Introdução
Este documento descreve o procedimento para recuperar o Cluster Manager do servidor inicial na configuração da Plataforma de Implantação Nativa na Nuvem (CNDP).
Pré-requisitos
Requisitos
A Cisco recomenda que você tenha conhecimento destes tópicos:
- Infraestrutura Cisco Subscriber Microservices (SMI)
- Arquitetura 5G CNDP ou SMI-Bare-metal (BM)
- DRBD (Distributed Replicated Block Device, dispositivo de bloco replicado distribuído)
Componentes Utilizados
As informações neste documento são baseadas nestas versões de software e hardware:
- SMI 2020.2.2.35
- Kubernetes v1.21.0
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a rede estiver ativa, certifique-se de que você entenda o impacto potencial de qualquer comando.
Informações de Apoio
O que é o SMI Cluster Manager?
Um gerenciador de cluster é um cluster keepalived de 2 nós usado como o ponto inicial para implantação de cluster de plano de controle e plano do usuário. Ele executa um cluster Kubernetes de nó único e um conjunto de PODs que são responsáveis por toda a configuração do cluster. Somente o gerenciador de cluster primário está ativo e o secundário assume somente em caso de falha ou é desativado manualmente para manutenção.
O que é um servidor de início?
Esse nó executa o gerenciamento do ciclo de vida do Cluster Manager (CM) que está subjacente e, a partir dele, você pode enviar a configuração Day0.
Esse servidor geralmente é implantado em toda a região ou no mesmo data center que a função de orquestração de nível superior (por exemplo, NSO) e geralmente é executado como uma VM.
Problema
O gerenciador de cluster é hospedado em um cluster de 2 nós com DRBD (Distributed Replicated Block Device) e mantido ativo como Cluster Manager primário e Cluster Manager secundário. Nesse caso, o Cluster Manager secundário entra no estado desligado automaticamente enquanto a inicialização/instalação do SO no UCS indica que o SO está corrompido.
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 WFConnection Primary/Unknown UpToDate/DUnknown /mnt/stateful_partition ext4 568G 369G 170G 69%
Procedimento de manutenção
Esse processo ajuda a reinstalar o SO no servidor CM.
Identificar hosts
Faça login no Cluster-Manager e identifique os hosts:
cloud-user@POD-NAME-cm-primary:~$ cat /etc/hosts | grep 'deployer-cm'
127.X.X.X POD-NAME-cm-primary POD-NAME-cm-primary
X.X.X.X POD-NAME-cm-primary
X.X.X.Y POD-NAME-cm-secondary
Identificar Detalhes do Cluster do Servidor Inicial
Faça login no servidor Inception, entre no Implantador e verifique o nome do cluster com hosts-IP do Cluster-Manager.
Após o login bem-sucedido no servidor inicial, efetue login no centro de operações como mostrado aqui.
user@inception-server: ~$ ssh -p 2022 admin@localhost
Verifique o nome do cluster a partir do gerenciador de cluster SSH-IP (ssh-ip = endereço IP do nó SSH = endereço ip cimc do servidor ucs).
[inception-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | tab
SSH
NAME NAME IP SSH IP IP ADDRESS
------------------------------------------------------------------------------
POD-NAME-deployer cm-primary - X.X.X.X 10.X.X.X ---> Verify Name and SSH IP if Cluster is part of inception server SMI.
cm-secondary - X.X.X.Y 10.X.X.Y
Verifique a configuração do cluster de destino.
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME-deployer
Remova a unidade virtual para limpar o sistema operacional do servidor
Conecte-se ao CIMC do host afetado, limpe a unidade de inicialização e exclua a unidade virtual (VD).
a) CIMC > Storage > Cisco 12G Modular Raid Controller > Storage Log > Clear Boot Drive
b) CIMC > Storage > Cisco 12G Modular Raid Controller > Virtual drive > Select the virtual drive > Delete Virtual Drive
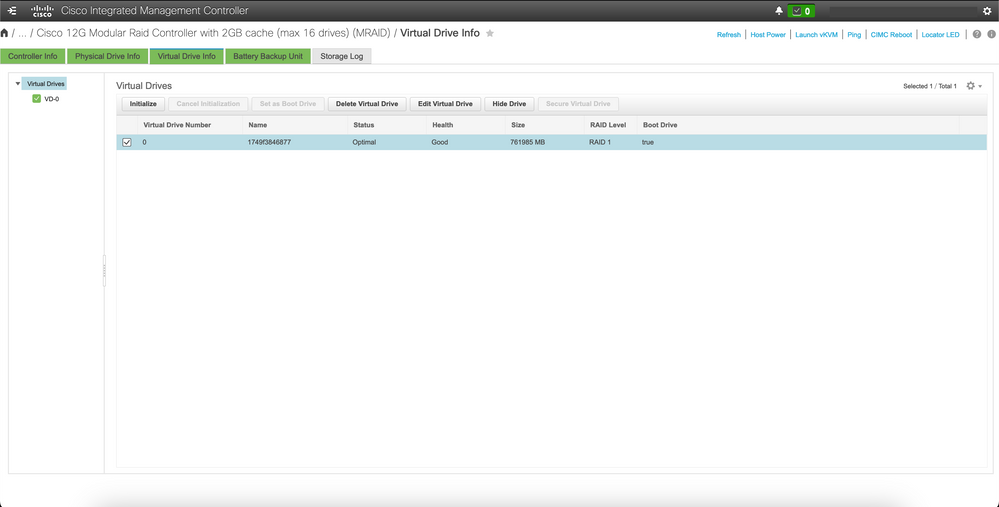
Executar Sincronização de Cluster
Execute a sincronização de cluster padrão para o Cluster-Manager a partir do servidor de origem.
