更換計算伺服器UCS C240 M4 - CPAR
下載選項
無偏見用語
本產品的文件集力求使用無偏見用語。針對本文件集的目的,無偏見係定義為未根據年齡、身心障礙、性別、種族身分、民族身分、性別傾向、社會經濟地位及交織性表示歧視的用語。由於本產品軟體使用者介面中硬式編碼的語言、根據 RFP 文件使用的語言,或引用第三方產品的語言,因此本文件中可能會出現例外狀況。深入瞭解思科如何使用包容性用語。
關於此翻譯
思科已使用電腦和人工技術翻譯本文件,讓全世界的使用者能夠以自己的語言理解支援內容。請注意,即使是最佳機器翻譯,也不如專業譯者翻譯的內容準確。Cisco Systems, Inc. 對這些翻譯的準確度概不負責,並建議一律查看原始英文文件(提供連結)。
目錄
簡介
本文檔介紹在Ultra-M設定中替換故障計算伺服器所需的步驟。
此過程適用於使用NEWTON版本的Openstack環境,其中Elastic Series Controller(ESC)不管理Cisco Prime Access Registrar(CPAR),並且CPAR直接安裝在Openstack上部署的VM上。
背景資訊
Ultra-M是經過預打包和驗證的虛擬化移動資料包核心解決方案,旨在簡化VNF的部署。 OpenStack是適用於Ultra-M的虛擬化基礎架構管理器(VIM),包含以下節點型別:
- 計算
- 對象儲存磁碟 — 計算(OSD — 計算)
- 控制器
- OpenStack平台 — 導向器(OSPD)
Ultra-M的高級體系結構及涉及的元件如下圖所示:
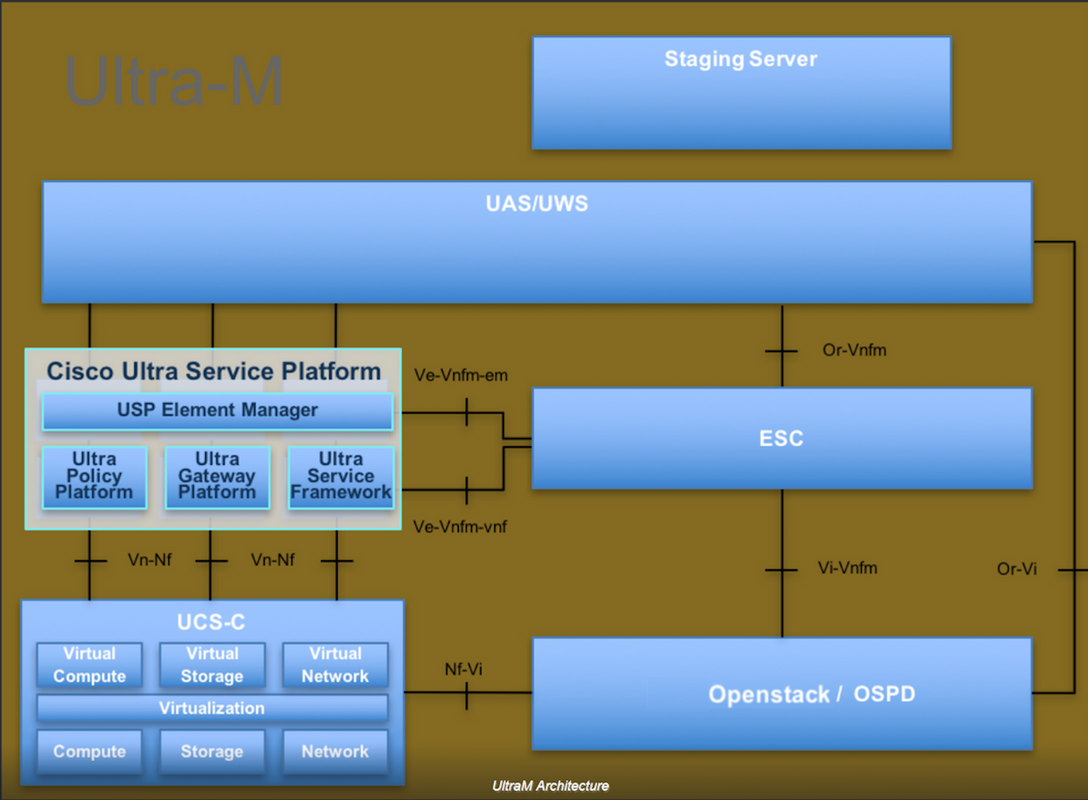
本文檔面向熟悉Cisco Ultra-M平台的思科人員,詳細說明了在OpenStack和Redhat作業系統上執行的步驟。
附註:Ultra M 5.1.x版本用於定義本文檔中的過程。
縮寫
| 澳門幣 | 程式方法 |
| OSD | 對象儲存磁碟 |
| OSPD | OpenStack平台導向器 |
| 硬碟 | 硬碟驅動器 |
| 固態硬碟 | 固態驅動器 |
| VIM | 虛擬基礎架構管理員 |
| 虛擬機器 | 虛擬機器 |
| EM | 元素管理器 |
| UAS | Ultra自動化服務 |
| UUID | 通用唯一識別符號 |
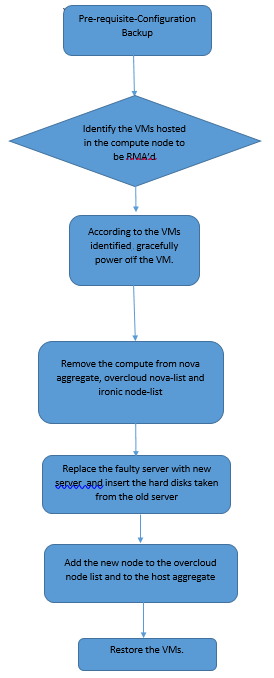
MoP的工作流程
必要條件
備份
在替換Compute節點之前,請務必檢查Red Hat OpenStack平台環境的當前狀態。建議您檢查當前狀態,以避免Compute替換過程處於開啟狀態時出現問題。通過這種更換流程可以實現這一點。
在進行恢復時,思科建議使用以下步驟備份OSPD資料庫:
[root@ al03-pod2-ospd ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@ al03-pod2-ospd ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
此過程可確保在不影響任何例項可用性的情況下替換節點。
附註:確保您擁有該例項的快照,以便在需要時恢復虛擬機器。請按照以下步驟操作,瞭解如何拍攝虛擬機器的快照。
確定計算節點中託管的VM
確定託管在計算伺服器上的虛擬機器。
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
