Substituição do servidor OSPD UCS 240M4 - CPS
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento descreve as etapas necessárias para substituir um servidor defeituoso que hospeda o OSPD (OpenStack Platform Diretor) em uma configuração Ultra-M.
Informações de Apoio
O Ultra-M é uma solução de núcleo de pacotes móveis virtualizados, pré-embalada e validada, projetada para simplificar a implantação de VNFs. O OpenStack é o Virtualized Infrastructure Manager (VIM) para Ultra-M e consiste nos seguintes tipos de nó:
- Computação
- Disco de Armazenamento de Objeto - Computação (OSD - Compute)
- Controlador
- Plataforma OpenStack - Diretor (OSPD)
A arquitetura de alto nível da Ultra-M e os componentes envolvidos são mostrados nesta imagem.
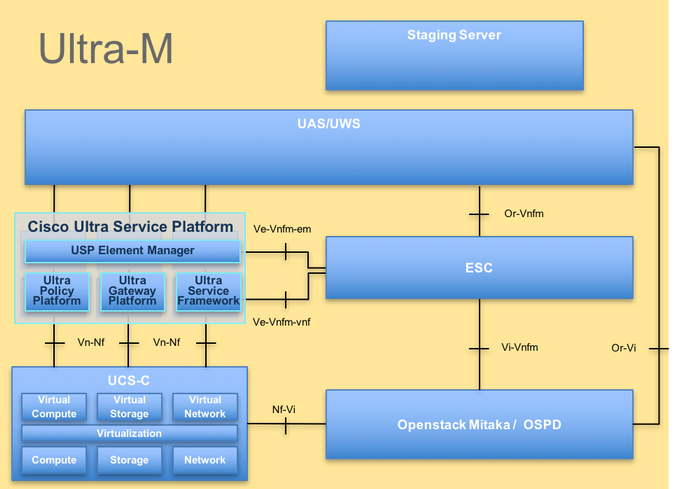 Arquitetura UltraM
Arquitetura UltraM
Note: A versão Ultra M 5.1.x é considerada para definir os procedimentos neste documento. Este documento destina-se ao pessoal da Cisco familiarizado com a plataforma Cisco Ultra-M e detalha as etapas necessárias para serem executadas no nível OpenStack no momento da substituição do servidor OSPD.
Abreviaturas
| VNF | Função de rede virtual |
| ESC | Controlador de serviço elástico |
| MOP | Método de Procedimento |
| OSD | Discos de Armazenamento de Objeto |
| HDD | Unidade de disco rígido |
| SSD | Unidade de estado sólido |
| VIM | Virtual Infrastructure Manager |
| VM | Máquina virtual |
| EM | Gestor de Elementos |
| UAS | Ultra Automation Services |
| UUID | Identificador de ID universal exclusivo |
Fluxo de trabalho do MoP
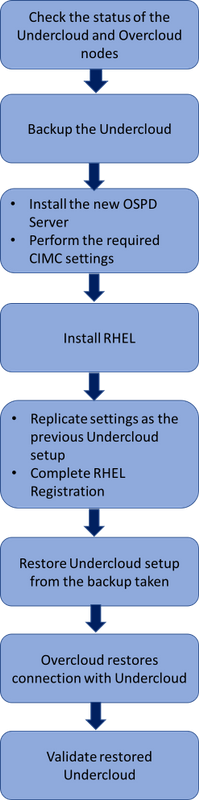 Fluxo de trabalho de alto nível do procedimento de substituição
Fluxo de trabalho de alto nível do procedimento de substituição
Prerequisites
Verificação de status
Antes de substituir um servidor OSPD, é importante verificar o estado atual do ambiente da plataforma Red Hat OpenStack e garantir que ele esteja saudável para evitar complicações quando o processo de substituição estiver ativo.
1. Verifique o status da pilha do OpenStack e a lista de nós.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
2. Verifique se todos os serviços em nuvem estão no status carregado, ativo e em execução no nó OSPD.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
Backup
1. Confirme se você tem espaço em disco suficiente disponível antes de executar o processo de backup. Espera-se que este touro tenha pelo menos 3,5 GB.
