了解 CPU 使用率达 99% 的 VIP 与接收端缓冲
目录
简介
本文解释通用接口处理器(VIP)CPU以99%的速度运行的原因,以及Rx端缓冲区的含义。
先决条件
要求
本文档没有任何特定的要求。
使用的组件
本文档不限于特定的软件和硬件版本。
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您使用的是真实网络,请确保您已经了解所有命令的潜在影响。
规则
有关文档规则的详细信息,请参阅 Cisco 技术提示规则。
背景信息
Rx端缓冲是当出站接口:
-
拥塞。
-
使用先入先出(FIFO)排队策略。
入站通用接口处理器(VIP)不会立即丢弃数据包。相反,它会在数据包内存中缓冲数据包,直到缓冲区可用于传出接口。根据VIP的类型,数据包内存可以是静态RAM(SRAM)或同步动态RAM(SDRAM)。
Cisco 7500系列架构基础
每个接口处理器(传统IP或VIP)都有一个连接到高速扩展系统总线,称为CyBus。路由/交换处理器(RSP)连接到两个CyBus(请参见图1)。
图1 - Cisco 7500系列架构 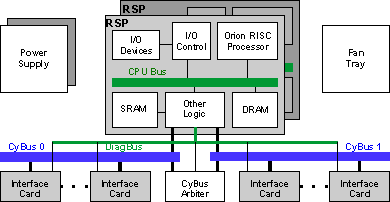
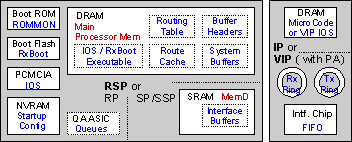
数据包缓冲区的类型
本节介绍各种类型的数据包缓冲区。
-
RSP上处理器内存中的系统缓冲区
这些缓冲区用于进程交换数据包。在show interfaces(输入和输出队列)和show buffers命令的输出中可以看到这些缓冲区。Cisco 7500系列路由器不能执行太多进程交换。因此,如果系统缓冲区有问题,则意味着向进程级别发送的数据包过多。这可能是由许多因素造成的,例如:
-
广播风暴
-
导致路由更新的网络不稳定
-
“拒绝服务”(DoS)攻击
-
快速交换路径中不支持的功能(例如X.25)
-
带选项的 IP 数据包.
有关如何排除过多进程交换故障的信息,请参阅以下文档:
-
-
RSP(MEMD)缓冲区上的数据包内存
在RSP7000、RSP1、RSP2和RSP4上,MEMD大小固定为2 MB。在RSP8和RSP16上,MEMD大小固定为8 MB。在启动时,当存在在线插入和删除(OIR)、微码重新加载、最大传输单元(MTU)更改或总线复杂时,MEMD会分布在所有接口之间。有关cbus复合体的详细信息,请参阅导致“%RSP-3-RESTART:cbus complex”的原因中详细讨论了此错误消息。您可以使用show controllers cbus命令检查MEMD缓冲区的状态。
分配MEMD时,会创建以下结构:
-
本地空闲队列(lfreeq) — 分配给每个接口,并用于此接口上接收的数据包。
-
全局自由队列(gfreeq) — 也分配了该队列,并且接口可以在某些限制内回退到该队列。
-
传输队列(txqueue或txq) — 分配给每个接口,用于通过此接口传出的数据包。
-
transmit acculator(txacc) — 表示输出接口传输队列(txqueue)上的元素数。 当传输累加器(txacc)等于传输限制(txlimit)时,所有缓冲区都会释放。txacc为0时,队列已满,不允许再排队。
-
-
数据包内存
在VIP上,数据包内存包含用于从VIP接口接收或发送到VIP接口的数据包的数据包缓冲区(颗粒)。图2表示数据包流。
图2 — 数据包流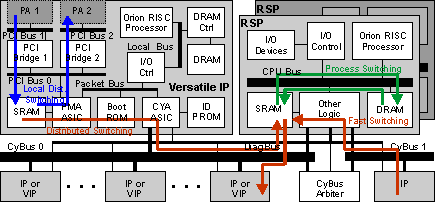
本部分重点介绍启用了分布式交换的VIP,因为当数据包遵循此类交换路径时,通常会发生接收端缓冲。可能有不同的场景,具体说明如下:
情形 1:当出站接口上没有拥塞时。
-
数据包在一个端口适配器(PA)上被接收并被发往数据包存储器上的数据包缓冲器。
-
如果VIP不能对数据包进行分布式交换,它就将该数据包转发到RSP,由其作出交换决策。
-
如果VIP可以作出交换决策而且流出接口在同一VIP上,数据包就通过该出站接口发出。VIP上的数据包据说是“本地交换”的,因为它不通过总线。
-
如果VIP可以作出交换决策但出局接口在另一个插槽中,VIP就会尽力通过cbus将数据包复制到出局接口的txqueue(在MEMD内)中。
-
然后数据包被通过cbus 复制到出局(V)IP中并通过该线路发出。
方案 2:当出站接口拥塞时。
有两个可能性:
-
如果传出接口上配置了排队,VIP会将数据包发往MEMD中的txqueue,数据包会通过排队代码立即从队列中提出。
-
如果配置了基于RSP的排队,数据包就会被复制到RSP上处理内存的系统缓冲器中。
-
如果使用了基于VIP的排队,数据包就会被复制到出站VIP的数据包存储器中。
-
-
如果出站接口的排队策略是FIFO,则接口不会立即丢弃数据包(这是出站接口拥塞时FIFO通常会发生的情况)。 相反,入站VIP会在数据包内存中缓冲数据包,直到某些缓冲区再次可用于传出接口。这叫作接收端(Rx-side)缓冲。
-

使用show controllers vip camculator命令检查Rx端缓冲的状态。状态表示:
-
路由器中现有接口的数量.
-
对这些接口,VIP对多少数据包进行了接收缓冲.
-
VIP为什么进行接收缓冲.
-
VIP丢弃了多少数据包,为什么丢弃
VIP以99%的CPU利用率运行
接收端(Rx-side)缓冲的一个结果是VIP可以以99%的CPU利用率运行。VIP会持续监控出站接口的txqueue的状态,一旦有空闲缓冲区,它就会将通过cbus的数据包复制到txqueue。