附註:此處顯示的輸出中,第一列對應於通用唯一識別符號(UUID),第二列是VM名稱,第三列是存在VM的主機名。此輸出的引數將在後續章節中使用。
快照流程
CPAR應用關閉
步驟1.開啟連線到網路的任何SSH客戶端並連線到CPAR例項。
重要的一點是,不要同時關閉一個站點內的所有4個AAA例項,而要逐個關閉。
步驟2.使用以下命令關閉CPAR應用程式:
/opt/CSCOar/bin/arserver stop
消息顯示「Cisco Prime Access Registrar Server Agent shutdown complete」。 應該出現了。
附註:如果使用者保持開啟的CLI會話,則arserver stop命令將無效,並顯示以下消息:
ERROR: You can not shut down Cisco Prime Access Registrar while the
CLI is being used. Current list of running
CLI with process id is:
2903 /opt/CSCOar/bin/aregcmd –s
在此示例中,需要終止突出顯示的進程ID 2903,然後才能停止CPAR。如果是這種情況,請使用以下命令終止進程:
kill -9 *process_id*
然後重複步驟1。
步驟3.使用以下命令驗證CPAR應用確實關閉:
/opt/CSCOar/bin/arstatus
應顯示以下消息:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VM快照任務
步驟1.輸入與當前正在處理的站點(城市)對應的Horizon GUI網站。訪問「Horizon(地平線)」時,將觀察影象中所示的螢幕:
步驟2.如圖所示,導覽至專案>例項。
如果使用的使用者為cpar,則此選單中只顯示4個AAA例項。
步驟3.一次僅關閉一個例項,重複本文檔中的整個過程。要關閉VM,請導航到操作>關閉例項並確認選擇。

步驟4 驗證例項是否確實通過Status = Shutoff和Power State = Shutdown關閉。
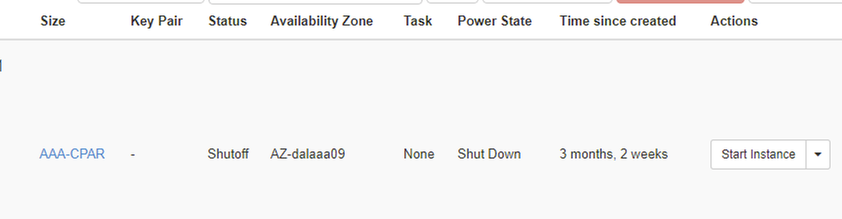
此步驟結束CPAR關閉過程。
虛擬機器快照
一旦CPAR VM關閉,可以並行拍攝快照,因為它們屬於獨立的計算。
四個QCOW2檔案是並行建立的。
獲取每個AAA例項的快照(25分鐘–1小時)(使用qcow映像作為源的例項為25分鐘,使用原始映像作為源的例項為1小時)。
步驟1.登入POD的Openstack的Horizon GUI。
步驟2.登入後,進入頂部選單上的Project > Compute > Instances部分,並查詢AAA例項。
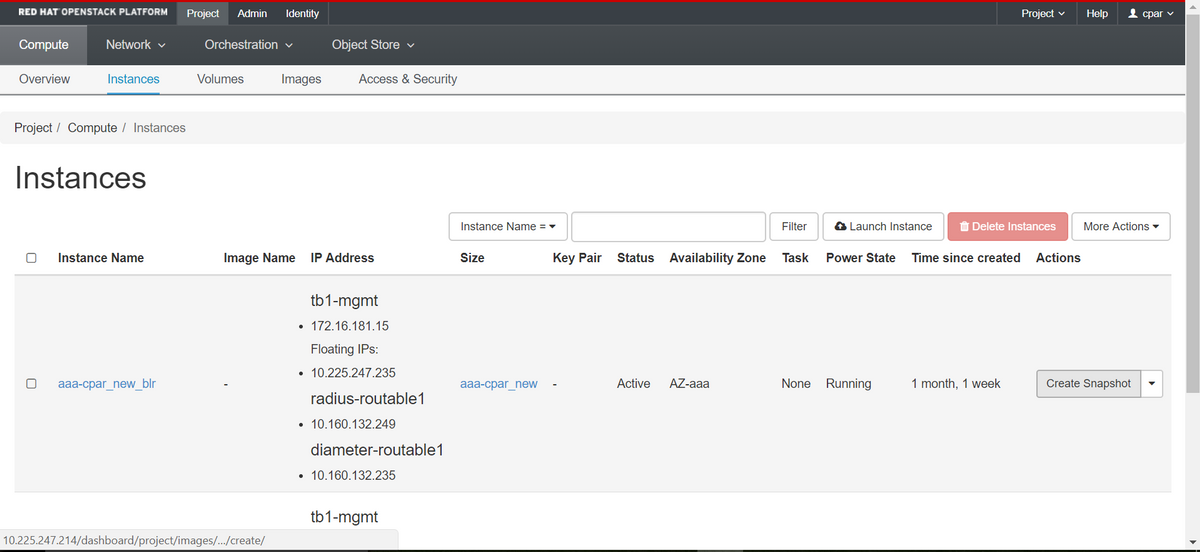
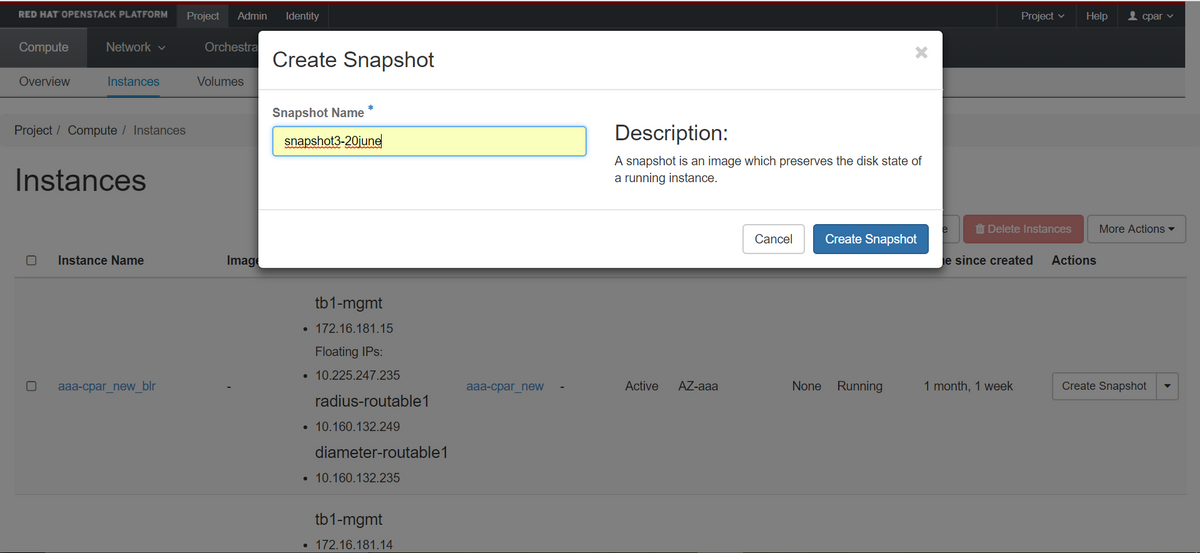
步驟3.按一下Create Snapshot繼續建立快照(需要在相應的AAA例項上執行該操作)。
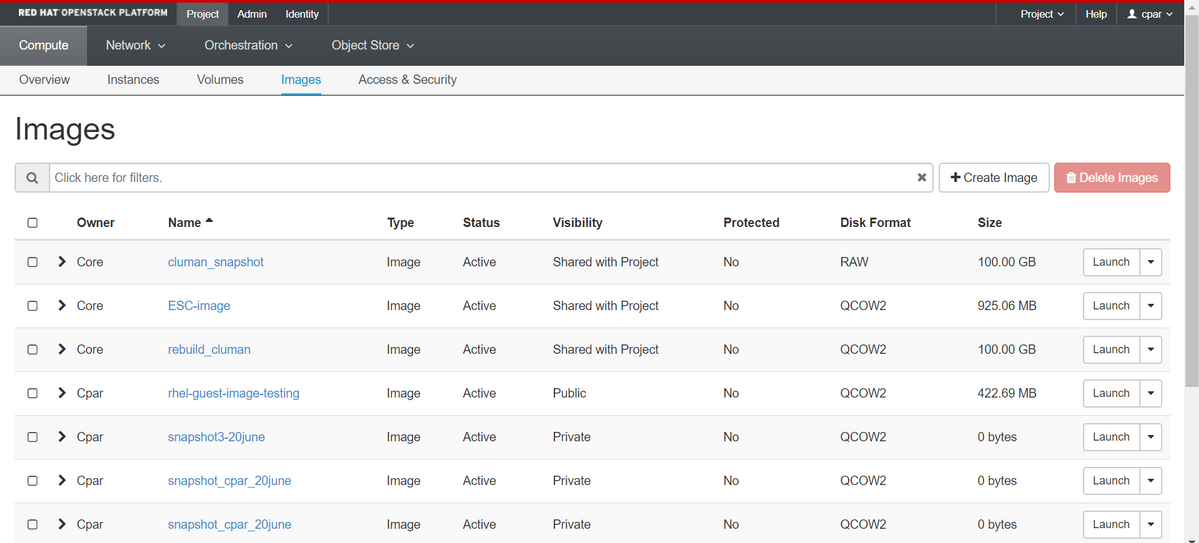
步驟4.執行快照後,導航到Images選單,驗證快照是否完成並報告沒有問題。
步驟5.下一步是以QCOW2格式下載快照,並將其傳輸到遠端實體,以防OSPD在此過程中丟失。為此,請在OSPD級別使用此命令glance image-list標識快照