[stack@director ~]$df -h
2. Execute esses comandos como o usuário raiz para fazer backup dos dados do nó de nuvem para um arquivo chamado undercloud-backup-[timestamp].tar.gz.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Instalar o novo nó OSPD
Instalação do servidor UCS
1. As etapas para instalar um novo servidor UCS C240 M4 e as etapas de configuração inicial podem ser consultadas aqui: Guia de instalação e serviço do servidor Cisco UCS C240 M4
2. Faça login no servidor usando o CIMC IP.
3. Execute a atualização do BIOS se o firmware não estiver de acordo com a versão recomendada usada anteriormente. As etapas para a atualização do BIOS são fornecidas aqui: Guia de atualização do BIOS de servidor com montagem em rack Cisco UCS C-Series
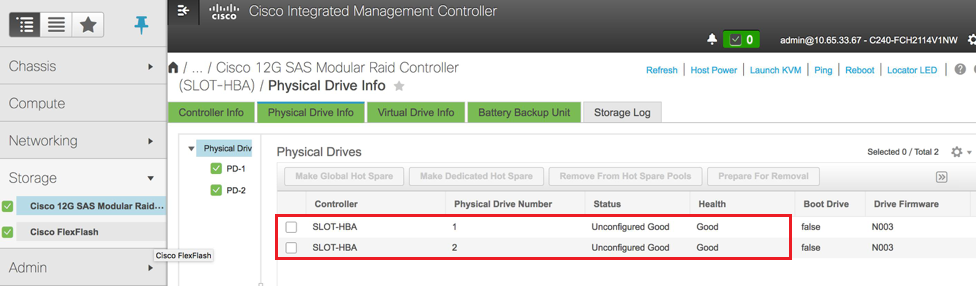
4. Verifique o status das unidades físicas. Ele deve ser "Não configurado como bom". Navegue até Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Physical Drive Info (Armazenamento > Informações da unidade física conforme mostrado nesta imagem.
5. Crie uma unidade virtual a partir das unidades físicas com RAID Nível 1. Navegue até Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives conforme mostrado nesta imagem.