当VIP以99%的速率运行时,Rx缓冲发生时,本身没有任何警告。这并不意味着VIP过载。如果VIP需要完成更重要的任务(如需要交换另一个数据包),这不会受到CPU利用率高的影响。
在实验中,您可以做一个简单的测试来说明这一点:
Serial 2/0/0的时钟频率为128 Kbps,并以线速接收流量。流量被切换到串行10/0,其中时钟速率为64 Kbps,排队策略为FIFO。唯一的选择就是丢弃数据包。
router#show controller cbus MEMD at 40000000, 8388608 bytes (unused 697376, recarves 6, lost 0) RawQ 48000100, ReturnQ 48000108, EventQ 48000110 BufhdrQ 48000130 (21 items), LovltrQ 48000148 (15 items, 2016 bytes) IpcbufQ 48000158 (24 items, 4096 bytes) IpcbufQ_classic 48000150 (8 items, 4096 bytes) 3570 buffer headers (48002000 - 4800FF10) pool0: 8 buffers, 256 bytes, queue 48000138 pool1: 2940 buffers, 1536 bytes, queue 48000140 pool2: 550 buffers, 4512 bytes, queue 48000160 pool3: 4 buffers, 4544 bytes, queue 48000168 slot2: VIP2, hw 2.11, sw 22.20, ccb 5800FF40, cmdq 48000090, vps 8192 software loaded from system IOS (tm) VIP Software (SVIP-DW-M), Version 12.0(21)S, EARLY DEPLOYMENT RELEASE SOFTWARE (fc1) ROM Monitor version 122.0 Mx Serial(4), HW Revision 0x3, FW Revision 1.45 Serial2/0/0, applique is V.35 DCE received clockrate 2015232 gfreeq 48000140, lfreeq 480001D0 (1536 bytes) rxlo 4, rxhi 336, rxcurr 16, maxrxcurr 293 txq 48001A00, txacc 48001A02 (value 294), txlimit 294 Serial2/0/1, applique is V.35 DTE received clockrate 246 gfreeq 48000140, lfreeq 480001D8 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48001A08, txacc 48001A0A (value 6), txlimit 6 Serial2/0/2, applique is Universal (cable unattached) received clockrate 246 gfreeq 48000140, lfreeq 480001E0 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48001A10, txacc 48001A12 (value 6), txlimit 6 Serial2/0/3, applique is Universal (cable unattached) received clockrate 246 gfreeq 48000140, lfreeq 480001E8 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48001A18, txacc 48001A1A (value 6), txlimit 6 slot10: FSIP, hw 1.12, sw 20.09, ccb 5800FFC0, cmdq 480000D0, vps 8192 software loaded from system Serial10/0, applique is V.35 DTE gfreeq 48000140, lfreeq 48000208 (1536 bytes) rxlo 4, rxhi 336, rxcurr 1, maxrxcurr 1 txq 48000210, txacc 480000B2 (value 2), txlimit 294 Serial10/1, applique is Universal (cable unattached) gfreeq 48000140, lfreeq 48000218 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48000220, txacc 480000BA (value 6), txlimit 6 Serial10/2, applique is Universal (cable