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
步驟6.一旦識別出要下載的快照(在本例中為以上綠色標籤的快照),便會通過此命令glance image-download以QCOW2格式下載該快照,如下所示。
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- 「&」將進程傳送到後台。完成此操作需要一些時間,一旦完成,映像就可以位於/tmp目錄中。
- 將進程傳送到後台時,如果連線丟失,則進程也會停止。
- 運行命令disown -h,以便在安全外殼(SSH)連線丟失的情況下,該進程仍在OSPD上運行並完成。
步驟7.下載過程完成後,需要執行壓縮過程,因為作業系統處理的過程、任務和臨時檔案可能使ZEROES填充該快照。用於檔案壓縮的命令是virt-sparsify。
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
此過程需要一些時間(大約10-15分鐘)。 完成後,生成的檔案就是下一步中指定的需要傳輸到外部實體的檔案。
需要驗證檔案完整性,為了做到這一點,請運行下一個命令,並在輸出結尾查詢corrupted屬性。
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
為了避免丟失OSPD的問題,需要將最近在QCOW2格式上建立的快照轉移到外部實體。在開始檔案傳輸之前,我們必須檢查目標是否有足夠的可用磁碟空間,使用命令df -kh以驗證記憶體空間。建議通過SFTP sftp root@x.x.x.x(其中x.x.x.x是遠端OSPD的IP)臨時將其傳輸到其他站點的OSPD。為了加快傳輸速度,可以將目標傳送到多個OSPD。同樣,也可以使用此命令scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp(其中x.x.x.x是遠端OSPD的IP)將檔案傳輸到另一個OSPD。
正常斷電
關閉節點電源
- 要關閉例項電源,請執行以下操作:nova stop <INSTANCE_NAME>
- 現在您會看到處於關閉狀態的例項名稱。
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
計算節點刪除
不論計算節點中託管的VM,本節中提到的步驟都是通用的。
從服務清單中刪除計算節點
從服務清單中刪除compute服務:
[stack@director ~]$ openstack compute service list |grep compute-3 | 138 | nova-compute | pod2-stack-compute-3.localdomain | AZ-aaa | enabled | up | 2018-06-21T15:05:37.000000 |
openstack 計算 service delete <ID>
[stack@director ~]$ openstack compute service delete 138
刪除中子代理
刪除compute伺服器的舊關聯中子代理和open vswitch代理:
[stack@director ~]$ openstack network agent list | grep compute-3 | 3b37fa1d-01d4-404a-886f-ff68cec1ccb9 | Open vSwitch agent | pod2-stack-compute-3.localdomain | None | True | UP | neutron-openvswitch-agent |
