Identificar e Solucionar Problemas do Código de Falha da ACI F199144, F93337, F381328, F93241, F450296 : TCA
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introdução
Este documento descreve as etapas de remediação para os códigos de falha da ACI: F199144, F93337, F381328, F93241, F450296
Background
Se você tiver uma malha da ACI conectada à Intersight, uma solicitação de serviço foi gerada em seu nome para indicar que uma instância dessa falha foi encontrada na malha da ACI conectada à Intersight.
Isso está sendo monitorado ativamente como parte dos contratos de ACI proativos.
Este documento descreve as próximas etapas para remediar a seguinte falha:
Falha : F199144
"Code" : "F199144",
"Description" : "TCA: External Subnet (v4 and v6) prefix entries usage current value(eqptcapacityPrefixEntries5min:extNormalizedLast) value 91% raised above threshold 90%",
"Dn" : "topology/pod-1/node-132/sys/eqptcapacity/fault-F199144"
Essa falha específica é gerada quando o uso atual do prefixo de sub-rede externa excede 99%. Isso sugere uma limitação de hardware em termos de rotas tratadas por esses switches.
Início rápido para resolver falha: F199144
1. Comando "show platform internal hal l3 routingthresholds"
module-1# show platform internal hal l3 routingthresholds
Executing Custom Handler function
OBJECT 0:
trie debug threshold : 0
tcam debug threshold : 3072
Supported UC lpm entries : 14848
Supported UC lpm Tcam entries : 5632
Current v4 UC lpm Routes : 19526
Current v6 UC lpm Routes : 0
Current v4 UC lpm Tcam Routes : 404
Current v6 UC lpm Tcam Routes : 115
Current v6 wide UC lpm Tcam Routes : 24
Maximum HW Resources for LPM : 20480 < ------- Maximum hardware resources
Current LPM Usage in Hardware : 20390 < ------------Current usage in Hw
Number of times limit crossed : 5198 < -------------- Number of times that limit was crossed
Last time limit crossed : 2020-07-07 12:34:15.947 < ------ Last occurrence, today at 12:34 pm2. Comando "show platform internal hal-stats"
module-1# show platform internal hal health-stats
No sandboxes exist
|Sandbox_ID: 0 Asic Bitmap: 0x0
|-------------------------------------
L2 stats:
=========
bds: : 249
...
l2_total_host_entries_norm : 4
L3 stats:
=========
l3_v4_local_ep_entries : 40
max_l3_v4_local_ep_entries : 12288
l3_v4_local_ep_entries_norm : 0
l3_v6_local_ep_entries : 0
max_l3_v6_local_ep_entries : 8192
l3_v6_local_ep_entries_norm : 0
l3_v4_total_ep_entries : 221
max_l3_v4_total_ep_entries : 24576
l3_v4_total_ep_entries_norm : 0
l3_v6_total_ep_entries : 0
max_l3_v6_total_ep_entries : 12288
l3_v6_total_ep_entries_norm : 0
max_l3_v4_32_entries : 49152
total_l3_v4_32_entries : 6294
l3_v4_total_ep_entries : 221
l3_v4_host_uc_entries : 6073
l3_v4_host_mc_entries : 0
total_l3_v4_32_entries_norm : 12
max_l3_v6_128_entries : 12288
total_l3_v6_128_entries : 17
l3_v6_total_ep_entries : 0
l3_v6_host_uc_entries : 17
l3_v6_host_mc_entries : 0
total_l3_v6_128_entries_norm : 0
max_l3_lpm_entries : 20480 < ----------- Maximum
l3_lpm_entries : 19528 < ------------- Current L3 LPM entries
l3_v4_lpm_entries : 19528
l3_v6_lpm_entries : 0
l3_lpm_entries_norm : 99
max_l3_lpm_tcam_entries : 5632
max_l3_v6_wide_lpm_tcam_entries: 1000
l3_lpm_tcam_entries : 864
l3_v4_lpm_tcam_entries : 404
l3_v6_lpm_tcam_entries : 460
l3_v6_wide_lpm_tcam_entries : 24
l3_lpm_tcam_entries_norm : 15
l3_v6_lpm_tcam_entries_norm : 2
l3_host_uc_entries : 6090
l3_v4_host_uc_entries : 6073
l3_v6_host_uc_entries : 17
max_uc_ecmp_entries : 32768
uc_ecmp_entries : 250
uc_ecmp_entries_norm : 0
max_uc_adj_entries : 8192
uc_adj_entries : 261
uc_adj_entries_norm : 3
vrfs : 150
infra_vrfs : 0
tenant_vrfs : 148
rtd_ifs : 2
sub_ifs : 2
svi_ifs : 185
Falha nas próximas etapas: F199144
1. Reduza o número de rotas que cada switch deve processar para estar em conformidade com a escalabilidade definida para o modelo de hardware. Verifique o guia de escalabilidade aqui https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/4-x/verified-scalability/Cisco-ACI-Verified-Scalability-Guide-412.html
2. Considere alterar o Forwarding Scale Profile com base na escala. https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/all/forwarding-scale-profiles/cisco-apic-forwarding-scale-profiles/m-overview-and-guidelines.html
3. Removendo a sub-rede 0.0.0.0/0 em L3Out e configurar apenas as sub-redes necessárias
4. Se você estiver usando a Geração 1, atualize seu hardware da Geração 1 para a Geração 2, pois os switches da Geração 2 permitem mais de 20.000 rotas v4 externas.