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
Se a sincronização de cluster padrão falhar, execute a sincronização de cluster com a opção de reimplantação force-vm para a reinstalação completa (a atividade de sincronização de cluster pode levar de 45 a 55 minutos para ser concluída, dependendo do número de nós hospedados no cluster)
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true force-vm-redeploy true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
Monitorar os Logs de Sincronização de Sincronização de Cluster
[inception-server] SMI Cluster Deployer# monitor sync-logs POD-NAME-deployer
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Cluster name: POD-NAME
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Force VM Redeploy: true
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: Force partition Redeploy: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: reset_k8s_nodes: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: purge_data_disks: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: upgrade_strategy: auto
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: sync_phase: all
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: debug: true
...
...
...
O servidor é provisionado novamente e instalado por sincronização de cluster bem-sucedida.
PLAY RECAP *********************************************************************
cm-primary : ok=535 changed=250 unreachable=0 failed=0 skipped=832 rescued=0 ignored=0
cm-secondary : ok=299 changed=166 unreachable=0 failed=0 skipped=627 rescued=0 ignored=0
localhost : ok=59 changed=8 unreachable=0 failed=0 skipped=18 rescued=0 ignored=0
Thursday 23 February 2023 13:17:24 +0000 (0:00:00.109) 0:56:20.544 *****. ---> ~56 mins to complete cluster sync
===============================================================================
2023-02-23 13:17:24.539 DEBUG cluster_sync.POD-NAME: Cluster sync successful
2023-02-23 13:17:24.546 DEBUG cluster_sync.POD-NAME: Ansible sync done
2023-02-23 13:17:24.546 INFO cluster_sync.POD-NAME: _sync finished. Opening lock
Verificação
Verifique se o Gerenciador de cluster afetado está acessível e se a visão geral do DRBD dos Gerenciadores de cluster primário e secundário está no status Atualizado.
cloud-user@POD-NAME-cm-primary:~$ ping X.X.X.Y
PING X.X.X.Y (X.X.X.Y) 56(84) bytes of data.
64 bytes from X.X.X.Y: icmp_seq=1 ttl=64 time=0.221 ms
64 bytes from X.X.X.Y: icmp_seq=2 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=3 ttl=64 time=0.151 ms
64 bytes from X.X.X.Y: icmp_seq=4 ttl=64 time=0.154 ms
64 bytes from X.X.X.Y: icmp_seq=5 ttl=64 time=0.172 ms
64 bytes from X.X.X.Y: icmp_seq=6 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=7 ttl=64 time=0.174 ms
--- X.X.X.Y ping statistics ---
7 packets transmitted, 7 received, 0% packet loss, time 6150ms
rtt min/avg/max/mdev = 0.151/0.171/0.221/0.026 ms
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 Connected Primary/Secondary UpToDate/UpToDate /mnt/stateful_partition ext4 568G 17G 523G 4%
O gerenciador de cluster afetado foi instalado e provisionado novamente na rede com êxito.
2.2 Verifique o nome do cluster no gerenciador de cluster SSH-IP.
[servidor de início] SMI Cluster Deployer# show running-config clusters * nós * k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | guia
SSH
NOME NOME IP SSH IP ENDEREÇO IP
------------------------------------------------------------------------------
POD-NAME cm-primary - 192.X.X.X 10.192.X.X
cm-secondary - 192.X.X.Y 10.192.X.Y
*SSH IP = nó SSH IP
*ENDEREÇO IP = ucs-server cimc ip-address
2.3 Verifique a configuração do cluster de destino.
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME Faça login no servidor Inception e entre no Deployer e verifique cluster-name com hosts-IP do Cluster-Manager. Faça login no servidor Inception, entre no Implantador e verifique cluster-name com hosts-IP do Cluster-Manager.
 Feedback
Feedback