서비스 수준 관리:모범 사례 백서
목차
소개
이 문서에서는 고가용성 네트워크에 대한 서비스 수준 관리 및 SLA(서비스 수준 계약)에 대해 설명합니다.서비스 수준 관리 및 성과 지표에 대한 중요한 성공 요소가 포함되어 성공을 평가합니다.또한 고가용성 서비스 팀에서 파악한 모범 사례 지침을 따르는 SLA에 대한 중요한 세부 정보도 제공합니다.
서비스 수준 관리 개요
지금까지 네트워크 조직은 견고한 네트워크 인프라를 구축하고 개별 서비스 문제를 해결하기 위해 적극적으로 노력함으로써 증가하는 네트워크 요구 사항을 충족해 왔습니다.운영 중단이 발생하면 조직은 새로운 프로세스, 관리 기능 또는 인프라를 구축하여 특정 운영 중단이 다시 발생하지 않도록 합니다.그러나 변경률이 높아지고 가용성 요구 사항이 증가함에 따라, 예기치 않은 다운타임을 사전에 방지하고 네트워크를 신속하게 복구할 수 있는 향상된 모델이 필요합니다.많은 통신 사업자와 기업 조직에서 비즈니스 목표를 달성하는 데 필요한 서비스 수준을 더 정확하게 정의하려고 시도했습니다.
주요 성공 요인
SLA의 중요한 성공 요인은 획득 가능한 서비스 수준을 성공적으로 구축하고 SLA를 유지하기 위한 주요 요소를 정의하는 데 사용됩니다.중요한 성공 요인으로 자격을 부여하려면 프로세스 또는 프로세스 단계를 통해 SLA의 품질을 개선하고 네트워크 가용성에 대한 일반적인 혜택을 얻을 수 있어야 합니다.또한 중요한 성공 요인은 측정 가능해야 하며, 이는 조직이 정의된 절차와 비교하여 얼마나 성공했는지 판단할 수 있어야 합니다.
자세한 내용은 서비스 수준 관리 구현을 참조하십시오.
성과 지표
성과 지표는 조직이 중요한 성공 요인을 측정하는 메커니즘을 제공합니다.일반적으로 이러한 내용을 매월 검토하여 서비스 수준 정의 또는 SLA가 제대로 작동하는지 확인합니다.네트워크 작업 그룹 및 필요한 툴 그룹은 다음 메트릭을 수행할 수 있습니다.
참고: SLA가 없는 조직의 경우 측정 단위뿐 아니라 서비스 레벨 정의 및 서비스 레벨 검토를 수행하는 것이 좋습니다.
성능 지표에는 다음이 포함됩니다.
-
가용성, 성능, 사후 대응적 서비스 응답 시간, 문제 해결 목표, 문제 에스컬레이션을 포함하는 문서화된 서비스 수준 정의 또는 SLA
-
서비스 수준 규정 준수를 검토하고 개선 사항을 구현하기 위한 월간 네트워킹 서비스 수준 검토 회의
-
가용성, 성능, 우선 순위별 서비스 응답 시간, 우선 순위별 해결 시간, 기타 측정 가능한 SLA 매개변수를 포함한 성능 지표 메트릭.
자세한 내용은 서비스 수준 관리 구현을 참조하십시오.
서비스 수준 관리 프로세스 흐름
서비스 수준 관리를 위한 상위 레벨 프로세스 흐름에는 두 개의 주요 그룹이 있습니다.
다음 다이어그램에서 개체를 클릭하여 해당 단계에 대한 세부 정보를 봅니다.
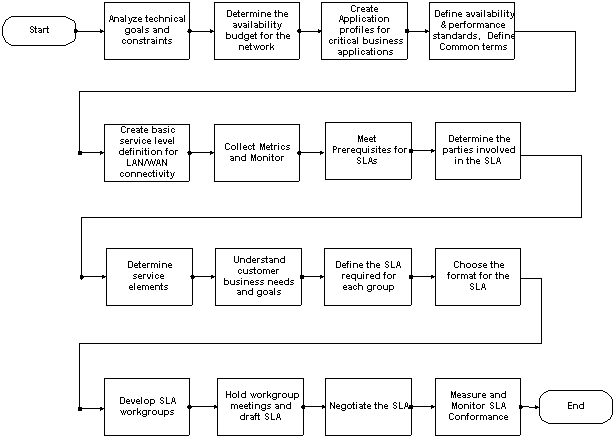
서비스 수준 관리 구현
서비스 수준 관리 구현은 16단계로 구성되며, 다음 두 가지 주요 범주로 구분됩니다.
네트워크 서비스 레벨 정의
네트워크 관리자는 네트워크를 지원, 관리 및 측정하는 주요 규칙을 정의해야 합니다.서비스 레벨은 모든 네트워크 직원에게 목표를 제공하며, 전체 서비스 품질에 대한 메트릭으로 사용될 수 있습니다.또한 서비스 레벨 정의를 네트워크 리소스를 예산 편성하기 위한 툴로 사용할 수 있으며, 더 높은 QoS에 대한 자금 조달을 위한 증거로도 사용할 수 있습니다.또한 벤더 및 캐리어 성능을 평가하는 방법도 제공합니다.
서비스 수준 정의 및 측정이 없으면 조직에 명확한 목표가 없습니다.애플리케이션, 서버/클라이언트 운영 또는 네트워크 지원 간에 차이가 거의 없는 사용자가 서비스 만족도를 관리할 수 있습니다.최종 결과가 조직에 명확하지 않기 때문에 예산 편성이 더욱 어려워질 수 있으며, 마지막으로 네트워크 조직은 네트워크 및 지원 모델을 개선하는 과정에서 사전 대응성이 아닌 사후 대응적인 경향이 있습니다.
서비스 수준 모델을 구축하고 지원하는 데 다음 단계를 권장합니다.
1단계:기술 목표 및 제약 조건 분석
기술적 목표와 제약 조건을 분석하기 시작하는 가장 좋은 방법은 기술적인 목표와 요구 사항을 브레인스토밍하거나 조사하는 것입니다.이러한 개인은 자신의 서비스와 관련된 구체적인 목표를 가지고 있기 때문에 이 논의의 다른 IT 기술 담당자를 초대하는 데 도움이 될 수 있습니다.기술 목표로는 가용성 수준, 처리량, 지터, 지연, 응답 시간, 확장성 요구 사항, 새로운 기능 도입, 새로운 애플리케이션 도입, 보안, 관리 용이성, 비용 등이 있습니다.그런 다음 사용 가능한 리소스에 따라 이러한 목표를 달성하기 위한 제약 조건을 조사해야 합니다.제약 조건에 대한 설명을 사용하여 각 목표에 대한 워크시트를 생성할 수 있습니다.처음에는, 대부분의 목표를 달성할 수 없는 것처럼 보일 수도 있다.그런 다음 비즈니스 요구 사항을 충족할 수 있는 목표를 우선시하거나 기대치를 낮춥니다.
예를 들어 가용성 레벨이 99.999%이거나 연간 5분의 다운타임이 발생할 수 있습니다.하드웨어 단일 장애 지점, MTTR(Mean Time to Repair) 고장 하드웨어 원격 위치, 캐리어 신뢰성, 사전 장애 감지 기능, 높은 변경률, 현재 네트워크 용량 제한 등 이러한 목표를 달성하기 위한 수많은 제약이 있습니다.따라서 목표를 더 달성 가능한 수준으로 조정할 수 있습니다.다음 섹션의 가용성 모델을 통해 현실적인 목표를 설정할 수 있습니다.
또한 제약 조건이 적은 네트워크의 특정 영역에서 더 높은 가용성을 제공하는 것에 대해서도 생각할 수 있습니다.네트워킹 조직이 가용성 서비스 표준을 게시하면 조직 내의 비즈니스 그룹이 허용되지 않는 수준을 찾을 수 있습니다.따라서 비즈니스 요구 사항을 충족할 수 있는 SLA 논의 또는 자금 조달/예산 책정 모델을 시작할 수 있는 것은 당연합니다.
기술 목표 달성에 관련된 모든 제약 또는 위험을 식별하는 작업가장 큰 위험 또는 원하는 목표에 미치는 영향을 고려하여 제약의 우선 순위를 지정합니다.이를 통해 조직은 네트워크 개선 이니셔티브의 우선 순위를 정하고 제약 조건을 얼마나 쉽게 해결할 수 있는지를 결정할 수 있습니다.다음과 같은 세 가지 제약 조건이 있습니다.
-
네트워크 기술, 복원력 및 구성
-
계획, 설계, 구현 및 운영을 비롯한 라이프사이클 업무
-
현재 트래픽 로드 또는 애플리케이션 동작
네트워크 기술, 복원력 및 구성 제약 조건은 현재 기술, 하드웨어, 링크, 설계 또는 구성과 관련된 제한 또는 위험입니다.기술 제한은 기술 자체에 의해 발생하는 모든 제약 조건을 포함합니다.예를 들어, 현재 어떤 기술도 이중화 네트워크 환경에서 1초 미만의 컨버전스 시간을 허용하지 않으므로 네트워크 전반의 음성 연결을 유지하는 데 중요한 역할을 할 수 있습니다.또 다른 예로, 데이터가 지상 링크에서 이동할 수 있는 원시 속도(밀리초 당 약 100마일)를 들 수 있습니다.
네트워크 하드웨어 복원력 위험 조사는 네트워크의 정의된 경로에 따라 하드웨어 토폴로지, 계층 구조, 모듈 방식, 이중화 및 MTBF에 중점을 두어야 합니다.네트워크 링크 제약 조건은 엔터프라이즈 조직을 위한 네트워크 링크 및 통신업체 연결에 중점을 두어야 합니다.링크 제약 조건에는 링크 이중화 및 다양성, 미디어 제한, 배선 인프라, 로컬 루프 연결, 장거리 연결이 포함될 수 있습니다.설계 제약 조건은 네트워크의 물리적 또는 논리적 설계와 관련되며, 장비 사용 가능한 공간에서부터 라우팅 프로토콜 구현의 확장성에 이르기까지 모든 것을 포함합니다.모든 프로토콜 및 미디어 설계는 구성, 가용성, 확장성, 성능 및 용량과 관련하여 고려해야 합니다.DHCP(Dynamic Host Configuration Protocol), DNS(Domain Name System), 방화벽, 프로토콜 변환기, 네트워크 주소 변환기와 같은 네트워크 서비스 제약 조건도 고려해야 합니다.
수명 주기 방식은 일관성 및 모듈 구조를 위해 일관성 있게 솔루션을 구축하고, 문제를 탐지 및 수리하며, 용량 또는 성능 문제를 방지하고, 네트워크를 구성하는 데 사용되는 네트워크의 프로세스와 관리를 정의합니다.일반적으로 전문 지식 및 프로세스가 비가용성에 가장 큰 도움이 되므로 이 영역을 고려해야 합니다.네트워크 라이프사이클은 계획, 설계, 구현 및 운영의 주기를 의미합니다.이러한 각 영역에서 성능 관리, 구성 관리, 결함 관리, 보안과 같은 네트워크 관리 기능을 이해해야 합니다.네트워크 수명 주기 평가는 Cisco NSA HAS(High-Availability Services) 서비스를 통해 네트워크 수명 주기 관행과 관련된 현재 네트워크 가용성 제약을 보여줍니다.
현재의 트래픽 로드 또는 애플리케이션 제약 조건은 단순히 현재 트래픽 및 애플리케이션의 영향을 의미합니다.
안타깝게도 많은 애플리케이션에 상당한 제약이 있어 세심한 관리가 필요합니다.현재 애플리케이션의 지터, 지연, 처리량 및 대역폭 요구 사항은 일반적으로 많은 제약을 가지고 있습니다.응용 프로그램이 작성된 방식에도 제약 조건이 생성될 수 있습니다.애플리케이션 프로파일링을 통해 이러한 문제를 더 잘 이해할 수 있습니다.다음 섹션에서는 이 기능을 다룹니다.현재 가용성, 트래픽, 용량 및 성능을 전반적으로 조사하는 것은 네트워크 관리자가 현재 서비스 수준의 기대치와 위험을 파악하는 데도 도움이 됩니다.이 작업은 일반적으로 네트워크 베이스라인 설정이라는 프로세스를 통해 수행되며, 이는 일반적으로 약 1개월 동안 정의된 기간 동안 네트워크 성능, 가용성 또는 용량 평균을 정의하는 데 도움이 됩니다.이 정보는 일반적으로 용량 계획 및 추세 분석에 사용되지만 서비스 수준 문제를 파악하는 데도 사용할 수 있습니다.
다음 워크시트에서는 보안 공격 또는 DoS(Denial-of-Service) 공격을 방지하는 예제의 목표에 대해 위의 목표/제약 조건을 사용합니다.또한 이 워크시트를 사용하여 보안 공격을 최소화하기 위한 서비스 범위를 결정할 수도 있습니다.
| 위험 또는 제약 조건 | 제약 조건 유형 | 잠재적 영향 |
|---|---|---|
| 사용 가능한 DoS 탐지 툴로는 모든 유형의 DoS 공격을 탐지할 수 없습니다. | 기술/복원력 | 높음 |
| 경고에 대응할 수 있는 필수 인력과 프로세스가 없습니다. | 라이프사이클 작업 | 높음 |
| 현재 네트워크 액세스 정책이 없습니다. | 라이프사이클 작업 | 중간 |
| 대역폭 혼잡을 공격에 사용하는 경우 현재의 낮은 대역폭 인터넷 연결이 원인일 수 있습니다. | 네트워크 용량 | 중간 |
| 현재 공격을 방지하기 위한 보안 컨피그레이션은 완전하지 않을 수 있습니다. | 기술/복원력 | 중간 |
2단계:가용성 예산 결정
가용성 예산은 정의된 두 지점 간의 네트워크 이론상 가용성입니다.정확한 이론적 정보는 여러 가지 방법으로 유용합니다.
