Ultra-M UCS 240M4单硬盘故障 — 热插拔程序 — CPAR
下载选项
非歧视性语言
此产品的文档集力求使用非歧视性语言。在本文档集中,非歧视性语言是指不隐含针对年龄、残障、性别、种族身份、族群身份、性取向、社会经济地位和交叉性的歧视的语言。由于产品软件的用户界面中使用的硬编码语言、基于 RFP 文档使用的语言或引用的第三方产品使用的语言,文档中可能无法确保完全使用非歧视性语言。 深入了解思科如何使用包容性语言。
关于此翻译
思科采用人工翻译与机器翻译相结合的方式将此文档翻译成不同语言,希望全球的用户都能通过各自的语言得到支持性的内容。 请注意:即使是最好的机器翻译,其准确度也不及专业翻译人员的水平。 Cisco Systems, Inc. 对于翻译的准确性不承担任何责任,并建议您总是参考英文原始文档(已提供链接)。
目录
简介
本文档介绍在Ultra-M设置中更换服务器中故障硬盘驱动器(HDD)所需的步骤。
此过程适用于NEWTON版本的OpenStack环境,其中ESC不管理CPAR,CPAR直接安装在部署在OpenStack上的虚拟机(VM)上。
背景信息
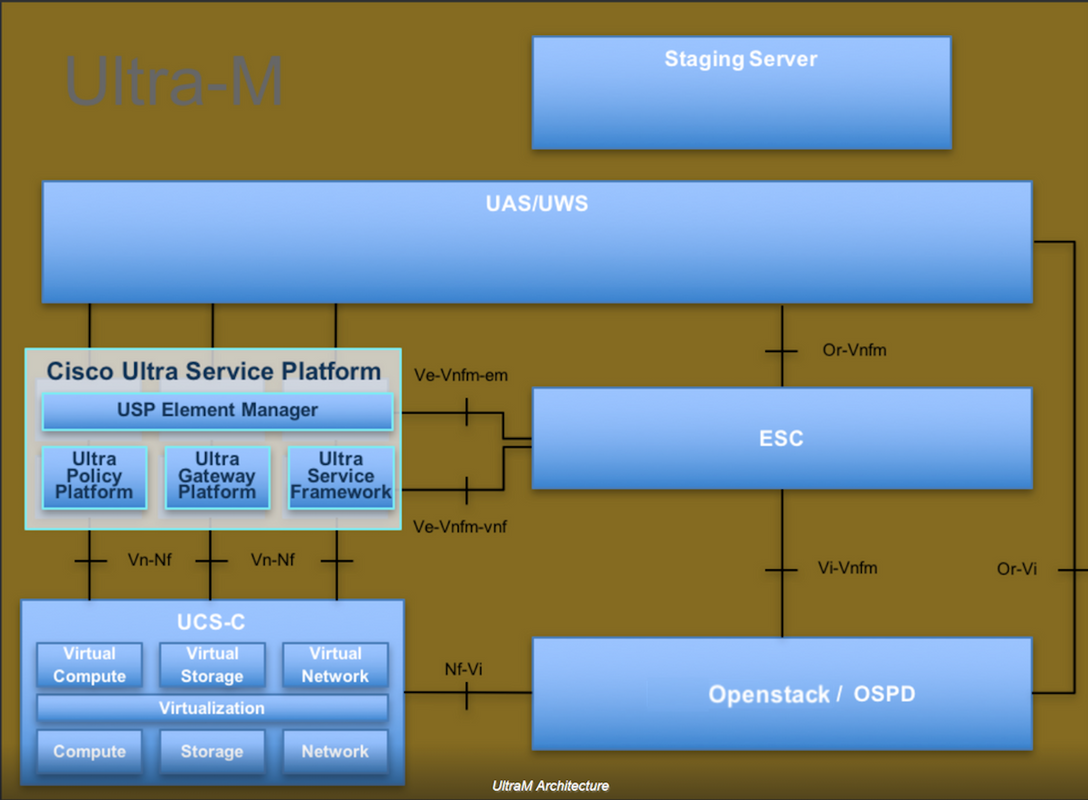
Ultra-M是预打包和验证的虚拟化移动数据包核心解决方案,旨在简化虚拟网络功能(VNF)的部署。 OpenStack是Ultra-M的虚拟基础设施管理器(VIM),由以下节点类型组成:
- 计算
- 对象存储磁盘 — 计算(OSD — 计算)
- 控制器
- OpenStack平台 — 导向器(OSPD)
此图中描述了Ultra-M的高级体系结构和涉及的组件:
本文档面向熟悉Cisco Ultra-M平台的思科人员,并详细介绍在更换OSPD服务器时在OpenStack级别执行所需的步骤。
注意:为了定义本文档中的步骤,我们考虑了Ultra M 5.1.x版本。
缩写
| VNF | 虚拟网络功能 |
| MoP | 程序方法 |
| OSD | 对象存储磁盘 |
| OSPD | OpenStack平台导向器 |
| 硬盘 | 硬盘驱动器 |
| SSD | 固态驱动器 |
| VIM | 虚拟基础设施管理器 |
| 虚拟机 | 虚拟机 |
| EM | 元素管理器 |
| UAS | 超自动化服务 |
| UUID | 通用唯一标识符 |
MoP工作流
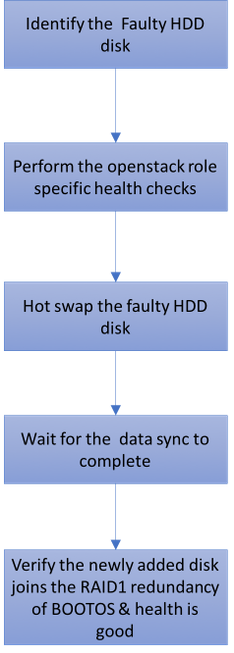
单硬盘故障
- 每台裸机服务器都配置了两个HDD驱动器,以在Raid 1配置中充当BOOT DISK。在单个HDD发生故障时,由于存在RAID 1级冗余,故障HDD驱动器可以热插拔。
- 有关更换UCS C240 M4服务器上故障组件的步骤,请参阅:更换服务器组件。
- 如果单个HDD发生故障,则仅热交换故障HDD,因此更换新磁盘后无需BIOS升级过程。
- 更换磁盘后,必须等待磁盘之间的数据同步。可能需要数小时才能完成。
- 在基于OpenStack(Ultra-M)的解决方案中,UCS 240M4裸机服务器可以承担以下角色之一:计算、OSD — 计算、控制器和OSPD。在这些服务器角色中处理单个HDD故障所需的步骤相同,此部分介绍在热交换磁盘之前要执行的运行状况检查。
计算服务器上的单硬盘故障
- 如果UCS 240M4(充当计算节点)中观察到HDD驱动器故障,请在执行故障磁盘热插拔之前执行此运行状况检查。
- 确定在此服务器上运行的VM,并验证功能状态是否正常。
识别托管在计算节点中的虚拟机
确定托管在计算服务器上的VM,并验证它们是否处于活动状态并正在运行。
[stack@director ~]$ nova list | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
运行状况检查
步骤1.在操作系统(OS)级别运行命令/opt/CSCOar/bin/arstatus。
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
步骤2.在操作系统级别运行命令/opt/CSCOar/bin/aregcmd并输入管理员凭证。验证CPAR运行状况是10/10,并退出CPAR CLI。
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
步骤3.运行命令netstat | grep diameter并验证是否已建立所有Diameter路由代理(DRA)连接。
此处提到的输出适用于需要Diameter链路的环境。如果显示的链路较少,则表示与需要分析的DRA断开。
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
步骤4.检查TPS日志是否显示CPAR正在处理的请求。突出显示的值代表TPS,这些值是您需要注意的值。
TPS的值不得超过1500。
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
步骤5.在name_radius_1_log中查找任何“错误”或“警报”消息
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
步骤6.要验证CPAR进程使用的内存量,请运行以下命令:
top | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
此突出显示值必须低于7Gb,这是应用级别允许的最大值。
步骤7.要验证磁盘利用率,请运行命令df -h。
[root@aaa02 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg_arucsvm51-lv_root 26G 21G 4.1G 84% / tmpfs 1.9G 268K 1.9G 1% /dev/shm /dev/sda1 485M 37M 424M 8% /boot /dev/mapper/vg_arucsvm51-lv_home 23G 4.3G 17G 21% /home
