Técnicas de codificação de forma de onda
Contents
Introduction
Embora o ser humano esteja bem capacitado para comunicações analógicas, a transmissão analógica não é particularmente eficiente. Quando os sinais analógicos se tornam fracos devido à perda de transmissão, torna-se difícil separa a estrutura analógica complexa da estrutura do ruído de transmissão aleatório. Se amplificar os sinais analógicos, ele também amplificará os ruídos e, eventualmente, as conexões analógicas se tornarão ruidosas demais para serem usadas. Os sinais digitais, tendo somente os estados “one-bit” e o “zero-bit”, são separados mais facilmente do ruído. Eles podem ser amplificados sem corrompimento. A codificação digital é mais imune ao corrompimento por ruído em conexões de interurbanas. Além disso, os sistemas de comunicação do mundo foram convertidos para um formato de transmissão digital chamado modulação de código de pulso (PCM). PCM é um tipo de codificação denominada em forma de onda porque cria uma forma codificada da forma de onda de voz original. Este documento descreve em um nível superior o processo de conversão de sinais de voz analógicos em sinais digitais.
Prerequisites
Requirements
Não existem requisitos específicos para este documento.
Componentes Utilizados
Este documento não se restringe a versões de software e hardware específicas.
Conventions
For more information on document conventions, refer to the Cisco Technical Tips Conventions.
Modulação de código de pulso
O PCM é um método de codificação de forma de onda definido na especificação ITU-T G.711.
Filtrando
O primeiro passo para converter o sinal de analógico em digital é filtrar o componente de frequência mais alta do sinal. Isso torna as coisas mais fáceis de downstream para converter esse sinal. A maior parte da energia da língua falada está entre 200 ou 300 hertz e cerca de 2700 ou 2800 hertz. Aproximadamente 3000 hertz de largura de banda para comunicação de voz padrão e voz padrão é estabelecida. Portanto, não é preciso ter filtros precisos (é muito caro). Uma largura de banda de 4000 hertz é feita do ponto de vista do equipamento. Esse filtro limitador de banda é utilizado para evitar aliasing (anti-aliasing). Isso acontece quando o sinal de voz analógico de entrada é submetido a uma amostragem, definido pelo critério Nyquist como Fs < 2(BW). A frequência de amostragem é inferior à frequência mais alta do sinal analógico de entrada. Isso cria uma sobreposição entre o espectro de frequência das amostras e o sinal analógico de entrada. O filtro de saída de baixa passagem, usado para reconstruir o sinal de entrada original, não é inteligente o suficiente para detectar essa sobreposição. Portanto, cria um novo sinal que não se origina na origem. Essa criação de um sinal falso quando a amostragem é chamada de aliasing.
Amostragem
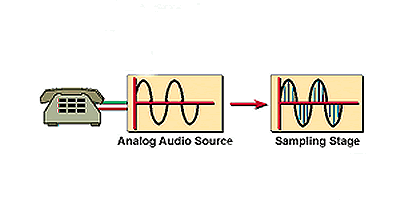
A segunda etapa para converter um sinal de voz analógico em um sinal de voz digital é coletar o sinal de entrada filtrado em uma frequência de amostragem constante. Ele é realizado usando um processo chamado modulação de amplitude de pulso (PAM). Esta etapa usa o sinal analógico original para modular a amplitude de um trem de pulso que tem uma amplitude e frequência constantes. (Veja a Figura 2).
O comboio de impulsos move-se a uma frequência constante, chamada de frequência de amostragem. O sinal de voz analógico pode ser amostrado a um milhão de vezes por segundo ou a duas a três vezes por segundo. Como a freqüência de amostragem é determinada? Um cientista chamado Harry Nyquist descobriu que o sinal analógico original pode ser reconstruído se forem colhidas amostras suficientes. Ele determinou que se a frequência de amostragem for pelo menos o dobro da frequência mais alta do sinal de voz analógico de entrada original, esse sinal pode ser reconstruído por um filtro de baixa passagem no destino. O critério Nyquist é dito assim:
Fs > 2(BW) Fs = Sampling frequency BW = Bandwidth of original analog voice signal
Figura 1: Amostragem Analógica
Digitalizar voz
Depois de filtrar e colher amostras (usando PAM) de um sinal de voz analógico de entrada, a próxima etapa é digitalizar essas amostras em preparação para transmissão através de uma rede de telefonia. O processo de digitalização de sinais de voz analógica é chamado PCM. A única diferença entre PAM e PCM é que o PCM leva o processo um passo mais longe. O PCM decodifica cada amostra analógica usando palavras de código binário. O PCM tem um conversor analógico-digital no lado de origem e um conversor digital-analógico no lado de destino. A PCM usa uma técnica chamada quantização para codificar essas amostras.