openstack network agent delete <ID>
[stack@director ~]$ openstack network agent delete 3b37fa1d-01d4-404a-886f-ff68cec1ccb9
從Ironic資料庫中刪除
從具有諷刺意味的資料庫中刪除節點並對其進行驗證:
nova show <計算-node> | grep hypervisor
[root@director ~]# source stackrc [root@director ~]# nova show pod2-stack-compute-4 | grep hypervisor | OS-EXT-SRV-ATTR:hypervisor_hostname | 7439ea6c-3a88-47c2-9ff5-0a4f24647444
ironic node-delete <ID>
[stack@director ~]$ ironic node-delete 7439ea6c-3a88-47c2-9ff5-0a4f24647444 [stack@director ~]$ ironic node-list
現在不能在ironic node-list中列出已刪除的節點。
從超雲中刪除
步驟1.使用所示內容建立名為delete_node.sh的指令碼檔案。請確保提到的模板與用於堆疊部署的deploy.sh指令碼中使用的模板相同:
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack <stack-name> <UUID>
[stack@director ~]$ source stackrc [stack@director ~]$ /bin/sh delete_node.sh + openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod2-stack 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Deleting the following nodes from stack pod2-stack: - 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae real 0m52.078s user 0m0.383s sys 0m0.086s
步驟2.等待OpenStack堆疊操作變為COMPLETE狀態:
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod2-stack | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
安裝新的計算節點
有關安裝新UCS C240 M4伺服器的步驟和初始設定步驟,請參閱Cisco UCS C240 M4伺服器安裝和服務指南
步驟1.安裝伺服器後,將硬碟插入相應插槽中作為舊伺服器。
步驟2.使用CIMC IP登入到伺服器。
步驟3.如果韌體與以前使用的推薦版本不一致,請執行BIOS升級。BIOS升級步驟如下:Cisco UCS C系列機架式伺服器BIOS升級指南