unattached) gfreeq 48000140, lfreeq 48000228 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48000230, txacc 480000C2 (value 6), txlimit 6 Serial10/3, applique is Universal (cable unattached) gfreeq 48000140, lfreeq 48000238 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48000240, txacc 480000CA (value 6), txlimit 6 Serial10/4, applique is Universal (cable unattached) gfreeq 48000140, lfreeq 48000248 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48000250, txacc 480000D2 (value 6), txlimit 6 Serial10/5, applique is Universal (cable unattached) gfreeq 48000140, lfreeq 48000258 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48000260, txacc 480000DA (value 6), txlimit 6 Serial10/6, applique is Universal (cable unattached) gfreeq 48000140, lfreeq 48000268 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48000270, txacc 480000E2 (value 6), txlimit 6 Serial10/7, applique is Universal (cable unattached) gfreeq 48000140, lfreeq 48000278 (1536 bytes) rxlo 4, rxhi 336, rxcurr 0, maxrxcurr 0 txq 48000280, txacc 480000EA (value 6), txlimit 6 router#
值2表示仅剩两个缓冲区。当txacc小于4时,Rx缓冲不会在MEMD中对数据包排队。
VIP中的show controllers vip 2 tech-support命令显示,它以99%的CPU运行:
router#show controllers vip 2 tech-support show tech-support from Slot 2: ------------------ show version ------------------ Cisco Internetwork Operating System Software IOS (tm) VIP Software (SVIP-DW-M), Version 12.0(21)S, EARLY DEPLOYMENT RELEASE SOFTWARE (fc1) Copyright (c) 1986-2000 by cisco Systems, Inc. Compiled Tue 18-Jul-00 22:03 by htseng Image text-base: 0x600108F0, data-base: 0x602E0000 ROM: System Bootstrap, Version 11.1(4934) [pgreenfi 122], INTERIM SOFTWARE VIP-Slot2 uptime is 1 week, 23 hours, 27 minutes System returned to ROM by power-on Running default software cisco VIP2 (R4700) processor (revision 0x02) with 32768K bytes of memory. Processor board ID 00000000 R4700 CPU at 100Mhz, Implementation 33, Rev 1.0, 512KB L2 Cache 4 Serial network interface(s) Configuration register is 0x0 ... ------------------ show process cpu ------------------ CPU utilization for five seconds: 99%/97%; one minute: 70%; five minutes: 69%
VIP以99%的CPU利用率运行,即使它只接收128 Kbps。这表明CPU使用率未与每秒数据包数相关联。这是因为VIP 2能够交换比此更多的数据包。这只是接收端缓冲的一个标志。
要检查Rx端缓冲的作用,请执行以下命令:
router#show controllers vip 2 accumulator
show vip accumulator from Slot 2:
Buffered RX packets by accumulator:
...