-
조직은 이를 내부 가용성 및 편차를 신속하게 정의하고 해결할 수 있는 목표로 사용할 수 있습니다.
-
이 정보는 네트워크 플래너가 시스템의 가용성을 결정하면서 설계가 비즈니스 요구 사항을 충족하도록 하는 데 사용할 수 있습니다.
하드웨어 장애, 소프트웨어 장애, 전력 및 환경 문제, 링크 또는 캐리어 장애, 네트워크 설계, 인적 오류, 프로세스 부족 등의 이유로 인해 비가용성 또는 중단 시간이 발생할 수 있습니다.네트워크의 전체 가용성 예산을 평가할 때 이러한 각 매개변수를 면밀히 평가해야 합니다.
조직에서 현재 가용성을 측정하는 경우 가용성 예산이 필요하지 않을 수 있습니다.가용성 측정을 기준으로 사용하여 서비스 레벨 정의에 사용된 현재 서비스 레벨을 추정합니다.그러나 실제 측정 결과와 비교하여 이론상의 잠재적 가용성을 파악하기 위해 두 가지를 비교하는 데 관심이 있을 수 있습니다.
가용성은 제품 또는 서비스가 필요할 때 작동할 가능성입니다.다음 정의를 참조하십시오.
-
사용 가능성
-
1 - (총 연결 중단 시간) / (총 서비스 중 연결 시간)
-
1 - [Sigma(X의 가동 중단 기간 i에서 가동 중단에 영향을 받는 수 연결 수)] / (서비스 X의 최대 작동 시간)
-
-
가용성 없음
1 - 가용성 또는 하드웨어 장애, 소프트웨어 장애, 환경 및 전원 문제, 링크 또는 캐리어 장애, 네트워크 설계, 사용자 오류 및 프로세스 장애로 인한 총 연결 시간
-
하드웨어 가용성
첫 번째 조사 영역은 잠재적인 하드웨어 장애 및 비가용성에 미치는 영향입니다.이를 확인하려면 조직은 모든 네트워크 구성 요소의 MTBF와 두 지점 사이의 경로에 있는 모든 장치의 하드웨어 문제에 대한 MTTR을 이해해야 합니다.네트워크가 모듈형 계층적 네트워크인 경우 거의 모든 2포인트 간에 하드웨어 가용성이 동일합니다.MTBF 정보는 모든 Cisco 구성 요소에 사용할 수 있으며 요청 시 로컬 어카운트 매니저에게 제공됩니다.Cisco NSA HAS 프로그램은 또한 시스템에 모듈 이중화, 섀시 이중화 및 경로 이중화가 존재하는 경우에도 네트워크 경로를 따라 하드웨어 가용성을 결정하는 데 도움이 되는 툴을 사용합니다.하드웨어 신뢰성의 주요 요소 중 하나는 MTTR입니다.기업은 고장난 하드웨어를 얼마나 신속하게 복구할 수 있는지 평가해야 합니다.조직에서 예비 부품 보유 계획이 없고 표준 Cisco SMARTnet™ 계약을 사용하는 경우 평균 교체 시간이 약 24시간입니다.코어 이중화와 액세스 이중화가 없는 일반적인 LAN 환경에서 약 99.99%의 가용성은 4시간 MTTR입니다.
-
소프트웨어 가용성
다음 조사 영역은 소프트웨어 장애입니다.Cisco는 소프트웨어 오류로 인해 소프트웨어 장애를 디바이스 콜드시작으로 정의합니다.Cisco는 소프트웨어 가용성을 이해하는 데 큰 진전을 이루었습니다.그러나 최신 릴리스는 측정 시간이 걸리며 일반 구축 소프트웨어보다 사용 가능한 것이 낮은 것으로 간주됩니다.IOS 버전 11.2(18)와 같은 일반적인 구축 소프트웨어는 99.9999% 이상의 가용성을 기준으로 측정되었습니다.이 값은 Cisco 라우터에서 6분을 복구 시간(라우터가 다시 로드되는 시간)으로 사용하는 실제 콜드시작 시간을 기준으로 계산됩니다. 다양한 버전을 사용하는 조직은 복잡성 증가, 상호 운용성 및 문제 해결 시간 증가로 인해 가용성이 약간 저하될 것으로 예상됩니다.최신 소프트웨어 버전을 사용하는 조직은 더 높은 수준의 비가용성을 가질 것으로 예상됩니다.비가용성에 대한 배포도 상당히 광범위하므로, 고객은 일반 구축 릴리스와 가까운 가용성 또는 심각한 비가용성을 경험할 수 있습니다.
-
환경 및 전력 가용성
또한 사용 가능한 환경 및 전력 문제도 고려해야 합니다.환경 문제는 장비를 지정된 작동 온도에서 유지하는 데 필요한 냉각 시스템의 붕괴와 관련이 있습니다.대부분의 Cisco 디바이스는 모든 하드웨어의 손상을 감수하기보다는 사양이 현저히 부족할 때 단순히 종료됩니다.가용 예산에서는 전력이 이 영역에서 비가용성의 주요 원인이므로 사용됩니다.
전원 장애가 네트워크 가용성을 결정하는 중요한 측면이지만 이론상 전력 분석을 정확하게 수행할 수 없기 때문에 이 논의는 제한적입니다.조직이 평가해야 하는 것은 지리적 영역 환경, 전원 백업 기능, 모든 장치에 일관된 품질 성능을 제공하기 위해 구현된 프로세스를 기반으로 장치에 대한 전력 가용성을 대략적으로 측정하는 것입니다.
보수적 평가를 위해, 백업 생성기, UPS(Uninterruptible-power-supply) 시스템 및 고품질 전원 구현 프로세스를 갖춘 기업은 99.9999%의 가용성을 경험할 수 있지만, 이러한 시스템을 사용하지 않는 조직은 99.99%의 가용성을 경험할 수 있으며 연간 다운타임이 약 36분 정도 발생할 수 있습니다.물론 조직의 인식 또는 실제 데이터를 기반으로 이러한 값을 보다 현실적인 값으로 조정할 수 있습니다.
-
링크 또는 캐리어 오류
링크 및 캐리어 장애는 WAN 환경의 가용성과 관련된 주요 요소입니다.WAN 환경은 하드웨어 장애, 소프트웨어 장애, 사용자 오류, 전원 장애 등 조직의 네트워크와 동일한 가용성 문제가 발생하는 다른 네트워크일 뿐입니다.
많은 캐리어 네트워크에서 이미 시스템에 대한 가용성 예산을 수행했지만 이 정보를 얻기 어려울 수 있습니다.또한 통신 사업자는 실제 가용성 예산에 기초하여 거의 또는 전혀 근거가 없는 가용성 보장 레벨을 자주 가지고 있다는 점에 유의하십시오.이러한 보증 레벨은 때때로 단순히 캐리어를 홍보하는 데 사용되는 마케팅 및 영업 방법입니다.경우에 따라 이러한 네트워크는 매우 좋은 것으로 보이는 가용성 통계도 게시합니다.이러한 통계는 완전히 이중화된 코어 네트워크에만 적용될 수 있으며, WAN 네트워크의 비가용성의 주요 원인이 되는 로컬 루프 액세스 때문에 비가용성을 고려하지 않습니다.
WAN 환경에 대한 예상 가용성 생성은 실제 캐리어 정보 및 WAN 연결에 대한 이중화 수준을 기반으로 해야 합니다.조직에 여러 건물 입구 설비, 이중 로컬 루프 공급자, SONET(Synchronous-Optical-Network) 로컬 액세스, 지리적 다양성을 지닌 중복 장거리 통신 사업자가 있는 경우 WAN 가용성이 크게 향상될 것입니다.
전화 서비스는 WAN 환경에서 비이중화 네트워크 연결을 위한 매우 정확한 가용성 예산입니다.전화기의 엔드 투 엔드 연결에는 이 섹션에 설명된 것과 유사한 가용성 예산 방법론을 사용하여 99.94%의 예상 가용 예산이 있습니다.이 방법론은 약간 변형된 데이터 환경에서 성공적으로 사용되었으며, 현재 통신 사업자 케이블 네트워크의 패킷 케이블 사양에서 대상으로 사용되고 있습니다.이 값을 완전히 이중화된 시스템에 적용하면 WAN 가용성이 99.9999%에 가까운 것으로 가정합니다.물론 비용 및 가용성 때문에 지리적으로 완전히 이중화된 WAN 시스템을 보유하고 있는 조직은 거의 없으므로 이 기능에 대한 올바른 판단을 사용하십시오.
LAN 환경에서 링크 장애가 발생할 가능성이 낮습니다.그러나 플래너는 커넥터가 끊어졌거나 느슨하여 약간의 다운타임을 감수해야 할 수 있습니다.LAN 네트워크의 경우 약 99.9999%의 가용성을 예상하며, 이는 연간 약 30초입니다.
-
네트워크 설계
네트워크 설계는 가용성의 또 다른 주요 요인입니다.확장성이 없는 설계, 설계 오류, 네트워크 통합 시간 모두 가용성에 부정적인 영향을 미칩니다.
참고: 이 문서의 목적 상, 확장 불가능한 설계 또는 설계 오류는 다음 섹션에 포함되어 있습니다.
그런 다음 네트워크 설계는 네트워크의 소프트웨어 및 하드웨어 장애를 기반으로 한 측정 가능한 값으로 제한되어 트래픽 재라우팅이 발생합니다.이 값은 일반적으로 "시스템 전환 시간"이라고 하며 시스템 내에서 자가 복구 프로토콜 기능의 한 요소입니다.
시스템 계산에 동일한 방법을 사용하여 가용성을 계산합니다.그러나 이는 네트워크 전환 시간이 네트워크 애플리케이션 요구 사항을 충족하지 않는 한 유효하지 않습니다.전환 시간이 허용되는 경우 계산에서 제거합니다.전환 시간이 허용되지 않는 경우 계산에 추가해야 합니다.예를 들어 예상 또는 실제 전환 시간이 30초인 환경에서 VoIP(Voice over IP)를 사용할 수 있습니다.이 예에서는 사용자가 전화를 끊고 다시 시도할 수 있습니다.사용자는 이 기간을 비가용성으로 볼 수 있지만, 가용성 예산에서는 예측되지 않았습니다.
이중화된 경로를 따라 이론적인 소프트웨어 및 하드웨어 가용성을 확인하여 시스템 전환 시간으로 인해 비가용성을 계산합니다. 이 영역에서 전환이 이루어지기 때문입니다.장애 발생 가능한 디바이스의 수, 이중 경로에서 전환을 일으키는 디바이스의 수, 해당 디바이스의 MTBF 및 전환 시간을 알고 있어야 합니다.간단한 예는 두 개의 동일한 중복 디바이스 각각에 대해 35,433시간의 MTBF와 30초의 전환 시간을 예로 들 수 있습니다.35,433을 8766(윤년을 포함하는 연간 평균 시간)으로 나누면 4년마다 한 번 디바이스가 실패합니다.전환 시간으로 30초를 사용하는 경우, 전환 때문에 각 디바이스에서 매년 평균 7.5초 동안 비가용성을 경험한다고 가정할 수 있습니다.사용자가 두 경로 중 하나를 통과할 수 있으므로, 그 결과는 매년 두 배로 증가하여 15초로 증가합니다.이 값을 연간 초 단위로 계산할 때, 전환으로 인한 가용성은 이 단순 시스템에서 99.99999785% 가용성으로 계산할 수 있습니다.전환 가능성이 있는 네트워크의 중복 디바이스 수 때문에 다른 환경에서도 이 비율이 더 높을 수 있습니다.
-
사용자 오류 및 프로세스
사용자 오류 및 프로세스 가용성 문제는 엔터프라이즈 및 캐리어 네트워크에서 비가용성의 주요 원인입니다.비가용성의 약 80%는 오류, 변경 실패, 성능 문제 등의 문제로 인해 발생합니다.
조직은 가용성 예산을 결정할 때 다른 이론상의 비가용성의 4배만 사용하기를 원치 않을 것입니다. 그러나 많은 환경에서 이러한 경우가 해당한다는 증거가 지속적으로 입증되고 있습니다.다음 섹션에서는 비가용성의 이러한 측면을 보다 철저히 다룹니다.
사용자 오류 및 프로세스로 인해 비가용성의 양을 이론적으로 계산할 수 없으므로 가용성 예산에서 제거된 항목을 제거하고 조직이 완벽을 추구하도록 하는 것이 좋습니다.한 가지 주의 사항은 조직이 자체 프로세스 및 전문성 수준에서 가용성에 대한 현재 위험을 이해해야 한다는 것입니다.이러한 위험과 방해 요인을 더 잘 이해하게 되면 네트워크 플래너는 이러한 문제로 인해 비가용성의 양을 어느 정도 고려하고자 할 수 있습니다.Cisco NSA HAS 프로그램은 이러한 문제를 조사하고 조직이 프로세스, 사용자 오류 또는 전문 지식 문제로 인해 발생할 수 있는 비가용성을 이해하도록 도와줍니다.
-
최종 가용 예산 결정
이전에 정의한 각 영역의 가용성을 곱하여 전체 가용성 예산을 결정할 수 있습니다.이 작업은 일반적으로 계층적 모듈형 LAN 환경 또는 계층적 표준 WAN 환경과 같은 두 지점 간의 연결이 유사한 동종 환경에 대해 수행됩니다.
이 예에서는 계층적 모듈형 LAN 환경에 대한 가용성 예산이 수행됩니다.이 환경은 모든 네트워크 구성 요소에 백업 생성기와 UPS 시스템을 사용하고 전원을 올바르게 관리합니다.조직은 VoIP를 사용하지 않으며 소프트웨어 전환 시간을 고려하기를 원하지 않습니다.예상치는 다음과 같습니다.