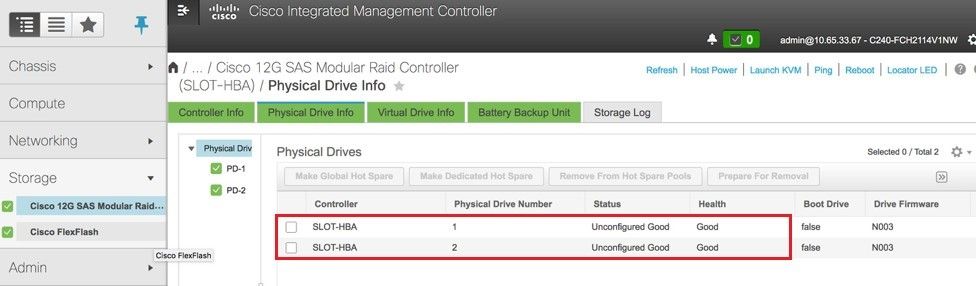
步驟4.要驗證未配置良好的物理驅動器的狀態,請導航到儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>物理驅動器資訊。
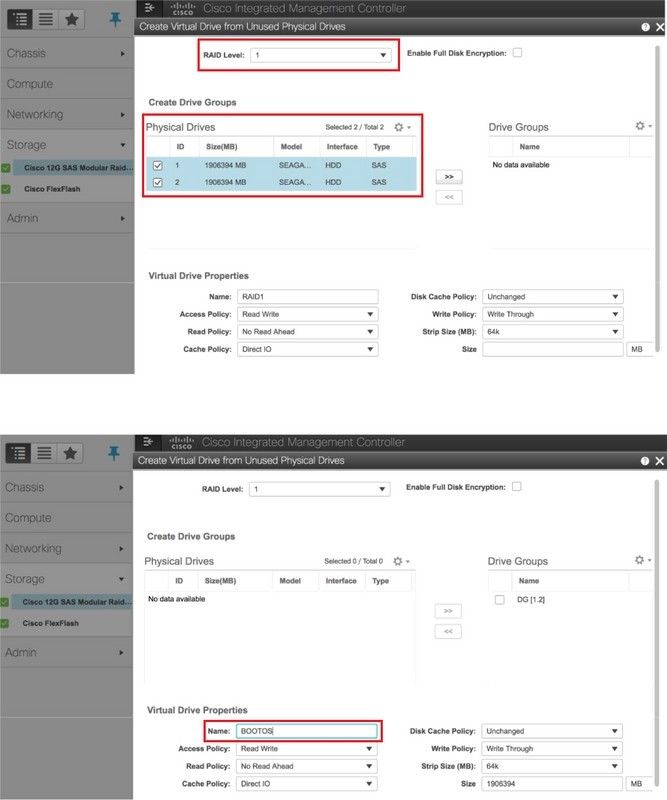
步驟5。若要從RAID級別為1的物理驅動器建立虛擬驅動器,請導航到Storage > Cisco 12G SAS Modular Raid Controller(SLOT-HBA)> Controller Info > Create Virtual Drive from Unused Physical Drives。
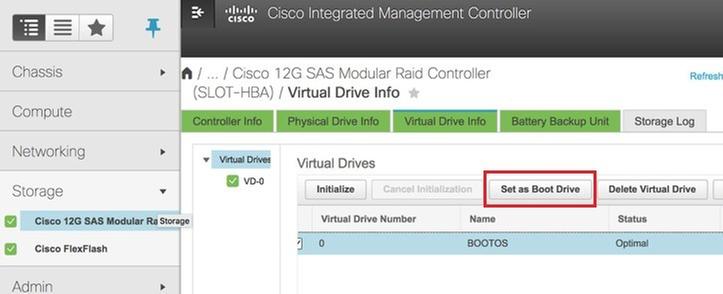
步驟6.選擇VD並設定Set as Boot Drive,如下圖所示。
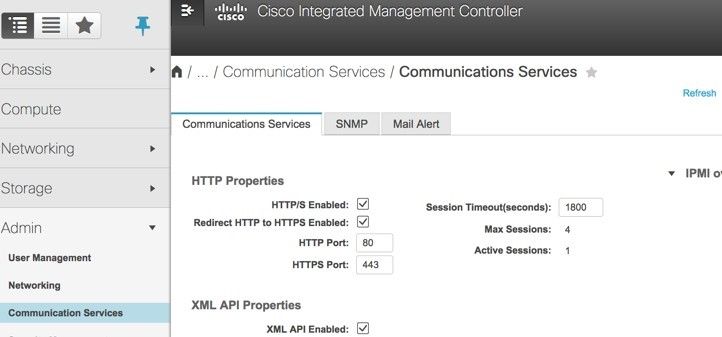
步驟7.若要啟用IPMI over LAN,請導覽至Admin > Communication Services > Communication Services,如下圖所示。
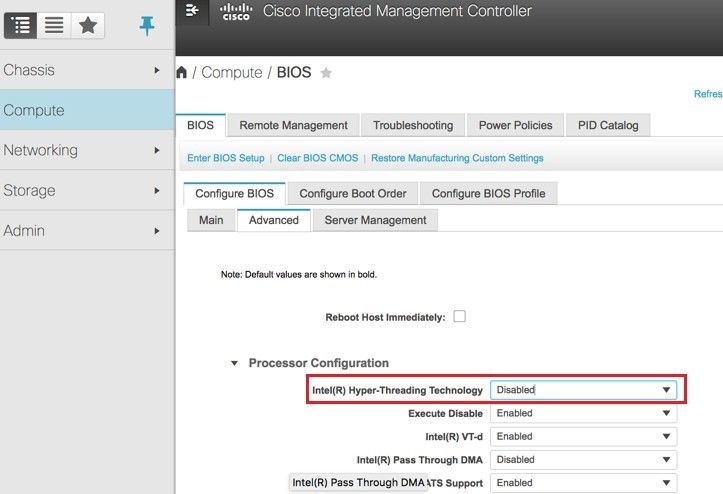
步驟8.若要停用超執行緒,請導覽至Compute > BIOS > Configure BIOS > Advanced > Processor Configuration。
附註:此處顯示的影象和本節中提到的配置步驟是參考韌體版本3.0(3e),如果您使用其他版本,可能會有細微的變化。
將新計算節點新增到超雲中
不論計算節點託管的VM,本節中提到的步驟都常見。
步驟1.使用不同的索引新增Compute伺服器
建立一個add_node.json檔案,該檔案僅包含要新增的新計算伺服器的詳細資訊。請確保以前未使用過新計算伺服器的索引號。通常,遞增下一個最高計算值。
範例:最高驗前是compute-17,因此,在2-vnf系統的情況下建立了compute-18。
附註:請記住json格式。
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:compute-18,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
步驟2.匯入json檔案。
[stack@director ~]$ openstack baremetal import --json add_node.json Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e Successfully set all nodes to available.
步驟3.使用上一步中提到的UUID運行節點內檢。
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e [stack@director ~]$ ironic node-list |grep 7eddfa87 | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False | [stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c Waiting for introspection to finish... Successfully introspected all nodes. Introspection completed. Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9 Successfully set all nodes to available. [stack@director ~]$ ironic node-list |grep available | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
步驟4.運行以前用於部署堆疊的deploy.sh指令碼,以便將新計算機新增到超雲堆疊:
[stack@director ~]$ ./deploy.sh ++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180 … Starting new HTTP connection (1): 192.200.0.1 "POST /v2/action_executions HTTP/1.1" 201 1695 HTTP POST http://192.200.0.1:8989/v2/action_executions 201 Overcloud Endpoint: http://10.1.2.5:5000/v2.0 Overcloud Deployed clean_up DeployOvercloud: END return value: 0 real 38m38.971s user 0m3.605s sys 0m0.466s
步驟5.等待openstack狀態變為完成。
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | ADN-ultram | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
步驟6.檢查新的compute節點是否處於活動狀態。
[root@director ~]# nova list | grep pod2-stack-compute-4 | 5dbac94d-19b9-493e-a366-1e2e2e5e34c5 | pod2-stack-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.116 |
恢復虛擬機器
通過快照恢復例項
恢復過程:
可以使用前面步驟中拍攝的快照重新部署以前的例項。
步驟1 [可選]。如果沒有以前的VMsnapshot可用,則連線到傳送備份的OSPD節點,並將備份傳送回其原始OSPD節點。通過sftp root@x.x.x.x,其中x.x.x.x是原始OSPD的IP。將快照檔案儲存在/tmp目錄中。
步驟2.連線到重新部署例項的OSPD節點。

使用以下命令獲取環境變數:
# source /home/stack/pod1-stackrc-Core-CPAR
步驟3.要將快照用作影象,必須將其上傳到水平面。使用下一個命令執行此操作。
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
這個過程可以從地平線看到。

步驟4.在地平線中,導覽至專案>例項,然後按一下Launch Instance,如下圖所示。

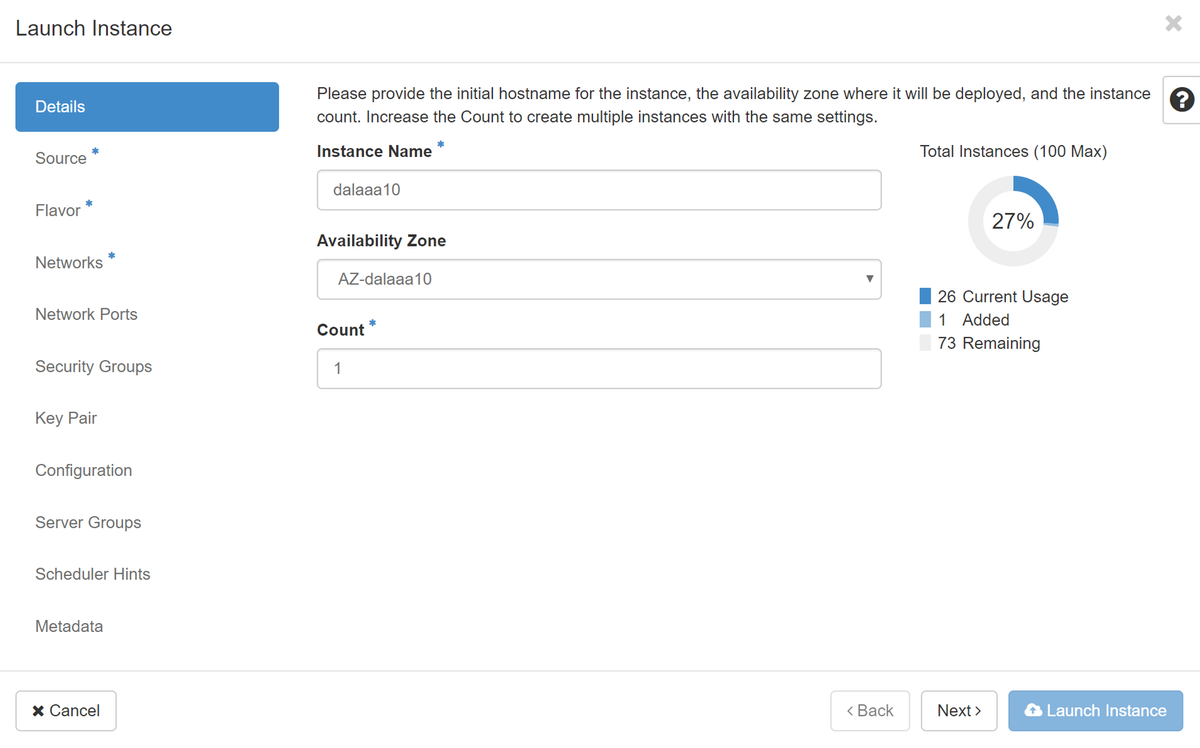