Falha : F93337
"Code" : "F93337",
"Description" : "TCA: memory usage current value(compHostStats15min:memUsageLast) value 100% raised above threshold 99%",
"Dn" : "comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/fault-F93337"Essa falha específica é gerada quando o host da VM está consumindo mais memória do que o limite. O APIC monitora esses hosts via VCenter. Comp:HostStats15min é uma classe que representa as estatísticas mais atuais do host em um intervalo de amostragem de 15 minutos. Esta aula é atualizada a cada 5 minutos.
Início Rápido para Resolver Falha : F93337
1. Comando "moquery -d 'comp/prov-VMware/ctrlr-[<DVS>]-<VCenter>/vm-vm-<VM id do DN da falha>'"
Esse comando fornece informações sobre a VM afetada
# comp.Vm
oid : vm-1071
cfgdOs : Ubuntu Linux (64-bit)
childAction :
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071
ftRole : unset
guid : 501030b8-028a-be5c-6794-0b7bee827557
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T17:16:06.572+05:30
monPolDn : uni/tn-692673613-VSPAN/monepg-test
name : VM3
nameAlias :
os :
rn : vm-vm-1071
state : poweredOn
status :
template : no
type : virt
uuid : 4210b04b-32f3-b4e3-25b4-fe73cd3be0ca2. Comando "moquery -c compRsHv | grep 'vm-1071'"
Esse comando fornece informações sobre o host onde a VM está sendo hospedada. Neste exemplo, a VM está localizada no host 347
apic2# moquery -c compRsHv | grep vm-1071
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/rshv-[comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068]3. Comando "moquery -c compHv -f 'comp.Hv.oid=="host-1068"'"
Este comando fornece detalhes sobre o host
apic2# moquery -c compHv -f 'comp.Hv.oid=="host-1068"'
Total Objects shown: 1
# comp.Hv
oid : host-1068
availAdminSt : gray
availOperSt : gray
childAction :
countUplink : 0
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068
enteringMaintenance : no
guid : b1e21bc1-9070-3846-b41f-c7a8c1212b35
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T14:23:26.654+05:30
monPolDn : uni/infra/moninfra-default
name : myhost
nameAlias :
operIssues :
os :
rn : hv-host-1068
state : poweredOn
status :
type : hv
uuid :Falha nas próximas etapas: F93337
1. Altere a memória alocada para a VM no Host.
2. Se a memória for esperada, você poderá suprimir a falha criando uma política de coleta de estatísticas para alterar o valor de limite.
a. No espaço da VM, crie uma nova política de monitoramento.

b. Em sua política de Monitoramento, selecione stats collection policy.
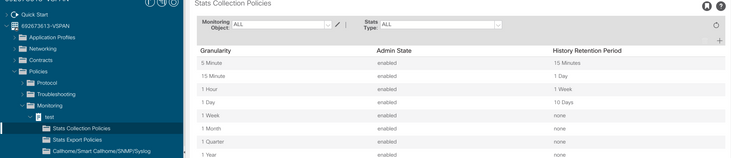
c. Clique no ícone de edição ao lado do menu suspenso Monitoring object (Objeto de monitoramento) e verifique a máquina virtual (comp.Vm) como um objeto de monitoramento. Depois de enviar, selecione o objeto compVm no menu suspenso Objeto de monitoramento.

