Introdução
Este documento descreve diferentes tipos de erros de disco, como classificá-los e as ferramentas que você pode usar para identificá-los.
Pré-requisitos
Requisitos
Não existem requisitos específicos para este documento.
Componentes Utilizados
As informações neste documento são baseadas em discos rígidos no Unified Computing System (UCS).
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. Todos os dispositivos utilizados neste documento foram iniciados com uma configuração (padrão) inicial. Se a sua rede estiver ativa, certifique-se de que entende o impacto potencial de qualquer comando.
Informações de Apoio
O documento também descreve a função da controladora HDD (Hard Disk Drive, unidade de disco rígido) e RAID (Redundant Array of Independent Disks, matriz redundante de discos independentes) ao identificar erros médios nas unidades.
Observação: erros médios também são chamados de erros de mídia
Lidar com erros médios de HDD
O que causa erros médios de HDD?
A causa mais comum de erros médios é a baixa amplitude do sinal que resulta em
- Local de leitura de LBA (endereço de barramento lógico) não confiável. Às vezes recuperável com várias tentativas.
- Em condições transitórias, as gravações de moscas altas são causadas por partículas moles.
- Condições transitórias causadas por choques temporários, vibrações ou eventos acústicos que resultem em gravações fora da via.
- Função de mapa de erros ruim na fabricação de HDD que resulta no preenchimento dos locais de defeito primário atuais.
Como o HDD detecta o erro médio?
Etapa 1.O HDD executa periodicamente verificações de mídia de fundo para detectar erros.
Etapa 2. O disco rígido tenta ler a mídia e, por algum motivo, não consegue recuperar os dados que foram gravados.
Etapa 3. Quando o HDD não consegue recuperar os dados que foram gravados, ele chama o código de recuperação do HDD, que tentará várias etapas de recuperação de erros para ler com êxito os dados da mídia.
Etapa 4. Se todas as etapas de recuperação falharem, a unidade gerará um erro 03/11/0x de volta ao host e os LBAs serão colocados na lista de defeitos pendentes.
Como o controlador RAID detecta erros médios?
- O controlador RAID encontrará erros médios durante as operações de leitura de unidades "Patrol", verificações de consistência, leituras normais, recriações e leitura/modificação/gravação.
- Com base na configuração RAID, a controladora pode ser capaz de lidar com o erro médio relatado pelo HDD e nenhuma outra ação será necessária.
- Em alguns casos, o controlador não será capaz de lidar com o erro médio e passará o erro ao host para lidar com o erro.
Quando o sistema operacional (SO) detecta erros médios?
- Se o disco rígido reportar um erro médio e o controlador RAID não puder lidar com a recuperação, o host será notificado do erro.
- Essa notificação não é mais apenas uma mensagem de aviso que informa ao sistema que o evento ocorreu; é uma solicitação para que o SO atue porque o HDD e o controlador RAID não puderam se recuperar do erro médio.
- Se o SO tiver o contexto necessário para resolver corretamente o erro médio, ele deverá ser tratado pelo SO
- Se os discos estiverem em Just a Bunch Of Disk (JBOD), o SO verá erros, pois eles não são corrigidos pelo controlador. Isso é comum em ambientes HyperFlex (HX)/Rede de área de armazenamento virtual (VSAN).
Função do HDD
Nível de HDD com defeitos de crescimento (lista G)
Enquanto uma unidade está em operação, a cabeça pode se deparar com um setor com um nível de leitura magnética enfraquecido. Os dados ainda são legíveis, mas podem ficar abaixo do limiar preferencial para os níveis de leitura do setor de bens qualificados. Esse drive de disco consideraria esse um setor que poderia e setor pouparia esses dados para um novo local disponível na lista de reserva válida conhecida. Depois que os dados são movidos, o endereço do setor antigo é adicionado à lista Grown Defects, nunca mais sendo usado. Este processo é um erro de mídia recuperável. A unidade fornecerá um acionador SMART quando a maioria de seus setores sobressalentes em boas condições estiver esgotada.
Função do controlador RAID
Leitura de unidades "Patrol"
- A leitura de unidades "Patrol" é uma opção definida pelo usuário que executa leituras de unidades em segundo plano e mapeia todas as áreas defeituosas da unidade.
- A leitura de unidades "Patrol" verifica se há erros de disco físico que possam causar falha na unidade. Essas verificações normalmente incluem uma tentativa de ação corretiva. A leitura de unidades "Patrol" pode ser ativada ou desativada com ativação automática ou manual.
- A leitura de unidades "Patrol" verifica periodicamente todos os setores de discos físicos conectados a um controlador, que incluem a área reservada do sistema nas unidades configuradas RAID. A leitura de unidades "Patrol" funciona para todos os níveis de RAID e para todos os drives hot spare.
- Esse processo começa somente quando o controlador RAID está ocioso por um período de tempo definido e nenhuma outra tarefa em segundo plano está ativa, embora possa continuar a ser executada ao mesmo tempo que processos pesados de Entrada/Saída (E/S).
- Não é possível realizar leituras de patrulha em unidades configuradas no JBOD.