Serial10/0:
MEMD txacc 0x00B2: 544980 in, 2644182 drops (126 paks, 378/376/376 bufs) 1544kbps
No MEMD acc: 544980 in
Limit drops : 2644102 normal pak drops, 80 high prec pak drops
Buffer drops : 0 normal pak drops, 0 high prec pak drops
No MEMD buf: 0 in
Limit drops : 0 normal pak drops, 0 high prec pak drops
Buffer drops : 0 normal pak drops, 0 high prec pak drops
...
Interface x:
MEMD txacc a: b in, c drops (d paks, e/f/g bufs) h kbps
No MEMD acc: i in
Limit drops : j normal pak drops, k high prec pak drops
Buffer drops : l normal pak drops, m high prec pak drops
No MEMD buf: n in
Limit drops : o normal pak drops, p high prec pak drops
Buffer drops : q normal pak drops, r high prec pak drops
| 密钥 | 描述 |
|---|---|
| a | MEMD中txacc的地址。系统中每个txacc(最多可有4096个)都有一个接收端(Rx-side)缓冲器。 |
| b | Rx缓冲的数据包数。 |
| c | VIP丢弃的数据包数。如果有足够的数据包内存缓冲区,VIP可以接收最多一秒的流量。但是,如果接口持续拥塞,则无法避免丢包。 |
| d | 目前在接收端被缓冲的数据包数量。 |
| e | 目前被接收端缓冲的粒子数量。一个数据包可以由多个微粒(particles)组成。 |
| f | 软极限,即VIP内存较低时的最大粒子数。 |
| g | 硬限制,即可随时使用的最大粒子数。 |
| h | 传出接口的速度(以kbps为单位)。 |
| 我 | 由于MEMD中无txacc可用而被接收端缓冲的数据包数量。这意味着输出队列已拥塞(tx队列中不再有可用缓冲区)。 此问题的解决方案是增加输出接口带宽(如果可能)。 |
| j | 由于没有MEMD接入而无法发送的IP优先级为6或7以外的数据包数,并且由于已达到粒子的软或硬限制而被丢弃。 |
| k | 与 j一样,但适用于IP优先级为6或7(互联网络和网络)的数据包。 |
| l | VIP希望接收缓冲区的IP优先级不是6或7的数据包数,但由于数据包内存中缺少可用缓冲区而丢弃。从Cisco IOS软件版本12.0(13)S和12.1(4)开始,您还可以使用show controller vip [all / slot#] packet-memory-drops命令查看丢弃的数据包数。在这种情况下,升级数据包存储器会很有帮助。 |
| m | 与 l一样,但适用于IP优先级为6或7(互联网络和网络)的数据包。 |
| n | VIP尝试Rx缓冲区的数据包数,因为没有MEMD缓冲区,但由于缺少数据包内存缓冲区而无法这样做。在这种情况下,请升级数据包内存。从Cisco IOS软件版本12.0(13)S和12.1(4)开始,您还可以使用show controllers vip [all / slot#] packet-memory-drops命令来了解数据包被丢弃的原因。 |
| o | 由于达到软(f)或硬(g)限制而丢弃的IP优先级不为6或7且无MEMD缓冲区的Rx缓冲数据包数。在这种情况下,使用RSP16会很有帮助,因为它有更大的MEMD存储空间(8MB,而RSP1、RSP2、RSP4和RSP7000为2 MB)。 在这种情况下,您还可以减少某些接口(例如ATM、POS或FDDI)的MTU。这些接口通常具有4470字节的MTU,而且由于缓冲区必须更大,因此可分配的MEMD缓冲区更少。 |
| p | 与 o一样,但适用于IP优先级为6或7(互联网络和网络)的数据包。 |