此总值必须低于80%,如果超过80%,则识别不必要的文件并进行清理。
步骤8.检验是否未生成“核心”文件。
- 当CPAR无法处理异常时,在应用崩溃时生成核心文件,并在以下两个位置生成:
[root@aaa02 ~]# cd /cisco-ar/ [root@aaa02 ~]# cd /cisco-ar/bin
这两个位置中不得有任何核心文件。如果找到,请提交Cisco TAC案例,以确定此类异常的根本原因,并附加核心文件进行调试。
- 如果运行状况检查正常,请继续执行故障磁盘热插拔过程,并等待数据同步,因为需要数小时才能完成。
- 重复运行状况检查步骤,以确认托管在计算节点上的虚拟机的运行状况已恢复。
控制器服务器上的单硬盘故障
- 如果UCS 240M4(充当控制器节点)中观察到HDD驱动器故障,请在执行故障磁盘热插拔之前执行这些运行状况检查。
- 检查控制器上的Pacemaker状态。
- 登录到其中一个活动控制器并检查起搏器状态。所有服务必须在可用控制器上运行,并在故障控制器上停止。
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Tue Jul 10 10:04:15 2018Last change: Fri Jul 6 09:03:35 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
- 检查活动控制器中的MariaDB状态。
[stack@director ~]$ nova list | grep control
| b896c73f-d2c8-439c-bc02-7b0a2526dd70 | pod2-stack-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.113 |
| 2519ce67-d836-4e5f-a672-1a915df75c7c | pod2-stack-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| e19b9625-5635-4a52-a369-44310f3e6a21 | pod2-stack-controller-2 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
[stack@director ~]$ for i in 192.200.0.102 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_ state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st5 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st3 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_s1 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_9 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local2 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_loca. ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_loc2 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_lo0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_l0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_. ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsre. ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsr1 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'ws2 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'w0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE '
*** 192.200.0.102 ***
Variable_nameValue
wsrep_local_state_commentSynced
Variable_nameValue
wsrep_cluster_size2
*** 192.200.0.110 ***
Variable_nameValue
wsrep_local_state_commentSynced
Variable_nameValue
wsrep_cluster_size2
- 验证每个活动控制器都存在以下线路:
wsrep_local_state_comment: Synced wsrep_cluster_size: 2
- 在活动控制器中检查Rabbitmq状态。
[heat-admin@pod2-stack-controller-0 ~]$ sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod2-stack-controller-0' ...
