調試外掛進行手動恢復。
4. 檢驗活動狀態下兩個閃爍均顯示為「[UU]」後,您可以繼續手動重新啟動待命Supervisor。 這可以通過發出以下命令來完成,其中「x」是停滯在「通電」狀態的備用模組:
(config)# out-of-service module x
(config)#no power off module x
這應該會使待命Supervisor回到「ha-standby」狀態(檢視「show module」輸出中的「Status」列可檢查此狀態)。 如果此操作成功,請繼續執行步驟6,如果不成功,請嘗試步驟5中概述的程式。
5. 如果您看到備用裝置一直停滯在通電狀態,並最終在上面的步驟之後保持電源循環,這可能是由於主用裝置重新載入備用裝置導致無法及時啟動所致。 這可能是因為啟動備用嘗試重新初始化其bootflash/RAID(可能需要10分鐘),但它在完成之前一直被活動狀態重置。 要解決此問題,請使用「x」對停留在通電狀態的備用插槽#進行以下配置:
(config)# system standby manual-boot
(config)# reload module x force-dnld
上述操作將使主用裝置不會自動重置備用裝置,然後重新載入備用裝置並強制其從主用裝置同步其映像。
等待10-15分鐘,檢視備用裝置是否最終能夠進入ha-standby狀態。處於ha-standby狀態後,使用以下命令重新啟用備用裝置的自動重新啟動:
(config)# system no standby manual-boot
6. 一旦備用裝置在「ha-standby」狀態下重新聯機,則需要運行恢復工具以確保恢復完成。 您可以為此步驟運行在活動狀態中的相同工具,無需額外下載,因為恢復工具在活動狀態和備用狀態下運行。
案例 J(2個在活動狀態下發生故障,2個在備用狀態下發生故障)
恢複方案:
2在活動時失敗
2在待機時失敗
解決步驟:
附註:在雙快閃記憶體發生故障時,通常會出現軟體「重新載入」不能完全恢復RAID,而且可能需要運行恢復工具或後續重新載入才能恢復。幾乎每次出現時,都通過物理重新拔插Supervisor模組解決了此問題。因此,如果可以對裝置進行物理訪問,請在外部備份配置之後,通過在準備重新載入裝置時重新物理地安裝Supervisor,嘗試快速恢復,這種恢復成功的可能性最大。這將完全斷開Supervisor的電源,並且應該允許恢復RAID中的兩個磁碟。如果物理重新拔插恢復只是部分恢復,請繼續執行步驟3;如果系統未完全啟動,則繼續執行步驟4。
摘要
常見問題
這個問題有沒有永久性的解決辦法?
請參見下面的長期解決方案部分。
為什麼無法通過重新載入備用Supervisor和故障轉移來恢復主用和備用上的雙故障轉移?
不能執行此操作的原因是,為了允許待命Supervisor進入「ha-standby」狀態,主用Supervisor必須向其快閃記憶體(SNMP資訊等)中寫入若干內容,如果它自身有雙快閃記憶體故障,則無法執行此操作。
如果快閃記憶體恢復工具無法重新裝載快閃記憶體,會發生什麼情況?
如需此案例中的選項,請聯絡Cisco TAC。
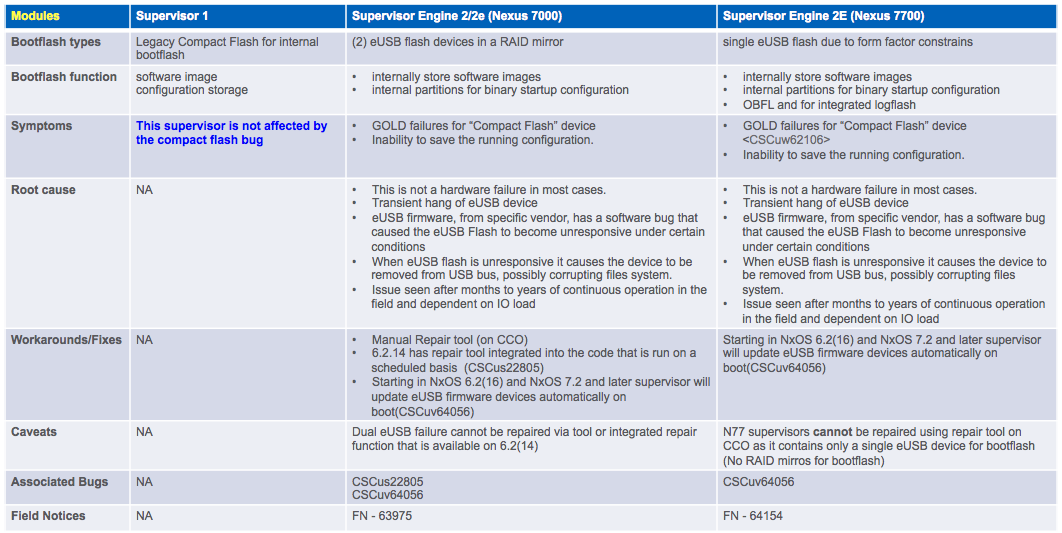
此錯誤是否也會影響Nexus 7700 Sup2E?
