OSPDサーバUCS 240M4の交換 – CPS
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
内容
概要
このドキュメントでは、Ultra-MセットアップでOpenStack Platform Director(OSPD)をホストする障害のあるサーバを交換するために必要な手順について説明します。
背景説明
Ultra-Mは、VNFの導入を簡素化するように設計された、パッケージ化および検証済みの仮想化モバイルパケットコアソリューションです。OpenStackは、Ultra-Mの仮想化インフラストラクチャマネージャ(VIM)であり、次のノードタイプで構成されています。
- 計算
- オブジェクトストレージディスク – コンピューティング(OSD – コンピューティング)
- コントローラ
- OpenStackプラットフォーム – Director(OSPD)
この図に示すように、Ultra-Mの高レベルのアーキテクチャと関連するコンポーネントを示します。
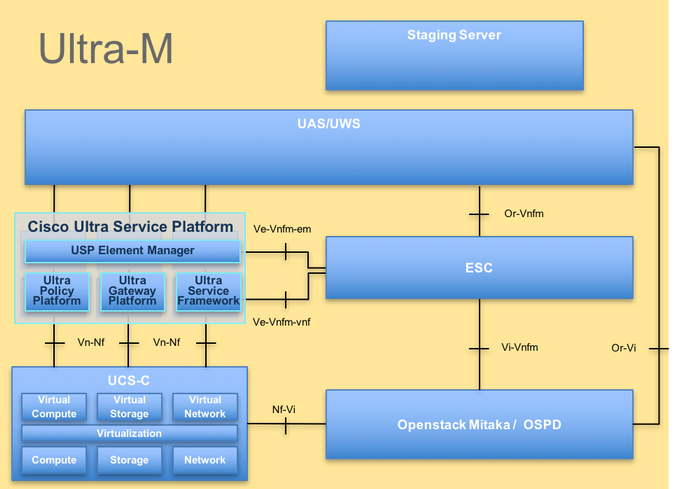 UltraMアーキテクチャ
UltraMアーキテクチャ
注:Ultra M 5.1.xリリースは、このドキュメントの手順の定義を目的としています。このドキュメントは、Cisco Ultra-Mプラットフォームに精通したシスコの担当者を対象としており、OSPDサーバの交換時にOpenStackレベルで実行する必要があります。
省略形
| VNF | 仮想ネットワーク機能 |
| ESC | Elastic Service Controller |
| MOP | 手続きの方法 |
| OSD | オブジェクトストレージディスク |
| HDD | ハードディスクドライブ |
| SSD | ソリッドステートドライブ |
| VIM | 仮想インフラストラクチャマネージャ |
| VM | 仮想マシン |
| EM | エレメント マネージャ |
| UAS | Ultra Automation Services |
| UUID | ユニバーサル一意IDentifier |
MoPのワークフロー
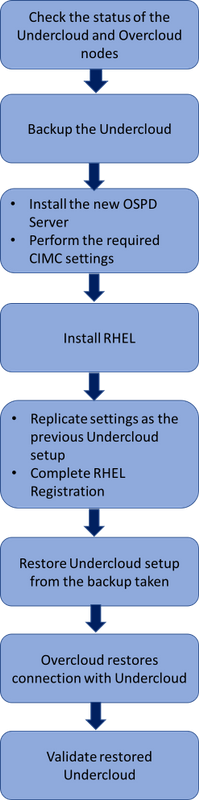 交換手順の高度なワークフロー
交換手順の高度なワークフロー
前提条件
ステータスチェック
OSPDサーバを交換する前に、Red Hat OpenStack Platform環境の現在の状態を確認し、交換プロセスがオンの場合の複雑さを回避するために正常であることを確認することが重要です。
1. OpenStackスタックの状態とノードリストを確認します。
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
2. OSPDノードからすべてのアンダークラウドサービスが読み込まれ、アクティブで、実行中の状態であるかどうかを確認します。
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
バックアップ
1.バックアッププロセスを実行する前に、十分なディスク領域があることを確認します。このtarballは少なくとも3.5 GBである必要があります。
[stack@director ~]$df -h
2.これらのコマンドをrootユーザーとして実行し、undercloudノードからundercloud-backup-[timestamp].tar.gzという名前のファイルにデータをバックアップします。
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
新しいOSPDノードのインストール
UCSサーバのインストール
1.新しいUCS C240 M4サーバのインストール手順と初期セットアップ手順については、『Cisco UCS C240 M4サーバインストールおよびサービスガイド』を参照してください
2. CIMC IPを使用してサーバにログインします。
3.ファームウェアが以前に使用した推奨バージョンと異なる場合は、BIOSアップグレードを実行します。BIOSアップグレードの手順は次のとおりです。Cisco UCS CシリーズラックマウントサーバBIOSアップグレードガイド
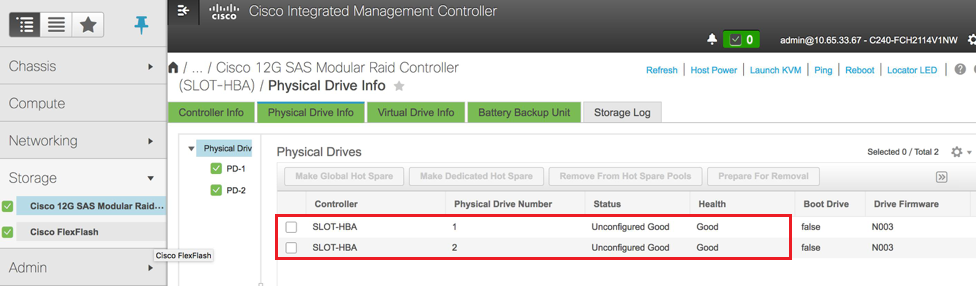
4.物理ドライブのステータスを確認します。「Unconfigured Good」である必要があります。次の図に示すように、[Storage] > [Cisco 12G SAS Modular Raid Controller (SLOT-HBA)] > [Physical Drive Info]に移動します。