Quantização e codificação
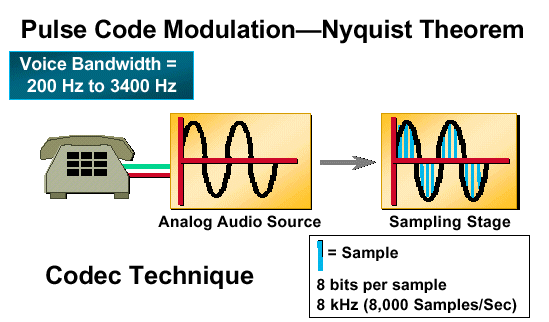
Figura 2: Modulação de código de pulso - Teorema Nyquist
Quantização é o processo de conversão de cada valor de exemplo analógico em um valor discreto que pode ser atribuído a uma única palavra de código digital.
À medida que as amostras de sinal de entrada entram na fase de quantização, são atribuídas com um intervalo de quantização. Todos os intervalos de quantização estão uniformemente espaçados (quantização uniforme) em todo o intervalo dinâmico do sinal analógico de entrada. A cada intervalo de quantização é atribuído um valor discreto na forma de uma palavra de código binária. O tamanho de palavra padrão usado é de oito bits. Se um sinal analógico de entrada for amostrado 8000 vezes por segundo e cada amostra receber uma palavra de código com oito bits de comprimento, então a taxa máxima de bits de transmissão para sistemas de telefonia usando PCM é de 64.000 bits por segundo. A Figura 2 ilustra a taxa de bit derivada para um sistema de PCM.
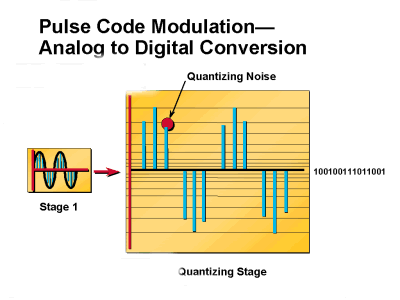
A cada amostra de entrada é atribuído um intervalo de quantização mais próximo de sua altura de amplitude. Se não for atribuído a uma amostra de entrada um intervalo de quantização que corresponda à sua altura real, um erro será introduzido no processo PCM. Esse erro é chamado ruído de quantização. O ruído de quantização é equivalente ao ruído aleatório que afeta a taxa de sinal para ruído (SNR) de um sinal de voz. O SNR é uma medida da intensidade do sinal em relação ao ruído de fundo. A razão é geralmente medida em decibéis (dB). Se a intensidade do sinal de entrada em microvolts for Vs e o nível de ruído, também em microvolts, for Vn, a razão sinal/ruído, S/N, em decibéis, é dada pela fórmula S/N = 20 log10(Vs/Vn). O SNR é medido em decibéis (dB). Quanto maior o SNR, melhor a qualidade da voz. O ruído de quantização reduz o SNR de um sinal. Portanto, um aumento no ruído de quantização degrada a qualidade de um sinal de voz. A Figura 3 mostra como o ruído de quantização é gerado. Para fins de codificação, uma palavra N bit produz rótulos de quantização 2N.
Figura 3: Conversão analógica para digital
Um modo de reduzir o ruído da quantização é aumentar a quantidade de intervalos de quantização. A diferença entre a altura da amplitude do sinal de entrada e o intervalo de quantização diminui à medida que os intervalos de quantização aumentam (aumentos nos intervalos diminuem o ruído de quantização). No entanto, a quantidade de palavras de código também precisa de ser aumentada proporcionalmente ao aumento dos intervalos de quantização. Esse processo apresenta problemas adicionais que lidam com a capacidade de um sistema PCM de lidar com mais palavras de código.