d. Clique no ícone de edição ao lado de Tipo de estatísticas e verifique o Uso da CPU.
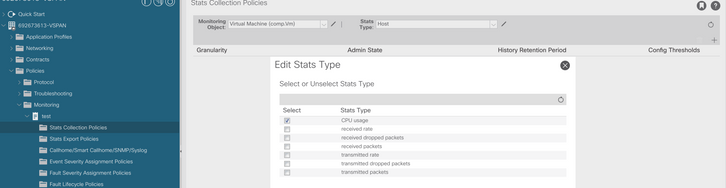
e. No menu suspenso tipo de estatísticas, clique em selecionar host, clique no sinal + e insira sua granularidade, estado de administração e período de retenção do histórico. Em seguida, clique em atualizar.

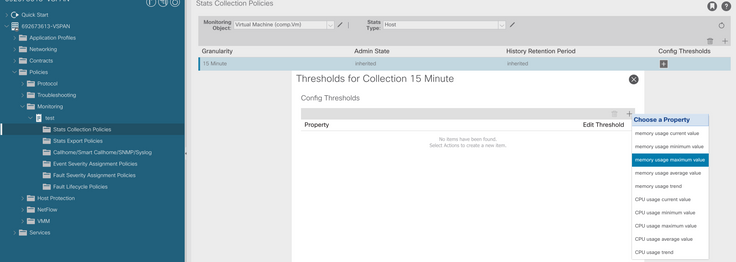
f. Clique no sinal + abaixo do limite de configuração e adicione "memory usage maximum value" como propriedade.
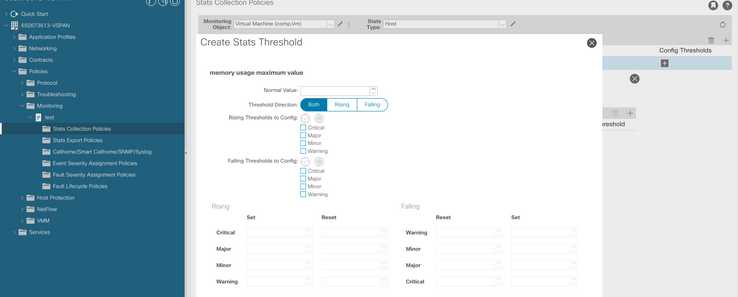
g. Altere o valor normal para o limite desejado.
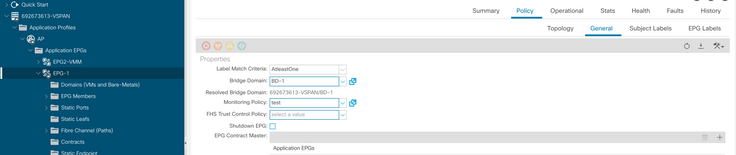
h. Aplicar a política de monitoramento no EPG
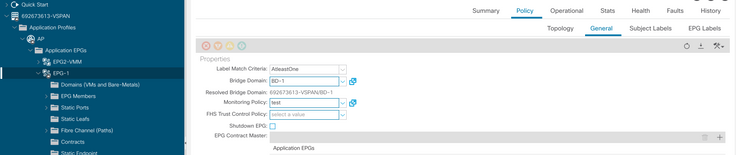
I. Para confirmar se a política é aplicada na VM, execute "moquery -c compVm -f 'comp.Vm.oid = "vm-<vm-id>"'"
apic1# moquery -c compVm -f 'comp.Vm.oid == "vm-1071"' | grep monPolDn
monPolDn : uni/tn-692673613-VSPAN/monepg-test <== Monitoring Policy test has been applied
Falha : F93241
"Code" : "F93241",
"Description" : "TCA: CPU usage average value(compHostStats15min:cpuUsageAvg) value 100% raised above threshold 99%",
"Dn" : "comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/fault-F93241"Essa falha específica é gerada quando o host da VM está consumindo mais CPU do que o limite. O APIC monitora esses hosts via VCenter. Comp:HostStats15min é uma classe que representa as estatísticas mais atuais do host em um intervalo de amostragem de 15 minutos. Esta aula é atualizada a cada 5 minutos.