5. RAIDレベル1の物理ドライブから仮想ドライブを作成します。次の図に示すように、[Storage] > [Cisco 12G SAS Modular Raid Controller (SLOT-HBA)] > [Controller Info] > [Create Virtual Drive from Unused Physical Drives]にににに移動します。
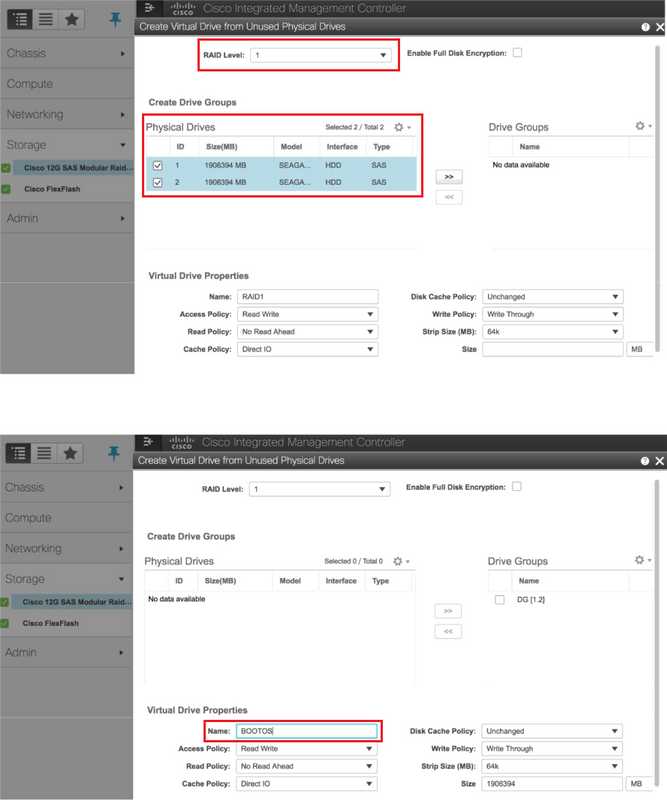
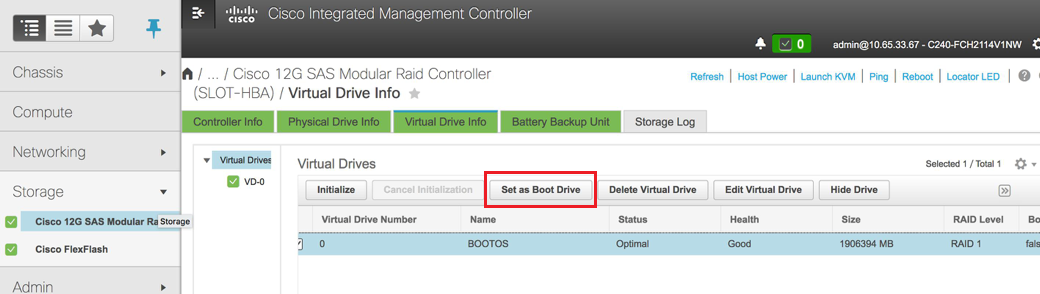
6. VDを選択し、次の図に示すように「Set as Boot Drive」を設定します。
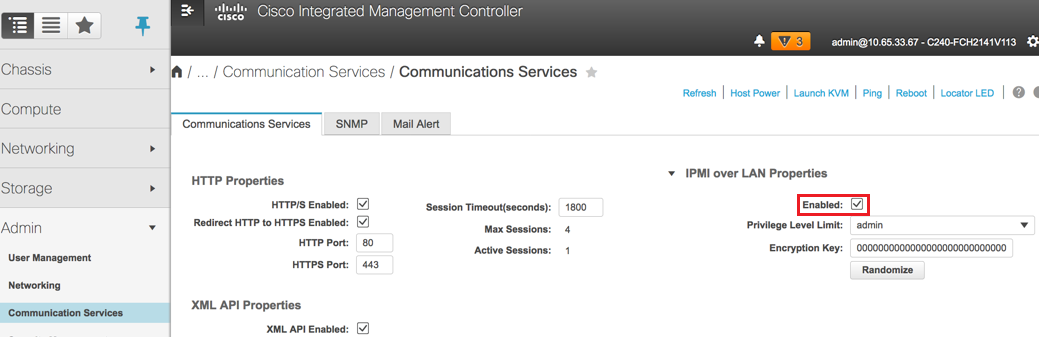
7. IPMI over LANを有効にします。次の図に示すように、[Admin] > [Communication Services] > [Communication Services]に移動します。
8.ハイパースレッディングをディセーブルにします。次の図に示すように、[Compute] > [BIOS] > [Configure BIOS] > [Advanced] > [Processor Configuration]に移動します。
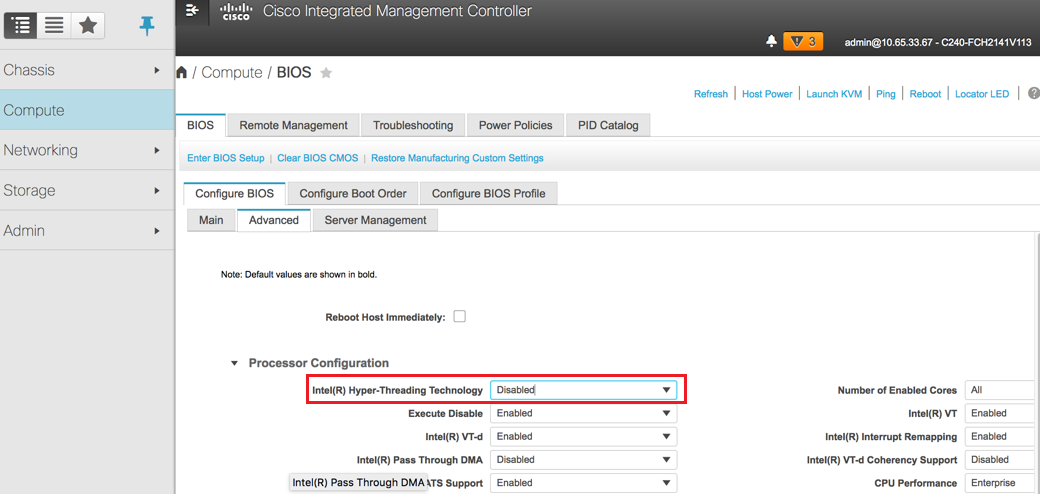
注:このセクションで説明するイメージと設定手順は、ファームウェアバージョン3.0(3e)を参照するもので、他のバージョンで作業する場合は、若干の違いがあります。
Redhatのインストール
Red Hat ISOイメージのマウント
1. OSP-Dサーバにログインします。
2. KVMコンソールの起動
3. 「仮想メディア」>「仮想デバイスのアクティブ化」を選択します。セッションを受け入れ、将来の接続に対する設定を記憶できるようにします。
4. [Virtual Media] > [Map CD/DVD]を選択して、Red Hat ISOイメージをマップします。
5. [Power] > [Reset System (Warm Boot)]の順に選択して、システムをリブートします。
6.再起動時にF6キーを押して、[Cisco vKVM-Mapped vDVD1.22]を選択してEnterキーを押します。
7. RHELをインストールします。
注:このセクションの手順は、設定が必要なパラメータの最小数を特定するインストールプロセスの簡略化されたバージョンを表しています。
8. Red Hat Enterprise Linuxをインストールしてインストールを開始するオプションを選択します
9. [Software Selection] > [Minimum Install Only]を選択します。
10.ネットワークインターフェイス(eno1およびeno2)の設定
11. [Network]と[Hostname]をクリックします。
- 外部通信(eno1またはeno2)に使用するインターフェイスを選択します
- [Configure]をクリックします
- [IPv4 Settings]タブ、[Select Manual]メソッドの順に選択し、[Add]をクリックします
- 次のパラメータを前の手順で設定します。 アドレス、ネットマスク、ゲートウェイ、DNSサーバ
12. 「日付と時刻」を選択し、地域と市区町村を指定します。
13. [Network Time]を有効にし、NTPサーバを設定します。
14. [Installation Destination]を選択し、ext4ファイルシステムを使用します。
注:'/home/'を削除し、ルート'/'の下の容量を再割り当てします。
15. Kdumpを無効にします。
16.ルートパスワードのみを設定します。
17.インストールを開始します。
アンダークラウドの復元
バックアップに基づくアンダークラウドのインストールの準備
マシンがRHEL 7.3でインストールされ、クリーン状態になったら、directorのインストールと実行に必要なすべてのサブスクリプション/リポジトリを再度有効にします。
1.ホスト名の設定。
[root@director ~]$sudo hostnamectl set-hostname <FQDN_hostname>
[root@director ~]$sudo hostnamectl set-hostname --transient <FQDN_hostname>
2. /etc/hostsファイルを編集します。
[root@director ~]$ vi /etc/hosts
<ospd_external_address> <server_hostname> <FQDN_hostname>
10.225.247.142 pod1-ospd pod1-ospd.cisco.com
3.ホスト名を検証します。