O SNR (incluindo o ruído de quantização) é o fator mais importante que afeta a qualidade da voz na quantificação uniforme. A quantização uniforme usa níveis de quantização iguais em todo o intervalo dinâmico de um sinal analógico de entrada. Portanto, os sinais baixos têm um pequeno SNR (qualidade de voz de baixo nível de sinal) e os sinais altos têm um grande SNR (qualidade de voz de alto nível de sinal). Como a maioria dos sinais de voz gerados são do tipo baixo, ter melhor qualidade de voz em níveis de sinal mais altos é uma forma muito ineficiente de digitalizar sinais de voz. Para melhorar a qualidade da voz em níveis de sinal mais baixos, a quantização uniforme (PCM uniforme) é substituída por um processo de quantização não uniforme chamado companding.
Compressão seguida de expansão
A compressão seguida de expansão refere-se ao processo de primeiro compactar um sinal analógico na origem e, em seguida, expandir este sinal de volta ao seu tamanho original quando alcança seu destino. O termo companhia é criado combinando os dois termos, comprimindo e expandindo, em uma palavra. No momento do processo de companhia, as amostras de sinal analógico de entrada são comprimidas em segmentos logarítmicos. Cada segmento é então quantificado e codificado usando-se quantificação uniforme. O processo de compactação é logarítmico. A compressão aumenta à medida que os sinais de exemplo aumentam. Em outras palavras, os sinais de amostra maiores são compactados mais do que os sinais de amostra menores. Isso faz com que o ruído de quantização aumente à medida que o sinal de exemplo aumenta. Um aumento logarítmico no ruído de quantização em toda a faixa dinâmica de um sinal de exemplo de entrada mantém o SNR constante ao longo dessa faixa dinâmica. Os padrões ITU-T para companhia são chamados de A-law e u-law.
Compressão seguida de expansão de “a-law e u-law”
A-law e u-law são esquemas de compressão de áudio (codecs) definidos pelo Comitê Consultivo para Telefonia Internacional e Telegrafia (CCITT - International Telephony And Telegraphy) G.711 que comprimem dados PCM lineares de 16 bits em oito bits de dados logarítmicos.
Companheiro da lei A
Limitando os valores da amostra linear a doze bits de magnitude, a compressão da lei A é definida por esta equação, em que A é o parâmetro de compressão (A=87.7 na Europa), e x é o inteiro normalizado a ser comprimido.
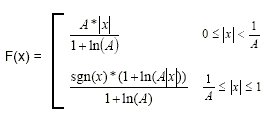
u-law Compander
Limitando os valores da amostra linear a treze bits de magnitude, a compressão u-law (u-law e Mu-law são usados como sinônimos neste documento) é definida por esta equação, onde m é o parâmetro de compressão (m =255 nos EUA e Japão) e x é o inteiro normalizado a ser comprimido.
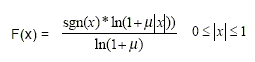
A norma A-law é utilizada principalmente pela Europa e pelo resto do mundo. A u-law é usada pela América do Norte e pelo Japão.
Semelhanças entre a-law e u-law
-
Ambas são aproximações lineares de relacionamento logarítmico de entrada/saída.
-
Ambos são implementados usando palavras de código de oito bits (256 níveis, um para cada intervalo de quantização). As palavras de código de oito bits permitem uma taxa de bits de 64 kilobits por segundo (kbps). Isto é calculado multiplicando a taxa de amostragem (o dobro da frequência de entrada) pelo tamanho da palavra de código (2 x 4 kHz x 8 bits = 64 kbps).
-
Ambos dividem um intervalo dinâmico em um total de 16 segmentos:
-
Oito segmentos positivos e oito negativos.
-
Cada segmento tem o dobro do comprimento do anterior.
-
A quantização uniforme é usada em cada segmento.
-
-
Ambos usam uma abordagem semelhante para codificar a palavra de oito bits:
-
Primeiro (MSB) identifica polaridade.
-
Bits dois, três e quatro identificam o segmento.
-
Os quatro últimos bits quantificam o segmento são os níveis de sinal mais baixos que a lei A.
-
Diferenças entre A-law e u-law
-
Diferentes aproximações lineares levam a diferentes comprimentos e inclinações.
-
A atribuição numérica das posições dos bits na palavra do código de oito bits aos segmentos e os níveis de quantização dentro dos segmentos são diferentes.
-
A a-law oferece um intervalo dinâmico maior que a u-law.
-
a u-law fornece melhor desempenho de sinal/distorção para sinais de baixo nível do que a A-law.