Início Rápido para Resolver Falha : F93241
1. Comando "moquery -d 'comp/prov-VMware/ctrlr-[<DVS>]-<VCenter>/vm-vm-<VM id do DN da falha>'"
Esse comando fornece informações sobre a VM afetada
# comp.Vm
oid : vm-1071
cfgdOs : Ubuntu Linux (64-bit)
childAction :
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071
ftRole : unset
guid : 501030b8-028a-be5c-6794-0b7bee827557
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T17:16:06.572+05:30
monPolDn : uni/tn-692673613-VSPAN/monepg-test
name : VM3
nameAlias :
os :
rn : vm-vm-1071
state : poweredOn
status :
template : no
type : virt
uuid : 4210b04b-32f3-b4e3-25b4-fe73cd3be0ca2. Comando "moquery -c compRsHv | grep 'vm-1071'"
Esse comando fornece informações sobre o host onde a VM está sendo hospedada. Neste exemplo, a VM está localizada no host 347
apic2# moquery -c compRsHv | grep vm-1071
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/rshv-[comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068]3. Comando "moquery -c compHv -f 'comp.Hv.oid=="host-1068"'"
Este comando fornece detalhes sobre o host
apic2# moquery -c compHv -f 'comp.Hv.oid=="host-1068"'
Total Objects shown: 1
# comp.Hv
oid : host-1068
availAdminSt : gray
availOperSt : gray
childAction :
countUplink : 0
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068
enteringMaintenance : no
guid : b1e21bc1-9070-3846-b41f-c7a8c1212b35
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T14:23:26.654+05:30
monPolDn : uni/infra/moninfra-default
name : myhost
nameAlias :
operIssues :
os :
rn : hv-host-1068
state : poweredOn
status :
type : hv
uuid :Falha nas próximas etapas: F93241
1. Atualize a CPU alocada para a VM no Host.
2. Se a CPU for esperada, você poderá suprimir a falha criando uma política de coleta de estatísticas para alterar o valor do limite.
a. No espaço da VM, crie uma nova política de monitoramento.

b. Em sua política de Monitoramento, selecione stats collection policy.
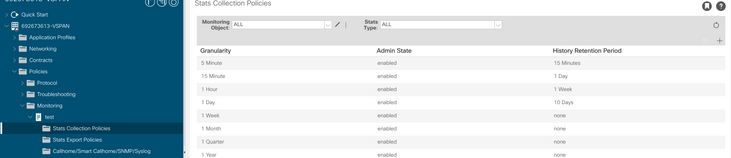
c. Clique no ícone de edição ao lado do menu suspenso Monitoring object (Objeto de monitoramento) e verifique a máquina virtual (comp.Vm) como um objeto de monitoramento. Depois de enviar, selecione o objeto compVm no menu suspenso Objeto de monitoramento.

d. Clique no ícone de edição ao lado de Tipo de estatísticas e verifique o Uso da CPU.
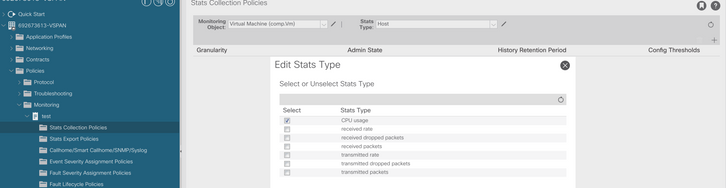
e. No menu suspenso tipo de estatísticas, clique em selecionar host, clique no sinal + e insira sua granularidade, estado de administração e período de retenção do histórico. Em seguida, clique em atualizar.

f. Clique no sinal + abaixo do limite de configuração e adicione "valor máximo de uso da CPU" como propriedade.
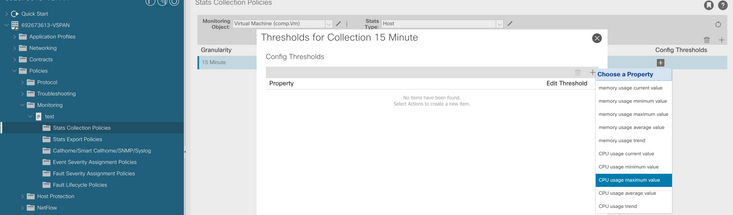
g. Altere o valor normal para o limite desejado.