-
두 엔드포인트 간 하드웨어 경로 가용성 = 99.99% 가용성
-
GD 소프트웨어 신뢰성을 참조로 사용하는 소프트웨어 가용성 = 99.9999% 가용성
-
백업 시스템을 통한 환경 및 전력 가용성 = 99.999% 가용성
-
LAN 환경에서 링크 장애 = 99.9999% 가용성
-
시스템 전환 시간을 고려하지 않음 = 100% 가용성
-
사용자 오류 및 프로세스 가용성이 완벽하게 보장됨 = 100% 가용성
조직에서 사용해야 하는 최종 가용성 예산은 0.99999 X 0.99999 X 0.99999 X 0.99999 = 0.999896 또는 99.9896% 가용성입니다.사용자 또는 프로세스 오류로 인해 잠재적인 비가용성을 고려하며 기술 요인으로 인해 비가용성이 4배 가용성이라고 가정할 경우 가용성 예산이 99.95%라고 가정할 수 있습니다.
이 예제 분석은 LAN 가용성이 평균 99.95에서 99.989% 사이로 떨어질 것임을 나타냅니다.이제 이러한 수치를 네트워킹 조직의 서비스 수준 목표로 사용할 수 있습니다.시스템의 가용성을 측정하고 위의 6개 영역 각각에서 발생한 비가용성의 비율을 결정함으로써 추가적인 가치를 얻을 수 있습니다.이를 통해 조직은 공급업체, 캐리어, 프로세스 및 직원을 올바르게 평가할 수 있습니다.이 수치를 사용하여 비즈니스 내에서 기대치를 설정할 수도 있습니다.이 숫자를 사용할 수 없는 경우, 추가 리소스를 할당하여 원하는 수준을 얻습니다.
네트워크 관리자는 특정 가용성 수준에서 다운타임의 양을 파악하는 것이 유용할 수 있습니다.가용성 수준을 고려할 때 1년 기간의 다운타임(분) 양은 다음과 같습니다.
1년 동안의 다운타임 분 = 525600 - (가용성 레벨 X 5256)
99.95%의 가용성 레벨을 사용하는 경우, 이 수치는 525600 - (99.95 X 5256) 또는 262.8분의 다운타임이 발생한 것으로 확인됩니다.위 가용성 정의의 경우, 이는 네트워크 내에서 서비스 중인 모든 연결의 평균 다운타임과 같습니다.
-
3단계:애플리케이션 프로파일 생성
애플리케이션 프로필은 네트워킹 조직이 개별 애플리케이션에 대한 네트워크 서비스 수준 요구 사항을 이해하고 정의하는 데 도움이 됩니다.이를 통해 네트워크는 개별 애플리케이션 요구 사항 및 네트워크 서비스를 전체적으로 지원할 수 있습니다.애플리케이션 또는 서버 그룹이 네트워크를 문제로 가리킬 때 애플리케이션 프로필은 네트워크 서비스 지원을 위한 문서화된 기준 역할을 할 수도 있습니다.궁극적으로 애플리케이션 프로필은 성능 및 가용성과 같은 애플리케이션 요구 사항을 현실적인 네트워크 서비스 목표 또는 현재 제한 사항과 비교하여 네트워크 서비스 목표를 애플리케이션 또는 비즈니스 요구 사항에 맞게 조정하는 데 도움이 됩니다.이는 서비스 수준 관리뿐 아니라 전반적인 하향식 네트워크 설계에도 중요합니다.
네트워크에 새 애플리케이션을 도입할 때마다 애플리케이션 프로필을 생성합니다.신규 및 기존 서비스에 대한 애플리케이션 프로필 생성을 적용하기 위해 IT 애플리케이션 그룹, 서버 관리 그룹 및 네트워킹 간에 계약이 필요할 수 있습니다.비즈니스 애플리케이션 및 시스템 애플리케이션을 위한 완전한 애플리케이션 프로파일비즈니스 애플리케이션에는 e- 메일, 파일 전송, 웹 브라우징, 의료 이미지 처리, 제조 등이 포함될 수 있습니다.시스템 애플리케이션에는 소프트웨어 배포, 사용자 인증, 네트워크 백업 및 네트워크 관리가 포함될 수 있습니다.
네트워크 분석가와 애플리케이션 또는 서버 지원 애플리케이션이 애플리케이션 프로필을 생성해야 합니다.새로운 애플리케이션을 사용하려면 애플리케이션 요구 사항의 특성을 제대로 지정하기 위해 프로토콜 분석기 및 WAN 에뮬레이터와 지연 에뮬레이션을 사용해야 할 수 있습니다.따라서 필요한 대역폭, 애플리케이션 사용 편의성에 대한 최대 지연, 지터 요구 사항을 파악할 수 있습니다.필요한 서버가 있는 한 실습 환경에서 이 작업을 수행할 수 있습니다.VoIP와 같은 다른 경우에는 지터, 지연, 대역폭 등 네트워크 요구 사항이 잘 게시되고 랩 테스트가 필요하지 않습니다.애플리케이션 프로필에는 다음 항목이 포함되어야 합니다.
-
응용 프로그램 이름
-
애플리케이션 유형
-
새 애플리케이션?
-
비즈니스 중요성
-
가용성 요구 사항
-
사용되는 프로토콜 및 포트
-
예상 사용자 대역폭(kbps)
-
사용자 수 및 위치
-
파일 전송 요구 사항(시간, 볼륨, 엔드포인트 포함)
-
네트워크 중단 영향
-
지연, 지터 및 가용성 요구 사항
애플리케이션 프로필의 목표는 애플리케이션의 비즈니스 요구 사항, 비즈니스 중요성, 대역폭, 지연, 지터와 같은 네트워크 요구 사항을 파악하는 것입니다.또한 네트워킹 조직은 네트워크 다운타임의 영향을 이해해야 합니다.경우에 따라 전체 애플리케이션 다운타임에 상당한 영향을 미치는 애플리케이션이나 서버를 다시 시작해야 합니다.애플리케이션 프로필을 완료하면 전반적인 네트워크 기능을 비교하고 네트워크 서비스 수준을 비즈니스 및 애플리케이션 요구 사항에 맞게 조정할 수 있습니다.
4단계:가용성 및 성능 표준 정의
가용성 및 성능 표준은 조직에 대한 서비스 기대치를 설정합니다.네트워크 또는 특정 애플리케이션의 다양한 영역에 대해 정의할 수 있습니다.또한 왕복 지연, 지터, 최대 처리량, 대역폭 약정, 전반적인 확장성 등의 측면에서 성능을 정의할 수 있습니다.조직은 서비스 기대치를 설정하는 것 외에도 각 서비스 표준을 정의하도록 주의를 기울여야 합니다. 그러면 네트워킹과 함께 일하는 사용자 및 IT 그룹이 서비스 표준과 애플리케이션 또는 서버 관리 요구 사항과 관련된 방법을 완전히 이해할 수 있습니다.사용자 및 IT 그룹도 서비스 표준을 측정할 수 있는 방법을 이해해야 합니다.
이전 서비스 레벨 정의 단계의 결과는 표준을 생성하는 데 도움이 됩니다.이 시점에서 네트워킹 조직은 네트워크의 현재 위험과 제약, 애플리케이션 동작에 대한 이해, 이론적 가용성 분석 또는 가용성 기준을 명확하게 파악해야 합니다.
-
서비스 표준을 적용할 지역 또는 애플리케이션 영역을 정의합니다.
여기에는 캠퍼스 LAN, 국내 WAN, 엑스트라넷 또는 파트너 연결과 같은 영역이 포함될 수 있습니다.경우에 따라 조직은 한 영역에서 서비스 수준 목표를 다르게 설정할 수 있습니다.기업 또는 서비스 공급자 조직에서는 이러한 문제가 흔히 발생하지 않습니다.이러한 경우 개별 서비스 요구 사항에 따라 다른 서비스 수준 표준을 생성하는 것이 일반적이지 않습니다.이는 하나의 지역 또는 서비스 지역에서 골드, 실버, 브론즈 서비스 표준으로 분류될 수 있습니다.
-
서비스 표준 매개변수를 정의합니다.
가용성 및 왕복 지연이 가장 일반적인 네트워크 서비스 표준입니다.필요에 따라 최대 처리량, 최소 대역폭 약정, 지터, 허용 가능한 오류율 및 확장성 기능도 포함될 수 있습니다.측정 방법에 대한 서비스 매개변수를 검토할 때는 주의해야 합니다.매개 변수가 SLA로 이동하는지 여부에 관계없이, 조직에서는 문제 또는 서비스 불일치가 발생할 때 서비스 매개 변수를 측정하거나 정당화할 수 있는 방법을 고려해야 합니다.
서비스 영역 및 서비스 매개변수를 정의한 후 이전 단계의 정보를 사용하여 서비스 표준 매트릭스를 구축합니다.또한 사용자 및 IT 그룹에 혼동을 일으킬 수 있는 영역을 정의해야 합니다.예를 들어, 왕복 ping에 대한 최대 응답 시간은 특정 애플리케이션의 원격 위치에서 Enter 키를 누르는 경우와 매우 다릅니다.다음 표는 미국 내의 성능 대상을 보여줍니다.
| 네트워크 영역 | 가용성 대상 | 측정 방법 | 평균 네트워크 응답 시간 대상 | 허용되는 최대 응답 시간 | 응답 시간 측정 방법 |
|---|---|---|---|---|---|
| LAN | 99.99% | 영향을 받은 사용자 분 | 5ms 미만 | 10밀리초 | 왕복 ping 응답 |
| WAN | 99.99% | 영향을 받은 사용자 분 | 100ms 미만(왕복 ping) | 150밀리초 | 왕복 ping 응답 |
| 중요 WAN 및 엑스트라넷 | 99.99% | 영향을 받은 사용자 분 | 100ms 미만(왕복 ping) | 150밀리초 | 왕복 ping 응답 |
5단계:네트워크 서비스 정의
이는 기본적인 서비스 수준 관리를 위한 마지막 단계입니다.서비스 수준 목표를 달성하기 위해 구현하는 사후 대응적, 사전 대응적 프로세스 및 네트워크 관리 기능을 정의합니다.최종 문서는 일반적으로 운영 지원 계획이라고 합니다.대부분의 애플리케이션 지원 계획에는 사후 대응적 지원 요구 사항만 포함됩니다.고가용성 환경에서는 사용자 서비스 통화가 시작되기 전에 네트워크 문제를 격리하고 해결하는 데 사용할 사전 대응적 관리 프로세스를 고려해야 합니다.최종 문서는 전반적으로 다음 작업을 수행해야 합니다.
-
서비스 수준 목표를 달성하는 데 사용되는 사후 대응적 및 사전 대응적 프로세스 설명
-
서비스 프로세스 관리 방법
-
서비스 목표 및 서비스 프로세스 측정 방법
이 섹션에서는 많은 서비스 제공자 및 기업 조직에서 고려해야 할 사후 대응적 서비스 정의 및 사전 대응적 서비스 정의에 대한 예를 다룹니다.서비스 수준 정의를 구축하는 목적은 가용성과 성능 목표를 충족하는 서비스를 만드는 것입니다.이를 위해 조직은 현재의 기술 제약, 가용성 예산 및 애플리케이션 프로필을 염두에 두고 서비스를 구축해야 합니다.특히, 조직은 가용성 모델에 의해 할당된 시간 내에 문제를 일관적이고 신속하게 식별하고 해결하는 서비스를 정의하고 구축해야 합니다.또한 조직은 무시될 경우 가용성과 성능에 영향을 미칠 잠재적 서비스 문제를 신속하게 파악하고 해결할 수 있는 서비스를 정의해야 합니다.
원하는 서비스 수준을 하룻밤 사이에 달성할 수 없습니다.낮은 전문성, 현재 프로세스 제한 사항 또는 부족한 인력 수준과 같은 단점은 이전 서비스 분석 단계를 거친 후에도 조직이 원하는 표준 또는 목표를 달성하지 못하게 할 수 있습니다.필요한 서비스 수준을 원하는 목표에 정확히 맞출 수 있는 정확한 방법은 없습니다.이를 수용하려면 서비스 표준을 측정하고 서비스 표준을 지원하는 데 사용되는 서비스 매개변수를 측정해야 합니다.조직이 서비스 목표를 충족하지 않을 경우 서비스 메트릭을 통해 문제를 파악해야 합니다.많은 경우 지원 서비스를 개선하고 원하는 서비스 목표를 달성하는 데 필요한 개선을 위해 예산 증가를 할 수 있습니다.시간이 지남에 따라 조직은 네트워크 서비스 및 비즈니스 요구 사항을 조정하기 위해 서비스 목표 또는 서비스 정의에 대해 몇 가지 조정을 할 수 있습니다.
예를 들어, 99.9%의 가용성으로 목표를 훨씬 높였을 때 조직은 99%의 가용성을 달성할 수 있습니다.서비스 및 지원 메트릭을 살펴본 결과, 이 조직의 담당자는 4개의 예산으로 책정되었기 때문에 하드웨어 교체가 원래 예측보다 훨씬 긴 약 24시간이 소요되었습니다.또한 사전 대응적 관리 기능이 무시되고 중복된 네트워크 디바이스가 복구되지 않고 있음을 발견했습니다.그들은 또한 개선할 인재가 없다는 것을 발견했습니다.그 결과, 현재 서비스 목표를 낮춘다는 것을 고려한 후, 조직은 원하는 서비스 수준을 달성하는 데 필요한 추가 리소스에 대한 예산을 책정했습니다.
