Ultra-M UCS 240M4伺服器中的主機板更換 — CPAR
下載選項
無偏見用語
本產品的文件集力求使用無偏見用語。針對本文件集的目的,無偏見係定義為未根據年齡、身心障礙、性別、種族身分、民族身分、性別傾向、社會經濟地位及交織性表示歧視的用語。由於本產品軟體使用者介面中硬式編碼的語言、根據 RFP 文件使用的語言,或引用第三方產品的語言,因此本文件中可能會出現例外狀況。深入瞭解思科如何使用包容性用語。
關於此翻譯
思科已使用電腦和人工技術翻譯本文件,讓全世界的使用者能夠以自己的語言理解支援內容。請注意,即使是最佳機器翻譯,也不如專業譯者翻譯的內容準確。Cisco Systems, Inc. 對這些翻譯的準確度概不負責,並建議一律查看原始英文文件(提供連結)。
目錄
簡介
本文檔介紹在Ultra-M設定中更換有故障的伺服器主機板所需的步驟。
此過程適用於使用NEWTON版本的Openstack環境,其中ESC不管理CPAR,而CPAR直接安裝在部署在Openstack上的VM上。
背景資訊
Ultra-M是經過預先打包和驗證的虛擬化移動資料包核心解決方案,旨在簡化VNF的部署。OpenStack是適用於Ultra-M的虛擬化基礎架構管理員(VIM),由以下節點型別組成:
- 計算
- 對象儲存磁碟 — 計算(OSD — 計算)
- 控制器
- OpenStack平台 — 導向器(OSPD)
Ultra-M的高級體系結構及涉及的元件如下圖所示:
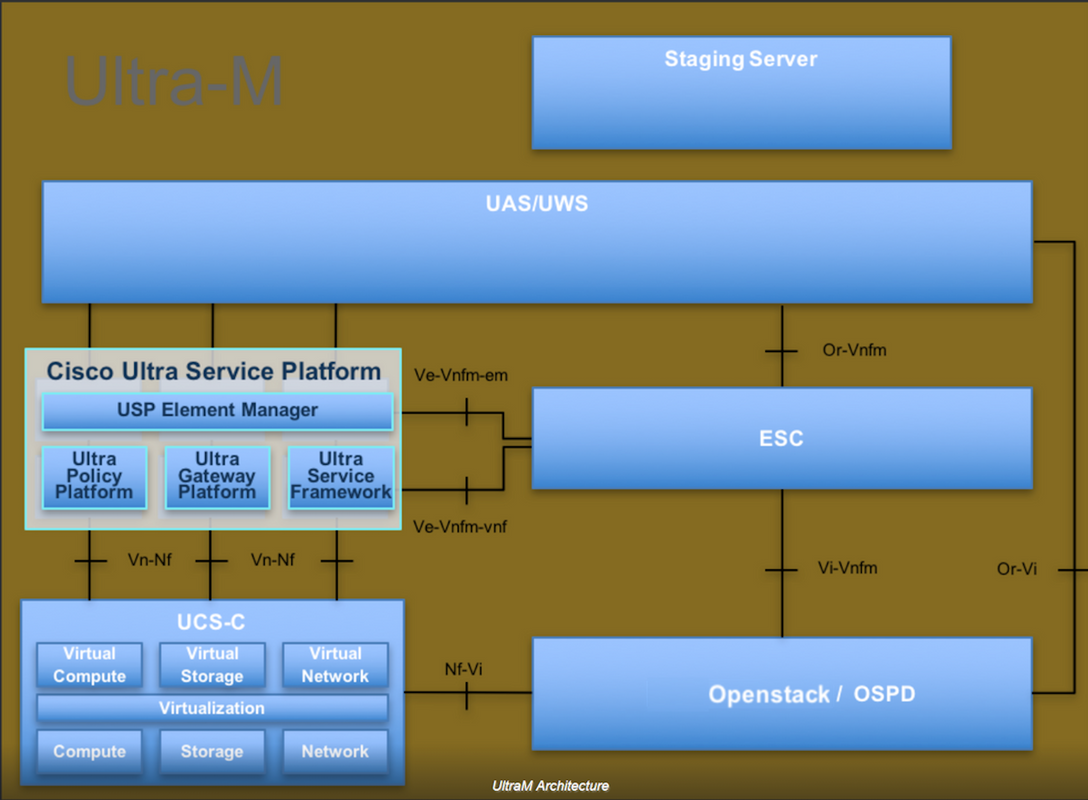
本文檔面向熟悉Cisco Ultra-M平台的思科人員,詳細說明了在OpenStack和Redhat作業系統上需要執行的步驟。
附註:Ultra M 5.1.x版本用於定義本文檔中的過程。
縮寫
| 澳門幣 | 程式方法 |
| OSD | 對象儲存磁碟 |
| OSPD | OpenStack平台導向器 |
| 硬碟 | 硬碟驅動器 |
| 固態硬碟 | 固態驅動器 |
| VIM | 虛擬基礎架構管理員 |
| 虛擬機器 | 虛擬機器 |
| EM | 元素管理器 |
| UAS | Ultra自動化服務 |
| UUID | 通用唯一識別符號 |
MoP的工作流程
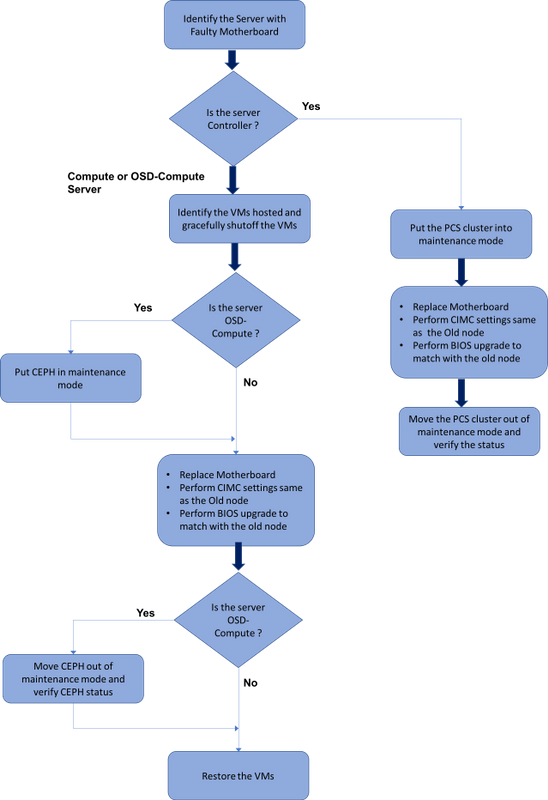
Ultra-M設定中的主機板更換
在Ultra-M設定中,在以下伺服器型別中可能需要更換主機板:計算、OSD計算和控制器。
附註:更換主機板後,會更換安裝有openstack的啟動盤。因此,無需將節點重新新增到超雲中。一旦伺服器在更換活動之後通電,它將自行註冊回重疊雲堆疊。
必要條件
在替換Compute節點之前,請務必檢查Red Hat OpenStack平台環境的當前狀態。建議您檢查當前狀態,以避免Compute替換過程處於開啟狀態時出現問題。通過這種更換流程可以實現這一點。
在進行恢復時,思科建議使用以下步驟備份OSPD資料庫:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
此過程可確保在不影響任何例項可用性的情況下替換節點。
附註:確保您擁有該例項的快照,以便在需要時恢復虛擬機器。按照以下步驟瞭解如何拍攝虛擬機器的快照。
計算節點中的主機板更換
在活動之前,託管在「計算」節點中的VM會正常關閉。更換主機板後,VM將恢復回來。
確定計算節點中託管的VM
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
附註:此處顯示的輸出中,第一列對應於通用唯一識別符號(UUID),第二列是VM名稱,第三列是存在VM的主機名。此輸出的引數在後續小節中使用。
備份:快照流程
步驟1. CPAR應用程式關閉。
步驟1.開啟連線到網路的任何ssh客戶端並連線到CPAR例項。
重要的一點是,不要同時關閉一個站點內的所有4個AAA例項,而要逐個關閉。
步驟2.使用以下命令關閉CPAR應用程式:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
如果使用者保持開啟的CLI會話,則arserver stop命令無法工作,並顯示以下消息:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