步驟5.輸入例項名稱並選擇可用區,如下圖所示。
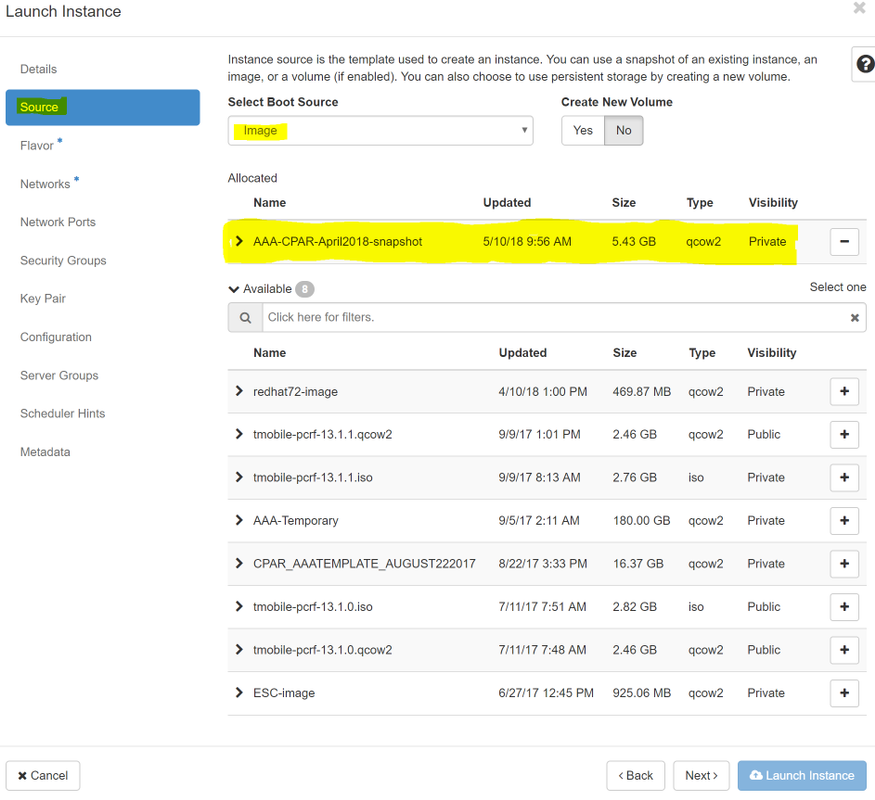
步驟6.在Source索引標籤中,選擇映像以建立例項。在Select Boot Source功能表中選擇image,此處將顯示映像的清單,然後選擇您按一下+符號時先前上傳的映像。
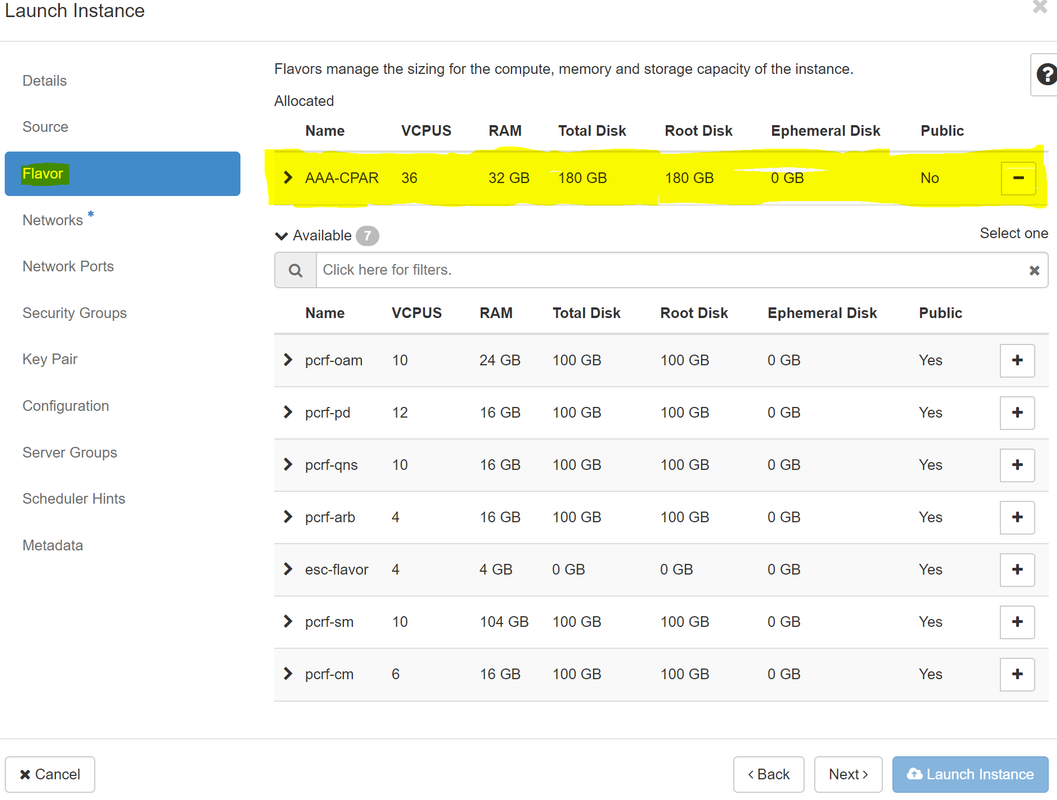
步驟7.在Flavor索引標籤中,按一下+符號選擇AAA調味,如下圖所示。
步驟8.現在導航到Networks頁籤,並在您點選+符號時選擇例項所需的網路。在這種情況下,請選擇diameter-soutable1、radius-routable1和tb1-mgmt,如下圖所示。
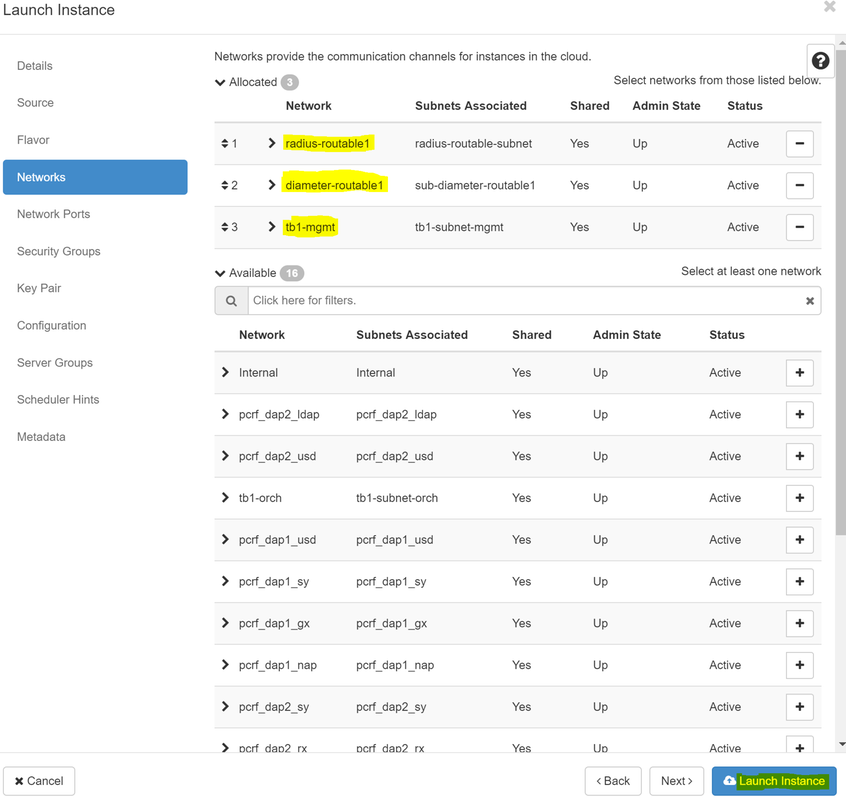
步驟9.按一下Launch例項建立該例項。可以在Horizon中監控進度:
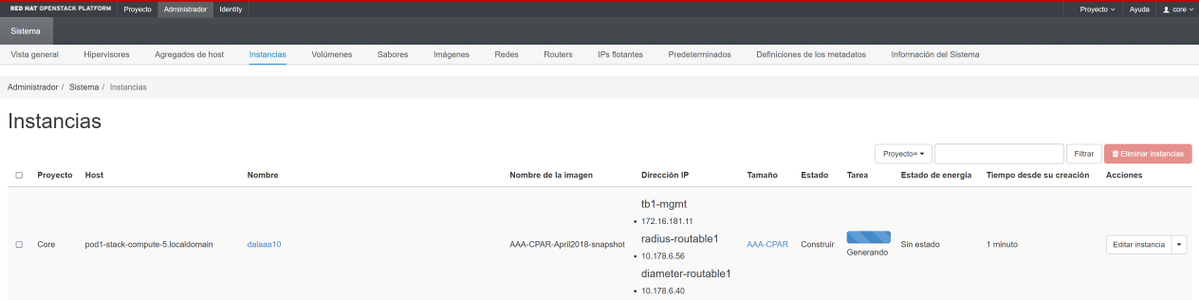
幾分鐘後,該例項將完全部署並可供使用。

建立和分配浮動IP地址
浮動IP地址是可路由地址,這意味著可以從Ultra M/Openstack體系結構外部訪問它,並且能夠與網路中的其他節點通訊。
步驟1。在Horizon頂部選單中,導航到Admin > Floating IPs。
步驟2.按一下Allocate IP to Project按鈕。
步驟3.在Allocate Floating IP視窗中,選擇新浮動IP所屬的Pool、將分配它的Project以及新的Floating IP地址本身。
例如:
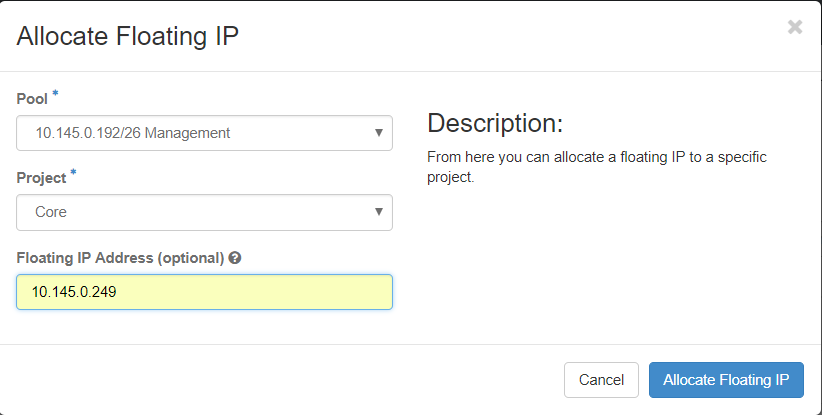
步驟4.按一下Allocate Floating IP 按鈕。
步驟5.在「展望期」頂部選單中,定位至「專案」>「常式」。
步驟6.在Action列中,按一下Create Snapshot按鈕中指向下方的箭頭,此時將顯示一個選單。選擇關聯浮動IP選項。
步驟7.在IP Address 欄位中選擇要使用的相應浮動IP地址,並從要在要關聯的埠中分配此浮動IP的新例項中選擇相應的管理介面(eth0)。請參考下一張影象作為此過程的示例。
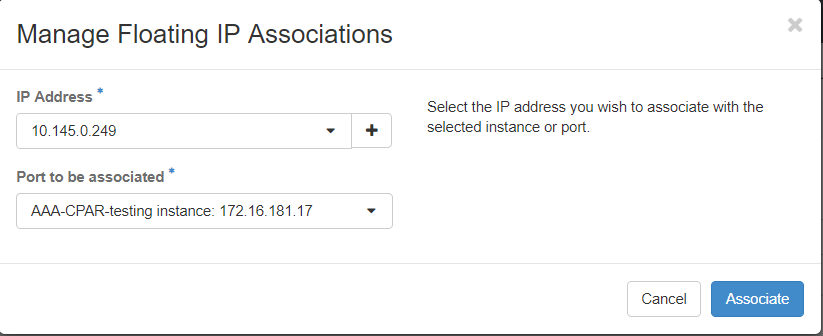
步驟8.按一下Associate。
啟用SSH
步驟1。在「展望期」頂部選單中,定位至「專案」>「例項」。
步驟2.按一下在Cunch a new instance部分中建立的例項/VM的名稱。
步驟3.按一下Console 索引標籤。這將顯示VM的CLI。
步驟4.顯示CLI後,輸入正確的登入憑證:
使用者名稱:根
密碼:cisco123
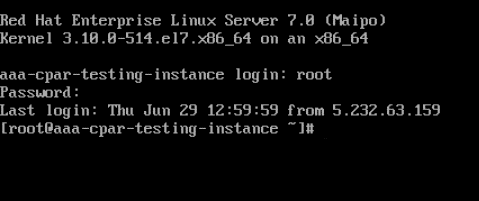
步驟5.在CLI中輸入命令vi /etc/ssh/sshd_config編輯ssh配置。
步驟6.開啟ssh配置檔案後,按I編輯該檔案。然後查詢下面顯示的部分,並將第一行從PasswordAuthentication no 更改為PasswordAuthentication yes。

步驟7.按ESC並輸入:wq!儲存sshd_config檔案更改。
步驟8.運行命令service sshd restart。
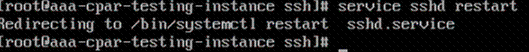
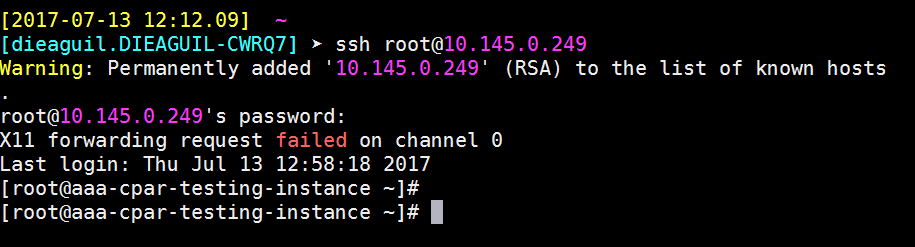