서비스 정의에는 사후 대응적 지원 정의와 사전 대응적 정의가 모두 포함되어야 합니다.사후 대응적 정의는 사용자 불만 또는 네트워크 관리 기능에서 식별된 문제에 대해 조직이 어떻게 반응할지 정의합니다.사전 대응적 정의는 손상된 "대기" 네트워크 구성 요소 복구, 오류 감지, 용량 임계값 및 업그레이드 등 잠재적인 네트워크 문제를 식별하고 해결하는 방법을 설명합니다.다음 섹션에서는 사후 대응적 및 사전 대응적 서비스 수준 정의의 예를 제공합니다.
사후 대응적 서비스 수준 정의
다음 서비스 수준 영역은 일반적으로 헬프데스크 데이터베이스 통계 및 정기 감사를 사용하여 측정됩니다.이 표에서는 조직에 대한 문제 심각도의 예를 보여 줍니다.차트에는 SLA 또는 추가 애플리케이션 프로파일링 및 성능 what-if 분석에서 처리할 수 있는 새 서비스에 대한 요청을 처리하는 방법이 포함되지 않습니다.일반적으로 심각도 5는 동일한 지원 프로세스를 통해 처리되는 경우 새 서비스에 대한 요청일 수 있습니다.
| 심각도 1 | 심각도 2 | 심각도 3 | 심각도 4 |
|---|---|---|---|
| 심각한 비즈니스 영향 LAN 사용자 또는 서버 세그먼트 축소 중요 WAN 사이트 다운 | 손실 또는 성능 저하를 통해 비즈니스에 큰 영향을 미칠 수 있으며, 캠퍼스 LAN이 다운될 수 있는 해결 방법5-99명의 사용자가 국내 WAN 사이트에 영향을 미침 국제 WAN 사이트 다운 심각한 성능 영향 | 리던던시 손실과 같은 일부 특정 네트워크 기능이 손실되거나 성능이 저하됨 LAN 리던던시 손실된 캠퍼스 LAN 성능 | 조직에 비즈니스에 영향을 미치지 않는 기능 쿼리 또는 결함 |
문제 심각도를 정의한 경우 지원 프로세스를 정의하거나 조사하여 서비스 응답 정의를 생성합니다.일반적으로 서비스 응답 정의를 위해서는 단계별 지원 구조와 헬프 데스크 소프트웨어 지원 시스템이 문제 티켓을 통해 문제를 추적해야 합니다.또한 각 우선순위에 대한 응답 시간 및 해결 시간, 우선순위별 통화 수, 응답/해결 품질에 대한 메트릭을 사용할 수 있어야 합니다.지원 프로세스를 정의하기 위해 조직의 각 지원 계층의 목표와 해당 역할과 책임을 정의하는 데 도움이 됩니다.이를 통해 조직은 각 지원 수준에 대한 리소스 요구 사항과 전문성 수준을 이해할 수 있습니다.다음 표는 문제 해결 지침이 포함된 계층형 지원 조직의 예를 보여줍니다.
| 지원 계층 | 책임 | 목표 |
|---|---|---|
| Tier 1 지원 | 상시 지원 헬프데스크 지원 전화 응답, 문제 티켓 발신, 문제 해결, 최대 15분, 티켓 문서화, 적절한 Tier 2 지원 | 수신 통화의 40% 해결 |
| Tier 2 지원 | 대기열 모니터링, 네트워크 관리, 스테이션 모니터링 소프트웨어 식별된 문제에 대한 문제 해결 구현 구현 계층 1, 공급업체 및 계층 3 escalation에서 전화 받기 문제 해결 시까지 통화 소유권 가정 | Tier 2 레벨에서 100% 통화 해결 |
| Tier 3 지원 | 모든 우선 순위 1 문제에 대해 계층 2에 즉각적인 지원을 제공해야 함 SLA 해결 기간 내에 계층 2에 의해 해결되지 않은 모든 문제를 해결하는 데 동의함 | 직접적인 문제 소유권 없음 |
다음 단계는 서비스 응답 및 서비스 해결 서비스 정의에 대한 매트릭스를 생성하는 것입니다.하드웨어 교체를 포함한 문제 해결 속도를 위한 목표를 설정합니다.서비스 응답 시간 및 복구 시간이 네트워크 가용성에 직접적인 영향을 미치기 때문에 이 영역에서 목표를 설정하는 것이 중요합니다.문제 해결 시간도 가용성 예산에 맞게 조정해야 합니다.가용성 예산에서 많은 수의 심각성 문제가 고려되지 않을 경우, 조직은 이러한 문제의 근원과 잠재적 해결책을 이해하기 위해 작업할 수 있습니다.다음 표를 참조하십시오.
| 문제 심각도 | 헬프 데스크 응답 | Tier 2 응답 | 현장 계층 2 | 하드웨어 교체 | 문제 해결 |
|---|---|---|---|---|---|
| 1 | Tier 2, Network Operations Manager로 즉시 에스컬레이션 | 5분 | 2시간 | 2시간 | 4시간 |
| 2 | Tier 2, Network Operations Manager로 즉시 에스컬레이션 | 5분 | 4시간 | 4시간 | 8시간 |
| 3 | 15분 | 2시간 | 12시간 | 24시간 | 36시간 |
| 4 | 15분 | 4시간 | 3일 | 3일 | 6일 |
서비스 응답 및 서비스 해결 외에도 에스컬레이션을 위한 매트릭스를 구축합니다.에스컬레이션 매트릭스는 사용 가능한 리소스가 서비스에 심각한 영향을 미치는 문제에 집중하도록 합니다.일반적으로, 분석가들이 문제를 해결하는 데 초점을 맞출 때, 그 문제에 추가 리소스를 가져오는 데 거의 집중하지 않습니다.추가 리소스를 공지해야 하는 시기를 정의하면 관리 문제에 대한 인지도를 높일 수 있으며 일반적으로 향후 사전 대응적 또는 사전 예방적인 조치를 취하는 데 도움이 됩니다.다음 표를 참조하십시오.
| 경과 시간 | 심각도 1 | 심각도 2 | 심각도 3 | 심각도 4 |
|---|---|---|---|---|
| 5분 | 네트워크 운영 관리자, Tier 3 지원, 네트워킹 책임자 | |||
| 1시간 | 네트워크 운영 관리자, Tier 3 지원, 네트워킹 담당 디렉터로 업데이트 | 네트워크 운영 관리자, Tier 3 지원, 네트워킹 담당 디렉터로 업데이트 | ||
| 2시간 | VP로 에스컬레이션, 이사, 운영 관리자로 업데이트 | |||
| 4시간 | VP, 이사, 운영 관리자, Tier 3 지원에 대한 근본 원인 분석, 해결되지 않은 경우 CEO 알림 필요 | VP로 에스컬레이션, 이사, 운영 관리자로 업데이트 | ||
| 24시간 | 네트워크 운영 관리자 | |||
| 5일 | 네트워크 운영 관리자 |
지금까지 서비스 수준 정의는 운영 지원 조직이 문제를 파악한 후 어떻게 대응하는지에 중점을 두었습니다.운영 조직은 지난 수년간 위와 유사한 정보를 보유한 운영 지원 계획을 수립했습니다.그러나 이러한 경우 누락된 것은 조직이 문제를 어떻게 파악하고 어떤 문제를 식별할지 입니다.더 정교한 네트워크 조직은 사용자 문제 보고서 또는 불만 사항으로 인해 다시 식별된 문제와는 달리 사전 대응적으로 식별되는 문제의 백분율에 대한 목표만 만들어 이 문제를 해결하려고 했습니다.
다음 표에서는 조직에서 사전 대응적 지원 기능과 사전 대응적 지원을 전반적으로 어떻게 측정하고자 하는지 보여줍니다.
| 네트워크 영역 | 사전 문제 식별 비율 | 사후 대응 문제 식별 비율 |
|---|---|---|
| LAN | 80 % | 20 % |
| WAN | 80 % | 20 % |
사전 대응형 툴이 문제 표를 자동으로 생성하는 경우, 특히 간편하고 쉽게 측정할 수 있으므로 사전 대응적 지원 정의를 정의하는 것이 좋습니다.이를 통해 근본 원인을 해결하는 대신 능동적으로 문제를 해결하는 데 네트워크 관리 툴/정보를 집중할 수 있습니다.그러나 이 방법의 주요 문제는 사전 지원 요구 사항을 정의하지 않는다는 것입니다.이를 통해 일반적으로 사전 대응적 지원 관리 기능에 허점이 생기고 가용성 위험이 증가합니다.
사전 대응적 서비스 수준 정의
서비스 레벨 정의를 생성하는 보다 포괄적인 방법론에는 네트워크 모니터링 방법 및 운영 조직이 정의된 NMS(Network Management Station) 임계값에 대해 7 x 24를 기준으로 어떻게 반응하는지 자세히 설명되어 있습니다.MIB(Management Information Base) 변수의 수 및 네트워크 상태와 관련된 사용 가능한 네트워크 관리 정보의 양 때문에 불가능한 작업으로 보일 수 있습니다.또한 매우 비싸고 리소스가 많이 사용될 수 있습니다.안타깝게도 이러한 반대 의견은 많은 사람들이 사전 대응적 서비스 정의를 구현하지 못하도록 합니다. 이는 기본적으로 간단하고, 이해하기 쉬우며, 네트워크에서 가장 높은 가용성 또는 성능 위험에만 적용되어야 한다는 것입니다.그러면 조직에서 기본적인 사전 대응적 서비스 정의에서 가치가 확인될 경우 단계별 접근 방식을 구현하는 한 시간이 지남에 따라 큰 영향 없이 더 많은 변수를 추가할 수 있습니다.
모든 운영 지원 계획에 사전 대응적 서비스 정의의 첫 번째 영역을 포함합니다.서비스 정의에서는 운영 그룹이 네트워크의 여러 영역에서 네트워크를 사전 대응적으로 식별하고 대응하거나 다운된 조건을 연결하는 방법을 간단히 설명합니다.이러한 정의(또는 관리 지원)가 없다면 조직은 다양한 지원, 비현실적인 사용자 기대치를 기대할 수 있으며 궁극적으로 네트워크 가용성을 낮출 수 있습니다.
다음 표는 조직이 링크/디바이스 다운 조건에 대한 서비스 정의를 생성하는 방법을 보여줍니다.이 예에서는 네트워크의 시간 및 영역에 따라 다른 알림 및 응답 요구 사항을 가질 수 있는 기업 조직을 보여줍니다.
| 네트워크 디바이스 또는 링크 다운 | 탐지 방법 | 5 x 8 알림 | 7 x 24 알림 | 5 x 8 해상도 | 7 x 24 해상도 |
|---|---|---|---|---|---|
| 코어 LAN | SNMP 디바이스 및 링크 폴링, 트랩 | NOC는 문제 티켓, 페이지 LAN-duty 호출기 생성 | 자동 페이지 LAN 관세 호출기, LAN 담당 직원이 코어 LAN 대기열에 대한 문제 티켓 생성 | NOC에 의해 15분 내에 할당된 LAN 분석가, 서비스 응답 정의에 따라 수리 | 우선 순위 1 및 2 즉각적인 조사 및 해결 우선 순위 3 및 4 오전 문제 해결 대기열 |
| 국내 WAN | SNMP 디바이스 및 링크 폴링, 트랩 | NOC는 문제 티켓, WAN 관세 호출기 페이지 생성 | 자동 페이지 WAN 듀티 페이저, WAN 담당 직원이 WAN 대기열에 대한 문제 티켓 생성 | NOC에 의해 15분 내에 할당된 WAN 분석가, 서비스 응답 정의에 따라 수리 | 우선 순위 1 및 2 즉각적인 조사 및 해결 우선 순위 3 및 4 오전 문제 해결 대기열 |
| 엑스트라넷 | SNMP 디바이스 및 링크 폴링, 트랩 | NOC는 문제 티켓, 페이지 파트너 직무 호출기 | 파트너 직무 호출기 자동 페이지, 파트너 직무 담당자가 파트너 대기열에 대한 문제 티켓 생성 | NOC에 의해 15분 내에 할당된 파트너 분석가, 서비스 응답 정의에 따라 수리 | 우선 순위 1 및 2 즉각적인 조사 및 해결오전 해결을 위한 우선순위 3 및 4 대기열 |
나머지 사전 대응적 서비스 수준 정의는 다음 두 가지 범주로 나눌 수 있습니다.네트워크 오류 및 용량/성능 문제.이러한 영역에는 서비스 수준 정의가 있는 네트워크 조직의 비율이 극히 적습니다.그 결과, 이러한 문제는 무시되거나 산발적으로 처리됩니다.일부 네트워크 환경에서는 이 문제가 해결되지만 고가용성 환경에서는 일반적으로 일관성 있는 사전 예방적 서비스 관리가 필요합니다.
네트워킹 조직은 여러 가지 이유로 사전 대응적인 서비스 정의를 따르기 어렵습니다.가용성 위험, 가용성 예산, 애플리케이션 문제를 기준으로 사전 대응적 서비스 정의에 대한 요구 사항 분석을 수행하지 않았기 때문입니다.이로 인해 사전 대응적 서비스 정의에 대한 요건이 불분명하고 혜택은 명확하지 않습니다. 특히 추가 리소스가 필요할 수 있습니다.
두 번째 이유는 기존 또는 새로 정의된 리소스와 함께 수행할 수 있는 사전 대응적 관리의 양을 조정하는 것입니다.가용성 또는 성능에 심각한 영향을 미칠 수 있는 경고만 생성합니다.또한 이벤트 상관관계 관리 또는 프로세스를 고려하여 동일한 문제에 대해 여러 사전 예방적 문제 티켓이 생성되지 않도록 해야 합니다.기업이 어려움을 겪을 수 있는 마지막 이유는 새로운 사전 대응적 알림 세트를 생성하면 이전에 탐지되지 않았던 메시지가 초기에 넘쳐나는 경우가 많기 때문입니다.운영 그룹은 이러한 이전에 탐지되지 않은 상태를 수정하거나 해결하기 위해 이 초기 문제 및 추가 단기 리소스에 대비해야 합니다.