在此示例中,需要終止突出顯示的進程ID 2903,然後才能停止CPAR。如果是這種情況,請使用以下命令終止此流程:
kill -9 *process_id*
然後重複步驟1。
步驟3.通過發出以下命令驗證CPAR應用程式確實已關閉:
/opt/CSCOar/bin/arstatus
應顯示以下消息:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VM快照任務
步驟1.輸入與當前正在處理的站點(城市)對應的Horizon GUI網站。
訪問Horizon時,出現以下螢幕:
步驟2.導覽至專案>例項,如下圖所示。
如果使用的是CPAR,則此選單中只顯示4個AAA例項。
步驟3.一次僅關閉一個例項,請重複本文檔中的整個過程。
要關閉VM,請導航到操作>關閉例項並確認選擇。

步驟4.通過檢查Status = Shutoff和Power State = Shut Down來驗證例項確實已關閉。
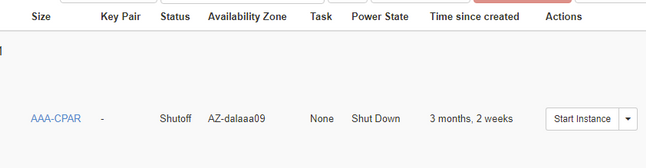
此步驟結束CPAR關閉過程。
虛擬機器快照
一旦CPAR VM關閉,可以並行拍攝快照,因為它們屬於獨立的計算。
將並行建立四個QCOW2檔案。
獲取每個AAA例項的快照(25分鐘–1小時)(使用qcow映像作為源的例項為25分鐘,使用原始映像作為源的例項為1小時)
步驟1.登入POD的Openstack的地平線GUI。
步驟2.登入後,進入頂部選單上的Project > Compute > Instances部分並查詢AAA例項。
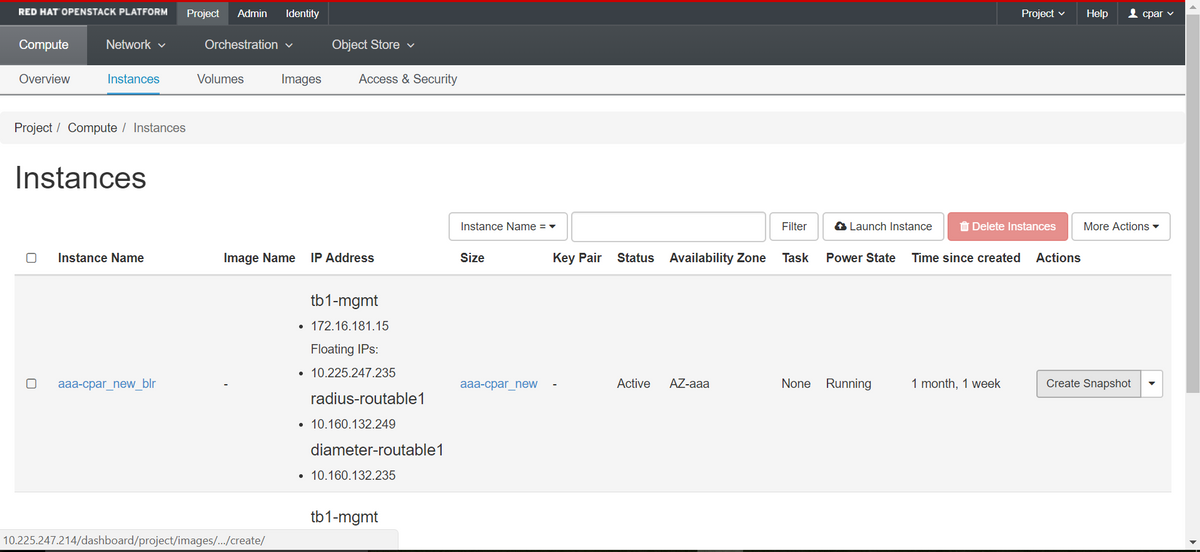
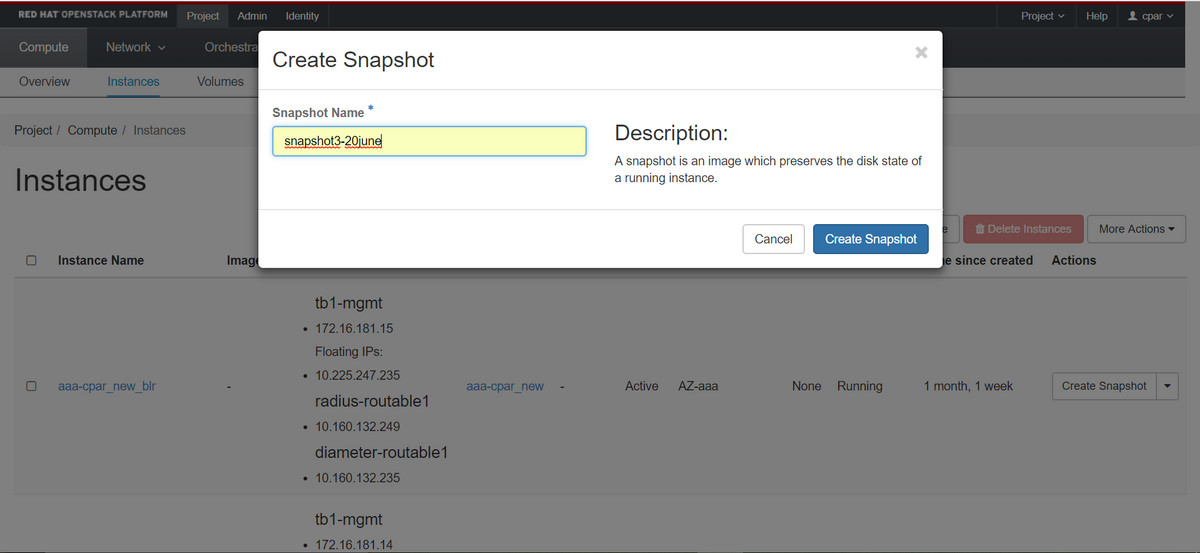
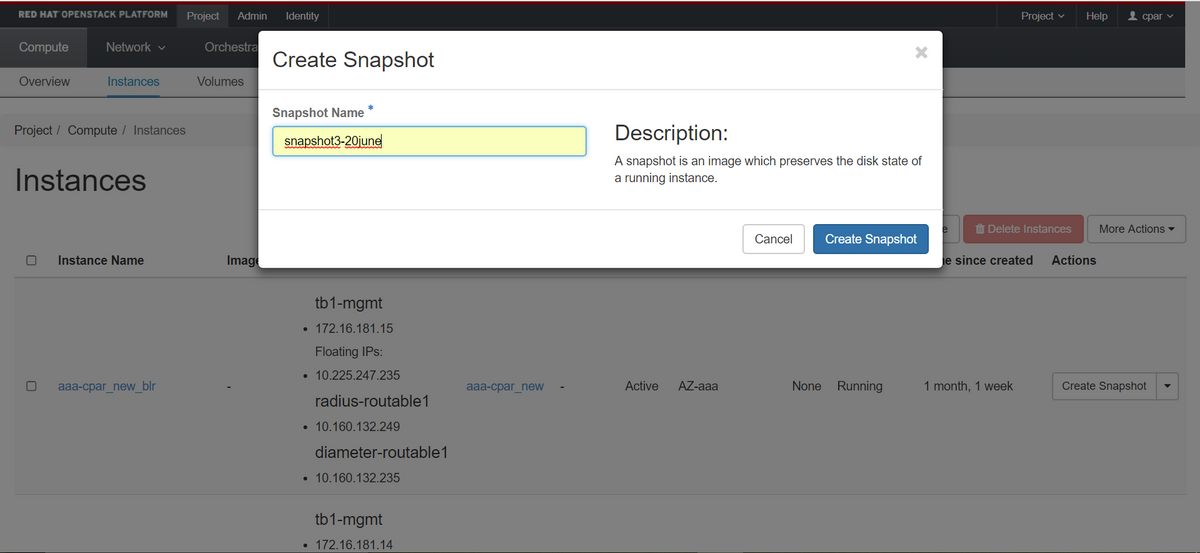
步驟3.按一下Create Snapshot按鈕繼續建立快照(需要在相應的AAA例項上執行該操作)。
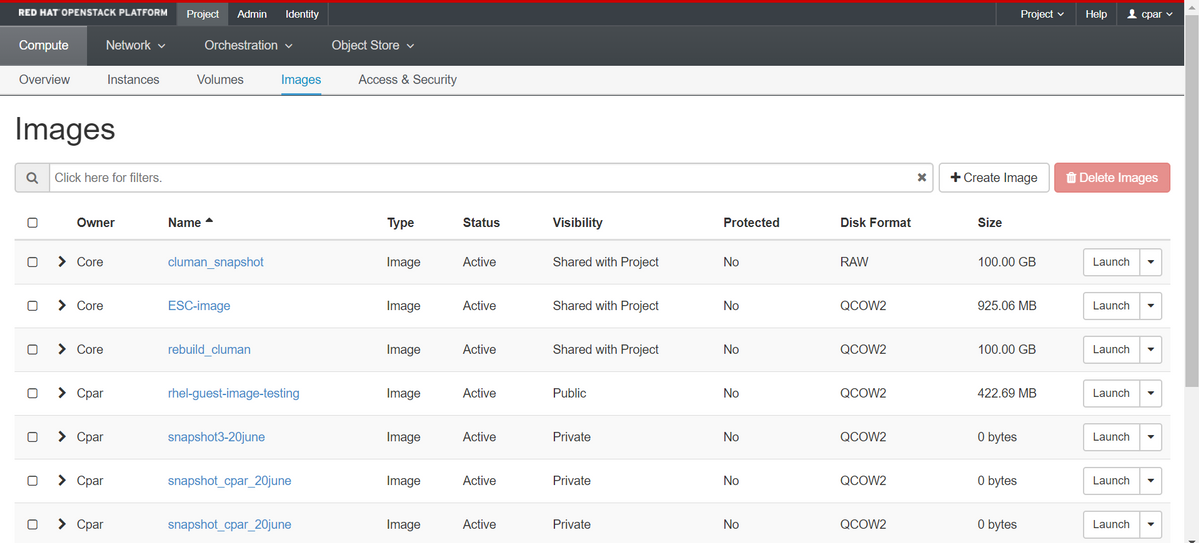
步驟4.運行快照後,導航到IMAGES選單,驗證是否全部完成,並報告沒有問題。
步驟5.下一步是以QCOW2格式下載快照,並將其傳輸到遠端實體,以防OSPD在此過程中丟失。為此,請在OSPD級別使用此命令glance image-list標識快照。
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
步驟6.確定要下載的快照後(本例中為以上綠色標籤的快照),使用命令glance image-download以QCOW2格式下載該快照,如下所示。
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- 「&」將進程傳送到後台。完成此操作需要一些時間,一旦完成,映像就可以位於/tmp目錄中。
- 將進程傳送到後台時,如果連線丟失,則進程也會停止。
- 執行命令「disown -h」,以便在SSH連線丟失的情況下,該進程仍在OSPD上運行並完成。
步驟7.下載過程完成後,需要執行壓縮過程,因為作業系統處理的過程、任務和臨時檔案可能使ZEROES填充該快照。用於檔案壓縮的命令是virt-sparsify。
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
此過程需要一些時間(大約10-15分鐘)。 完成後,生成的檔案就是下一步中指定的需要傳輸到外部實體的檔案。
需要驗證檔案完整性,為了實現這一目的,請執行下一個命令,並在輸出結束時查詢「已損壞」屬性。
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
為了避免丟失OSPD的問題,需要將最近在QCOW2格式上建立的快照轉移到外部實體。在開始檔案傳輸之前,我們必須檢查目標是否有足夠的可用磁碟空間,使用命令「df -kh」驗證記憶體空間。我們的建議是通過使用SFTP「sftproot@x.x.x.x」(其中x.x.x.x是遠端OSPD的IP)將其暫時傳輸到另一個站點的OSPD。為了加快傳輸速度,可以將目標傳送到多個OSPD。同樣,我們可以使用以下命令scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp(其中x.x.x.x是遠端OSPD的IP)將檔案傳輸到另一個OSPD。
