패킷 음성 네트워크의 지연 이해
목차
소개
패킷, 프레임 또는 셀 인프라를 통해 음성을 전송하는 네트워크를 설계할 때 네트워크의 지연 구성 요소를 이해하고 고려하는 것이 중요합니다.모든 잠재적 지연을 정확하게 고려할 경우 전반적인 네트워크 성능이 허용되는지 확인합니다.전체 음성 품질은 압축 알고리즘, 오류 및 프레임 손실, 에코 취소, 지연 등을 포함하는 여러 요소의 함수입니다.이 백서에서는 패킷 네트워크를 통해 Cisco 라우터/게이트웨이를 사용할 때의 지연 원인을 설명합니다.이 예제는 프레임 릴레이에 맞춰져 있지만 VoIP(Voice over IP) 및 VoATM(Voice over ATM) 네트워크에도 적용할 수 있습니다.
기본 음성 흐름
이 다이어그램에는 압축된 음성 회로의 흐름이 나와 있습니다.전화기의 아날로그 신호는 코덱을 통해 PCM(Pulse Code Modulation) 신호로 디지털화됩니다. 그런 다음 PCM 샘플은 WAN을 통해 전송하기 위해 음성을 패킷 형식으로 압축하는 압축 알고리즘으로 전달됩니다.클라우드의 반대쪽에서는 정확히 동일한 기능이 역순으로 수행됩니다.그림 2-1에 전체 흐름이 나와 있습니다.
그림 2-1 엔드 투 엔드 음성 흐름 
네트워크 구성 방식에 따라 라우터/게이트웨이는 코덱과 압축 기능을 모두 수행하거나 그중 하나만 수행할 수 있습니다.예를 들어 아날로그 음성 시스템을 사용하는 경우 라우터/게이트웨이는 그림 2-2와 같이 CODEC 기능과 압축 기능을 수행합니다.
그림 2-2 라우터/게이트웨이의 코덱기능 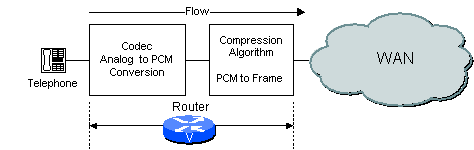
디지털 PBX를 사용하는 경우 PBX는 코덱의 기능을 수행하고 라우터는 PBX에서 전달한 PCM 샘플을 처리합니다.그림 2-3에 예가 나와 있습니다.
그림 2-3 PBX의 코덱기능 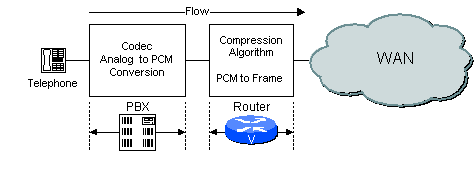
음성 압축 작동 방식
Cisco 라우터/게이트웨이에 사용되는 복잡한 압축 알고리즘은 Voice codec에서 제공하는 PCM 샘플 블록을 분석합니다.이러한 블록은 코더에 따라 길이가 다릅니다.예를 들어 G.729 알고리즘에서 사용하는 기본 블록 크기는 10ms이고 G.723.1 알고리즘에서 사용하는 기본 블록 크기는 30ms입니다.그림 3-1에는 G.729 압축 시스템이 작동하는 방법의 예가 나와 있습니다.
그림 3-1 음성 압축 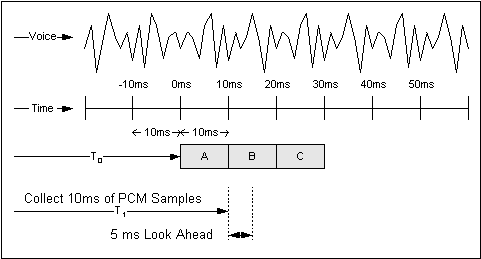
아날로그 음성 스트림은 PCM 샘플로 디지털화되어 압축 알고리즘에 10ms 단위로 전달됩니다.Look ahead는 Algorithmic Delay에서 설명합니다.
지연 제한 표준
ITU(International Telecommunication Union)는 권장 G.114의 음성 애플리케이션에 대한 네트워크 지연을 고려합니다. 이 권장 사항은 표 4.1과 같이 3개의 단방향 지연 밴드를 정의합니다.
표 4.1 지연 사양
| 범위(밀리초) | 설명 |
|---|---|
| 0-150 | 대부분의 사용자 응용 프로그램에 사용할 수 있습니다. |
| 150-400 | 관리자가 전송 시간 및 전송 품질이 사용자 애플리케이션의 전송 품질에 미치는 영향을 알고 있는 경우 허용됩니다. |
| 400 이상 | 일반적인 네트워크 계획 용도의 경우 허용되지 않습니다.그러나 예외적인 경우 이 제한이 초과된 것으로 인식됩니다. |
참고: 이러한 권장 사항은 에코가 적절하게 제어되는 연결을 위한 것입니다.이는 에코 취소기가 사용됨을 의미합니다.단방향 지연이 25ms(G.131)를 초과할 경우 에코 취소가 필요합니다.