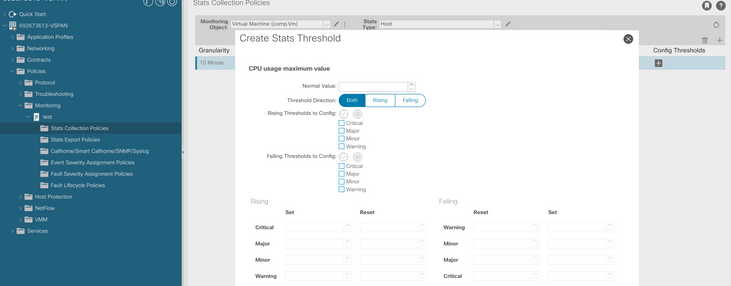
h. Aplicar a política de monitoramento no EPG
I. Para confirmar se a política é aplicada na VM, execute "moquery -c compVm -f 'comp.Vm.oid = "vm-<vm-id>"'"
apic1# moquery -c compVm -f 'comp.Vm.oid == "vm-1071"' | grep monPolDn
monPolDn : uni/tn-692673613-VSPAN/monepg-test <== Monitoring Policy test has been appliedFalha : F381328
"Code" : "F381328",
"Description" : "TCA: CRC Align Errors current value(eqptIngrErrPkts5min:crcLast) value 50% raised above threshold 25%",
"Dn" : "topology/<pod>/<node>/sys/phys-<[interface]>/fault-F381328"Essa falha específica é gerada quando erros de CRC em uma interface excedem o limite. Há dois tipos comuns de erros de CRC vistos - erros de FCS e erros de CRC estompados. Os erros de CRC são propagados devido a um caminho comutado cut-through e são o resultado de erros iniciais de FCS. Como a ACI segue a comutação cut-through, esses quadros acabam atravessando a estrutura da ACI e vemos erros de CRC de piscar ao longo do caminho, isso não significa que todas as interfaces com erros de CRC sejam falhas. A recomendação é identificar a origem do CRC e corrigir o SFP/Porta/Fibra problemático.
Início Rápido para Resolver Falha : F381328
1. Descartar as interfaces de maior número com CRC na malha
moquery -c rmonEtherStats -f 'rmon.EtherStats.cRCAlignErrors>="1"' | egrep "dn|cRCAlignErrors" | egrep -o "\S+$" | tr '\r\n' ' ' | sed -re 's/([[:digit:]]+)\s/\n\1 /g' | awk '{printf "%-65s %-15s\n", $2,$1}' | sort -rnk 2
topology/pod-1/node-103/sys/phys-[eth1/50]/dbgEtherStats 399158
topology/pod-1/node-101/sys/phys-[eth1/51]/dbgEtherStats 399158
topology/pod-1/node-1001/sys/phys-[eth2/24]/dbgEtherStats 3991582. Descartar o maior número de FCS na malha
moquery -c rmonDot3Stats -f 'rmon.Dot3Stats.fCSErrors>="1"' | egrep "dn|fCSErrors" | egrep -o "\S+$" | tr '\r\n' ' ' | sed -re 's/topology/\ntopology/g' | awk '{printf "%-65s %-15s\n", $1,$2}' | sort -rnk 2Falha nas próximas etapas: F381328
1. Se houver erros de FCS na estrutura, resolva-os. Esses erros geralmente indicam problemas na camada 1.
2. Se houver erros de interrupção de CRC na porta do painel frontal, verifique o dispositivo conectado na porta e identifique por que as interrupções estão vindo desse dispositivo.
Script Python para falha : F381328
Este processo inteiro também pode ser automatizado usando um script python. Consulte https://www.cisco.com/c/en/us/support/docs/cloud-systems-management/application-policy-infrastructure-controller-apic/217577-how-to-use-fcs-and-crc-troubleshooting-s.html
Falha : F450296
"Code" : "F450296",
"Description" : "TCA: Multicast usage current value(eqptcapacityMcastEntry5min:perLast) value 91% raised above threshold 90%",
"Dn" : "sys/eqptcapacity/fault-F450296"Essa falha específica é gerada quando o número de entradas multicast excede o limite.