| q | VIP尝试Rx缓冲区但IP优先级不是6或7的数据包数,因为没有MEMD缓冲区,但由于缺少数据包内存缓冲区而无法这样做。在这种情况下,升级数据包内存会有所帮助。从Cisco IOS软件版本12.0(13)S和12.1(4)开始,您还可以使用show controllers vip [all / slot#] packet-memory-drops命令更好地了解数据包被丢弃的原因。 |
| r | 与 q一样,但适用于IP优先级为6或7(互联网络和网络)的数据包。 |
如果路由器运行的Cisco IOS软件版本早于12.0(13)ST、12.1(04)DB、12.1(04)DC、12.0(13)S、12.1(4)12.1(4)AA12.1(4)t 012.0(13)或12.0(13)SC,show controllers vip [all / slot#] acculator的输出提供了上述的简化版本。由于接收端缓冲,它不考虑丢弃数据包的不同IP优先级。
输出显示如下:
Serial10/0: MEMD txacc 0x00B2: 544980 in, 2644182 drops (126 paks, 378/376/376 bufs) 1544kbps No MEMD acc: 544980 in, 2644182 limit drops, 0 no buffer No MEMD buf: 0 in, 0 limit drops, 0 no buffer Interface x: MEMD txacc a: b in, c drops (d paks, e/f/g bufs) h kbps No MEMD acc: i in, j+k limit drops, l+m no buffer No MEMD buf: n in, o+p limit drops, q+r no buffer
Rx端缓冲区示例
示例 1:插槽2中的VIP以128Kbps的速率接收流量,并将其路由到串行10/0(64Kbps)。
Serial10/0:
MEMD txacc 0x00B2: 544980 in, 2644182 drops (126 paks, 378/376/376 bufs) 1544kbps
No MEMD acc: 544980 in
Limit drops : 2644102 normal pak drops, 80 high prec pak drops
Buffer drops : 0 normal pak drops, 0 high prec pak drops
No MEMD buf: 0 in
Limit drops : 0 normal pak drops, 0 high prec pak drops
Buffer drops : 0 normal pak drops, 0 high prec pak drops
-
在此,544980个数据包成功通过Rx缓冲,2644182被丢弃。2644182中80个被丢弃的数据包的IP优先级为6或7。
-
126个数据包当前是Rx缓冲的,它们使用378个粒子。
-
由于MEMD中的tx队列缺少空闲缓冲区,所有数据包都是Rx缓冲的。这意味着输出接口被拥塞。丢弃是因为达到最大数量的Rx缓冲数据包。典型的解决方案是升级出站接口带宽、重新路由某些流量以使出站接口不那么拥塞,或者启用一些排队丢弃不太重要的流量。
示例 2:Rx端缓冲区,不丢弃。
ATM1/0:
MEMD txacc 0x0082: 203504 in, 0 drops (0 paks, 0/81/37968 bufs) 155520kbps
No MEMD acc: 85709 in
Limit drops : 0 normal pak drops, 0 high prec pak drops
Buffer drops : 0 normal pak drops, 0 high prec pak drops
No MEMD buf: 117795 in
Limit drops : 0 normal pak drops, 0 high prec pak drops
Buffer drops : 0 normal pak drops, 0 high prec pak drops
-
在本例中,85709个数据包是Rx缓冲的,因为ATM 1/0拥塞,但没有丢包。
-
117795数据包是Rx缓冲数据包,因为VIP无法获取MEMD缓冲区。不会丢弃任何数据包。典型的解决方案是减少一些MTU,以便分配更多MEMD缓冲区。RSP8也有帮助。
示例 3:本地交换.