正常斷電
關閉節點電源
- 要關閉例項電源,請執行以下操作:nova stop <INSTANCE_NAME>
- 現在您會看到處於關閉狀態的例項名稱。
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
更換主機板
有關更換UCS C240 M4伺服器中主機板的步驟,請參閱Cisco UCS C240 M4伺服器安裝和服務指南
- 使用CIMC IP登入到伺服器。
- 如果韌體與以前使用的推薦版本不一致,請執行BIOS升級。此處提供了BIOS升級步驟:Cisco UCS C系列機架式伺服器BIOS升級指南
恢復虛擬機器
通過快照恢復例項
恢復過程
可以使用前面步驟中拍攝的快照重新部署以前的例項。
步驟1 [可選]。如果沒有以前的VMsnapshot可用,則連線到傳送備份的OSPD節點,並將備份轉換回其原始OSPD節點。使用「sftproot@x.x.x.x」,其中x.x.x.x是原始OSPD的IP。將快照檔案儲存在/tmp目錄中。
步驟2.連線到重新部署例項的OSPD節點。
 使用以下命令獲取環境變數:
使用以下命令獲取環境變數:
# source /home/stack/pod1-stackrc-Core-CPAR
步驟3.要將快照用作影象,必須將其上傳到水平面。使用下一個命令執行此操作。
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
這一過程可以從地平線看到。

步驟4.在Horizon中,導航到Project > Instances,然後按一下Launch Instance。

步驟5.填寫例項名稱並選擇可用區域。
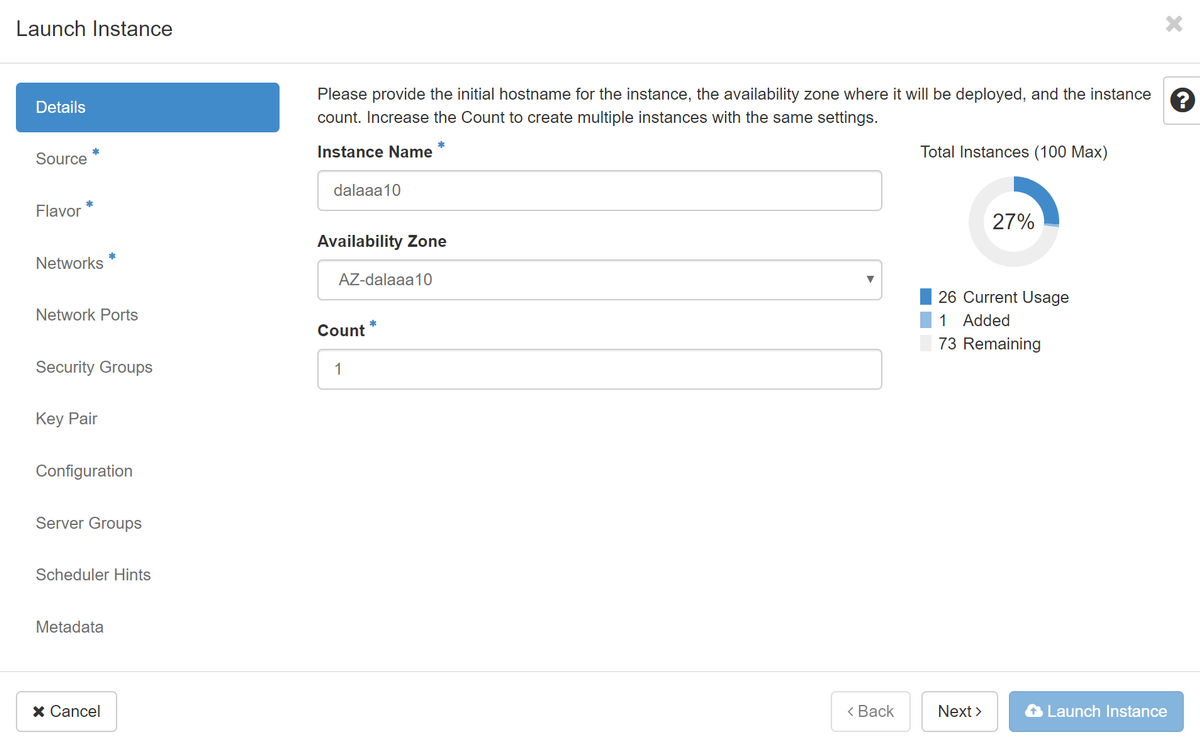
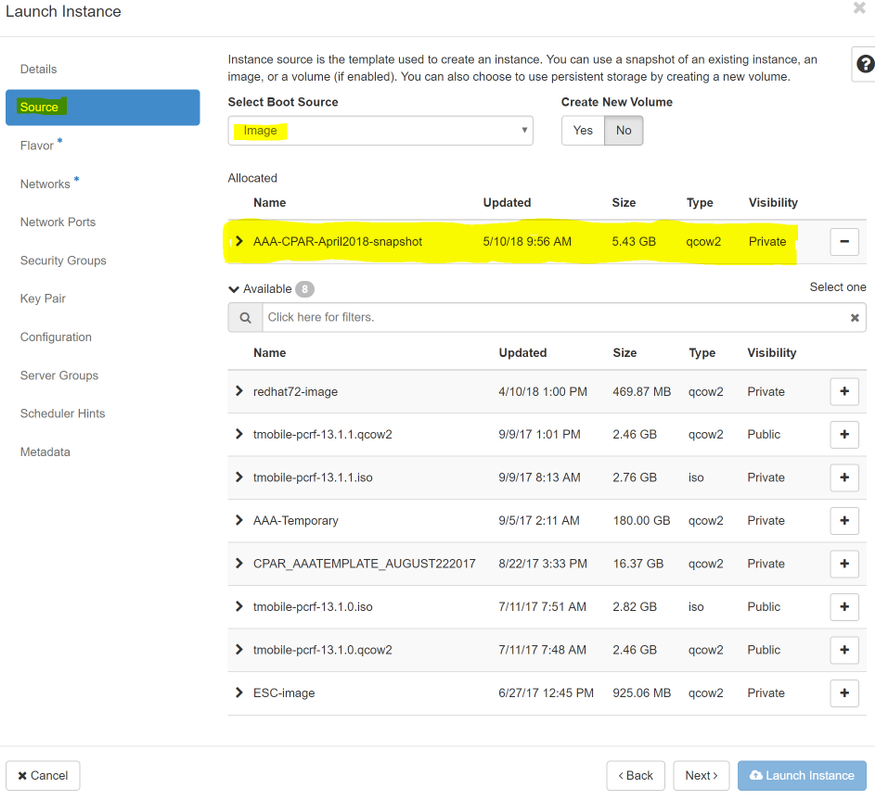
步驟6.在「Source」頁籤中,選擇建立例項的影象。在「選擇啟動源」選單中,選擇image,此處顯示映像清單,選擇之前上傳的映像,然後按一下+sign。
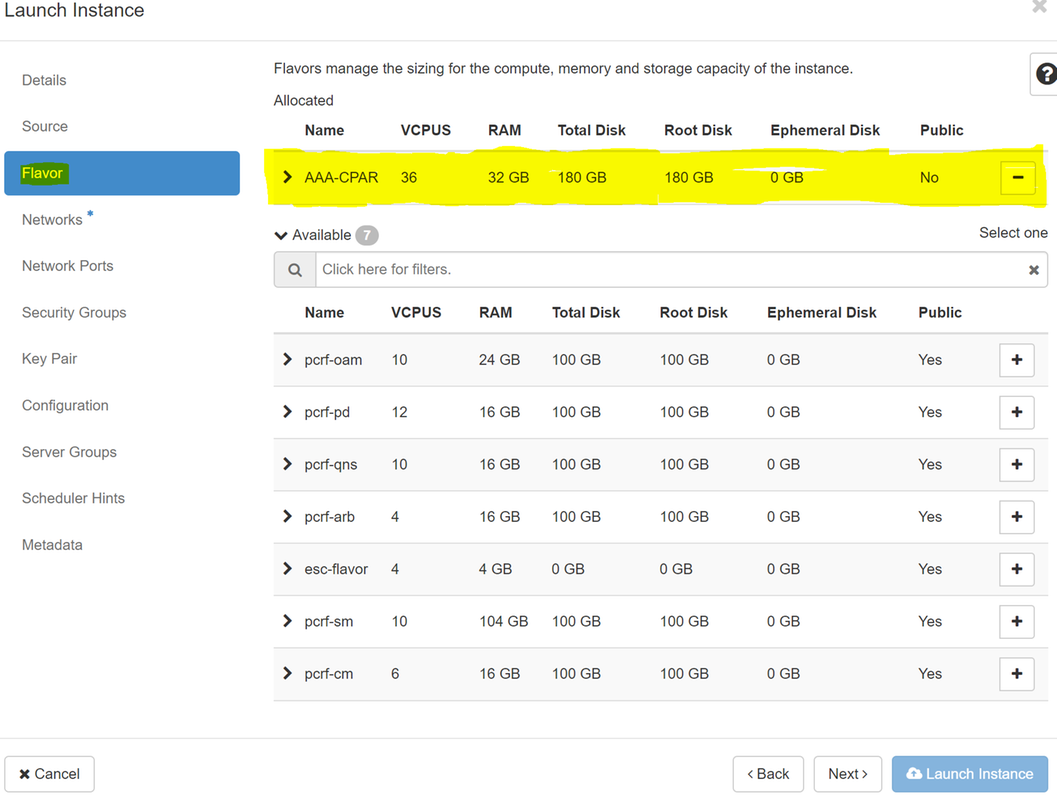
步驟7.在Flavor頁籤中,按一下+符號時選擇AAA調味。
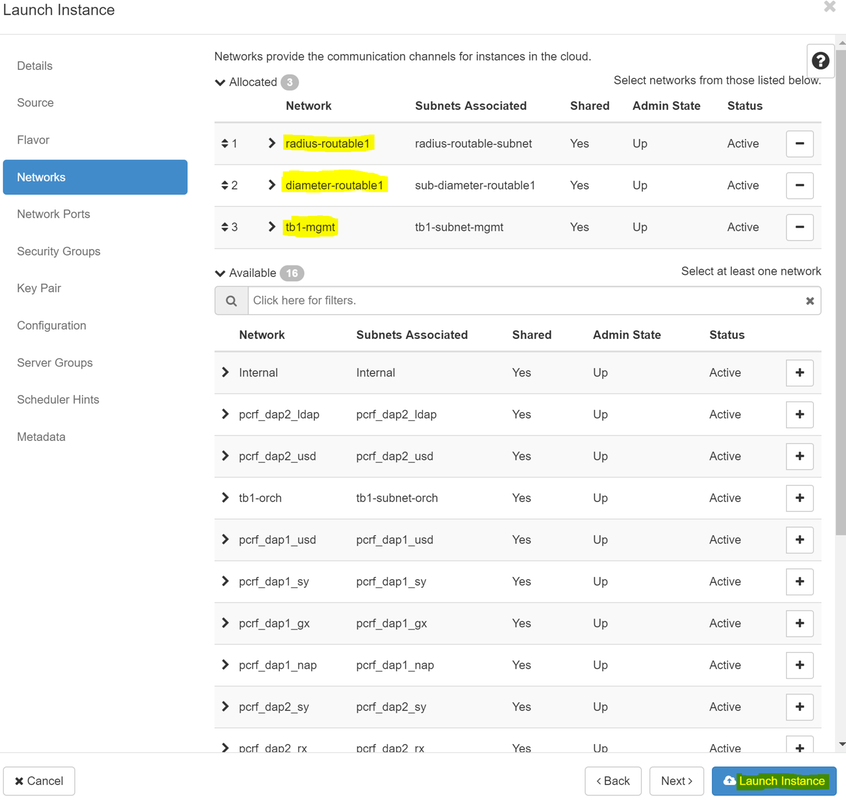
步驟8.最後,導航到network頁籤,然後在點選+符號時選擇例項需要的網路。在本例中,選擇diameter-soutable1、radius-routable1和tb1-mgmt。
步驟9.最後,按一下Launch例項建立該例項。可以在Horizon中監控進度:
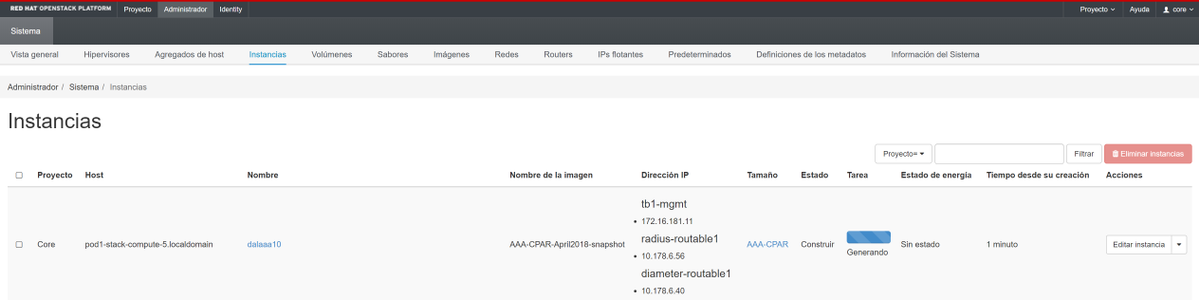
幾分鐘後,該例項完全部署並可供使用。

建立和分配浮動IP地址
浮動IP地址是可路由地址,這意味著可以從Ultra M/Openstack體系結構外部訪問它,並且能夠與網路中的其他節點通訊。
步驟1。在Horizon頂部選單中,導航到Admin > Floating IPs。
步驟2.按一下AllocateIP to Project按鈕。
步驟3.在Allocate Floating IP視窗中,選擇新的浮動IP所屬的Pools、它將被分配到的專案以及newFloating IP 地址本身。
例如:
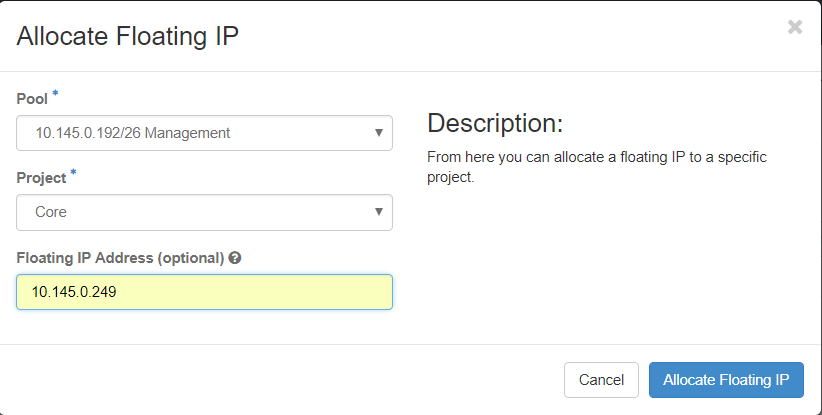
步驟4.按一下AllocateFloating IPbutton。
步驟5.在「展望期」頂部選單中,導航至「專案」>「例項」。
步驟6.在Actioncolumn中,按一下「建立快照」(Create Snapshotbutton)按鈕中指向下的箭頭,將顯示選單。選擇關聯浮動IP選項。
步驟7.選擇要在IP地址欄位中使用的相應浮動IP地址,然後從要在要關聯的埠中分配此浮動IP的新例項中選擇相應的管理介面(eth0)。請參考下一張影象作為此過程的示例。