N7700 Sup2E - CSCuv64056有一個單獨的缺陷。 恢復工具對N7700不起作用。
恢復工具是否適用於NPE映像?
恢復工具不能用於NPE映像。
ISSU到已解析版本的代碼是否會解決此問題?
不能。ISSU將使用Supervisor切換,由於快閃記憶體故障,該切換可能無法正確執行。
重置受影響的主機板。Raid狀態顯示0xF0,但GOLD測試仍失敗?
在應用自動恢復後,主機板重置後會重置RAID狀態位。
但是,並非所有故障條件都能自動恢復。
如果RAID狀態位未列為[2/2] [UU],則恢復不完整。
按照列出的恢復步驟進行操作
快閃記憶體故障是否會影響操作?
不能,但是系統可能無法在電源故障時重新啟動。啟動配置也將丟失。
從客戶的角度而言,在監控和恢復方面,對於系統是否正常運行有什麼建議?
檢查GOLD compact test狀態是否有任何故障,並在第一個快閃記憶體部件出現故障後立即嘗試恢復。
是否可以通過將受影響代碼中的ISSU轉換為固定版本來修復發生故障的EUSB快閃記憶體故障?
ISSU無法修復出現故障的eUSB。最佳選擇是在sup上運行單個eusb故障的恢復工具,或在發生雙eusb故障時重新載入sup。
一旦問題得到糾正,則進行升級。針對CSCus22805的修復程式僅幫助更正單個eusb故障,它通過定期掃描系統並嘗試使用指令碼重新喚醒無法訪問的或只讀的eUSB來修復此問題。
Supervisor上同時出現兩個eusb快閃記憶體故障的情況很少見,因此這種解決方法是有效的。
如果使用外掛或重新載入修復快閃記憶體故障,問題重新出現需要多長時間?
通常情況下,正常運行時間較長。這不能精確量化,範圍可以是一年或更長。其底線是,在讀取寫入方面,eusb快閃記憶體上的壓力越大,系統進入此場景的概率就越高。
Show system internal raid在不同的部分顯示兩次快閃記憶體狀態。而且這些部分不一致
第一部分顯示當前狀態,第二部分顯示啟動狀態。
當前狀態是重要的,它應始終顯示為UU。
長期解決方案
此缺陷在6.2(14)中存在解決方法,但韌體修復已新增到6.2(16)和7.2(x)及更高版本。
建議升級到帶有韌體修復程式的版本,以完全解決此問題。
如果您無法升級到NXOS的固定版本,有兩種可能的解決方案。
解決方案1是每週使用計畫程式主動運行快閃記憶體恢復工具。 下列排程程式配置與bootflash中的快閃記憶體恢復工具:
功能排程器
排程程式作業名稱Flash_Job
copy bootflash:/n7000-s2-flash-recovery-tool.10.0.2.gbin bootflash:/flash_recovery_tool_copy
load bootflash:/flash_recovery_tool_copy
exit
scheduler schedule name Flash_Recovery
作業名稱Flash_Job
每週時間7
附註:
- 快閃記憶體恢復需要具有相同的名稱且位於bootflash中。
- 「time weekly 7」配置中的7表示一週中的一天,在本例中為星期六。
- 思科建議運行快閃記憶體恢復工具的最大頻率為每週一次。
解決方案2在以下技術說明連結中記錄
由思科工程師貢獻
- Austin PeacockCisco TAC工程師
 意見
意見