[root@director ~]$ cat /etc/hostname
pod1-ospd.cisco.com
4. DNS構成を検証します。
[root@director ~]$ cat /etc/resolv.conf
#Generated by NetworkManager
nameserver <DNS_IP>
5.プロビジョニングNICインターフェイスを変更します。
[root@director ~]$ cat /etc/sysconfig/network-scripts/ifcfg-eno1
DEVICE=eno1
ONBOOT=yes
HOTPLUG=no
NM_CONTROLLED=no
PEERDNS=no
DEVICETYPE=ovs
TYPE=OVSPort
OVS_BRIDGE=br-ctlplane
BOOTPROTO=none
MTU=1500
Redhat登録の完了
1.このパッケージをダウンロードして、rhサテライトを使用するようにsubscription-managerを設定します。
[root@director ~]$ rpm -Uvh http:///pub/katello-ca-consumer-latest.noarch.rpm
[root@director ~]$ subscription-manager config
2. RHEL 7.3用のアクティベーションキーを使用してrhサテライトに登録します。
[root@director ~]$subscription-manager register --org="<ORG>" --activationkey="<KEY>"
3.定期購読の確認
[root@director ~]$ subscription-manager list –consumed
4.古いOSPDリポジトリと同じリポジトリを有効にします。
[root@director ~]$ sudo subscription-manager repos --disable=*
[root@director ~]$ subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-extras-rpms --enable=rh
el-7-server-openstack-10-rpms --enable=rhel-7-server-rh-common-rpms --enable=rhel-ha-for-rhel-7-server-rpm
5.システムを更新して、最新の基本システムパッケージがあることを確認し、システムを再起動します。
[root@director ~]$sudo yum update -y
[root@director ~]$sudo reboot
アンダークラウドの復元
サブスクリプションを有効にした後、バックアップされたundercloud tarファイルundercloud-backup-'date +%F'.tar.gzを新しいOSPDサーバのルートディレクトリ/rootにインポートします。
1. mariadbサーバをインストールします。
[root@director ~]$ yum install -y mariadb-server
2. MariaDB設定ファイルとデータベースバックアップを抽出します。この操作をrootユーザとして実行します。
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/my.cnf.d/server.cnf
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz root/undercloud-all-databases.sql
3. /etc/my.cnf.d/server.cnfを編集し、バインドアドレスが存在する場合はコメントアウトします。
[root@tb3-ospd ~]# vi /etc/my.cnf.d/server.cnf
4. MariaDBサービスを開始し、max_allowed_packet設定を一時的に更新します。
[root@director ~]$ systemctl start mariadb
[root@director ~]$ mysql -uroot -e"set global max_allowed_packet = 16777216;"
5.特定のアクセス許可をクリーンアップします(後で再作成します)。
[root@director ~]$ for i in ceilometer glance heat ironic keystone neutron nova;do mysql -e "drop user $i";done
[root@director ~]$ mysql -e 'flush privileges'