이 권고안은 이동통신 시대를 위한 것이다.따라서, 이러한 기능은 개인 음성 네트워크에서 일반적으로 적용할 때보다 더 엄격합니다.최종 사용자의 위치 및 비즈니스 요구 사항이 네트워크 디자이너에게 잘 알려져 있는 경우 지연이 더 많이 허용될 수 있습니다.프라이빗 네트워크의 경우 200ms의 지연이 합리적인 목표이며 250ms의 제한이 있습니다.예상되는 최대 음성 연결 지연을 파악하고 최소화하도록 모든 네트워크를 설계해야 합니다.
지연 소스
고정 및 변수라는 두 가지 유형의 지연이 있습니다.
-
고정 지연 구성 요소는 연결의 전체 지연에 직접 추가됩니다.
-
WAN에 연결된 직렬 포트의 이그레스 트렁크 버퍼에서 큐잉 지연으로 인해 가변 지연이 발생합니다.이러한 버퍼는 네트워크 전체에서 지터라는 가변 지연을 생성합니다.가변 지연은 수신 라우터/게이트웨이의 de-jitter 버퍼를 통해 처리됩니다.de-jitter 버퍼는 이 문서의 De-jitter Delay (Qurn) 섹션에 설명되어 있습니다.
그림 5-1은 네트워크의 모든 고정 및 가변 지연 소스를 식별합니다.각 출처에 대해서는 이 문서에서 자세히 설명합니다.
그림 5-1:지연 소스 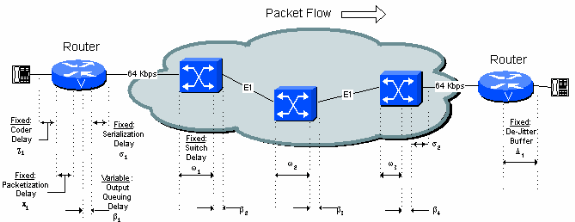
코드(처리 중) 지연
코드 지연 시간은 DSP(디지털 신호 프로세서)가 PCM 샘플 블록을 압축하는 데 걸리는 시간입니다.이를 처리 지연(χn)이라고도 합니다. 이 지연은 사용된 음성 코드 및 프로세서 속도에 따라 달라집니다.예를 들어 ACELP(대수적 코드 흥분된 선형 예측) 알고리즘은 PCM 샘플의 10ms 블록을 분석하고 압축합니다.
경합 구조 대수적 코드 흥분선형 예측(CS-ACELP) 프로세스의 압축 시간은 DSP 프로세서의 로드를 기준으로 2.5ms에서 10ms의 범위입니다.DSP에 4개의 음성 채널이 완전히 로드되면 코드 지연 시간은 10ms입니다.DSP에 음성 채널이 하나만 로드되면 코드 지연 시간은 2.5ms입니다.설계상 최악 10ms의 케이스 시간을 사용합니다.
압축 해제 시간은 각 블록의 압축 시간의 약 10%입니다.그러나 압축 해제 시간은 여러 샘플이 있기 때문에 프레임당 샘플 수에 비례합니다.따라서 세 개의 샘플이 있는 프레임에 대해 최악의 경우 압축 해제 시간은 3 x 1 ms 또는 3ms입니다.일반적으로 압축된 G.729 출력의 두 개 또는 세 개의 블록이 한 프레임에 배치되고 한 개의 압축 G.723.1 출력 샘플은 단일 프레임으로 전송됩니다.
표 5.1에는 가장 좋은 케이스 코더 지연 및 최악의 경우 코더 지연이 나와 있습니다.
표 5.1 최상의/최악의 케이스 처리 지연
| 코더 | 비율 | 필수 샘플 블록 | Best Case Coder 지연 | 최악의 케이스 코더 지연 |
|---|---|---|---|---|
| ADPCM, G.726 | 32Kbps | 10밀리초 | 2.5밀리초 | 10밀리초 |
| CS-ACELP, G.729A | 8.0Kbps | 10밀리초 | 2.5밀리초 | 10밀리초 |
| MP-MLQ, G.723.1 | 6.3Kbps | 30밀리초 | 5밀리초 | 20밀리초 |
| MP-ACELP, G.723.1 | 5.3Kbps | 30밀리초 | 5밀리초 | 20밀리초 |
알고리즘 지연
압축 알고리즘은 알려진 음성 특성을 사용하여 샘플 블록 N을 올바르게 처리합니다. 샘플 블록 N을 정확하게 재현하려면 알고리즘이 블록 N+1에 있는 내용을 알고 있어야 합니다. 이 해상도는 추가적인 지연인 알고리즘 지연이라고 합니다.이렇게 하면 압축 블록의 길이가 효과적으로 증가합니다.
N+1 차단은 N+2 차단을 찾는 등 반복적으로 발생합니다.순효과는 링크의 전체 지연에 5ms가 추가됩니다.즉, 정보 블록을 처리하는 데 필요한 총 시간은 10m이며, 이 시간은 5ms의 지속적인 오버헤드 계수입니다.그림 3-1 참조:음성 압축.
-
G.726 코더의 알고리즘 지연은 0ms입니다.
-
G.729 코더의 알고리즘 지연은 5ms입니다.
-
G.723.1 코더의 알고리즘 지연은 7.5ms입니다.
이 문서의 나머지 부분에 있는 예제를 보려면 30ms/30바이트 페이로드로 G.729 압축을 가정합니다.설계를 용이하게 하고 보수적으로 접근하기 위해 이 문서의 나머지 부분에 나와 있는 표는 최악의 경우 코드 지연으로 간주합니다.코더 지연, 압축 해제 지연 및 알고리즘 지연은 코더 지연이라고 하는 한 가지 요인으로 분류됩니다.