사전 대응적 서비스 수준 정의의 첫 번째 범주는 네트워크 오류입니다.네트워크 오류는 소프트웨어 오류 또는 하드웨어 오류, 프로토콜 오류, 미디어 제어 오류, 정확도 오류, 환경 경고 등의 시스템 오류로 세분화할 수 있습니다.서비스 수준 정의 개발에서는 이러한 문제 조건이 어떻게 탐지될 것인지, 누가 그러한 문제를 볼 것인지, 그리고 이러한 문제가 발생할 때 어떤 일이 발생할 것인지를 일반적으로 이해하는 것으로 시작합니다.필요한 경우 서비스 수준 정의에 특정 메시지 또는 문제를 추가합니다.성공을 위해 다음 영역에서 추가 작업이 필요할 수도 있습니다.
-
Tier 1, Tier 2 및 Tier 3 지원 책임
-
네트워크 관리 정보의 우선 순위를 운영 그룹이 효과적으로 처리할 수 있는 사전 대응적 작업의 양과 균형 유지
-
지원 인력이 정의된 경고를 효과적으로 처리할 수 있도록 하는 교육 요구 사항
-
동일한 근본 원인 문제에 대해 여러 문제 티켓이 생성되지 않도록 하는 이벤트 상관관계 방법론
-
Tier 1 지원 수준에서 이벤트 식별에 도움이 되는 특정 메시지 또는 경고에 대한 설명서
다음 표는 네트워크 오류에 대한 서비스 수준 정의의 예를 보여줍니다. 이를 통해 사전 대응적 네트워크 오류 알림의 책임 주체, 문제 식별 방법, 문제 발생 시 발생할 상황을 명확하게 파악할 수 있습니다.조직은 성공을 보장하기 위해 위에서 정의한 추가적인 노력이 필요할 수 있습니다.
s.
| 오류 범주 | 탐지 방법 | 임계값 | 수행한 작업 |
|---|---|---|---|
| 소프트웨어 오류(소프트웨어에 의해 강제로 충돌) | syslog 뷰어를 사용하여 syslog 메시지를 매일 검토 계층 2 지원에 의해 완료 | 레벨 3 이상의 100번 이상 우선순위 0, 1, 2에 대한 모든 발생 | 문제를 검토하고, 문제 티켓을 만들고, 새로운 발생 또는 문제가 주의를 요하는 경우 디스패치합니다. |
| 하드웨어 오류(하드웨어에서 강제로 충돌) | syslog 뷰어를 사용하여 syslog 메시지를 매일 검토 계층 2 지원에 의해 완료 | 레벨 3 이상의 100번 이상 우선순위 0, 1, 2에 대한 모든 발생 | 문제를 검토하고, 문제 티켓을 만들고, 새로운 발생 또는 문제가 주의를 요하는 경우 디스패치합니다. |
| 프로토콜 오류(IP 라우팅 프로토콜만 해당) | syslog 뷰어를 사용하여 syslog 메시지를 매일 검토 계층 2 지원에 의해 완료 | 1일 10건의 메시지(우선 순위 0, 1, 2회 이상 레벨 3 이상 100회 이상) | 문제를 검토하고, 문제 티켓을 만들고, 새로운 발생 또는 문제가 주의를 요하는 경우 디스패치합니다. |
| 미디어 제어 오류(FDDI, POS 및 고속 이더넷 전용) | syslog 뷰어를 사용하여 syslog 메시지를 매일 검토 계층 2 지원에 의해 완료 | 1일 10건의 메시지(우선 순위 0, 1, 2회 이상 레벨 3 이상 100회 이상) | 문제를 검토하고, 문제 티켓을 만들고, 새로운 발생 또는 문제가 주의를 요하는 경우 디스패치합니다. |
| 환경 메시지(전원 및 온도) | syslog 뷰어를 사용하여 syslog 메시지를 매일 검토 계층 2 지원에 의해 완료 | 모든 메시지 | 문제 티켓 생성 및 새로운 문제 디스패치 |
| 정확도 오류(링크 입력 오류) | 5분 간격으로 SNMP 폴링 NOC에서 받은 임계값 이벤트 | 입력 또는 출력 오류 모든 링크에서 5분 간격으로 1개의 오류 발생 | 새로운 문제에 대한 문제 티켓 생성 및 Tier 2 지원에 발송 |
사전 대응적 서비스 수준 정의의 다른 범주는 성능 및 용량에 적용됩니다.진정한 성능 및 용량 관리에는 예외 관리, 기본 설정 및 추세 분석, what-if 분석 등이 포함됩니다.서비스 수준 정의는 조사 또는 업그레이드를 시작할 성능 및 용량 예외 임계값 및 평균 임계값을 정의하기만 합니다.그런 다음 이러한 임계값은 세 가지 성능 및 용량 관리 프로세스 모두에 어떤 방식으로 적용될 수 있습니다.
용량 및 성능 서비스 수준 정의는 다음과 같은 여러 범주로 나눌 수 있습니다.네트워크 링크, 네트워크 디바이스, 엔드 투 엔드 성능 및 애플리케이션 성능이러한 영역에서 서비스 수준 정의를 개발하려면 장치 용량, 미디어 용량, QoS 특성 및 애플리케이션 요구 사항의 특정 측면에 대한 심층적인 기술 지식이 필요합니다.따라서 네트워크 설계자는 공급업체 입력을 통해 성능 및 용량 관련 서비스 수준 정의를 개발하는 것이 좋습니다.
네트워크 오류와 마찬가지로, 용량 및 성능에 대한 서비스 수준 정의 개발도 이러한 문제 조건이 어떻게 탐지될 것인지, 누가 이러한 문제를 볼 것인지, 발생할 경우 어떤 일이 발생할 것인지를 이해하는 것으로 시작됩니다.필요한 경우 서비스 레벨 정의에 특정 이벤트 정의를 추가할 수 있습니다.성공을 위해 다음 영역에서 추가 작업이 필요할 수도 있습니다.
-
애플리케이션 성능 요구 사항에 대한 명확한 이해
-
비즈니스 요구 사항 및 전체 비용을 기준으로 조직에 적합한 임계값에 대한 상세한 기술 조사
-
예산 주기 및 순환 중단 업그레이드 요건
-
Tier 1, Tier 2 및 Tier 3 지원 책임
-
운영 그룹이 효과적으로 처리할 수 있는 사전 대응적 작업의 양과 균형을 이루는 네트워크 관리 정보의 우선 순위 및 중요도
-
지원 직원이 메시지 또는 알림을 이해하고 정의된 조건을 효과적으로 처리할 수 있도록 하는 교육 요구 사항
-
동일한 근본 원인 문제에 대해 여러 문제 티켓이 생성되지 않도록 하는 이벤트 상관관계 방법론 또는 프로세스
-
Tier 1 지원 수준에서 이벤트 식별에 도움이 되는 특정 메시지 또는 경고에 대한 설명서
다음 표는 사전 대응적 네트워크 오류 알림을 담당하는 사람, 문제 식별 방법, 문제 발생 시 발생할 상황을 명확하게 파악할 수 있는 링크 사용률에 대한 서비스 수준 정의 예를 보여줍니다.조직은 성공을 보장하기 위해 위에서 정의한 추가적인 노력이 필요할 수 있습니다.
| 네트워크 영역/미디어 | 탐지 방법 | 임계값 | 수행한 작업 |
|---|---|---|---|
| 캠퍼스 LAN 백본 및 배포 링크 | 코어 및 배포 링크의 RMON 예외 트랩을 5분 간격으로 SNMP 폴링 | 50% 5분 간격으로 예외 트랩을 통한 사용률 90% | QoS 요구 사항을 평가하거나 반복적인 문제에 대한 업그레이드 계획을 수립하기 위해 성능 이메일 별칭 그룹에 대한 이메일 알림 |
| 국내 WAN 링크 | 5분 간격으로 SNMP 폴링 | 5분 간격으로 75% 활용 | QoS 요구 사항을 평가하거나 반복적인 문제에 대한 업그레이드 계획을 수립하기 위해 성능 이메일 별칭 그룹에 대한 이메일 알림 |
| 엑스트라넷 WAN 링크 | 5분 간격으로 SNMP 폴링 | 5분 간격으로 60% 활용 | QoS 요구 사항을 평가하거나 반복적인 문제에 대한 업그레이드 계획을 수립하기 위해 성능 이메일 별칭 그룹에 대한 이메일 알림 |
다음 표에서는 디바이스 용량 및 성능 임계값에 대한 서비스 레벨 정의를 정의합니다.네트워크 문제 또는 가용성 문제를 방지하는 데 유용하고 의미 있는 임계값을 만들어야 합니다.이 영역은 디바이스 컨트롤 플레인 리소스 문제가 심각한 네트워크에 영향을 미칠 수 있으므로 매우 중요한 영역입니다.
| Cisco 7500 | CPU, 메모리, 버퍼 | CPU에 대한 RMON 알림 -5분 간격으로 SNMP 폴링 | 5분 간격으로 CPU 75%, RMON 알림을 통해 99% 5분 간격으로 메모리 50% 사용 버퍼 99% 사용률 | 문제 해결 또는 RMON CPU 업그레이드 계획 99%, 문제 티켓 및 페이지 Tier 2 지원 호출기 구축을 위해 성능 및 용량 e- 메일 별칭 그룹에 대한 e- 메일 알림 |
| Cisco 2600 | CPU, 메모리 | 5분 간격으로 SNMP 폴링 | 5분 간격 동안 75%의 CPU 5분 간격 동안 50%의 메모리 | 문제 해결 또는 업그레이드 계획을 위해 성능 및 용량 e- 메일 별칭 그룹에 대한 e- 메일 알림 |
| Catalyst 5000 | 백플레인 사용률, 메모리 | 5분 간격으로 SNMP 폴링 | 50% 활용도의 백플레인 75% 활용도의 메모리 | 문제 해결 또는 업그레이드 계획을 위해 성능 및 용량 e- 메일 별칭 그룹에 대한 e- 메일 알림 |
| LightStream® 1010 ATM 스위치 | CPU, 메모리 | 5분 간격으로 SNMP 폴링 | 65%의 CPU 사용률 50%의 메모리 | 문제 해결 또는 업그레이드 계획을 위해 성능 및 용량 e- 메일 별칭 그룹에 대한 e- 메일 알림 |
다음 표에서는 엔드 투 엔드 성능 및 용량에 대한 서비스 수준 정의를 정의합니다.이러한 임계값은 일반적으로 애플리케이션 요구 사항을 기반으로 하지만, 일부 유형의 네트워크 성능 또는 용량 문제를 나타내는 데 사용할 수도 있습니다.성능에 대한 서비스 수준 정의를 가지고 있는 대부분의 조직에서는 소수의 성능 정의만 생성합니다. 네트워크의 모든 지점에서 다른 지점까지 성능을 측정하려면 상당한 리소스가 필요하며 높은 네트워크 오버헤드가 발생하기 때문입니다.이러한 엔드 투 엔드 성능 문제는 링크 또는 디바이스 용량 임계값에서도 발생할 수 있습니다.지리적 위치별로 일반적인 정의를 권장합니다.필요한 경우 일부 중요 사이트 또는 링크를 추가할 수 있습니다.
| 네트워크 영역/미디어 | 측정 방법 | 임계값 | 수행한 작업 |
|---|---|---|---|
| 캠퍼스 LAN | 문제 없음 예상 전체 LAN 인프라 측정이 어려움 | 항상 10밀리초 미만의 왕복 응답 시간 | 문제 해결 또는 업그레이드 계획을 위해 성능 및 용량 e- 메일 별칭 그룹에 대한 e- 메일 알림 |
| 국내 WAN 링크 | IPM(Internet Performance Monitor) ICMP 에코를 사용하는 경우에만 SF에서 NY로, SF에서 시카고로 현재 측정 | 5분 동안의 평균 왕복 응답 시간 75밀리초 | QoS 요구 사항을 평가하거나 반복적인 문제에 대한 업그레이드 계획을 수립하기 위해 성능 이메일 별칭 그룹에 대한 이메일 알림 |
| 샌프란시스코-도쿄 | IPM 및 ICMP 에코를 사용하여 San Francisco에서 Brussels까지의 현재 측정 | 5분 동안 평균 250밀리초 왕복 응답 시간 | QoS 요구 사항을 평가하거나 반복적인 문제에 대한 업그레이드 계획을 수립하기 위해 성능 이메일 별칭 그룹에 대한 이메일 알림 |
| 샌프란시스코-브뤼셀 | IPM 및 ICMP 에코를 사용하여 San Francisco에서 Brussels까지의 현재 측정 | 5분 동안의 평균 175밀리초 왕복 응답 시간 | QoS 요구 사항을 평가하거나 반복적인 문제에 대한 업그레이드 계획을 수립하기 위해 성능 이메일 별칭 그룹에 대한 이메일 알림 |
서비스 수준 정의의 마지막 영역은 애플리케이션 성능입니다.애플리케이션 성능 서비스 수준 정의는 일반적으로 애플리케이션 또는 서버 관리 그룹에 의해 생성됩니다. 서버 자체의 성능 및 용량이 애플리케이션 성능의 가장 큰 요인일 가능성이 있기 때문입니다.네트워킹 조직은 다음과 같은 이유로 네트워크 애플리케이션 성능을 위한 서비스 수준 정의를 만들어 엄청난 혜택을 누릴 수 있습니다.
-
서비스 수준 정의 및 측정은 그룹 간의 충돌을 제거하는 데 도움이 됩니다.
-
개별 애플리케이션에 대한 서비스 수준 정의는 QoS가 주요 애플리케이션에 대해 구성되고 다른 트래픽은 선택 사항으로 간주될 경우 중요합니다.