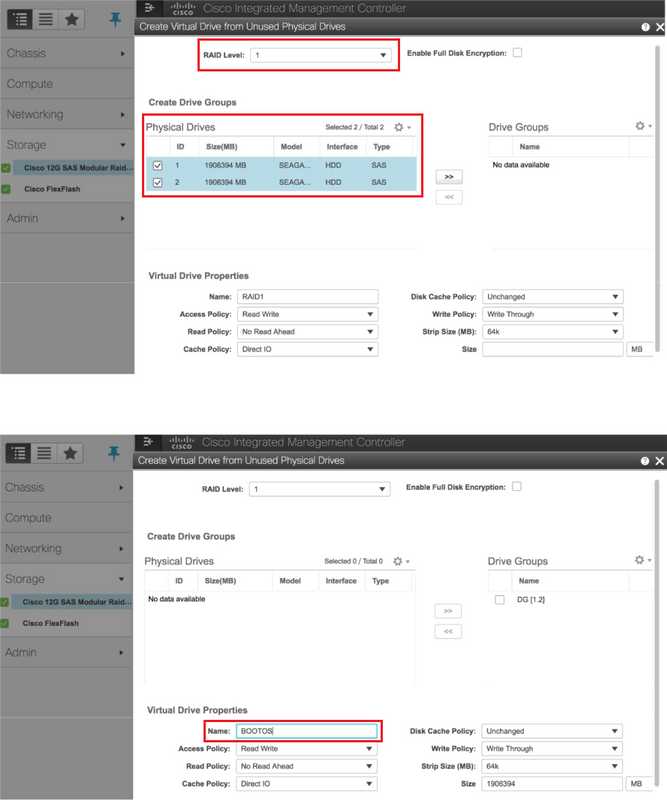
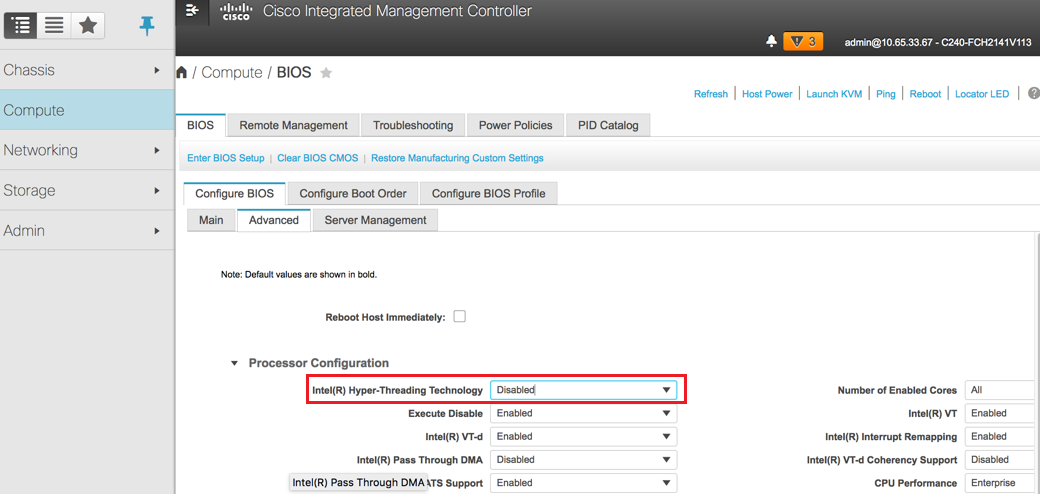
6. Selecione o VD e configure "Set as Boot Drive" (Definir como unidade de inicialização) como mostrado nesta imagem.
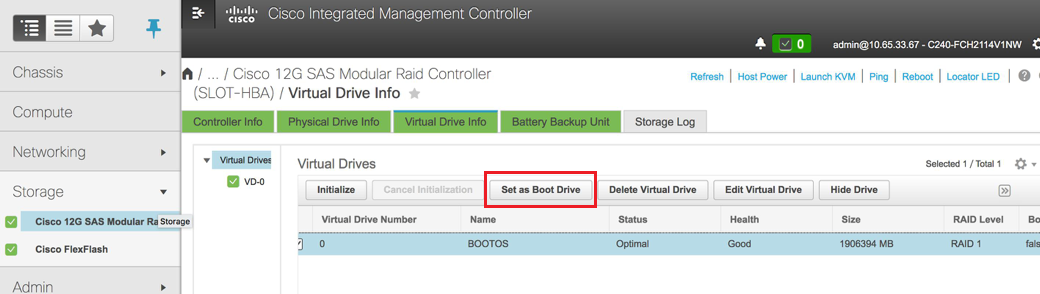
7. Ative IPMI na LAN. Navegue até Admin > Communication Services > Communication Services conforme mostrado nesta imagem.
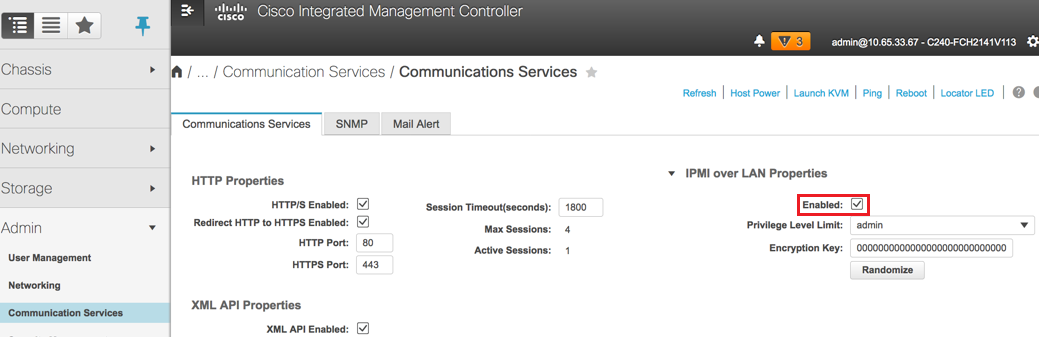
8. Desative o hyperthreading. Navegue até Compute > BIOS > Configure BIOS > Advanced > Processor Configuration conforme mostrado nesta imagem.
Note: A imagem mostrada aqui e as etapas de configuração mencionadas nesta seção referem-se à versão de firmware 3.0(3e) e pode haver pequenas variações se você trabalhar em outras versões.
Instalação do Redhat
Monte a imagem ISO do Red Hat
1. Fazer login no servidor OSP-D
2. Iniciar o console KVM
3. Selecione Virtual Media > Ativate Virtual Devices. Aceite a sessão e ative a memória de sua configuração para conexões futuras.
4. Selecione Virtual Media > Mapear CD/DVD e mapeie a imagem ISO da Red Hat.
5. Selecione Power > Reset System (Warm Boot) (Alimentação > Redefinir sistema (inicialização em modo de aquecimento) para reinicializar o sistema.