일괄 코더 지연 매개변수를 생성하는 데 사용되는 방정식은 다음과 같습니다.
수식 1:Lumped Coder 지연 매개변수 
이 문서의 나머지 부분에 사용되는 G.729의 루핑된 코더 지연은 다음과 같습니다.
블록당 최악의 케이스 압축 시간:10밀리초
블록당 압축 해제 시간 x 3블록 3ms
알고리즘 지연 5ms —
합계(χ) 18ms
박케화 지연
파키화 지연(n)은 패킷 페이로드를 인코딩된/압축된 음성으로 채우는 데 걸리는 시간입니다.이 지연은 vocoder에 필요한 샘플 블록 크기 및 단일 프레임에 배치된 블록 수의 함수입니다.음성 샘플이 해제되기 전에 버퍼에 누적되므로 패킷화 지연도 누적 지연이라고 할 수 있습니다.
일반적인 규칙으로서 30ms를 넘지 않는 박화 지연을 위해 노력해야 합니다.Cisco 라우터/게이트웨이에서 구성된 페이로드 크기에 따라 표 5.2의 다음 숫자를 사용해야 합니다.
표 5.2:공통 패킷
| 코더 | 페이로드 크기(바이트) | 패킷 지연(ms) | 페이로드 크기(바이트) | 패킷 지연(ms) | |
|---|---|---|---|---|---|
| PCM, G.711 | 64Kbps | 160 | 20 | 240 | 30 |
| ADPCM, G.726 | 32Kbps | 80 | 20 | 120 | 30 |
| CS-ACELP, G.729 | 8.0Kbps | 20 | 20 | 30 | 30 |
| MP-MLQ, G.723.1 | 6.3Kbps | 24 | 24 | 60 | 48 |
| MP-ACELP, G.723.1 | 5.3Kbps | 20 | 30 | 60 | 60 |
CPU 부하에 대해 패킷화 지연의 균형을 맞춰야 합니다.지연이 낮을수록 프레임 속도가 높아지고 CPU의 로드가 높아집니다.일부 이전 플랫폼에서는 20ms 페이로드를 통해 주 CPU가 과부화될 수 있습니다.
패킷화 프로세스의 파이프라인 지연
각 음성 샘플의 경우 알고리즘 지연 및 패킷화 지연이 모두 발생하지만, 실제로는 프로세스가 중첩되며 이러한 파이프라인의 순 편익 효과가 있습니다.그림 2-1에 나와 있는 예를 생각해 보십시오.
그림 5-2:파이프라이닝 및 패킷화 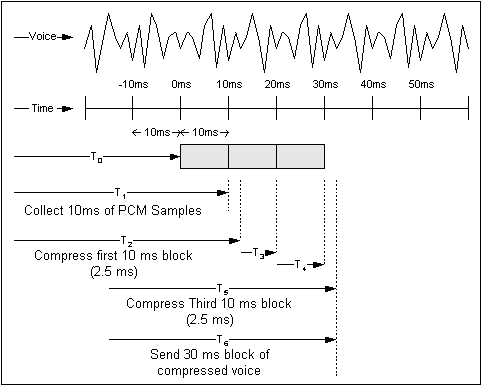
그림의 맨 위에는 샘플 음성 웨이브 형태가 나와 있습니다.두 번째 줄은 10ms 단위로 시간 배율입니다.T0에서 CS-ACELP 알고리즘은 코덱에서 PCM 샘플을 수집하기 시작합니다.T1에서 이 알고리즘은 첫 10ms의 샘플을 수집하여 압축하기 시작합니다.T2에서 첫 번째 샘플 블록이 압축되었습니다.이 예에서 압축 시간은 T2-T1에 표시된 대로 2.5ms입니다.
두 번째 및 세 번째 블록은 T3 및 T4에서 수집됩니다. 세 번째 블록은 T5에서 압축됩니다. 패킷은 T6에서 어셈블되고 전송(즉시로 가정)됩니다. 압축 및 패킷화 프로세스의 파이프라인 특성 때문에, 음성 프레임이 전송될 때까지의 지연 시간이 T6-T0 또는 약 32.5ms입니다.
예를 들어, 이 예는 최상의 케이스 지연을 기반으로 합니다.최악의 케이스 지연이 사용되는 경우, 이 수치는 40ms, 코더 지연의 경우 10ms, 패킷화 지연의 경우 30ms입니다.
이러한 예제는 알고리즘 지연을 포함하지 않습니다.
직렬화 지연
Serialization 지연(n)은 네트워크 인터페이스에 음성 또는 데이터 프레임을 클럭하는 데 필요한 고정 지연입니다.트렁크의 클럭 속도와 직접 관련이 있습니다.클럭 속도가 낮고 프레임 크기가 작으면 프레임을 분리하는 데 필요한 추가 플래그가 중요합니다.
표 5.3은 서로 다른 선 속도에서 서로 다른 프레임 크기에 필요한 직렬화 지연을 보여줍니다.이 테이블은 계산에 페이로드 크기가 아니라 총 프레임 크기를 사용합니다.