注:セットアップで以前にceilometerサービスが無効になっている場合は、上記のコマンドを実行して「ceilometer」を削除します。
6. stackuserアカウントを作成します。
[root@director ~]$ sudo useradd stack
[root@director ~]$ sudo passwd stack << specify a password
[root@director ~]$ echo "stack ALL=(root) NOPASSWD:ALL" | sudo tee -a /etc/sudoers.d/stack
[root@director ~]$ sudo chmod 0440 /etc/sudoers.d/stack
7.スタックユーザのホームディレクトリを復元します。
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz home/stack
8. swiftおよびglanceベースパッケージをインストールし、そのデータを復元します。
[root@director ~]$ yum install -y openstack-glance openstack-swift
[root@director ~]$ tar --xattrs -xzC / -f undercloud-backup-$DATE.tar.gz srv/node var/lib/glance/images
9.データが正しいユーザーによって所有されていることを確認します。
[root@director ~]$ chown -R swift: /srv/node
[root@director ~]$ chown -R glance: /var/lib/glance/images
10.アンダークラウドSSL証明書を復元します(オプション – セットアップでSSL証明書を使用する場合にのみ実行されます)。
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/instack-certs/undercloud.pem
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/ca-trust/source/anchors/ca.crt.pem
11. undercloudのインストールをstackuserとして再実行し、必ずスタックユーザのホームディレクトリで実行してください。
[root@director ~]$ su - stack
[stack@director ~]$ sudo yum install -y python-tripleoclient
12. /etc/hostsにホスト名が正しく設定されていることを確認します。
13. undercloudを再インストールします。
[stack@director ~]$ openstack undercloud install
<snip>
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and must be
secured.
#############################################################################
復元されたアンダークラウドをオーバークラウドに再接続する
これらの手順を完了すると、アンダークラウドは自動的にオーバークラウドへの接続を復元すると予想されます。ノードは、数秒間隔で発行される単純なHTTP要求を使用して、保留中のタスクのオーケストレーション(熱)をポーリングし続けます。
完了したリストアの検証
新しく復元した環境のヘルスチェックを実行するには、次のコマンドを使用します。
[root@director ~]$ su - stack
Last Log in: Tue Nov 28 21:27:50 EST 2017 from 10.86.255.201 on pts/0
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| b1f5294a-629e-454c-b8a7-d15e21805496 | pod1-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.119 |
| 9106672e-ac68-423e-89c5-e42f91fefda1 | pod1-compute-1 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
| b3ed4a8f-72d2-4474-91a1-b6b70dd99428 | pod1-compute-2 | ACTIVE | - | Running | ctlplane=192.200.0.124 |