-
A-law requer 13 bits para um equivalente PCM uniforme. u-law requer 14 bits para um equivalente PCM uniforme.
-
Uma conexão internacional precisa usar a Lei-A, até que a conversão para A é da responsabilidade do país da lei-u.
Modulação de código de pulso diferencial
No momento do processo PCM, as diferenças entre os sinais de amostra de entrada são mínimas. O PCM diferencial (DPCM) é projetado para calcular essa diferença e depois transmitir esse pequeno sinal de diferença em vez de todo o sinal de exemplo de entrada. Uma vez que a diferença entre as amostras de entrada é inferior a uma amostra de entrada completa, o número de bits necessários para a transmissão é reduzido. Isso permite uma redução na taxa de transferência necessária para transmitir sinais de voz. O uso do DPCM pode reduzir a taxa de bits da transmissão de voz para 48 kbps.
Como o DPCM calcula a diferença entre o atual sinal de exemplo e um exemplo anterior? A primeira parte do DHCP funciona exatamente como o PCM (e este é motivo porque isso é chamado de PCM diferencial). O sinal de entrada é exemplificado em uma freqüência de amostragem constante (duas vezes a freqüência de entrada). Assim, essas amostras são moduladas, com uso do processo de PAM. Nesse ponto, o processo DPCM assume. O sinal de entrada exemplificado é armazenado naquilo que é chamado de prognosticador. O preditor pega o sinal de exemplo armazenado e o envia por meio de um diferenciador. O diferenciador compara o sinal de amostra anterior com o sinal de amostra atual e envia essa diferença para a fase de quantificação e codificação do PCM (essa fase pode ser uniformizada na quantificação ou na combinação com A-law ou u-law). Depois de quantificar e codificar, o sinal de diferença é transmitido ao seu destino final. Na extremidade receptora da rede, tudo é invertido. Primeiro, o sinal de diferença é desquantificado. Em seguida, esse sinal de diferença é adicionado a um sinal de exemplo armazenado nem um previsor e enviado a um filtro de baixa freqüência que reconstrói o sinal de entrada original.
O DPCM é uma boa maneira de reduzir a taxa de bits para transmissão de voz. No entanto, causa outros problemas que lidam com a qualidade de voz. O DPCM quantifica e codifica a diferença entre um sinal de entrada de amostra anterior e um sinal de entrada de amostra atual. O DPCM quantiza o sinal de diferença usando a quantização uniforme. A quantização uniforme gera um SNR pequeno para sinais de exemplo de entrada pequenos e grande para sinais de exemplo de entrada grandes. Sendo assim, a qualidade de voz é melhor a sinais mais elevados. Esse cenário é muito ineficiente, já que a maioria dos sinais gerados pela voz humana é pequena. A qualidade da voz precisa se concentrar em pequenos sinais. Para resolver esse problema, o DPCM adaptável é desenvolvido.
DPCM adaptativo
O ADPCM (Adaptive DPCM) é um método de codificação de forma de onda definido na especificação ITU-T G.726.
O ADPCM adapta os níveis de quantização do sinal de diferença gerado no momento do processo DPCM. Como a ADPCM adapta esses níveis de quantização? Se o sinal de diferença for baixo, o ADPCM aumenta o tamanho dos níveis de quantização. Se o sinal de diferença é elevado, o ADPCM reduz o tamanho dos níveis de quantização. Portanto, o ADPCM adapta o nível de quantização ao tamanho do sinal de diferença de entrada. Isso gera um SNR uniforme em todo o intervalo dinâmico do sinal de diferença. O uso do ADPCM reduz a taxa de bits da transmissão de voz para 32 kbps, metade da taxa de bits do PCM A-law ou u-law. A ADPCM produz voz de "qualidade de tarifação", como o PCM A-law ou u-law. O codificador deve ter um loop de feedback, usando os bits de saída do codificador para recalibrar o quantificador.
Passos específicos a 32 KB/s
Aplicável como Padrões de ITU G.726.
-
Converta exemplos de PCM de Lei-A ou Lei-µ em um exemplo de PCM linear.
-
Calcule o valor previsto do próximo exemplo.
-
Meça a diferença entre a amostra atual e o valor previsto.
-
Diferença de código em quatro bits, envie esses bits.
-
Devolva quatro bits ao preditor.
-
Devolva quatro bits para o quantificador.
 Feedback
Feedback