步驟9.為了測試已正確應用SSH配置更改,請開啟任何SSH客戶端,並嘗試使用分配給例項的浮動IP(例如10.145.0.249)和使用者root建立遠端安全連線。
建立SSH會話
使用安裝應用程式的相應VM/伺服器的IP地址開啟SSH會話。

CPAR例項啟動
一旦活動完成並且可以在關閉的站點中重新建立CPAR服務,請按照以下步驟操作。
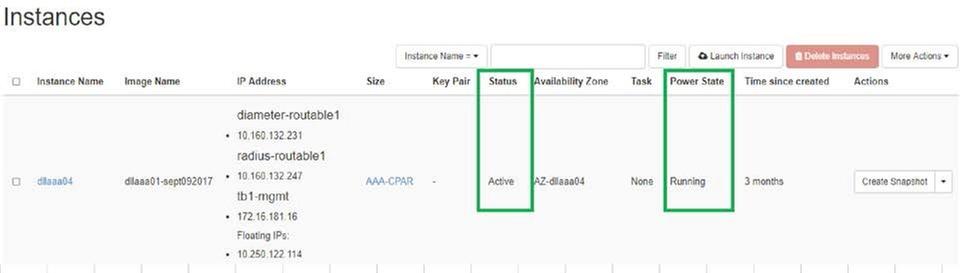
- 要重新登入到Horizon,請導航到專案>例項>啟動例項。
- 驗證例項的狀態是否為「active(活動)」 ,電源狀態是否為「running(運行)」 :
活動後運行狀況檢查
步驟1.在作業系統級別執行命令/opt/CSCOar/bin/arstatus。
[root@wscaaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
步驟2.在作業系統級別執行命令/opt/CSCOar/bin/aregcmd,然後輸入管理員憑據。驗證CPAR Health(CPAR運行狀況)為10(滿分10)並退出CPAR CLI。
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd
Cisco Prime Access Registrar 7.3.0.1 Configuration Utility
Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved.
Cluster:
User: admin
Passphrase:
Logging in to localhost
[ //localhost ]
LicenseInfo = PAR-NG-TPS 7.2(100TPS:)
PAR-ADD-TPS 7.2(2000TPS:)
PAR-RDDR-TRX 7.2()
PAR-HSS 7.2()
Radius/
Administrators/
Server 'Radius' is Running, its health is 10 out of 10
--> exit
步驟3.執行命令netstat | grep diameter並驗證所有DRA連線是否已建立。
下面提到的輸出適用於預期存在Diameter連結的環境。如果顯示的連結較少,則表示與需要分析的DRA斷開連線。
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
步驟4.檢查TPS日誌是否顯示CPAR正在處理的請求。突出顯示的值代表了TPS,而那些值是我們需要注意的。
TPS的值不應超過1500。
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
步驟5.在name_radius_1_log中查詢任何「錯誤」或「警報」消息
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
步驟6.使用以下命令驗證CPAR進程所用的記憶體量:
頂端 | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
此突出顯示的值應小於:7Gb,這是應用級別允許的最大容量。
由思科工程師貢獻
- Karthikeyan Dachanamoorthy思科高級服務
- Harshita Bhardwaj思科高級服務
 意見
意見