[{nodes,[{disc,['rabbit@pod2-stack-controller-0',
'rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-2']}]},
{running_nodes,['rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-2',
'rabbit@pod2-stack-controller-0']},
{cluster_name,<<"rabbit@pod2-stack-controller-1.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod2-stack-controller-1',[]},
{'rabbit@pod2-stack-controller-2',[]},
{'rabbit@pod2-stack-controller-0',[]}]}]
- 如果运行状况检查正常,请继续执行故障磁盘热插拔过程,并等待数据同步,因为需要数小时才能完成。
- 重复运行状况检查步骤,以确认控制器的运行状况已恢复。
OSD-Compute服务器上的单硬盘故障
- 如果UCS 240M4(充当OSD计算节点)中观察到HDD驱动器故障,请在执行故障磁盘热插拔之前执行运行状况检查。
- 识别OSD计算节点中托管的虚拟机
- 确定托管在计算服务器上的虚拟机
[stack@director ~]$ nova list | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
- CEPH进程在osd-compute服务器上处于活动状态。
[heat-admin@pod2-stack-osd-compute-1 ~]$ systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d1.mount loaded active mounted /var/lib/ceph/osd/ceph-1
var-lib-ceph-osd-ceph\x2d10.mount loaded active mounted /var/lib/ceph/osd/ceph-10
var-lib-ceph-osd-ceph\x2d4.mount loaded active mounted /var/lib/ceph/osd/ceph-4
var-lib-ceph-osd-ceph\x2d7.mount loaded active mounted /var/lib/ceph/osd/ceph-7
ceph-osd@1.service loaded active running Ceph object storage daemon
ceph-osd@10.service loaded active running Ceph object storage daemon
ceph-osd@4.service loaded active running Ceph object storage daemon
ceph-osd@7.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
14 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
- 验证OSD(硬盘)到日志(SSD)的映射是否正常。
[heat-admin@pod2-stack-osd-compute-1 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
- 验证CEPH运行状况和OSD树映射是否正常。
[heat-admin@pod2-stack-osd-compute-1 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e81: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v23095222: 704 pgs, 6 pools, 809 GB data, 424 kobjects
2418 GB used, 10974 GB / 13393 GB avail
704 active+clean
client io 1329 kB/s wr, 0 op/s rd, 122 op/s wr
[heat-admin@pod2-stack-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod2-stack-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod2-stack-osd-compute-1
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod2-stack-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
- 如果运行状况检查正常,请继续执行故障磁盘热插拔过程,并等待数据同步,因为它需要数小时才能完成。
- 重复运行状况检查步骤,以确认托管在OSD-Compute节点上的虚拟机的运行状况已恢复。
OSPD服务器上的单硬盘故障
- 如果UCS 240M4(充当OSPD节点)中观察到HDD驱动器故障,请在执行故障磁盘热插拔之前执行运行状况检查。
- 检查openstack堆栈和节点列表的状态。
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
- 检查所有下云服务是否都处于从OSP-D节点加载、活动和运行状态。
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-metadata-agent.service loaded active running OpenStack Neutron Metadata Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
lines 1-43
lines 2-44 37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
lines 4-46/46 (END) lines 4-46/46 (END) lines 4-46/46 (END) lines 4-46/46 (END) lines 4-46/46 (END)
- 如果运行状况检查正常,请继续执行故障磁盘热插拔过程,并等待数据同步,因为它需要数小时才能完成。
- 重复运行状况检查步骤,以确认OSPD节点的运行状况已恢复。
 反馈
反馈