표 5.3:다양한 프레임 크기에 대한 직렬화 지연(밀리초)
| 프레임 크기(바이트) | 회선 속도(Kbps) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 19.2 | 56 | 64 | 128 | 256 | 384 | 512 | 768 | 1024 | 1544 | 2048 | |
| 38 | 15.83 | 5.43 | 4.75 | 2.38 | 1.19 | 0.79 | 0.59 | 0.40 | 0.30 | 0.20 | 0.15 |
| 48 | 20.00 | 6.86 | 6.00 | 3.00 | 1.50 | 1.00 | 0.75 | 0.50 | 0.38 | 0.25 | 0.19 |
| 64 | 26.67 | 9.14 | 8.00 | 4.00 | 2.00 | 1.33 | 1.00 | 0.67 | 0.50 | 0.33 | 0.25 |
| 128 | 53.33 | 18.29 | 16.00 | 8.00 | 4.00 | 2.67 | 2.00 | 1.33 | 1.00 | 0.66 | 0.50 |
| 256 | 106.67 | 36.57 | 32.00 | 16.00 | 8.00 | 5.33 | 4.00 | 2.67 | 2.00 | 1.33 | 1.00 |
| 512 | 213.33 | 73.14 | 64.00 | 32.00 | 16.00 | 10.67 | 8.00 | 5.33 | 4.00 | 2.65 | 2.00 |
| 1024 | 426.67 | 149.29 | 128.00 | 64.00 | 32.00 | 21.33 | 16.00 | 10.67 | 8.00 | 5.31 | 4.00 |
| 1500 | 625.00 | 214.29 | 187.50 | 93.75 | 46.88 | 31.25 | 23.44 | 15.63 | 11.72 | 7.77 | 5.86 |
| 2048 | 853.33 | 292.57 | 256.00 | 128.00 | 64.00 | 42.67 | 32.00 | 21.33 | 16.00 | 10.61 | 8.00 |
테이블에서 64Kbps 회선에서 길이가 38바이트(37+1 플래그)인 CS-ACELP 음성 프레임은 직렬화 지연 시간이 4.75ms입니다.
참고: 53바이트 ATM 셀(T1:0.275ms, E1:0.207ms)는 라인 속도와 스몰 셀 크기로 인해 무시할 수 있습니다.
대기/버퍼링 지연
압축된 음성 페이로드가 빌드되면 헤더가 추가되고 네트워크 연결에서 전송을 위해 프레임이 대기됩니다.음성은 라우터/게이트웨이에서 절대 우선 순위를 가져야 합니다.따라서 음성 프레임은 이미 재생된 데이터 프레임 또는 그 앞에 있는 다른 음성 프레임만 대기해야 합니다.기본적으로 음성 프레임은 출력 대기열에 있는 이전 프레임의 직렬화 지연을 기다립니다.대기 지연(sender)은 가변 지연이며 트렁크 속도와 대기열 상태에 따라 달라집니다.대기 지연과 연관된 임의 요소가 있습니다.
예를 들어, 64Kbps 회선에 있고 한 데이터 프레임(48바이트)과 한 음성 프레임(42바이트) 뒤에 대기열에 있다고 가정합니다. 48바이트 프레임 중 얼마나 많은 프레임이 재생되었는지 알 수 있는 무작위 특성이 있기 때문에, 평균적으로 데이터 프레임의 절반이 재생되었다고 가정할 수 있습니다.serialization 테이블의 데이터를 기반으로 데이터 프레임 구성 요소는 6ms * 0.5 = 3ms입니다.대기열에서 다른 음성 프레임 앞에 오는 시간(5.25ms)을 추가하면 총 8.25ms의 대기 지연이 발생합니다.
대기열 지연의 특성을 파악하는 방법은 네트워크 엔지니어가 담당합니다.일반적으로 최악의 경우 시나리오를 설계하고 네트워크를 설치한 후 성능을 조정해야 합니다.사용자가 사용할 수 있는 음성 회선이 많을수록 평균 음성 패킷이 대기열에서 대기할 가능성이 높습니다.우선 순위 구조로 인해 음성 프레임은 두 개 이상의 데이터 프레임 뒤에 대기하지 않습니다.
네트워크 스위칭 지연
엔드포인트 위치를 상호 연결하는 공용 프레임 릴레이 또는 ATM 네트워크는 음성 연결을 가장 많이 지연시키는 소스입니다.네트워크 스위칭 지연(옴)도 수량화하기가 가장 어렵습니다.
Cisco 장비 또는 기타 사설 네트워크에서 광역 연결을 제공하는 경우 지연의 개별 구성 요소를 식별할 수 있습니다.일반적으로 고정 구성 요소는 네트워크 내의 트렁크에 대한 전파 지연에서 비롯되며, 가변 지연은 대속 스위치에 프레임을 잠그거나 나가는 대기 지연에서 발생합니다.전파 지연을 추정하기 위해, 널리 사용되는 10마이크로초/마일 또는 6마이크로초/km(G.114)의 예상 수치가 널리 사용됩니다.그러나 중간 멀티플렉싱 장비, 백홀, 전자레인지 링크 및 캐리어 네트워크에서 발견되는 기타 요인들은 많은 예외를 만들어 냅니다.
지연의 또 다른 중요한 요소는 WAN 내에서 대기하는 것입니다.프라이빗 네트워크에서는 기존 대기 지연을 측정하거나 광역 네트워크 내에서 홉별 예산을 추정할 수 있습니다.