애플리케이션 성능을 생성 및 측정하도록 선택하는 경우 서버 자체에 대한 성능을 측정하지 않는 것이 가장 좋습니다.그러면 네트워크 문제와 애플리케이션 또는 서버 문제를 구별할 수 있습니다.Cisco 라우터 및 Cisco IPM에서 실행되는 프로브 또는 시스템 가용성 에이전트 소프트웨어를 사용하여 패킷 유형 및 측정 빈도를 제어합니다.
다음 표는 애플리케이션 성능에 대한 간단한 서비스 레벨 정의를 보여줍니다.
| 애플리케이션 | 측정 방법 | 임계값 | 수행한 작업 |
|---|---|---|---|
| ERP(Enterprise Resource Planning) 애플리케이션 TCP 포트 1529 Brussels-SF | IPM 측정 포트 1529 왕복 성능 Brussels 게이트웨이가 SFO 게이트웨이 2에 연결되도록 Brussels-San Francisco | 5분 동안의 평균 175밀리초 왕복 응답 시간 | 문제 평가 또는 반복 문제에 대한 업그레이드 계획을 위해 성능 이메일 별칭 그룹에 대한 이메일 알림 |
| ERP 애플리케이션 TCP 포트 1529 Tokyo - SF | IPM 측정 포트 1529 왕복 성능 Brussels 게이트웨이가 SFO 게이트웨이 2에 연결되도록 Brussels-San Francisco | 5분 동안 평균 200밀리초 왕복 응답 시간 | 문제 평가 또는 반복 문제에 대한 업그레이드 계획을 위해 성능 이메일 별칭 그룹에 대한 이메일 알림 |
| 고객 지원 애플리케이션 TCP 포트 1702 시드니 - SF | IPM 측정 포트 1702 왕복 성능을 사용하여 시드니-샌프란시스코 SFO 게이트웨이 1로 시드니 게이트웨이 | 5분 동안 평균 250밀리초 왕복 응답 시간 | 문제 평가 또는 반복 문제에 대한 업그레이드 계획을 위해 성능 이메일 별칭 그룹에 대한 이메일 알림 |
6단계:메트릭 및 모니터 수집
서비스 수준 정의 자체는 조직이 메트릭을 수집하고 성공을 모니터링하지 않는 한 가치가 없습니다.중요한 서비스 레벨 정의를 생성할 때 서비스 레벨을 측정 및 보고하는 방법을 정의합니다.서비스 수준 측정은 조직이 목표를 달성하고 있는지, 가용성 또는 성능 문제의 근본 원인을 파악합니다.서비스 레벨 정의를 측정하는 방법을 선택할 때도 이 목표를 고려하십시오.자세한 내용은 SLA 생성 및 유지 관리를 참조하십시오.
서비스 레벨을 모니터링하려면 보통 매월 정기적인 검토 회의를 열어 정기적인 서비스를 논의합니다.모든 메트릭과 목표 준수 여부에 대해 설명합니다.이러한 문제가 일치하지 않을 경우 문제의 근본 원인을 파악하고 개선을 구현합니다.또한 현재의 이니셔티브와 개별 상황 개선 진행 상황도 다루어야 합니다.
SLA 생성 및 유지 관리
서비스 수준 정의는 조직 전반에 걸쳐 일관된 QoS를 생성하고 가용성을 개선하는 데 도움이 되는 뛰어난 구성 요소입니다.다음 단계는 SLA입니다. SLA는 비즈니스 목표와 비용 요구 사항을 서비스 품질에 직접 맞추므로 개선됩니다.잘 구성된 SLA는 네트워크 문제 또는 문제에 대한 명확한 프로세스와 절차를 유지하여 사용자 커뮤니티와 지원 그룹 간의 효율성, 품질 및 시너지 효과를 위한 모델 역할을 합니다.
SLA는 다음과 같은 몇 가지 이점을 제공합니다.
-
SLA는 서비스에 대한 양방향 책임을 설정합니다. 즉, 사용자와 애플리케이션 그룹도 네트워크 서비스에 대해 책임을 집니다.특정 서비스에 대한 SLA를 생성하고 네트워크 그룹과 비즈니스 영향을 통신하지 않을 경우, 실제로 문제가 발생할 수 있습니다.
-
SLA는 비즈니스 요구 사항을 충족하는 데 필요한 표준 툴과 리소스를 결정하는 데 도움이 됩니다.SLA 없이 사용할 수 있는 툴과 인력을 결정하는 것은 예산 추측에 불과합니다.이 서비스는 과잉 엔지니어링되어 과소비나 미비 엔지니어링이 가능하여 비즈니스 목표를 달성할 수 없습니다.SLA를 조정하면 균형 잡힌 최적의 수준을 달성할 수 있습니다.
-
문서화된 SLA는 서비스 수준 기대치를 설정하기 위한 더 명확한 수단을 생성합니다.
서비스 레벨 정의가 생성된 후 SLA를 구축하기 위해 다음 단계를 권장합니다.서비스 레벨 정의가 생성된 후 SLA를 구축하기 위해 다음 단계를 권장합니다.
12. SLA 형식을 선택합니다.
13. SLA 작업 그룹 개발
14. 워크그룹 회의를 열고 SLA 초안을 작성합니다.
15. SLA를 협상합니다.
7단계:SLA 요건 충족
IT SLA 개발 전문가들은 성공적인 SLA를 위한 3가지 전제 조건을 확인했습니다.그러나 이러한 목표를 충족하지 못하는 조직은 SLA 프로세스에 문제를 예상할 수 있으며 SLA 프로세스와 관련된 잠재적 문제를 고려해야 합니다.네트워킹 조직이 일반적인 비즈니스 요구 사항을 충족하는 서비스 수준 정의를 구축할 수 있다면 SLA를 구현하지 못할 경우 아무런 문제가 없습니다.다음은 SLA 프로세스의 전제 조건입니다.
-
비즈니스에는 서비스 중심 문화가 있어야 합니다.
조직은 고객의 요구를 먼저 고려해야 합니다.서비스에 대한 하향식 우선 순위가 있어야 합니다. 따라서 고객의 요구 사항 및 인식을 완벽하게 파악할 수 있습니다.고객 만족도 조사 및 고객 중심 서비스 이니셔티브를 수행합니다.
또 다른 서비스 지표는 조직이 서비스 또는 지원 만족도를 기업 목표라고 표시한다는 것일 수 있습니다.IT 조직이 이제 조직의 전반적인 성공에 매우 연결되어 있기 때문에 이러한 현상은 흔한 일입니다.
SLA 프로세스는 기본적으로 고객의 요구 사항 및 비즈니스 요구 사항에 따라 개선되어야 하므로 서비스 문화가 중요합니다.과거에는 이러한 작업을 수행하지 않았다면 SLA 프로세스가 어려워질 것입니다.
-
고객/비즈니스 이니셔티브는 모든 IT 활동을 주도해야 합니다.
회사의 비전 또는 사명은 고객 및 비즈니스 이니셔티브와 연계되어야 하며, 이를 통해 SLA를 포함한 모든 IT 활동을 주도해야 합니다.특정 목표를 달성하기 위해 네트워크를 구축하는 경우가 너무 많으나 네트워킹 그룹은 그 목표와 후속 비즈니스 요구 사항을 파악하지 못합니다.이러한 경우 설정된 예산이 네트워크에 할당되므로 현재의 요구 사항에 과민 대응하거나 요구 사항을 크게 과소평가하여 오류가 발생할 수 있습니다.
고객/비즈니스 이니셔티브가 IT 활동과 연계될 경우, 네트워킹 조직은 새로운 애플리케이션 배포, 새로운 서비스 또는 기타 비즈니스 요구 사항을 보다 쉽게 조정할 수 있습니다.기업 목표 달성에 대한 관계 및 일반적인 전반적인 초점은 현재 진행되며 모든 그룹이 한 팀으로 실행됩니다.
-
SLA 프로세스 및 계약에 커밋해야 합니다.
먼저 효과적인 계약을 개발하기 위한 SLA 프로세스를 익히기 위한 노력이 필요합니다.둘째, 계약의 서비스 요구 사항을 준수해야 합니다.관련된 모든 사람의 중요한 의견과 노력 없이 강력한 SLA를 생성할 것으로 기대하지 마십시오.이러한 노력은 관리 및 SLA 프로세스와 관련된 모든 개인으로부터 제공되어야 합니다.
8단계:SLA 관련 당사자 결정
엔터프라이즈 수준의 네트워크 SLA는 네트워크 요소, 서버 관리 요소, 헬프 데스크 지원, 애플리케이션 요소, 비즈니스 또는 사용자 요구 사항에 크게 좌우됩니다.일반적으로 각 영역의 관리는 SLA 프로세스에 포함됩니다.이 시나리오는 조직에서 기본 사후 대응적 지원 SLA를 구축하는 경우에 적합합니다.고가용성 요구 사항이 높은 기업 조직에서는 가용성 예산 책정, 성능 제한, 애플리케이션 프로파일링 또는 사전 대응적 관리 기능과 같은 문제를 해결하기 위해 SLA 프로세스 동안 기술 지원이 필요할 수 있습니다.사전 대응적인 관리 SLA 측면을 위해 네트워크 설계자 및 애플리케이션 설계자로 구성된 기술 팀을 권장합니다.기술 지원은 네트워크의 가용성 및 성능 기능과 특정 목표에 도달하기 위해 무엇이 필요한지에 대해 훨씬 더 근접하게 접근할 수 있습니다.
통신 사업자 SLA에는 일반적으로 사용자 입력이 포함되지 않습니다. 다른 통신 사업자에게 경쟁 우위를 점하기 위한 목적으로만 생성되기 때문입니다.경우에 따라 상위 관리는 서비스를 홍보하고 내부 직원에게 내부 목표를 제공하기 위해 고가용성 또는 고성능 레벨에서 이러한 SLA를 생성합니다.다른 통신 사업자는 내부적으로 측정하고 관리하는 강력한 서비스 수준 정의를 만들어 가용성을 향상하는 기술적 측면에 주력합니다.다른 경우에는 두 작업이 동시에 수행되지만 반드시 함께 또는 같은 목표를 가지고 있지는 않습니다.
그런 다음 SLA에 관련된 당사자를 선택하는 것은 SLA의 목표를 기반으로 해야 합니다.몇 가지 가능한 목표는 다음과 같습니다.
-
사후 대응적 지원 비즈니스 목표 달성
-
사전 대응적 SLA를 정의하여 최고 수준의 가용성 제공
-
서비스 홍보 또는 판매
9단계:서비스 요소 결정
1차 서비스/지원 SLA에는 일반적으로 지원 수준, 평가 방법, SLA 조정을 위한 에스컬레이션 경로, 전반적인 예산 문제 등 많은 구성 요소가 포함됩니다.고가용성 환경을 위한 서비스 요소에는 사전 대응적 서비스 정의와 사후 대응적 목표가 포함되어야 합니다.자세한 내용은 다음과 같습니다.
-
현장 지원 업무 시간 및 비근무 지원 절차
-
문제 유형, 문제 해결 시작 최대 시간, 문제 해결 최대 시간, 에스컬레이션 절차 등 우선 순위 정의
-
지원 대상 제품 또는 서비스, 비즈니스 중요도에 따라 순위 지정
-
전문성 기대, 성능 수준 기대, 상태 보고, 문제 해결을 위한 사용자 책임 지원
-
지역 또는 사업부 지원 수준의 문제 및 요구 사항
-
문제 관리 방법론 및 절차(통화 추적 시스템)
-
헬프 데스크 목표
-
네트워크 오류 감지 및 서비스 응답
-
네트워크 가용성 측정 및 보고
-
네트워크 용량, 성능 측정 및 보고
-
충돌 해결 절차
-
구현된 SLA 자금 지원
네트워크 애플리케이션 또는 서비스 SLA는 사용자 그룹 요구 사항 및 비즈니스 중요도에 따라 추가적인 요구 사항을 가질 수 있습니다.네트워크 조직은 이러한 비즈니스 요구 사항을 잘 듣고 전반적인 지원 구조에 맞는 전문 솔루션을 개발해야 합니다.일부 개인 또는 그룹만을 위한 프리미어 서비스를 생성하지 않는 것이 중요하므로 전반적인 지원 문화에 맞추는 것이 중요합니다.대부분의 경우 이러한 추가 요구 사항을 "솔루션" 범주에 넣을 수 있습니다.예를 들면 비즈니스 요구 사항을 기반으로 하는 플래티넘, 골드 및 실버 솔루션이 될 수 있습니다.특정 비즈니스 요구 사항에 대한 SLA 요구 사항의 다음 예를 참조하십시오.
참고: 지원 구조, 에스컬레이션 경로, 헬프 데스크 절차, 측정 및 우선순위 정의는 일관된 서비스 문화를 유지하고 개선하기 위해 대체로 동일하게 유지해야 합니다.