SRP0/0/0: local txacc 0x1A02: 2529 in, 0 drops (29 paks, 32/322/151855 bufs) 622000kbps
本地txacc表示此输出接口与接收数据包的接口位于同一VIP上。这些数据包在本地交换,但出站接口(本例中为srp 0/0/0)拥塞。2529个数据包是Rx缓冲的,并且没有丢弃任何数据包。
示例 4:前向队列.
router#show controllers vip 2 accumulator
Buffered RX packets by accumulator:
Forward queue 0 : 142041 in, 3 drops (0 paks, 0/24414/24414 bufs) 100000kbps
No MEMD buf: 142041 in
Limit drops : 0 normal pak drops, 0 high prec pak drops
Buffer drops : 3 normal pak drops, 0 high prec pak drops
Forward queue 9 : 68 in, 0 drops (0 paks, 0/15/484 bufs) 1984kbps
No MEMD buf: 68 in
Limit drops : 0 normal pak drops, 0 high prec pak drops
Buffer drops : 0 normal pak drops, 0 high prec pak drops
Forward queue 13: 414 in, 0 drops (0 paks, 0/14/468 bufs) 1920kbps
No MEMD buf: 414 in
Limit drops : 0 normal pak drops, 0 high prec pak drops
Buffer drops : 0 normal pak drops, 0 high prec pak drops
Forward queue 14: 46 in, 0 drops (0 paks, 0/14/468 bufs) 1920kbps
No MEMD buf: 46 in
Limit drops : 0 normal pak drops, 0 high prec pak drops
Buffer drops : 0 normal pak drops, 0 high prec pak drops
某些数据包不能被分布式交换。在这种情况下,VIP必须将数据包转发到RSP的原始队列,然后由RSP做出交换决策。当数据包无法立即复制到MEMD时,VIP Rx会缓冲它们并跟踪每个入站接口有多少个数据包是Rx缓冲的。
前向队列0.7用于第一个端口适配器(PA),而8.15用于第二个PA。
| 前向队列编号 | ...显示在上接收的Rx缓冲数据包的数量…… |
|---|---|
| 0 | 第一个端口适配器(PA)的第一个塞孔(plughole) |
| 8 | 第二个PA的第一个塞孔(plughole) |
| 9 | 第二个PA的第二个塞孔(plughole) |
导致VIP上CPU利用率较高的其他原因
当Rx端缓冲被发现为非活动时,以下因素之一可能导致VIP上的CPU使用率较高:
-
由分布式流量整形导致的VIP上CPU利用率高达99%
如果配置了分布式流量整形(DTS),数据包一进入dTS队列,VIP CPU的利用率就会迅速上升到99%。
这是正常的也是预料之中的行为。配置dTS时,VIP CPU会旋转以检查下一个时间间隔(Tc)是否在CPU不忙(即没有流量时)到达。 否则,验证在tx/rx中断例程中被携带。仅当CPU不忙时才旋转CPU。因此,性能不受影响。
如想了解何为“下一时间间隔(next time interval)”,请参见什么是令牌桶?
注意:仅当流量整形必须在整形队列中将数据包入队时,它才会变为活动状态。换句话说,当流量量超过整形速率时。这就说明了配置了dTS时为何VIP CPU的利用率始终为99%。有关dTS的详细信息,请参阅:
-
欺骗内存访问和校验错误引起的高VIP CPU利用率
调整错误和欺骗内存访问是Cisco IOS软件在不使VIP崩溃的情况下纠正的软件故障。如果这些错误频繁出现,则会导致操作系统进行大量更正,从而导致CPU使用率较高。
有关校准错误和欺骗内存访问的详细信息,请参阅排除欺骗访问、校准错误和欺骗中断故障。
使用 show alignment 命令来检查欺骗性内存访问和校正错误。这样的错误举例如下:
VIP-Slot1#show alignment No alignment data has been recorded. No spurious memory references have been recorded.
CPU使用率较高的其他原因可能是已启用的分布式功能的数量和范围。如果您怀疑这可能是原因,或者您无法确定本文档中说明的任何导致CPU使用率过高的原因,请向思科技术支持中心(TAC)提交服务请求。
建立 TAC 服务请求时应收集的信息
| 如果在执行上述故障排除步骤后仍需要帮助,并希望向Cisco TAC提出服务请求(仅限注册客户),请务必包括以下信息: |
|---|
注意:在收集上述信息(除非恢复网络操作需要)之前,请勿手动重新加载或重新通电路由器,因为这可能会导致丢失确定问题根本原因所需的重要信息。 |
 反馈
反馈