概要
このドキュメントでは、StarOS Virtual Network Functions(VNF)をホストするUltra-Mセットアップのサーバで、障害のあるHDDドライブの両方を交換するために必要な手順について説明します。
背景説明
Ultra-Mは、VNFの導入を簡素化するように設計された、パッケージ化および検証済みの仮想化モバイルパケットコアソリューションです。OpenStackは、Ultra-Mの仮想化インフラストラクチャマネージャ(VIM)であり、次のノードタイプで構成されています。
- 計算
- オブジェクトストレージディスク – コンピューティング(OSD – コンピューティング)
- コントローラ
- OpenStackプラットフォーム – Director(OSPD)
Ultra-Mのアーキテクチャと関連するコンポーネントを次の図に示します。
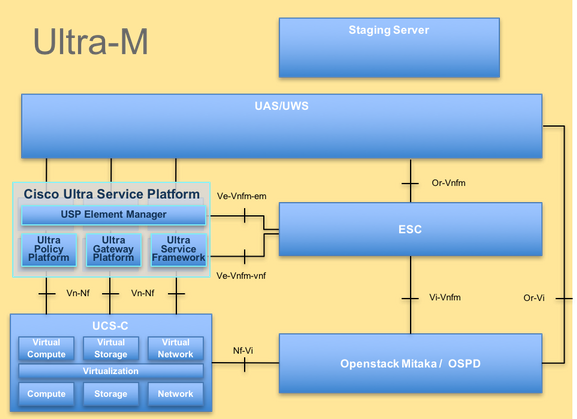 UltraMアーキテクチャ
UltraMアーキテクチャ
このドキュメントは、Cisco Ultra-Mプラットフォームに精通したシスコ担当者を対象としており、コントローラサーバ交換時にOpenStackおよびCPS VNFレベルで実行する必要がある手順の詳細を説明しています。
注:このドキュメントの手順を定義するために、Ultra M 5.1.xリリースが検討されています。
省略形
| VNF |
仮想ネットワーク機能 |
| CF |
制御機能 |
| SF |
サービス機能 |
| ESC |
Elastic Service Controller |
| MOP |
手続きの方法 |
| OSD |
オブジェクトストレージディスク |
| HDD |
ハードディスクドライブ |
| SSD |
ソリッドステートドライブ |
| VIM |
仮想インフラストラクチャマネージャ |
| VM |
仮想マシン |
| EM |
エレメント マネージャ |
| UAS |
Ultra Automation Services |
| UUID |
ユニバーサル一意IDentifier |
両方のHDD障害
1.各Baremetalサーバには、Raid 1構成でBOOT DISKとして機能する2つのHDDドライブがプロビジョニングされます。シングルHDD障害の場合、RAID 1レベルの冗長性があるため、障害のあるHDDドライブはホットスワップ可能です。ただし、両方のHDDドライブに障害が発生すると、サーバがダウンし、サーバへのアクセスが失われます。したがって、サーバとサービスへのアクセスを復元するには、HDDドライブの両方を交換し、サーバを既存のオーバークラウドスタックに追加する必要があります。
2. UCS C240 M4サーバで障害のあるコンポーネントを交換する手順は、次のURLから参照できます。 サーバコンポーネントの交換
3.両方のHDDに障害が発生した場合は、同じUCS 240M4サーバ内で、これら2つの障害のあるHDDのみを交換してください。新しいディスクを交換した後は、BIOSアップグレード手順は必要ありません。
4. OpenStackベース(Ultra-M)ソリューションでは、UCS 240M4 Baremetalサーバが次のいずれかの役割を担います。コンピューティング、OSD – コンピューティング、コントローラ、およびOSPD。これらの各サーバロールの両方のHDD障害を処理するために必要な手順については、次のセクションで説明します。
注:両方のHDDディスクが正常であるが、UCS 240M4サーバで他のハードウェアに障害がある場合は、UCS 240M4を新しいハードウェアに交換し、同じHDDドライブを再利用してください。ただし、この場合、HDDドライブのみに障害が発生している場合は、同じUCS 240M4を使用し直し、障害が発生したHDDドライブを新しいHDDドライブに交換します。
コンピューティングサーバの両方のHDD障害
コンピュートノードとして動作するUCS 240M4で両方のHDDドライブの障害が確認された場合は、次のリンクの交換手順に従ってください。PCRF-Replacement-of-Compute-Server-UCS-C240-M4
コントローラサーバの両方のHDD障害
両方のHDDドライブの障害がコントローラノードとして機能するUCS 240M4で発生する場合は、PCRF-Replacement-of-Controller-Server-UCS-C240-M4の交換手順に従います
両方のHDD障害を監視するコントローラサーバはSSH経由で到達可能ではないため、別のコントローラノードにログインして、上記のリンクに記載されているグレースフルシャットダウン手順を実行します。
OSD-Compute Serverの両方のHDD障害
両方のHDDドライブの障害がOSDコンピュートノードとして機能するUCS 240M4で発生する場合は、PCRF-Replacement-of-OSD-Compute-UCS-240M4
このリンクで説明されている手順では、両方の障害がサーバの到達不能につながるため、Ceph storage graceful shutdownを実行できません。したがって、これらの手順は無視してください。
OSPDサーバの両方のHDD障害
両方のHDDドライブの障害がOSPDノードとして機能するUCS 240M4で発生する場合は、次の交換手順に従います。Replacement-of-OSPD-Server-UCS-240M4-CPS
この場合、HDDディスクの交換後に復元するために以前に保存したOSPDバックアップは必要ありません。そうでない場合は、完全なスタックの再展開と同様です。
 フィードバック
フィードバック