-
버스트를 위한 대역폭 요구 사항 및 기능
-
성능 요구 사항
-
QoS 요구 사항 및 정의
-
솔루션 매트릭스 구축을 위한 가용성 요구 사항 및 이중화
-
모니터링 및 보고 요구 사항, 방법론 및 절차
-
애플리케이션/서비스 요소의 업그레이드 기준
-
예산 부족 요구 사항 또는 교차 청구 방법론 자금 조달
예를 들어, WAN 사이트 연결에 대한 솔루션 범주를 생성할 수 있습니다.Platinum 솔루션에는 T1 서비스가 두 개 제공됩니다.다른 통신업체가 각 T1 라인을 제공합니다.사이트에 두 개의 라우터가 구성되어 있어 T1 또는 라우터에 장애가 발생해도 사이트가 중단되지 않습니다.Gold 서비스에는 두 개의 라우터가 있지만 백업 프레임 릴레이가 사용됩니다.이 솔루션은 중단 기간 동안 대역폭이 제한적일 수 있습니다.Silver 솔루션에는 라우터 1개와 캐리어 서비스 1개만 있습니다.이러한 솔루션은 문제 티켓의 우선 순위 수준에 따라 고려됩니다.운영 중단에 우선 순위 1 또는 2 티켓이 필요한 경우, 일부 조직은 플래티넘 또는 골드 솔루션을 필요로 할 수 있습니다.그런 다음 고객 조직은 필요한 서비스 수준에 자금을 공급할 수 있습니다.다음 표는 익스트라넷 연결에 대한 비즈니스 요구 사항에 따라 세 가지 서비스 수준을 제공하는 조직의 예를 보여줍니다.
| 솔루션 | 플래티넘 | 골드 | 실버 |
|---|---|---|---|
| 장치 | WAN 연결을 위한 이중화 라우터 | 코어 사이트에서 백업을 위한 이중화 라우터 | 디바이스 이중화 없음 |
| WAN | 이중화 T1 연결, 여러 캐리어 | 프레임 릴레이 백업을 통한 T1 연결 | WAN 이중화 없음 |
| 대역폭 요구 사항 및 버스트 | 버스트를 위한 로드 공유가 있는 이중화 T1 | 로드 비공유, 중요한 애플리케이션에만 프레임 릴레이 백업,프레임 릴레이 64K CIR만 해당 | 최대 T1 |
| 성능 | 100ms의 일관된 왕복 응답 시간 | 응답 시간 100ms 이하 예상 99.9% | 응답 시간 100ms 이하 예상 99% |
| 가용성 요구 사항 | 99.99% | 99.95% | 99.9% |
| 작동 중지 시 헬프 데스크 우선 순위 | 우선 순위 1:비즈니스 크리티컬 서비스 중단 | 우선 순위 2:비즈니스에 영향을 미치는 서비스 중단 | 우선 순위 3:비즈니스 연결 중단 |
10단계:고객 비즈니스 요구 사항 및 목표 이해
이 단계는 SLA 개발자에게 많은 신뢰를 가져다 줍니다.다양한 비즈니스 그룹의 요구 사항을 이해함으로써 초기 SLA 문서는 비즈니스 요구 사항 및 원하는 결과에 훨씬 더 가까워집니다.고객 서비스의 다운타임 비용을 파악하십시오.생산성 손실, 수익 및 고객 영업권 손실과 관련하여 추정한 결과소수의 사람들과의 단순한 연결도 수익에 심각한 영향을 미칠 수 있다는 점을 명심하십시오.이 경우 고객이 발생 가능한 가용성과 성능 위험을 이해하도록 하여 조직이 필요한 서비스 수준을 더 잘 이해할 수 있도록 해야 합니다.이 단계를 놓친다면 많은 고객이 단순히 100% 가용성을 요구하게 될 수도 있습니다.
또한 SLA 개발자는 네트워크 업그레이드, 워크로드 및 예산 책정을 수용하기 위해 조직의 비즈니스 목표와 성장을 이해해야 합니다.사용할 애플리케이션을 이해하는 것도 도움이 됩니다.조직에서는 각 애플리케이션에 대한 애플리케이션 프로필을 보유하고 있지만 그렇지 않은 경우 애플리케이션에 대한 기술 평가를 수행하여 네트워크 관련 문제를 확인하는 것이 좋습니다.
11단계:각 그룹에 필요한 SLA 정의
주요 지원 SLA에는 중요한 비즈니스 유닛 및 기능적 그룹 표현(예: 네트워킹 운영, 서버 운영, 애플리케이션 지원 그룹)이 포함되어야 합니다.이러한 그룹은 비즈니스 요구 사항 및 지원 프로세스의 해당 부분에 따라 인식되어야 합니다.또한 여러 그룹에서 대표성을 확보함으로써 개별 그룹 기본 설정 또는 우선 순위 없이 공정한 전체 지원 솔루션을 만드는 데 도움이 됩니다.따라서 지원 조직은 개별 그룹에 프리미엄 서비스를 제공할 수 있으며, 이는 조직의 전반적인 서비스 문화를 저해할 수 있는 시나리오입니다.예를 들어, 고객은 실제로 해당 애플리케이션의 다운타임 비용이 수익 손실, 생산성 손실, 고객 영업권 상실 등의 측면에서 다른 애플리케이션보다 훨씬 적은 경우 자신의 애플리케이션이 기업 내에서 가장 중요하다고 주장할 수 있습니다.
조직 내 비즈니스 유닛마다 요구 사항이 다릅니다.네트워크 SLA의 목표 중 하나는 각기 다른 서비스 레벨을 수용할 수 있는 하나의 전체 형식에 대한 합의입니다.이러한 요구 사항은 일반적으로 가용성, QoS, 성능 및 MTTR입니다.네트워크 SLA에서 이러한 변수는 잠재적인 QoS 튜닝에 비즈니스 애플리케이션의 우선 순위를 지정하고, 네트워크에 영향을 미치는 여러 문제의 MTTR에 대한 헬프 데스크 우선 순위를 정의하고, 다양한 가용성 및 성능 요구 사항을 처리하는 데 도움이 되는 솔루션 매트릭스를 개발하여 처리됩니다.엔터프라이즈 제조 회사의 간단한 솔루션 매트릭스의 예는 다음 표와 같습니다.가용성, QoS 및 성능에 대한 정보를 추가할 수 있습니다.
| 사업부 | 애플리케이션 | 다운타임 비용 | 중단 시 문제 우선 순위 | 서버/네트워크 요구 사항 |
|---|---|---|---|---|
| 제조 | ERP | 높음 | 1 | 최고의 이중화 |
| 고객 지원 | 고객 관리 | 높음 | 1 | 최고의 이중화 |
| 엔지니어링 | 파일 서버, ASIC 설계 | 중간 | 2 | LAN 코어 이중화 |
| 마케팅 | 파일 서버 | 중간 | 2 | LAN 코어 이중화 |
12단계:SLA 형식 선택
SLA의 형식은 그룹 요구 사항 또는 조직 요구 사항에 따라 달라질 수 있습니다.다음은 네트워크 SLA에 대한 권장 개요의 예입니다.
-
계약의 목적
-
합의에 참여하는 당사자
-
계약의 목표 및 목표
-
-
제공되는 서비스 및 지원되는 제품
-
헬프데스크 서비스 및 통화 추적
-
MTTR 정의에 대한 비즈니스 영향을 기준으로 문제 심각도 정의
-
QoS 정의를 위한 비즈니스 크리티컬 서비스 우선순위
-
가용성 및 성능 요구 사항에 따라 정의된 솔루션 범주
-
교육 요건
-
용량 계획 요건
-
에스컬레이션 요건
-
보고
-
네트워크 솔루션 제공
-
새 솔루션 요청
-
지원되지 않는 제품 또는 애플리케이션
-
-
비즈니스 정책
-
업무 시간 중 지원
-
After-hour 지원 정의
-
휴일 지원 범위
-
연락처 전화 번호
-
워크로드 예측
-
고충처리
-
서비스 자격 기준
-
사용자 및 그룹 보안 책임
-
-
문제 관리 절차
-
통화 시작(사용자 및 자동)
-
1단계 응답 및 통화 수리 비율
-
통화 추적 및 기록 유지
-
발신자의 책임
-
문제 진단 및 통화 종료 요건
-
네트워크 관리 문제 감지 및 서비스 응답
-
문제 해결 범주 또는 정의
-
고질적인 문제 처리
-
심각한 문제/예외 통화 처리
-
-
서비스 품질 목표
-
품질 정의
-
측정 정의
-
품질 목표
-
문제 우선 순위별로 문제 해결을 시작하는 평균 시간
-
문제 우선 순위별로 문제를 해결하는 평균 시간
-
문제 우선 순위별로 하드웨어를 교체하는 평균 시간
-
네트워크 가용성 및 성능
-
용량 관리
-
성장 관리
-
품질 보고
-
-
인력 및 예산
-
스태핑 모델
-
운영 예산
-
-
계약 유지 관리
-
적합성 검토 일정
-
성능 보고 및 검토
-
보고서 메트릭 조정
-
정기 SLA 업데이트
-
-
승인
-
첨부 파일 및 표시
-
통화 흐름 다이어그램
-
에스컬레이션 매트릭스
-
네트워크 솔루션 매트릭스
-
보고서 예
-
13단계:SLA 작업 그룹 개발
다음 단계는 그룹 리더를 포함하여 SLA 작업 그룹의 참여자를 식별하는 것입니다.워크그룹은 사업부나 기능별 그룹의 사용자 또는 관리자 또는 지리적 위치의 담당자를 포함할 수 있습니다.이러한 개인은 각 작업 그룹에 SLA 문제를 전달합니다.주요 SLA 요소에 동의할 수 있는 관리자 및 의사 결정자가 참여해야 합니다.이러한 개인에는 SLA와 관련된 기술 문제를 정의하고 IT 수준의 결정을 내리는 데 도움이 되는 관리 및 기술 담당자(예: 헬프 데스크 관리자, 서버 운영 관리자, 애플리케이션 관리자, 네트워크 운영 관리자)가 포함될 수 있습니다.
네트워크 SLA 워크그룹은 다양한 애플리케이션과 서비스를 포함하는 하나의 네트워크 SLA에 대한 동의를 얻기 위해 광범위한 애플리케이션 및 비즈니스 표현으로 구성되어야 합니다.워크그룹은 네트워크에 대한 비즈니스 크리티컬 프로세스와 서비스, 개별 서비스의 가용성 및 성능 요구 사항을 평가할 수 있는 권한이 있어야 합니다.이 정보는 비즈니스에 영향을 미치는 다양한 문제 유형에 대한 우선 순위를 만들고, 네트워크에서 비즈니스 크리티컬 트래픽의 우선 순위를 지정하며, 비즈니스 요구 사항에 따라 미래의 표준 네트워킹 솔루션을 만드는 데 사용됩니다.
14단계:워크그룹 미팅 개최 및 SLA 초안 작성
작업 그룹은 먼저 작업 그룹 헌장을 만들어야 합니다.이 헌장은 SLA에 대한 목표, 이니셔티브 및 기간을 명시해야 합니다.그런 다음, 그룹은 특정 작업 계획을 개발하여 SLA를 개발 및 구현하기 위한 일정과 일정을 결정해야 합니다.또한 지원 기준과 비교하여 지원 수준을 측정하는 보고 프로세스를 개발해야 합니다.마지막 단계에서는 초안 SLA 계약을 생성합니다.
네트워킹 SLA 워크그룹은 SLA를 개발하기 위해 처음에는 일주일에 한 번 충족되어야 합니다.SLA가 생성되고 승인되면 그룹은 SLA 업데이트에 대해 매월 또는 분기별로 충족될 수 있습니다.
15단계:SLA 협상
SLA를 생성하는 마지막 단계는 최종 협상 및 로그오프입니다.이 단계는 다음과 같습니다.
-
초안 검토
-
내용 협상
-
문서 편집 및 개정
-
최종 승인 받기
초안 검토, 내용 협상 및 수정 작업 주기를 통해 최종 버전이 승인을 위해 관리에게 전송되기 전에 여러 주기가 소요될 수 있습니다.
네트워크 관리자의 관점에서 측정 가능한 결과를 협상하는 것이 중요합니다.다른 관련 조직의 성능 및 가용성 계약을 백업하십시오.여기에는 품질 정의, 측정 정의 및 품질 목표가 포함될 수 있습니다.추가된 서비스는 추가 비용과 동일합니다.사용자 그룹은 추가 서비스 수준의 비용이 더 많이 드는 것을 이해하고, 중요한 비즈니스 요구 사항인 경우 결정을 내릴 수 있도록 해야 합니다.하드웨어 교체 시간 등 SLA의 여러 측면에 대한 비용 분석을 쉽게 수행할 수 있습니다.
16단계:SLA 적합성 측정 및 모니터링
SLA 준수 및 보고 결과 측정은 장기적인 일관성 및 결과를 보장하는 데 도움이 되는 SLA 프로세스의 중요한 부분입니다.일반적으로 SLA의 주요 구성 요소는 측정 가능하며 측정 방법론을 SLA 구현 전에 적용하는 것이 좋습니다.그런 다음 사용자와 지원 그룹 간의 월별 회의를 개최하여 측정 결과를 검토하고, 문제의 근본 원인을 파악하고, 서비스 수준 요구 사항을 충족하거나 초과하는 솔루션을 제안합니다.이를 통해 SLA 프로세스가 모든 최신 품질 개선 프로그램과 유사하게 됩니다.
다음 섹션에서는 조직 내 관리가 SLA와 전반적인 서비스 수준 관리를 평가할 수 있는 방법에 대해 자세히 설명합니다.
서비스 수준 관리 성과 지표
서비스 수준 관리 성과 표시기는 서비스 수준을 성공 측정 수단으로 모니터링하고 개선하는 메커니즘을 제공합니다.이를 통해 조직은 서비스 문제에 더 신속하게 대응하고 서비스 또는 다운타임 비용에 영향을 주는 문제를 더 쉽게 이해할 수 있습니다.또한 서비스 수준 정의를 측정하지 않으면 조직이 사후 대응적 자세를 취할 수밖에 없으므로 긍정적인 사전 대응적 작업이 수행되지 않습니다.아무도 이 서비스가 잘 작동한다고 말할 수 없지만, 많은 사용자들이 이 서비스가 자신들의 요구 사항을 충족하지 못한다고 말할 것이다.