미국 프레임 릴레이 연결에 대한 일반적인 캐리어 지연은 40ms 고정형 및 25ms의 변수로, 총 최악의 경우 65ms입니다.간소화를 위해 예를 들어 6-1, 6-2 및 6-3에서는 40ms 고정 지연의 저속 직렬화 지연이 포함됩니다.
이 수치는 미국 내 어느 곳에서나 서비스를 제공하기 위해 미국 프레임 릴레이 통신 사업자가 게시한 수치입니다.최악의 경우보다 지리적으로 가까운 두 곳의 위치가 지연 성능이 더 우수하지만, 통신사는 일반적으로 최악의 경우를 문서화합니다.
프레임 릴레이 캐리어는 때때로 프리미엄 서비스를 제공합니다.이러한 서비스는 일반적으로 음성 또는 SNA(Systems Network Architecture) 트래픽에 사용되며, 네트워크 지연이 보장되며 표준 서비스 레벨보다 낮습니다.예를 들어, 미국의 한 운송회사는 최근 표준 서비스의 65ms가 아닌 전체 지연 시간 제한을 50ms로 하는 이러한 서비스를 발표했다.
지터 지연 제거
스피치는 지속적인 비트 속도 서비스이므로 신호가 네트워크를 나가기 전에 모든 변수 지연의 지터를 제거해야 합니다.Cisco 라우터/게이트웨이에서 이는 원엔드(수신) 라우터/게이트웨이에 있는 de-jitter(Qurn) 버퍼로 수행됩니다.de-jitter 버퍼는 변수 지연을 고정 지연으로 변환합니다.첫 번째 샘플을 받은 후 재생합니다.이 보유 기간은 초기 재생 지연 시간이라고 합니다.
그림 5- 3:지터 버퍼 작업 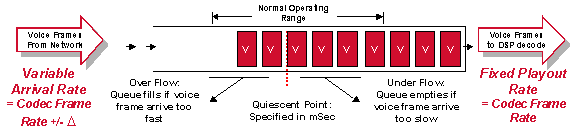
de-jitter 버퍼를 올바르게 처리하는 것이 중요합니다.샘플이 너무 짧은 시간 동안 보관될 경우 지연의 변동으로 인해 버퍼가 실행되고 음성에 간격이 생길 수 있습니다.샘플이 너무 오래 보관되면 버퍼가 오버런될 수 있으며 삭제된 패킷은 다시 음성 간격을 유발합니다.마지막으로, 패킷이 너무 오래 보관되면 연결의 전체 지연이 허용되지 않는 수준으로 증가할 수 있습니다.
de-jitter 버퍼에 대한 최적의 초기 재생 지연 시간은 연결의 총 변수 지연과 같습니다.그림 5-4에 나와 있습니다.
참고: de-jitter 버퍼는 적응할 수 있지만 최대 지연은 고정됩니다.적응형 버퍼가 구성되면 지연은 가변 숫자가 됩니다.그러나 최대 지연을 설계 목적으로 최악의 케이스로 사용할 수 있습니다.
적응형 버퍼에 대한 자세한 내용은 VoIP에 대한 재생 지연 개선 사항을 참조하십시오.
그림 5 -4:가변 지연 및 디지터 버퍼 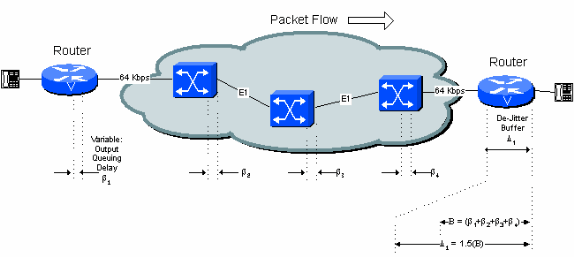
초기 플레이아웃 지연을 구성할 수 있습니다.오버플로되기 전의 버퍼의 최대 깊이는 일반적으로 이 값의 1.5 또는 2.0배로 설정됩니다.
40ms의 명목상 지연 설정을 사용하는 경우 de-jitter 버퍼가 비어 있을 때 받은 첫 번째 음성 샘플은 재생되기 전에 40ms 동안 유지됩니다.이는 네트워크에서 수신된 후속 패킷이 음성 연속성 손실 없이 최대 40ms 지연될 수 있음을 의미합니다(첫 번째 패킷과 관련해서).40ms 이상 지연되면 de-jitter 버퍼 비우기 및 수신된 다음 패킷이 40ms 동안 보관되어 버퍼를 재설정하기 위해 재생됩니다.그 결과 약 40ms 동안 재생된 음성의 간격이 생기게 됩니다.
지연에 대한 de-jitter 버퍼의 실제 기여도는 de-jitter 버퍼의 초기 재생 지연에 첫 번째 패킷이 네트워크에서 버퍼링된 실제 양을 더한 것입니다.최악의 경우는 de-jitter 버퍼 초기 지연의 두 배입니다(네트워크를 통한 첫 번째 패킷에 최소 버퍼링 지연만 발생한다고 가정). 실제로 많은 네트워크 스위치 홉을 통해 최악의 경우를 가정할 필요는 없습니다.이 문서의 나머지 부분에 있는 예제의 계산을 통해 초기 재생 지연 시간이 1.5배씩 증가하여 이 효과를 얻을 수 있습니다.
참고: 수신 라우터/게이트웨이에서 압축 해제 기능을 통해 지연이 발생합니다.그러나 앞서 설명한 대로 압축 처리 지연과 함께 이를 분류하여 고려합니다.