Nota:A Indexação Semântica Latente (LSI) recomenda que você deixe a frequência de leitura de patrulha e outras configurações de leitura de patrulha nos valores padrão para obter o melhor desempenho do sistema. Se decidir alterar os valores, registre o valor padrão original aqui para que você possa restaurá-los mais tarde.
Observação: a leitura de unidades "Patrol" não relata seu progresso enquanto é executada. O status de leitura de patrulha é relatado somente no log de eventos.
As opções de leitura de unidades "Patrol" são as mostradas na imagem:
 Exemplos da MegaCli
Exemplos da MegaCli
Para ver informações sobre o estado de leitura de patrulha e o atraso entre as execuções de leitura de patrulha:
# MegaCli64 -AdpPR -Info -aALL
Para descobrir a taxa de leitura atual da patrulha, execute:
# MegaCli64 -AdpGetProp PatrolReadRate -aALL
Para desativar a leitura de patrulha automática:
# MegaCli64 -AdpPR -Dsbl -aALL
Para ativar a leitura de patrulha automática:
#MegaCli64 -AdpPR -EnblAuto -aALL
Para iniciar uma patrulha manual, leia a varredura:
# MegaCli64 -AdpPR -Start -aALL
Para parar uma patrulha, leia a varredura:
# MegaCli64 -AdpPR -Stop -aALL
Verificação de consistência
- No RAID, a verificação de consistência verifica a exatidão dos dados redundantes em uma matriz. Por exemplo, em um sistema com paridade, verificar a consistência significa computar a paridade das unidades de dados e comparar os resultados com o conteúdo da unidade de paridade.
- JBOD não suporta verificação de consistência.
- O RAID 0 não suporta verificação de consistência.
- O RAID 1 usa uma comparação de dados, não paridade.
- O RAID 6 calcula a paridade para dois drives de paridade e verifica ambos.
Observação: é recomendável executar uma verificação de consistência pelo menos uma vez por mês.
As opções de gerenciamento da verificação de consistência são as mostradas na imagem:
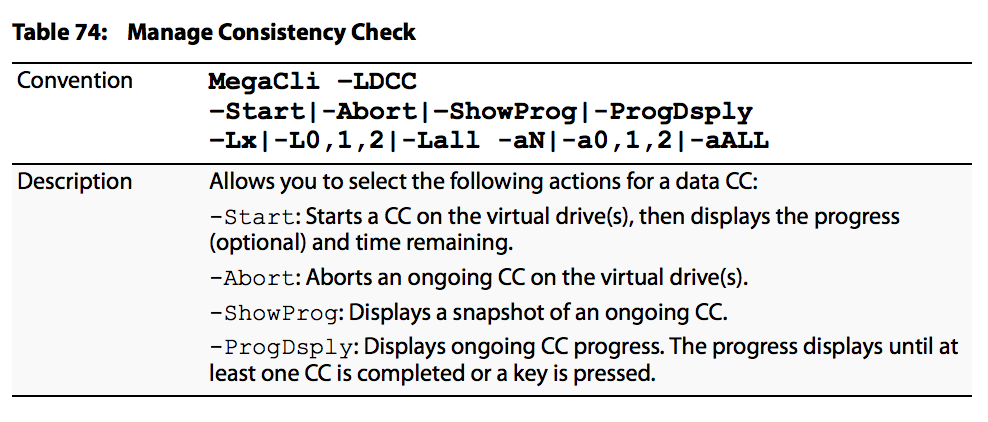
As opções de agendamento do Consistency Check são as mostradas na imagem:

Exemplos da MegaCli
Para ver a próxima hora agendada da verificação de consistência:
#MegaCli64 -AdpCcSched -Info -aALL
Para alterar a hora agendada da Verificação de Consistência:
#MegaCli64 -AdpCCSched -SetSTartTime 20171028 02 -aALL
Para desativar a verificação de consistência:
#MegaCli64 -AdpCcSched -Dsbl -aALL
Condições quando uma controladora RAID não pode reparar um erro médio
- Em JBOD
- O SO do host é responsável por erros médios.
- No RAID 0
- Não há redundância, portanto, o controlador não pode fornecer ao HDD os dados para gravação no LBA.
- No RAID 1
- Quando a controladora não consegue identificar qual cópia espelhada contém os dados corretos. Isso só ocorrerá se ambos os LBAs puderem ser lidos, mas os dados não corresponderem.
- RAID 5
- Se houver 2 ou mais erros na mesma faixa. É mais provável que ocorra após o início da reconstrução de uma matriz. A unidade que é recriada é um erro, e um erro médio em qualquer outra recriação de unidade seria o segundo erro. O controlador não seria capaz de reconstruir os dados necessários para reconstruir o LBA na unidade de substituição.
- RAID 6
- Se houver 3 ou mais erros na mesma faixa. É mais provável que ocorra durante a reconstrução de um storage. A unidade que é recriada é um erro e um erro médio em quaisquer outras duas unidades enquanto a recriação está em andamento seria um segundo e terceiro erros ou um erro médio e uma segunda falha de unidade. O controlador não seria capaz de reconstruir os dados necessários para reconstruir os LBAs nas unidades com os erros.
Informações Relacionadas
 Feedback
Feedback