Início Rápido para Resolver Falha : F450296
1. Comando "show platform internal hal-stats asic-unit all"
module-1# show platform internal hal health-stats asic-unit all
|Sandbox_ID: 0 Asic Bitmap: 0x0
|-------------------------------------
L2 stats:
=========
bds: : 1979
max_bds: : 3500
external_bds: : 0
vsan_bds: : 0
legacy_bds: : 0
regular_bds: : 0
control_bds: : 0
fds : 1976
max_fds : 3500
fd_vlans : 0
fd_vxlans : 0
vlans : 3955
max vlans : 3960
vlan_xlates : 6739
max vlan_xlates : 32768
ports : 52
pcs : 47
hifs : 0
nif_pcs : 0
l2_local_host_entries : 1979
max_l2_local_host_entries : 32768
l2_local_host_entries_norm : 6
l2_total_host_entries : 1979
max_l2_total_host_entries : 65536
l2_total_host_entries_norm : 3
L3 stats:
=========
l3_v4_local_ep_entries : 3953
max_l3_v4_local_ep_entries : 32768
l3_v4_local_ep_entries_norm : 12
l3_v6_local_ep_entries : 1976
max_l3_v6_local_ep_entries : 24576
l3_v6_local_ep_entries_norm : 8
l3_v4_total_ep_entries : 3953
max_l3_v4_total_ep_entries : 65536
l3_v4_total_ep_entries_norm : 6
l3_v6_total_ep_entries : 1976
max_l3_v6_total_ep_entries : 49152
l3_v6_total_ep_entries_norm : 4
max_l3_v4_32_entries : 98304
total_l3_v4_32_entries : 35590
l3_v4_total_ep_entries : 3953
l3_v4_host_uc_entries : 37
l3_v4_host_mc_entries : 31600
total_l3_v4_32_entries_norm : 36
max_l3_v6_128_entries : 49152
total_l3_v6_128_entries : 3952
l3_v6_total_ep_entries : 1976
l3_v6_host_uc_entries : 1976
l3_v6_host_mc_entries : 0
total_l3_v6_128_entries_norm : 8
max_l3_lpm_entries : 38912
l3_lpm_entries : 9384
l3_v4_lpm_entries : 3940
l3_v6_lpm_entries : 5444
l3_lpm_entries_norm : 31
max_l3_lpm_tcam_entries : 4096
max_l3_v6_wide_lpm_tcam_entries: 1000
l3_lpm_tcam_entries : 2689
l3_v4_lpm_tcam_entries : 2557
l3_v6_lpm_tcam_entries : 132
l3_v6_wide_lpm_tcam_entries : 0
l3_lpm_tcam_entries_norm : 65
l3_v6_lpm_tcam_entries_norm : 0
l3_host_uc_entries : 2013
l3_v4_host_uc_entries : 37
l3_v6_host_uc_entries : 1976
max_uc_ecmp_entries : 32768
uc_ecmp_entries : 1
uc_ecmp_entries_norm : 0
max_uc_adj_entries : 8192
uc_adj_entries : 1033
uc_adj_entries_norm : 12
vrfs : 1806
infra_vrfs : 0
tenant_vrfs : 1804
rtd_ifs : 2
sub_ifs : 2
svi_ifs : 1978
Mcast stats:
============
mcast_count : 31616 <<<<<<<
max_mcast_count : 32768
Policy stats:
=============
policy_count : 127116
max_policy_count : 131072
policy_otcam_count : 2920
max_policy_otcam_count : 8192
policy_label_count : 0
max_policy_label_count : 0
Dci Stats:
=============
vlan_xlate_entries : 0
vlan_xlate_entries_tcam : 0
max_vlan_xlate_entries : 0
sclass_xlate_entries : 0
sclass_xlate_entries_tcam : 0
max_sclass_xlate_entries : 0Falha nas próximas etapas: F450296
1. Considere mover parte do tráfego multicast para outros Leafs.
2. Explore vários perfis de escala de encaminhamento para aumentar a escala de multicast. Consulte o link https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/all/forwarding-scale-profiles/cisco-apic-forwarding-scale-profiles/m-forwarding-scale-profiles-523.html
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
1.0 |
11-Jul-2023 |
Versão inicial |
Colaborado por engenheiros da Cisco
- Savinder SinghTAC
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)