지연 예산 작성
고품질 음성 연결 지연에 대해 일반적으로 허용되는 제한은 200ms 단방향(또는 250ms의 제한)입니다. 이 수치에서 지연이 증가함에 따라, 말꾼과 청취자는 동기화되지 않게 되고, 종종 동시에 말을 하거나, 둘 다 상대방이 말을 할 때까지 기다립니다.이러한 상황을 탈커 중복 이라고 합니다.전반적인 음성 품질이 만족스럽기는 하지만, 사용자는 대화의 진정된 특성이 도저히 받아들일 수 없을 정도로 짜증나는 경우가 종종 있습니다.위성 연결을 통해 이동하는 국제 전화 통화에서 Talker 중복을 확인할 수 있습니다(위성 지연은 500ms, 250ms up, 250ms down).
다음 예는 다양한 네트워크 컨피그레이션과 네트워크 디자이너가 고려해야 하는 지연을 보여줍니다.
Single-Hop 연결
그림 6 - 1:단일 홉의 예 연결 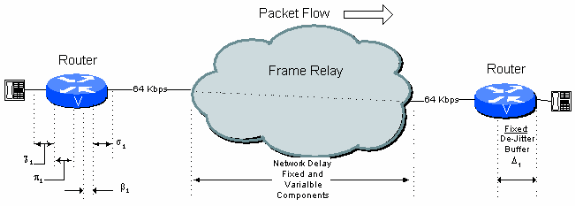
이 그림에서 퍼블릭 프레임 릴레이 연결을 통한 일반적인 원-홉의 연결은 표 6.1에 표시된 지연 예산을 가질 수 있습니다.
표 6.1:단일 홉의 지연 계산
| 지연 유형 | 고정(ms) | 변수(ms) |
|---|---|---|
| 코드 지연, χ1 | 18 | |
| 팩커화 지연, π1 | 30 | |
| 큐/버퍼링, OS1 | 8 | |
| 직렬화 지연(64kbps), σ1 | 5 | |
| 네트워크 지연(공용 프레임), ω1 | 40 | 25 |
| 디지터 버퍼 지연, Δ1 | 45 | |
| 합계 | 138 | 33 |
참고: 대기 지연 시간 및 네트워크 지연의 변수 구성 요소가 이미 de-jitter 버퍼 계산 내에서 고려되었으므로 총 지연은 모든 고정 지연의 합계에만 효과적입니다.이 경우 총 지연 시간은 138ms입니다.
C7200이 Tandem 스위치로 작동하는 공용 네트워크의 두 홉스
그림 6 - 2:라우터/게이트웨이 Tandem을 사용하는 두 개의 홉스 공용 네트워크 예 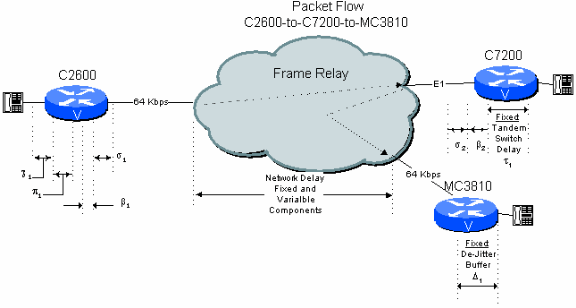
이제 Star-Topology 네트워크에서 지사 간 연결을 고려합니다. 여기서 본사 사이트의 C7200이 대상 지사에 대한 통화를 대기시킵니다.이 경우 신호는 중앙 C7200을 통해 압축된 형식으로 유지됩니다. 따라서 PBX Tandem 스위치를 사용하는 공용 네트워크를 통한 2홉의 연결이라는 다음 예와 관련하여 지연 예산을 상당히 절감할 수 있습니다.
표 6.2:라우터/게이트웨이 Tandem을 통한 2Hop 공용 네트워크 지연 계산
| 지연 유형 | 고정(ms) | 변수(ms) |
|---|---|---|
| 코드 지연, χ1 | 18 | |
| 팩커화 지연, π1 | 30 | |
| 큐/버퍼링, OS1 | 8 | |
| 직렬화 지연(64kbps), σ1 | 5 | |
| 네트워크 지연(공용 프레임), ω1 | 40 | 25 |
| MC3810, τ1의 직렬 지연 | 1 | |
| 큐/버퍼링, SSS2 | 0.2 | |
| 직렬화 지연(2Mbps), σ2 | 0.1 | |
| 네트워크 지연(공용 프레임), ω2 | 40 | 25 |
| 디지터 버퍼 지연, Δ1 | 75 | |
| 합계 | 209.1 | 58.2 |
참고: 대기 지연 시간 및 네트워크 지연의 변수 구성 요소가 이미 de-jitter 버퍼 계산 내에서 고려되었으므로 총 지연은 모든 고정 지연의 합계에만 효과적입니다.이 경우 총 지연 시간은 209.1ms입니다.