6. Após reiniciar, pressione F6 e selecione Cisco vKVM-Mapped vDVD1.22 e pressione Enter.
7. Instale o RHEL.
Note: O procedimento nesta seção representa uma versão simplificada do processo de instalação que identifica o número mínimo de parâmetros que devem ser configurados.
8. Selecione a opção para instalar o Red Hat Enterprise Linux para iniciar a instalação
9. Selecionar seleção de software > Somente instalação mínima
10. Configurar interfaces de rede (eno1 e eno2)
11. Clique em Rede e nome do host.
- Selecione a interface que seria usada para comunicação externa (eno1 ou eno2)
- Clique em Configurar
- Selecione a guia IPv4 Settings (Configurações IPv4), Select Manual method (Selecionar método manual) e clique em Add (Adicionar)
- Defina os seguintes parâmetros como usados anteriormente: Endereço, máscara de rede, Gateway, servidor DNS
12. Selecione Data e hora e especifique sua região e cidade.
13. Habilite o tempo de rede e configure os servidores NTP.
14. Selecione Destino da instalação e use o sistema de arquivos ext4.
Note: Exclua ‘/home/’ e realoque a capacidade na raiz '/'.
15. Desative o Kdump.
16. Definir apenas a senha raiz.
17. Inicie a instalação .
Restaure a nuvem inferior
Prepare a instalação da nuvem subjacente ao backup
Quando a máquina estiver instalada com o RHEL 7.3 e em um estado limpo, reative todas as assinaturas/repositórios necessários para instalar e executar o direcionador.
1. Configuração do nome de host.
[root@director ~]$sudo hostnamectl set-hostname <FQDN_hostname>
[root@director ~]$sudo hostnamectl set-hostname --transient <FQDN_hostname>
2. Editar /etc/hosts arquivo.
[root@director ~]$ vi /etc/hosts
<ospd_external_address> <server_hostname> <FQDN_hostname>
10.225.247.142 pod1-ospd pod1-ospd.cisco.com
3. Validar o nome do host.
[root@director ~]$ cat /etc/hostname
pod1-ospd.cisco.com
4. Valide a configuração DNS.
[root@director ~]$ cat /etc/resolv.conf
#Generated by NetworkManager
nameserver <DNS_IP>
5. Modifique a interface nic de provisionamento.
[root@director ~]$ cat /etc/sysconfig/network-scripts/ifcfg-eno1
DEVICE=eno1
ONBOOT=yes
HOTPLUG=no
NM_CONTROLLED=no
PEERDNS=no
DEVICETYPE=ovs
TYPE=OVSPort
OVS_BRIDGE=br-ctlplane
BOOTPROTO=none
MTU=1500
Preencha o registro do Redhat
1. Baixe este pacote para configurar o gerenciador de assinatura para usar rh-satélite.
[root@director ~]$ rpm -Uvh http:///pub/katello-ca-consumer-latest.noarch.rpm
[root@director ~]$ subscription-manager config
2. Registre-se com rh-satélite usando esta chave de ativação para RHEL 7.3.
[root@director ~]$subscription-manager register --org="<ORG>" --activationkey="<KEY>"
3. Para ver a assinatura.
[root@director ~]$ subscription-manager list –consumed
4. Habilite os repositórios como acordos de recompra OSPD antigos.
[root@director ~]$ sudo subscription-manager repos --disable=*
[root@director ~]$ subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-extras-rpms --enable=rh
el-7-server-openstack-10-rpms --enable=rhel-7-server-rh-common-rpms --enable=rhel-ha-for-rhel-7-server-rpm
5. Atualize o sistema para garantir que você tenha os pacotes básicos mais recentes e reinicialize o sistema.
[root@director ~]$sudo yum update -y
[root@director ~]$sudo reboot
Restauração da Subnuvem
Depois de habilitar a assinatura, importe o arquivo tar oculto com backup em nuvem undercloud-backup-`date +%F`.tar.gz para o novo diretório raiz/raiz do servidor OSPD.