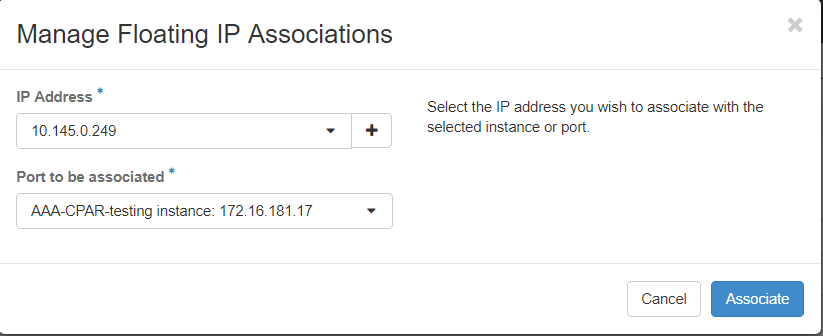
步驟8.最後,按一下onAssociatebutton。
啟用SSH
步驟1.在「水準」頂部選單中,導航到「專案」>「例項」。
步驟2.按一下sectionCunch a new instance中建立的例項/VM的名稱。
步驟3.按一下Console頁籤。這將顯示VM的命令列介面。
步驟4.顯示CLI後,輸入適當的登入憑證:
使用者名稱:root
密碼:cisco123
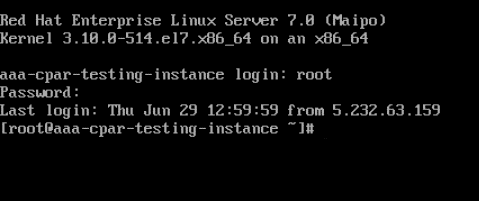
步驟5.在CLI中輸入命令dvi /etc/ssh/sshd_configto edit ssh配置。
步驟6.開啟ssh配置檔案後,按Ito編輯該檔案。然後查詢下面顯示的部分,並將第一行從PasswordAuthentication更改為PasswordAuthentication yes。

步驟7.按ESC並輸入:wq!以儲存sshd_config檔案更改。
步驟8.執行commandservice sshd restart。
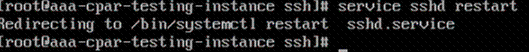
步驟9.為了測試已正確應用SSH配置更改,請開啟任何SSH客戶端,並嘗試使用分配給例項的浮動IP(即10.145.0.249)和userroot建立遠端安全連接。
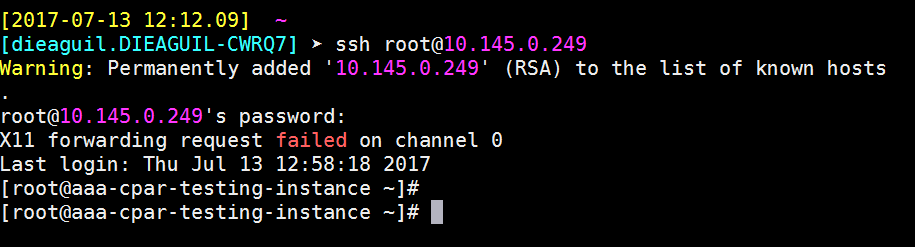
建立SSH會話
使用安裝應用程式的相應VM/伺服器的IP地址開啟SSH會話。

CPAR例項啟動
一旦活動完成並且可以在關閉的站點中重新建立CPAR服務,請按照以下步驟操作。
- 要重新登入到Horizon,請導航到專案>例項>啟動例項。
- 驗證例項的狀態是否為「active(活動)」 ,電源狀態是否為「running(運行)」 :
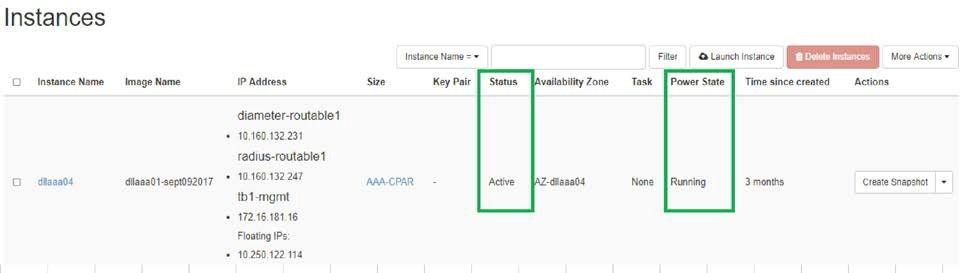
活動後運行狀況檢查
步驟1.在作業系統級別執行命令/opt/CSCOar/bin/arstatus。
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
步驟2.在作業系統級別執行命令/opt/CSCOar/bin/aregcmd,然後輸入管理員憑據。驗證CPAR Health(CPAR運行狀況)為10(滿分10)並退出CPAR CLI。
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
步驟3.運行命令netstat | grep diameter並驗證所有DRA連線是否已建立。
下面提到的輸出適用於預期存在Diameter連結的環境。如果顯示的連結較少,則表示與需要分析的DRA斷開連線。
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
步驟4.檢查TPS日誌是否顯示CPAR正在處理的請求。突出顯示的值代表了TPS,而那些值是我們需要注意的。
TPS的值不應超過1500。
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
步驟5.在name_radius_1_log中查詢任何「錯誤」或「警報」消息
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
步驟6.通過發出以下命令驗證CPAR進程使用的記憶體量:
頂端 | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
此突出顯示的值應小於:7Gb,這是應用級別允許的最大容量。
OSD計算節點中的主機板更換
在活動之前,Compute節點中託管的VM將正常關閉,CEPH將進入維護模式。更換主機板後,VM會恢復回來,CEPH會移出維護模式。
確定Osd-Compute節點中託管的VM
確定OSD計算伺服器上託管的VM。
[stack@director ~]$ nova list --field name,host | grep osd-compute-0 | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