PBX Tandem 스위치를 사용하여 공용 네트워크를 통한 2홉의 연결
그림 6-3:PBX Tandem을 사용하는 2Hop 공용 네트워크 예 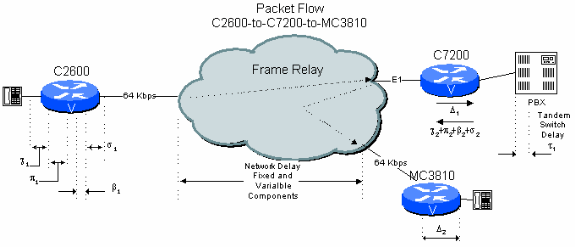
본사 사이트의 C7200이 전환을 위해 본사 PBX로 연결을 전달하는 지사-본사 네트워크에서의 지사 간 연결을 고려해 보십시오.여기서는 음성 신호를 압축 해제하여 지터를 제거한 다음 다시 압축 및 de-jitter를 수행해야 합니다.이 경우 이전 예와 비교하여 지연이 추가로 발생합니다.또한 두 CS-ACELP 압축 사이클은 음성 품질을 낮춥니다(다중 압축 사이클의 효과 참조).
표 6.3:PBX Tandem을 통한 2Hop 공용 네트워크 지연 계산
| 지연 유형 | 고정(ms) | 변수(ms) |
|---|---|---|
| 코드 지연, χ1 | 18 | |
| 팩커화 지연, π1 | 30 | |
| 큐/버퍼링, OS1 | 8 | |
| 직렬화 지연(64kbps), σ1 | 5 | |
| 네트워크 지연(공용 프레임), ω1 | 40 | 25 |
| 디지터 버퍼 지연, Δ1 | 40 | |
| 코드 지연, χ2 | 15 | |
| 팩커화 지연, π2 | 30 | |
| 큐/버퍼링, SSS2 | 0.1 | |
| 직렬화 지연(2Mbps), σ2 | 0.1 | |
| 네트워크 지연(공용 프레임), ω2 | 40 | 25 |
| 디지터 버퍼 지연, Δ2 | 40 | |
| 합계 | 258.1 | 58.1 |
참고: 대기 지연 및 네트워크 지연의 변수 구성 요소가 이미 de-jitter 버퍼 계산 내에서 고려되었으므로 총 지연은 모든 고정 지연과 de-jitter 버퍼 지연의 합계만 효과적으로 계산됩니다.이 경우 총 지연 시간은 258.1ms입니다.
중앙 사이트에서 PBX를 스위치로 사용하면 단방향 연결 지연이 206ms에서 255ms로 증가합니다.이는 단방향 지연에 대한 ITU 제한에 가깝습니다.이러한 유형의 네트워크 컨피그레이션은 엔지니어가 최소한의 지연을 위해 설계에 세심한 주의를 기울여야 합니다.
가장 나쁜 경우는 가변 지연으로 간주됩니다(공용 네트워크의 두 레그가 동시에 최대 지연을 볼 수는 없지만). 변수 지연에 대해 더 낙관적인 가정을 할 경우, 상황이 최소로 개선됩니다.그러나 캐리어의 프레임 릴레이 네트워크에서 고정형 및 가변 지연에 대한 더 나은 정보를 통해 계산된 지연을 줄일 수 있습니다.로컬 연결(예: Intra-State)은 지연 특성이 훨씬 더 높을 것으로 예상되지만, 통신사는 종종 지연 제한을 주지 않습니다.
PBX Tandem 스위치를 사용하여 사설 네트워크를 통한 2홉의 연결
그림 6-4:PBX Tandem을 사용한 2개의 Hop Private Network 예 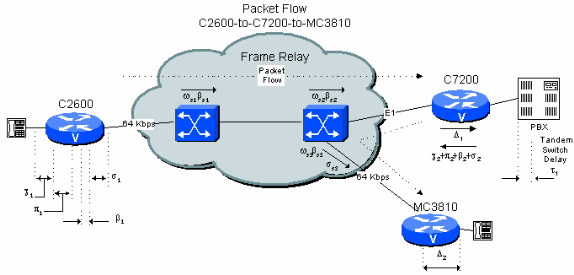
예를 들어 4.3에서는 최악의 케이스 지연을 가정할 때 지사 간 연결에서 중앙 사이트에 PBX 직렬 홉이 포함되고 양쪽에 공용 프레임 릴레이 네트워크 연결이 있는 경우 계산된 지연을 200ms로 유지하는 것이 매우 어렵다는 것을 보여줍니다.그러나 네트워크 토폴로지 및 트래픽을 알 수 있으면 계산된 수치를 상당히 줄일 수 있습니다.이는 일반적으로 통신사에서 제공하는 수치는 넓은 지역에 걸쳐 최악의 전송 및 대기 지연에 의해 제한되기 때문입니다.프라이빗 네트워크에서 더 합리적인 한도를 설정하는 것이 훨씬 쉽습니다.
스위치 간 전송 지연에 일반적으로 허용되는 수치는 10 마이크로초/마일의 순서입니다.장비에 따라 프레임 릴레이 네트워크의 트랜스 스위치 지연은 큐잉을 위해 1ms fixed 및 5ms의 변수여야 합니다.이 수치는 장비 및 트래픽에 따라 달라집니다.E1/T1 트렁크를 사용하는 경우 Cisco MGX WAN 스위치의 지연 수치는 스위치 총계 1ms 미만입니다.500마일의 거리를 가정하고 각 홉에 대해 1ms fixed 및 5ms 변수를 사용하면 지연 계산은 다음과 같습니다.