1. Instale o servidor mariadb.
[root@director ~]$ yum install -y mariadb-server
2. Extraia o arquivo de configuração de MariaDB e backup de banco de dados. Execute esta operação como usuário raiz.
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/my.cnf.d/server.cnf
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz root/undercloud-all-databases.sql
3. Edite /etc/my.cnf.d/server.cnf e comente a entrada do endereço de associação, se houver.
[root@tb3-ospd ~]# vi /etc/my.cnf.d/server.cnf
4. Inicie o serviço MariaDB e atualize temporariamente a configuração max_allowed_packet:
[root@director ~]$ systemctl start mariadb
[root@director ~]$ mysql -uroot -e"set global max_allowed_packet = 16777216;"
5. Limpe certas permissões (para ser recriado mais tarde):
[root@director ~]$ for i in ceilometer glance heat ironic keystone neutron nova;do mysql -e "drop user $i";done
[root@director ~]$ mysql -e 'flush privileges'
Note: Se o serviço do teto tiver sido desabilitado anteriormente na configuração, execute o comando acima removendo o "teto".
6. Crie a conta stackuser.
[root@director ~]$ sudo useradd stack
[root@director ~]$ sudo passwd stack << specify a password
[root@director ~]$ echo "stack ALL=(root) NOPASSWD:ALL" | sudo tee -a /etc/sudoers.d/stack
[root@director ~]$ sudo chmod 0440 /etc/sudoers.d/stack
7. Restaure o diretório inicial do usuário da pilha.
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz home/stack
8. Instale os pacotes base swift e Glance e restaure seus dados.
[root@director ~]$ yum install -y openstack-glance openstack-swift
[root@director ~]$ tar --xattrs -xzC / -f undercloud-backup-$DATE.tar.gz srv/node var/lib/glance/images
9. Confirme se os dados pertencem ao usuário correto.
[root@director ~]$ chown -R swift: /srv/node
[root@director ~]$ chown -R glance: /var/lib/glance/images
10. Restaure os certificados SSL em nuvem (opcional - a ser feito somente se a configuração usar certificados SSL).
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/instack-certs/undercloud.pem
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/ca-trust/source/anchors/ca.crt.pem
11. Execute novamente a instalação em nuvem como o usuário da pilha, certificando-se de executá-la no diretório inicial do usuário da pilha.
[root@director ~]$ su - stack
[stack@director ~]$ sudo yum install -y python-tripleoclient
12. Confirme se o nome do host está definido corretamente em /etc/hosts.
13. Reinstale a nuvem inferior.
[stack@director ~]$ openstack undercloud install
<snip>
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and must be
secured.
#############################################################################
Reconecte a subnuvem restaurada à nuvem geral
Após concluir essas etapas, é esperado que a nuvem inferior restaure automaticamente sua conexão com a nuvem. Os nós continuarão a pesquisar orquestração (calor) para tarefas pendentes, com o uso de uma simples solicitação HTTP emitida a cada poucos segundos.
Validar a restauração concluída
Use estes comandos para executar uma verificação de integridade do seu ambiente recém-restaurado.
[root@director ~]$ su - stack
Last Log in: Tue Nov 28 21:27:50 EST 2017 from 10.86.255.201 on pts/0
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| b1f5294a-629e-454c-b8a7-d15e21805496 | pod1-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.119 |
| 9106672e-ac68-423e-89c5-e42f91fefda1 | pod1-compute-1 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
| b3ed4a8f-72d2-4474-91a1-b6b70dd99428 | pod1-compute-2 | ACTIVE | - | Running | ctlplane=192.200.0.124 |
| 677524e4-7211-4571-ac35-004dc5655789 | pod1-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.107 |
| 55ea7fe5-d797-473c-83b1-d897b76a7520 | pod1-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.122 |
| c34c1088-d79b-42b6-9306-793a89ae4160 | pod1-compute-5 | ACTIVE | - | Running | ctlplane=192.200.0.108 |
| 4ba28d8c-fb0e-4d7f-8124-77d56199c9b2 | pod1-compute-6 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| d32f7361-7e73-49b1-a440-fa4db2ac21b1 | pod1-compute-7 | ACTIVE | - | Running | ctlplane=192.200.0.106 |
| 47c6a101-0900-4009-8126-01aaed784ed1 | pod1-compute-8 | ACTIVE | - | Running | ctlplane=192.200.0.121 |
| 1a638081-d407-4240-b9e5-16b47e2ff6a2 | pod1-compute-9 | ACTIVE | - | Running | ctlplane=192.200.0.112 |
<snip>
[stack@director ~]$ ssh heat-admin@192.200.0.107
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.1.10.10 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.97 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-192.200.0.106 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.95 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.98 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.92 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Stopped