따라서 서비스 수준 관리 성과 지표는 기존 서비스 수준을 완전히 이해하고 현재 문제를 기준으로 조정할 수 있는 수단을 제공하므로 서비스 수준 관리를 위한 기본 요건입니다.이는 사전 대응적 지원을 제공하고 품질을 개선하기 위한 토대입니다.조직에서 문제의 근본 원인을 분석하고 품질을 개선하면 가용성, 성능 및 서비스 품질을 향상시킬 수 있는 최상의 방법이 될 수 있습니다.
예를 들어 다음과 같은 실제 시나리오를 가정해 보십시오.X사는 네트워크가 오랫동안 자주 중단되었다는 수많은 사용자 불만을 받고 있었습니다.이 회사는 가용성을 측정함으로써 몇 개의 WAN 사이트가 주요 문제임을 발견했습니다.이러한 목표를 면밀히 조사한 결과 대부분의 문제가 몇 개의 WAN 사이트에 있는 것으로 드러났습니다.근본 원인을 찾았으며 조직에서 문제를 해결했습니다.그런 다음 가용성에 대한 서비스 수준 목표를 설정하고 사용자 그룹과 계약을 체결합니다.향후 측정은 SLA를 준수하지 않아 문제를 신속하게 파악했습니다.그 후 네트워킹 그룹은 더 우수한 전문성, 전문 지식 및 조직의 전반적인 자산을 보유한 것으로 간주되었습니다.이 그룹은 사후 대응에서 사전 대응으로 효과적으로 전환하고 회사의 순익에 기여했습니다.
안타깝게도 오늘날 대부분의 네트워킹 조직은 서비스 수준 정의가 제한적이며 성능 지표가 없습니다.그 결과 대부분의 시간을 능동적으로 근본 원인을 파악하고 비즈니스 요구 사항을 충족하는 네트워크 서비스를 구축하는 대신 사용자 불만 또는 문제에 대응하는 데 사용합니다.
다음 SLA 성능 지표를 사용하여 서비스 수준 관리 프로세스의 성공을 확인합니다.
-
가용성, 성능, 사후 대응적 서비스 응답 시간, 문제 해결 목표, 문제 에스컬레이션 등이 포함된 문서화된 서비스 수준 정의 또는 SLA
-
가용성, 성능, 우선 순위별 서비스 응답 시간, 우선 순위별 해결 시간, 기타 측정 가능한 SLA 매개변수 등 성능 지표 메트릭
-
서비스 수준 규정 준수를 검토하고 개선 사항을 구현하기 위한 월간 네트워킹 서비스 수준 관리 회의
문서화된 서비스 레벨 계약 또는 서비스 레벨 정의
첫 번째 성능 표시기는 SLA 또는 서비스 수준 정의를 자세히 설명하는 문서입니다.서비스 수준 정의의 기본 목표는 가용성과 성능이어야 합니다. 이는 기본 사용자 요구 사항이기 때문입니다.
2차 목표는 가용성 또는 성능 수준을 달성하는 방법을 정의하는 데 도움이 되기 때문에 중요합니다.예를 들어, 조직에서 가용성 및 성능 목표를 적극적으로 설정할 경우 문제가 발생하지 않도록 방지하고 문제가 발생할 때 신속하게 해결해야 합니다.2차 목표는 원하는 가용성과 성능 수준을 달성하는 데 필요한 프로세스를 정의하는 데 도움이 됩니다.
사후 대응적 2차 목표는 다음과 같습니다.
-
통화 우선순위별 사후 대응적 서비스 응답 시간
-
문제 해결 목표 또는 MTTR
-
문제 에스컬레이션 절차
사전 대응적 2차 목표는 다음과 같습니다.
-
디바이스 다운 또는 링크 다운 탐지
-
네트워크 오류 감지
-
용량 또는 성능 문제 감지.
기본 목표, 가용성 및 성능에 대한 서비스 수준 정의에는 다음이 포함되어야 합니다.
목표
-
목표 측정 방법
-
가용성 및 성능 측정 담당자
-
가용성 및 성능 목표를 담당하는 당사자
-
부적합 프로세스
가능한 경우 계측 당사자와 결과에 대한 상대방은 이해상충을 방지하기 위해 다를 것을 권고한다.경우에 따라 추가/이동/변경 오류, 감지되지 않은 오류 또는 가용성 측정 문제로 인해 가용성 번호를 조정해야 할 수도 있습니다.서비스 레벨 정의에는 정확도를 높이고 부적절한 조정을 방지하기 위해 결과를 수정하는 프로세스가 포함될 수도 있습니다.가용성 및 성능을 측정하는 방법은 다음 섹션을 참조하십시오.
사후 대응적 2차 목표에 대한 서비스 수준 정의는 다음을 포함하여 조직이 네트워크 또는 IT 전반의 문제에 대응하는 방법을 정의합니다.
-
문제 우선순위 정의
-
통화 우선순위별 사후 대응적 서비스 응답 시간
-
문제 해결 목표 또는 MTTR
-
문제 에스컬레이션 절차
일반적으로 이러한 목표는 주어진 시간 동안 문제에 대해 책임을 질 사람과 책임 있는 사람이 정의된 문제를 해결하기 위해 현재 작업을 어느 정도 중단해야 하는지를 정의합니다.다른 서비스 레벨 정의와 마찬가지로, 서비스 레벨 문서는 목표 측정 방법, 측정 담당자 및 부적합 프로세스를 자세히 설명해야 합니다.
사전 대응적 2차 목표의 서비스 정의는 네트워크 중단 식별, 링크 다운 또는 디바이스 다운 상태, 네트워크 오류 상태, 네트워크 용량 임계값 등 사전 대응적 지원을 제공하는 방법을 정의합니다.사전 예방적 관리를 통해 문제를 해결하고 문제를 더 신속하게 해결할 수 있으므로 사전 예방적 관리를 촉진하는 목표를 설정합니다.이 작업은 일반적으로 사용자 알림 없이 생성 및 해결된 사전 대응적 케이스 수의 목표를 설정하여 수행됩니다.많은 조직이 헬프데스크 소프트웨어에 플래그를 설정하여 사전 대응적 사례와 이를 위한 사후 대응적 사례를 식별합니다.서비스 레벨 문서에는 목표 측정 방법, 측정 담당자 및 부적합 프로세스에 대한 정보도 포함되어야 합니다.
성능 지표 메트릭
서비스 수준을 측정하고 가용성 및 성능의 주요 목표를 저해하는 근본 원인 서비스 문제를 파악하고 특정 대상을 목표로 하는 개선을 할 수 있도록 정의된 서비스 수준 목표를 측정할 것을 항상 권장합니다.전반적으로 메트릭은 네트워크 관리자가 서비스 수준 일관성을 관리하고 비즈니스 요구 사항에 따라 개선할 수 있는 툴입니다.
안타깝게도 많은 조직에서는 가용성, 성능 및 기타 메트릭을 수집하지 않습니다.조직에서는 이를 완전한 정확성, 비용, 네트워크 오버헤드 및 가용 리소스를 제공하지 못하는 것으로 보고 있습니다.이러한 요인은 서비스 수준을 측정하는 능력에 영향을 미칠 수 있지만, 서비스 수준을 관리하고 개선하기 위한 전반적인 목표에 초점을 맞춰야 합니다.많은 조직에서는 완전한 정확성을 제공하지는 않지만 이러한 주요 목표를 충족시키는 저비용의 낮은 오버헤드 메트릭을 생성할 수 있었습니다.
가용성 및 성능 측정은 서비스 수준 메트릭에서 간과되는 한 가지 영역입니다.이러한 메트릭을 통해 성공한 조직은 두 가지 간단한 방법을 사용합니다.한 가지 방법은 네트워크의 핵심 위치에서 에지로 ICMP(Internet Control Message Protocol) ping 패킷을 전송하는 것입니다.이 방법을 사용하여 성능을 얻을 수도 있습니다.이 방법을 성공적으로 사용하는 조직은 LAN 장치 또는 국내 현장 사무소와 같은 장치를 "가용성 그룹"으로 그룹화합니다.이는 또한 기업의 네트워크 내 지리적 또는 비즈니스 크리티컬 영역에 대한 서비스 수준 목표가 다르기 때문에 매력적입니다.이렇게 하면 메트릭 그룹이 가용성 그룹이 있는 모든 디바이스의 평균을 계산하여 적절한 결과를 얻을 수 있습니다.
가용성 계산의 또 다른 성공적인 방법은 문제 티켓 및 영향을 받는 IUM(User Minutes)이라는 측정값을 사용하는 것입니다. 이 방법을 사용하면 중단으로 인해 영향을 받은 사용자 수를 표식하고 가동 중단 시간(분)을 곱합니다.해당 기간에 총 시간(분)의 백분율로 표현되는 경우 이 값을 가용성으로 쉽게 변환할 수 있습니다.두 경우 모두 다운타임의 근본 원인을 파악하고 측정하여 개선을 보다 쉽게 목표로 설정할 수 있습니다.근본 원인 범주에는 하드웨어 문제, 소프트웨어 문제, 링크 또는 통신 사업자 문제, 전원 또는 환경 문제, 변경 실패, 사용자 오류 등이 있습니다.
측정 가능한 사후 대응적 지원 목표는 다음과 같습니다.
-
통화 우선순위별 사후 대응적 서비스 응답 시간
-
문제 해결 목표 또는 MTTR
-
문제 에스컬레이션 시간
다음 필드를 포함하여 헬프 데스크 데이터베이스에서 보고서를 생성하여 사후 대응적 지원 목표를 측정합니다.
-
통화가 처음 보고된 시간(또는 데이터베이스에 입력된 시간)
-
문제에 대해 작업하는 개인이 통화를 수락한 시간
-
문제가 에스컬레이션된 시간
-
문제가 종료된 시간
이러한 메트릭은 데이터베이스에 문제를 지속적으로 입력하고 실시간으로 문제를 업데이트하기 위해 관리 영향력을 필요로 할 수 있습니다.경우에 따라 조직에서는 네트워크 이벤트 또는 이메일 요청에 대한 문제 표를 자동으로 생성할 수 있습니다.따라서 문제의 시작 시간을 정확하게 파악할 수 있습니다.이러한 종류의 메트릭에서 생성된 보고서는 일반적으로 문제를 우선순위, 작업 그룹 및 개인별로 정렬하여 잠재적인 문제를 결정합니다.
사전 대응적 지원 프로세스를 측정하려면 사전 대응적 작업을 모니터링하고 실효성 측정치를 계산해야 하므로 더 어렵습니다.이 지역에서는 거의 할 일이 없다.그러나 소수의 사람들만이 실제로 헬프 데스크에 네트워크 문제를 보고할 것이며, 이들이 문제를 보고하면 문제를 설명하거나 문제를 네트워크 관련 문제로 격리하는 데 시간이 걸릴 것이 분명합니다.이중화 디바이스 또는 링크의 장애로 인해 모든 사전 대응적 케이스가 가용성과 성능에 즉각적인 영향을 미치는 것은 아닙니다.
사전 대응적인 서비스 수준 정의 또는 계약을 구현하는 조직은 비즈니스 요구 사항 및 잠재적 가용성 위험 때문에 이를 실현합니다.그런 다음 사전 대응적 케이스의 수량 또는 백분율을 기준으로 측정하며, 이는 사용자가 생성하는 사후 대응적 케이스와 다릅니다.각 영역별로 사전 대응적 케이스의 양을 측정하는 것도 좋습니다.이러한 범주에는 하위 디바이스, 하위 링크, 네트워크 오류 및 용량 위반이 포함됩니다.가용성 모델링 및 사전 대응적 사례를 사용하여 사전 대응적 서비스 정의를 구현하여 가용성에 미치는 영향을 파악할 수도 있습니다.
서비스 수준 관리 검토
서비스 수준 관리 성공의 또 다른 척도는 서비스 수준 관리 검토입니다.SLA가 제자리에 있는지 여부에 관계없이 이 작업을 수행해야 합니다.정의된 서비스 레벨을 측정하고 제공하는 담당자 및 매월 회의를 통해 서비스 레벨 관리 검토를 수행합니다.SLA가 관련된 경우 사용자 그룹이 있을 수도 있습니다.이 회의의 목적은 측정된 서비스 수준 정의의 성능을 검토하고 개선시키는 것입니다.
각 모임에는 다음을 포함하는 정의된 어젠다가 있어야 합니다.
-
지정된 기간 동안 측정된 서비스 수준 검토
-
개별 영역에 대해 정의된 개선 이니셔티브 검토
-
현재 서비스 수준 메트릭
-
현재 메트릭 집합을 기반으로 개선이 필요한 항목에 대한 논의
시간이 지남에 따라 조직에서는 그룹의 효율성을 확인하기 위해 서비스 레벨 규정 준수를 유도할 수도 있습니다.이 프로세스는 품질 원 또는 품질 향상 프로세스와 다르지 않습니다.이 회의는 개별 문제를 대상으로 하고 근본 원인을 기반으로 솔루션을 결정하는 데 도움이 됩니다.
서비스 수준 관리 요약
요약하자면, 서비스 수준 관리를 통해 조직은 사후 대응적 지원 모델에서 사전 대응적 지원 모델로 전환할 수 있습니다. 이 모델에서는 최신 문제가 아닌 비즈니스 요구 사항에 따라 네트워크 가용성과 성능 수준이 결정됩니다.이 프로세스를 통해 지속적인 서비스 수준 향상과 비즈니스 경쟁력 향상을 위한 환경을 구축할 수 있습니다.서비스 수준 관리는 사전 대응적 네트워크 관리를 위한 가장 중요한 관리 구성 요소입니다.따라서 서비스 수준 관리는 모든 네트워크 계획 및 설계 단계에서 권장되며 새로 정의된 네트워크 아키텍처부터 시작해야 합니다.이를 통해 조직은 다운타임 또는 재작업의 양이 가장 적은 솔루션을 처음으로 정확하게 구현할 수 있습니다.
 피드백
피드백