표 6.4:PBX Tandem을 통한 2홉의 프라이빗 네트워크 지연 계산
| 지연 유형 | 고정(ms) | 변수(ms) |
|---|---|---|
| 코드 지연, χ1 | 18 | |
| 팩커화 지연, π1 | 30 | |
| 큐/버퍼링, OS1 | 8 | |
| 직렬화 지연(64kbps), σ1 | 5 | |
| 네트워크 지연(전용 프레임), 옴S1 + sS1+ 옴S2 + S2 | 2 | 10 |
| 디지터 버퍼 지연, Δ1 | 40 | |
| 코드 지연, χ2 | 15 | |
| 팩커화 지연, π2 | 30 | |
| 큐/버퍼링, SSS2 | 0.1 | |
| 직렬화 지연(2Mbps), σ2 | 0.1 | |
| 네트워크 지연(전용 프레임), 옴S3 + sS3 | 1 | 8 |
| 직렬화 지연(64kbps), S3 | 5 | |
| 디지터 버퍼 지연, Δ2 | 40 | |
| 전송/거리 지연(분석되지 않음) | 5 | |
| 합계 | 191.1 | 26.1 |
참고: 대기 지연 시간 및 네트워크 지연의 변수 구성 요소가 이미 de-jitter 버퍼 계산 내에서 고려되었으므로 총 지연은 모든 고정 지연의 합계입니다.이 경우 총 지연 시간은 191.1ms입니다.
사설 프레임 릴레이 네트워크를 통해 실행할 경우 허브 사이트의 PBX를 통해 스포크-스포크 연결을 만들고 200ms의 그림에서 그대로 유지할 수 있습니다.
다중 압축 사이클의 효과
CS-ACELP 압축 알고리즘은 결정적이지 않습니다.즉, 입력 데이터 스트림이 출력 데이터 스트림과 정확히 같지 않습니다.그림 7-1과 같이 각 압축 주기와 함께 작은 양의 왜곡이 도입됩니다.
그림 7-1:압축 효과 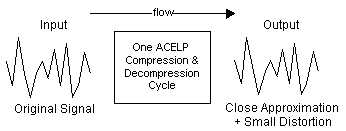
따라서 여러 CS-ACELP 압축 주기가 빠르게 왜곡을 일으킬 수 있습니다.이 추가 왜곡 효과는 적응형 ADPCM(differential pulse code modulation) 알고리즘과 달리 표현되지 않습니다.
이러한 특징이 미치는 영향은 지연의 효과 외에도 네트워크 설계자가 경로의 CS-ACELP 압축 주기 수를 고려해야 한다는 것입니다.
음성은 주관적이다.대부분의 사용자는 2개의 압축 주기가 여전히 적절한 음성 품질을 제공한다는 것을 알고 있습니다.세 번째 압축 주기는 일반적으로 심각한 성능 저하를 초래하며, 일부 사용자는 이를 받아들일 수 없습니다.일반적으로 네트워크 디자이너는 경로에서 CS-ACELP 압축 주기 수를 2로 제한해야 합니다.주기를 더 사용해야 하는 경우 고객이 먼저 듣게 합니다.
이전 예에서 본사의 PBX(PCM 형식)를 통해 지점과 지점 간 연결이 동시에 전환될 경우 본사 C7200에서 동시에 전환된 경우보다 훨씬 더 많은 지연이 발생합니다. PBX를 사용하여 전환할 경우 중앙 C7020에서 음성을 전환했을 때 하나의 주기가 아니라 경로에 두 개의 CS-ACELP 압축 주기가 있다는 것이 분명합니다. C7200 스위치드 예제(4.2)에서는 음성 품질이 더 우수하지만, 통화 계획 관리와 같은 다른 이유로 PBX를 경로에 포함해야 할 수도 있습니다.
중앙 PBX를 통해 지사 간 연결이 이루어지며 두 번째 지점에서 통화가 공용 음성 네트워크를 통해 확장되고 셀룰러 전화 네트워크에서 종료되는 경우 경로에 CS-ACELP 압축 주기가 3개 있으며 지연도 크게 증가합니다.이 시나리오에서는 품질이 눈에 띄게 영향을 받습니다.다시 한 번, 네트워크 디자이너는 최악의 통화 경로를 고려하고 사용자 네트워크, 기대 및 비즈니스 요구 사항에 따라 허용 여부를 결정해야 합니다.
높은 지연 연결 고려 사항
일반적으로 ITU에서 150ms의 단방향 지연 제한을 초과하는 패킷 음성 네트워크를 설계하는 것은 비교적 쉽습니다.
패킷 음성 네트워크를 설계할 때 엔지니어는 연결이 사용되는 빈도, 사용자가 요구하는 사항, 관련된 비즈니스 활동 유형을 고려해야 합니다.특정 상황에서 이러한 연결을 허용할 수 있는 것은 일반적이지 않습니다.
프레임 릴레이 연결이 큰 거리를 통과하지 못하면 네트워크의 지연 성능이 예제에 표시된 것보다 더 우수할 가능성이 높습니다.
직렬 라우터/게이트웨이 연결에서 발생하는 총 지연 시간이 너무 길어지면 종단 MC3810s 간에 PVC(Extra Permanent Virtual Circuit)를 직접 구성하는 것이 대안이 될 수 있습니다.이렇게 하면 통신 사업자가 일반적으로 PVC당 요금을 부과하므로 네트워크에 반복되는 비용이 추가되지만 경우에 따라 필요할 수 있습니다.
 피드백
피드백