Failed Actions:
* my-ipmilan-for-controller-0_start_0 on pod1-controller-1 'unknown error' (1): call=190, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-1 'unknown error' (1): call=192, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-1 'unknown error' (1): call=188, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-0 'unknown error' (1): call=210, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-0 'unknown error' (1): call=207, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-0 'unknown error' (1): call=206, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20006ms
* ip-192.200.0.106_monitor_10000 on pod1-controller-0 'not running' (7): call=197, status=complete, exitreason='none',
last-rc-change='Wed Nov 22 13:51:31 2017', queued=0ms, exec=0ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-2 'unknown error' (1): call=183, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=1ms, exec=20006ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-2 'unknown error' (1): call=184, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-2 'unknown error' (1): call=177, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:02 2017', queued=0ms, exec=20005ms
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[heat-admin@pod1-controller-0 ~]$ sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v1245812: 704 pgs, 6 pools, 542 GB data, 352 kobjects
1625 GB used, 11767 GB / 13393 GB avail
704 active+clean
client io 21549 kB/s wr, 0 op/s rd, 120 op/s wr
Verificar a operação do serviço de identidade (Keystone)
Esta etapa valida as operações do serviço de identidade consultando uma lista de usuários.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack user list
+----------------------------------+------------------+
| ID | Name |
+----------------------------------+------------------+
| 69ac2b9d89414314b1366590c7336f7d | admin |
| f5c30774fe8f49d0a0d89d5808a4b2cc | glance |
| 3958d852f85749f98cca75f26f43d588 | heat |
| cce8f2b7f1a843a08d0bb295a739bd34 | ironic |
| ce7c642f5b5741b48a84f54d3676b7ee | ironic-inspector |
| a69cd42a5b004ec5bee7b7a0c0612616 | mistral |
| 5355eb161d75464d8476fa0a4198916d | neutron |
| 7cee211da9b947ef9648e8fe979b4396 | nova |
| f73d36563a4a4db482acf7afc7303a32 | swift |
| d15c12621cbc41a8a4b6b67fa4245d03 | zaqar |
| 3f0ed37f95544134a15536b5ca50a3df | zaqar-websocket |
+----------------------------------+------------------+
[stack@director ~]$
[stack@director ~]$ source <overcloudrc>
[stack@director ~]$ openstack user list
+----------------------------------+------------+
| ID | Name |
+----------------------------------+------------+
| b4e7954942184e2199cd067dccdd0943 | admin |
| 181878efb6044116a1768df350d95886 | neutron |
| 6e443967ee3f4943895c809dc998b482 | heat |
| c1407de17f5446de821168789ab57449 | nova |
| c9f64c5a2b6e4d4a9ff6b82adef43992 | glance |
| 800e6b1163b74cc2a5fab4afb382f37d | cinder |
| 4cfa5a2a44c44c678025842f080e5f53 | heat-cfn |
| 9b222eeb8a58459bb3bfc76b8fff0f9f | swift |
| 815f3f25bcda49c290e1b56cd7981d1b | core |
| 07c40ade64f34a64932129175150fa4a | gnocchi |
| 0ceeda0bc32c4d46890e53adef9a193d | aodh |
| f3caab060171468592eab376a94967b8 | ceilometer |
+----------------------------------+------------+
[stack@director ~]$
Carregar imagens para introdução ao nó futuro
Valide /httpboot todos esses arquivos inspetor.ipxe, agent.kernel, agent.ramdisk. Caso contrário, siga estas etapas para atualizar em uma imagem.
[stack@director ~]$ ls /httpboot
inspector.ipxe
[stack@director ~]$ source stackrc
[stack@director ~]$ cd images/
[stack@director images]$ openstack overcloud image upload --image-path /home/stack/images
Image "overcloud-full-vmlinuz" is up-to-date, skipping.
Image "overcloud-full-initrd" is up-to-date, skipping.
Image "overcloud-full" is up-to-date, skipping.
Image "bm-deploy-kernel" is up-to-date, skipping.
Image "bm-deploy-ramdisk" is up-to-date, skipping.
[stack@director images]$ ls /httpboot
agent.kernel agent.ramdisk inspector.ipxe
[stack@director images]$
Reiniciando a vedação
A vedação estaria no estado parado após a recuperação do OSPD. Este procedimento ativará a vedação.
[heat-admin@pod1-controller-0 ~]$ sudo pcs property set stonith-enabled=true
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
[heat-admin@pod1-controller-0 ~]$sudo pcs stonith show
Informações Relacionadas
Colaborado por engenheiros da Cisco
- Aaditya DeodharCisco Advanced Services
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)