備份:快照流程
CPAR應用關閉
步驟1.開啟連線到網路的任何ssh客戶端並連線到CPAR例項。
重要的一點是,不要同時關閉一個站點內的所有4個AAA例項,而要逐個關閉。
步驟2.使用以下命令關閉CPAR應用程式:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
附註:如果使用者保持開啟的CLI會話,則arserver stop命令將無效,並顯示以下消息:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
在此示例中,需要終止突出顯示的進程ID 2903,然後才能停止CPAR。如果是這種情況,請使用以下命令終止此流程:
kill -9 *process_id*
然後重複步驟1。
步驟3.使用以下命令驗證CPAR應用確實已關閉:
/opt/CSCOar/bin/arstatus
將顯示以下消息:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VM快照任務
步驟1.輸入與當前正在處理的站點(城市)對應的Horizon GUI網站。
訪問「水平面」時,將看到以下影象:
步驟2.導覽至專案>例項,如下圖所示。
如果使用的是CPAR,則此選單中只顯示4個AAA例項。
步驟3.一次僅關閉一個例項,請重複本文檔中的整個過程。
要關閉VM,請導航到操作>關閉例項並確認您的選擇。

步驟4.通過檢查Status = Shutoff和Power State = Shut Down來驗證例項確實已關閉。
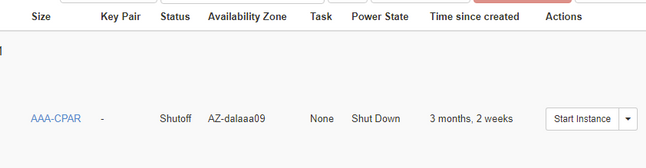
此步驟結束CPAR關閉過程。
虛擬機器快照
一旦CPAR VM關閉,可以並行拍攝快照,因為它們屬於獨立的計算。
四個QCOW2檔案是並行建立的。
獲取每個AAA例項的快照(25分鐘–1小時)(使用qcow映像作為源的例項為25分鐘,使用原始映像作為源的例項為1小時)
步驟1.登入POD的Openstack的HorizonGUI。
步驟2.登入後,進入頂部選單上的Project > Compute > Instances部分並查詢AAA例項。
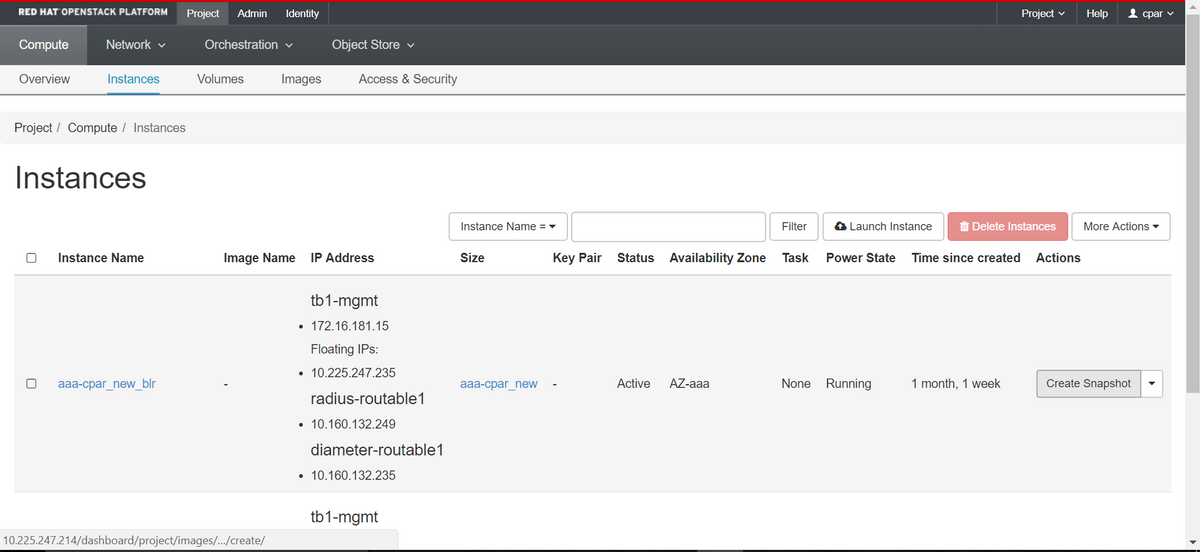
步驟3.按一下Create Snapshot按鈕繼續建立快照(需要在相應的AAA例項上執行該操作)。
步驟4.運行快照後,導航到IMAGES選單,驗證是否全部完成,並報告沒有問題。
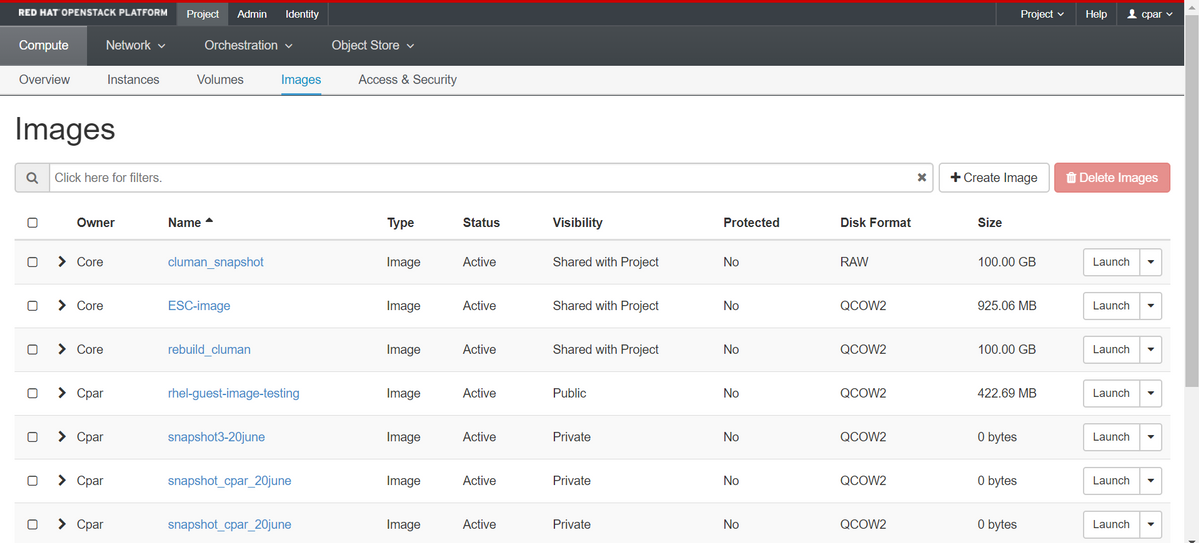
步驟5.下一步是以QCOW2格式下載快照,並將其傳輸到遠端實體,以防OSPD在此過程中丟失。為此,請在OSPD級別使用此命令glance image-list標識快照。
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
步驟6.確定要下載的快照後(本例中為以上綠色標籤的快照),現在使用此命令glance image-download以QCOW2格式下載該快照,如下所示。
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- 「&」將進程傳送到後台。完成此操作需要一些時間,一旦完成,映像就可以位於/tmp目錄中。
- 將進程傳送到後台時,如果連線丟失,則進程也會停止。
- 執行命令「disown -h」,以便在SSH連線丟失的情況下,該進程仍在OSPD上運行並完成。
7.下載過程完成後,需要執行壓縮過程,因為作業系統處理的進程、任務和臨時檔案可能使ZEROES填充該快照。用於檔案壓縮的命令是virt-sparsify。
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
此過程需要一些時間(大約10-15分鐘)。 完成後,生成的檔案就是下一步中指定的需要傳輸到外部實體的檔案。
需要驗證檔案完整性,為了做到這一點,請運行下一個命令,並在輸出末尾查詢「corrupt」屬性。
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
為了避免丟失OSPD的問題,需要將最近在QCOW2格式上建立的快照轉移到外部實體。在開始檔案傳輸之前,我們必須檢查目標是否有足夠的可用磁碟空間,使用命令「df -kh」驗證記憶體空間。我們的建議是通過使用SFTP「sftproot@x.x.x.x」(其中x.x.x.x是遠端OSPD的IP)將其暫時傳輸到另一個站點的OSPD。為了加快傳輸速度,可以將目標傳送到多個OSPD。同樣,我們可以使用以下命令scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp(其中x.x.x.x是遠端OSPD的IP)將檔案傳輸到另一個OSPD。
將CEPH置於維護模式
步驟1.驗證伺服器中的ceph osd樹狀態是否為up
[heat-admin@pod2-stack-osd-compute-0 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod2-stack-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod2-stack-osd-compute-1
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod2-stack-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
步驟2.登入到OSD Compute節點,並將CEPH置於維護模式。
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e79: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v22844323: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3858 kB/s wr, 0 op/s rd, 546 op/s wr
附註:刪除CEPH後,VNF HD RAID進入「已降級」狀態,但hd-disk必須仍然可以訪問
正常斷電
關閉節點電源
- 要關閉例項電源,請執行以下操作:nova stop <INSTANCE_NAME>
- 您會看到處於關閉狀態的例項名稱。
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
更換主機板
有關更換UCS C240 M4伺服器中主機板的步驟,請參閱Cisco UCS C240 M4伺服器安裝和服務指南
- 使用CIMC IP登入到伺服器。
- 如果韌體與以前使用的推薦版本不一致,請執行BIOS升級。此處提供了BIOS升級步驟:Cisco UCS C系列機架式伺服器BIOS升級指南
將CEPH移出維護模式
登入到OSD Compute節點並將CEPH移出維護模式。
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e81: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v22844355: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3658 kB/s wr, 0 op/s rd, 502 op/s wr
恢復虛擬機器
通過快照恢復例項
恢復過程:
可以使用前面步驟中拍攝的快照重新部署以前的例項。
步驟1 [可選]。如果沒有以前的VMsnapshot可用,則連線到傳送備份的OSPD節點,並將備份轉換回其原始OSPD節點。使用「sftproot@x.x.x.x」,其中x.x.x.x是原始OSPD的IP。將快照檔案儲存在/tmp目錄中。
步驟2.連線到重新部署例項的OSPD節點。

使用以下命令獲取環境變數:
# source /home/stack/pod1-stackrc-Core-CPAR
步驟3.要將快照用作影象,必須將其上傳到水平面。使用下一個命令執行此操作。
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
這一過程可以從地平線看到。

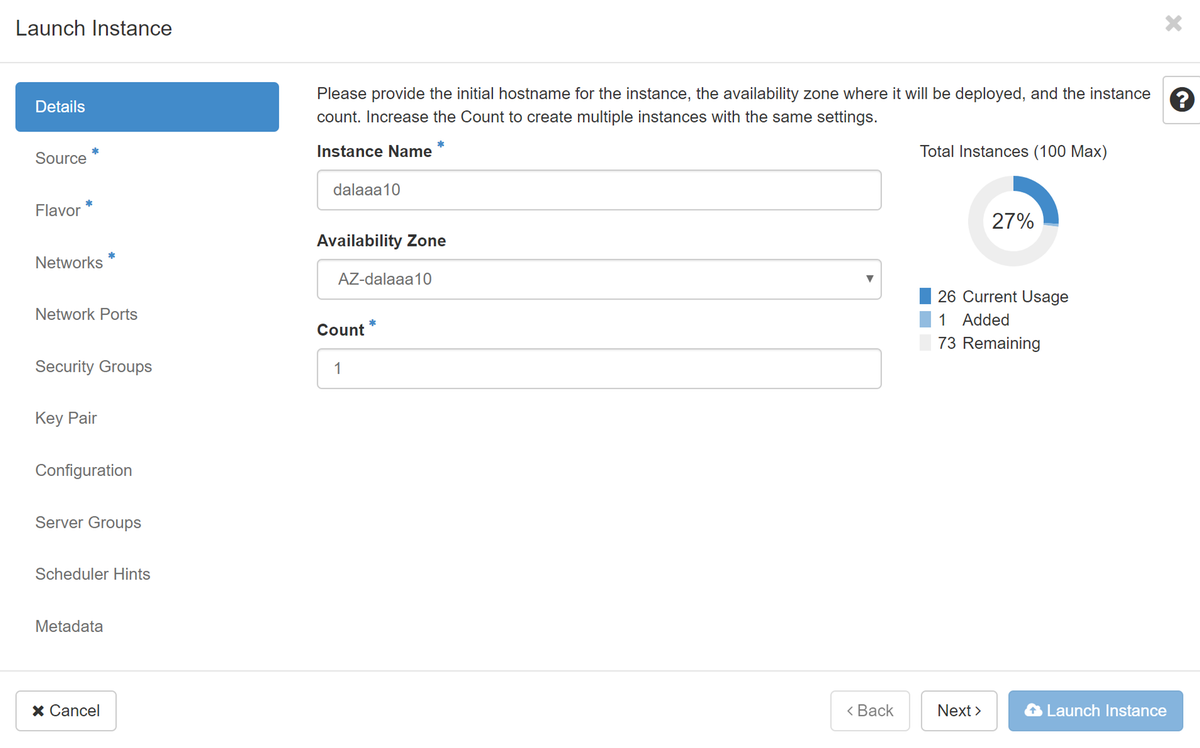
步驟4.在Horizon中,導航到Project > Instances,然後按一下Launch Instance。

步驟5.填寫例項名稱並選擇可用區域。
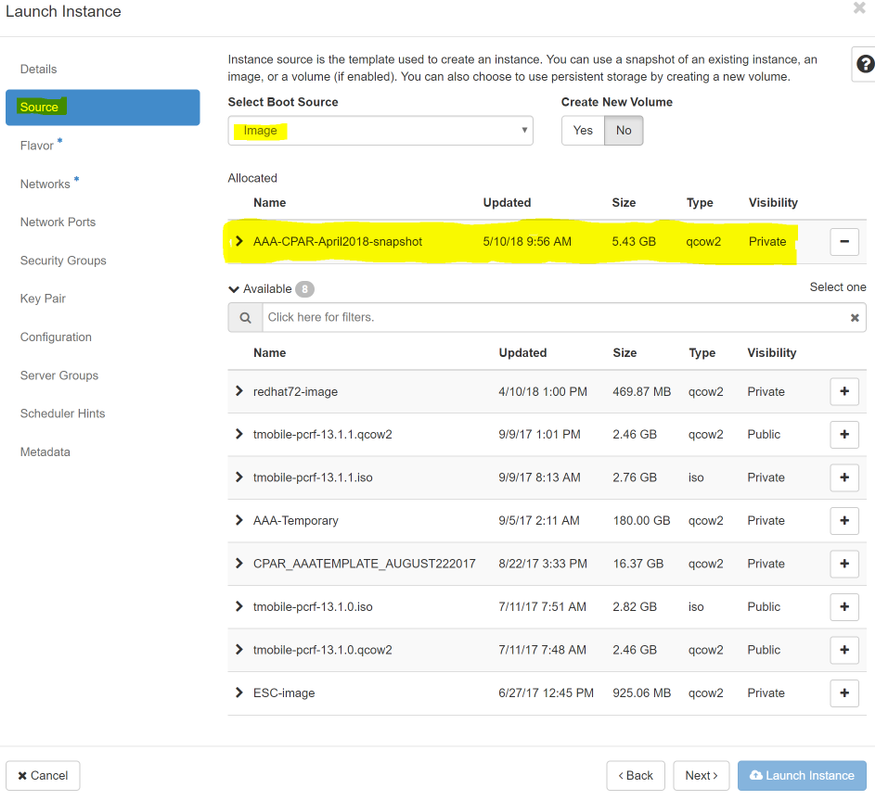
步驟6.在「源」頁籤中,選擇建立例項的影象。在「選擇啟動源」選單中,選擇image,此處顯示映像清單,選擇之前上傳的映像,然後按一下+sign。
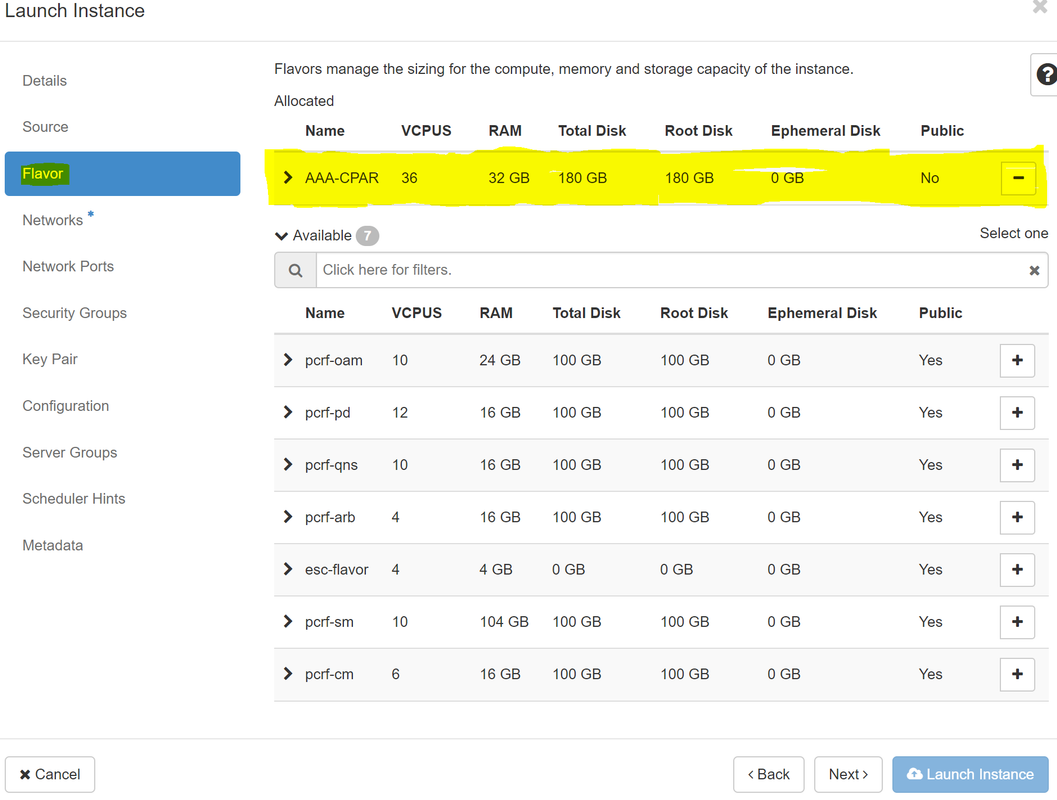
步驟7.在Flavor頁籤中,按一下+符號時選擇AAA調味。
步驟8.最後,導航到network頁籤,然後在點選+號時選擇例項需要的網路。在本例中,選擇diameter-soutable1、radius-routable1和tb1-mgmt。
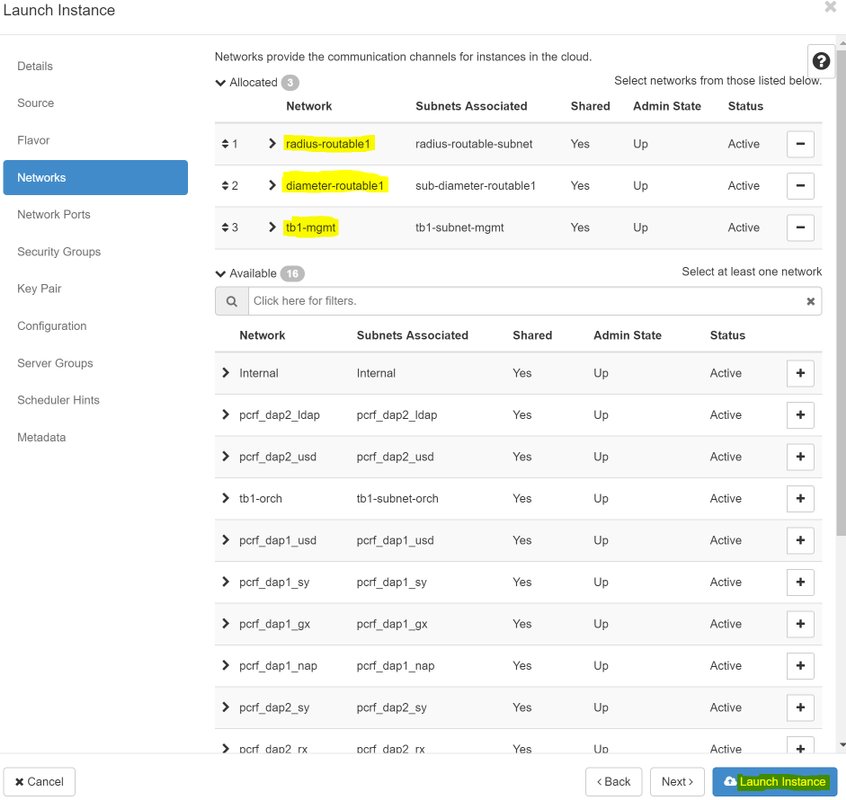
步驟9.最後,按一下Launch例項建立該例項。可以在Horizon中監控進度:
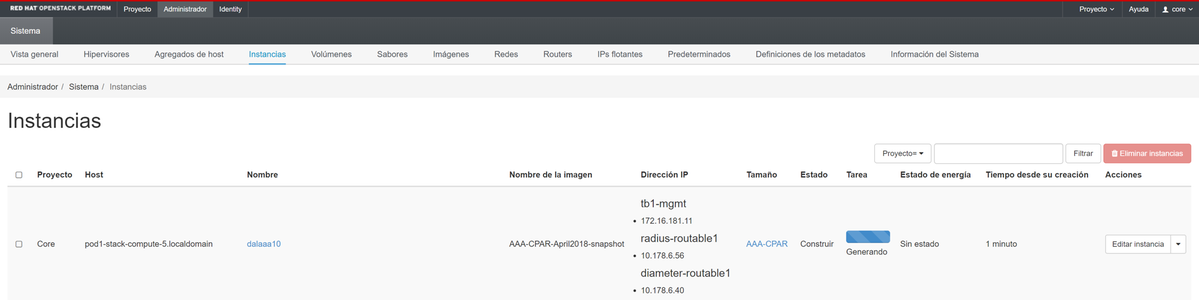
幾分鐘後,該例項完全部署並可供使用。

建立和分配浮動IP地址
浮動IP地址是可路由地址,這意味著可以從Ultra M/Openstack體系結構外部訪問它,並且能夠與網路中的其他節點通訊。
步驟1。在Horizon頂部選單中,導航到Admin > Floating IPs。
步驟2.按一下AllocateIP to Project按鈕。
步驟3.在Allocate Floating IP視窗中,選擇新的浮動IP所屬的Pools、它將被分配到的專案以及newFloating IP 地址本身。
例如:
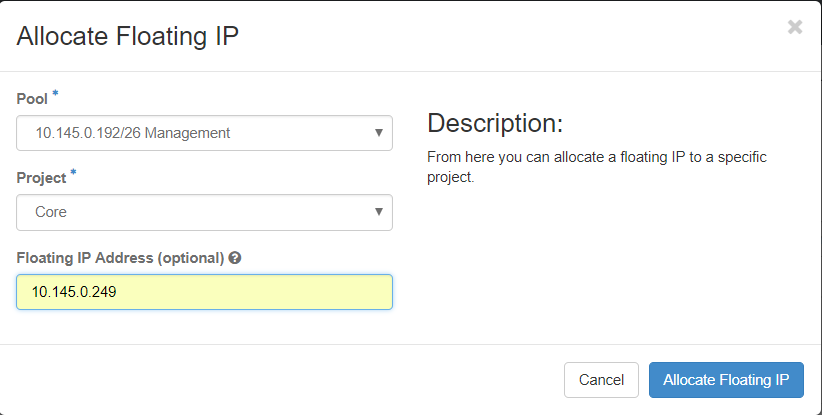
步驟4.按一下AllocateFloating IPbutton。
步驟5.在「展望期」頂部選單中,導航至「專案」>「例項」。
步驟6.在Actioncolumn中,按一下「建立快照」(Create Snapshotbutton)按鈕中指向下的箭頭,將顯示選單。選擇關聯浮動IP選項。
步驟7.選擇要在IP地址欄位中使用的相應浮動IP地址,然後從要在要關聯的埠中分配此浮動IP的新例項中選擇相應的管理介面(eth0)。請參考下一張影象作為此過程的示例。
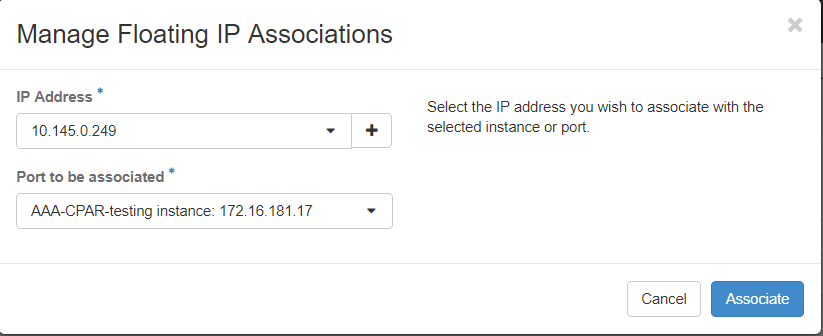
步驟8.最後,按一下Associatebutton。
啟用SSH
步驟1.在「水準」頂部選單中,導航到「專案」>「例項」。
步驟2.按一下sectionCunch a new instance中建立的例項/VM的名稱。
步驟3.按一下Console頁籤。這將顯示VM的CLI。
步驟4.顯示CLI後,輸入正確的登入憑證:
使用者名稱:root
密碼:cisco123
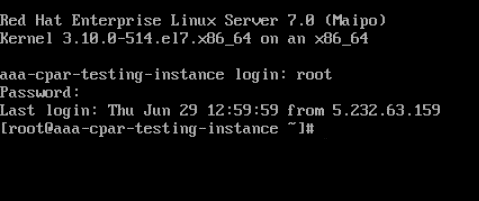
步驟5.在CLI中輸入命令dvi /etc/ssh/sshd_configto edit ssh配置。
步驟6.開啟ssh配置檔案後,按Ito編輯該檔案。然後查詢此處顯示的部分,並將第一行從PasswordAuthentication更改為PasswordAuthentication yes。

步驟7.按ESC並輸入:wq!以儲存sshd_config檔案更改。
步驟8.運行commandservice sshd restart。
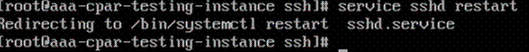
步驟9.為了測試已正確應用SSH配置更改,請開啟任何SSH客戶端,並嘗試使用分配給例項的浮動IP(即10.145.0.249)和userroot建立遠端安全連接。
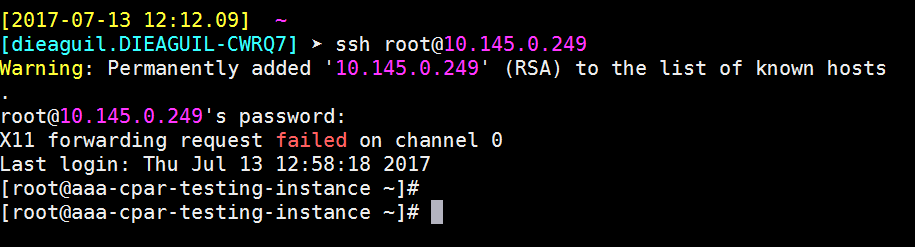
建立SSH會話
使用安裝應用程式的相應VM/伺服器的IP地址開啟SSH會話。

CPAR例項啟動
一旦活動完成並且可以在關閉的站點中重新建立CPAR服務,請遵循以下步驟。
- 返回水平面,導航到專案>例項>啟動例項。
- 驗證例項的狀態是否為「active(活動)」 ,電源狀態是否為「running(運行)」 :
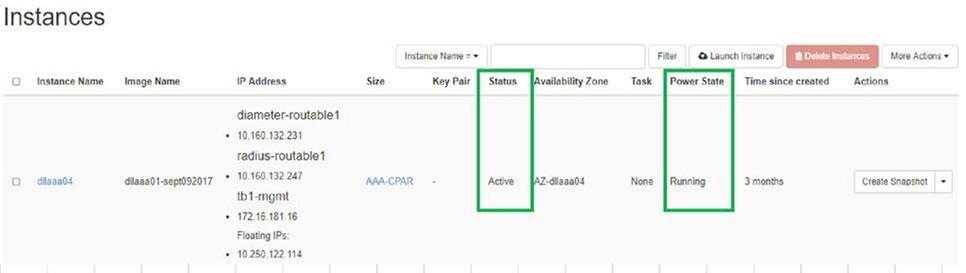
活動後運行狀況檢查
步驟1.在OS級別運行命令/opt/CSCOar/bin/arstatus。
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
步驟2.在作業系統級別運行命令/opt/CSCOar/bin/aregcmd,然後輸入管理員憑據。驗證CPAR Health(CPAR運行狀況)為10(滿分10)並退出CPAR CLI。
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
步驟3.運行命令netstat | grep diameter並驗證所有DRA連線是否已建立。
此處提到的輸出適用於預期存在Diameter連結的環境。如果顯示的連結較少,則表示與需要分析的DRA斷開連線。
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
步驟4.檢查TPS日誌是否顯示CPAR正在處理的請求。突出顯示的值代表了TPS,而那些值是我們需要注意的。
TPS的值不應超過1500。
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
步驟5.在name_radius_1_log中查詢任何「錯誤」或「警報」消息
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
步驟6.使用以下命令驗證CPAR進程使用的記憶體量:
頂端 | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
此突出顯示的值應小於:7Gb,這是應用級別允許的最大容量。
控制器節點中的主機板更換
驗證控制器狀態並將群集置於維護模式
在OSPD中,登入到控制器並驗證pc是否處於正常狀態 — 所有三個控制器都處於聯機狀態,且所有三個控制器都顯示為主控制器。
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:02:52 2018Last change: Mon Jul 2 12:49:52 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
將群集置於維護模式
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:10 2018Last change: Fri Jul 6 09:03:06 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Node pod2-stack-controller-0: standby
Online: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-1 ]
Stopped: [ pod2-stack-controller-0 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
更換主機板
在UCS C240 M4伺服器中更換主機板的過程請參閱Cisco UCS C240 M4伺服器安裝和服務指南
- 使用CIMC IP登入到伺服器。
- 如果韌體與以前使用的推薦版本不一致,請執行BIOS升級。BIOS升級步驟如下:
還原群集狀態
登入受影響的控制器,通過設定unstandby移除待機模式。 驗證控制器是否與群集聯機,並且galera將全部三個控制器顯示為主控制器。 這可能需要幾分鐘。
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:37 2018Last change: Fri Jul 6 09:03:35 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
由思科工程師貢獻
- Karthikeyan Dachanamoorthy思科高級服務
- Harshita Bhardwaj思科高級服務
 意見
意見