| 677524e4-7211-4571-ac35-004dc5655789 | pod1-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.107 |
| 55ea7fe5-d797-473c-83b1-d897b76a7520 | pod1-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.122 |
| c34c1088-d79b-42b6-9306-793a89ae4160 | pod1-compute-5 | ACTIVE | - | Running | ctlplane=192.200.0.108 |
| 4ba28d8c-fb0e-4d7f-8124-77d56199c9b2 | pod1-compute-6 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| d32f7361-7e73-49b1-a440-fa4db2ac21b1 | pod1-compute-7 | ACTIVE | - | Running | ctlplane=192.200.0.106 |
| 47c6a101-0900-4009-8126-01aaed784ed1 | pod1-compute-8 | ACTIVE | - | Running | ctlplane=192.200.0.121 |
| 1a638081-d407-4240-b9e5-16b47e2ff6a2 | pod1-compute-9 | ACTIVE | - | Running | ctlplane=192.200.0.112 |
<snip>
[stack@director ~]$ ssh heat-admin@192.200.0.107
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.1.10.10 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.97 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-192.200.0.106 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.95 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.98 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.92 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Stopped
Failed Actions:
* my-ipmilan-for-controller-0_start_0 on pod1-controller-1 'unknown error' (1): call=190, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-1 'unknown error' (1): call=192, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-1 'unknown error' (1): call=188, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-0 'unknown error' (1): call=210, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-0 'unknown error' (1): call=207, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-0 'unknown error' (1): call=206, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20006ms
* ip-192.200.0.106_monitor_10000 on pod1-controller-0 'not running' (7): call=197, status=complete, exitreason='none',
last-rc-change='Wed Nov 22 13:51:31 2017', queued=0ms, exec=0ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-2 'unknown error' (1): call=183, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=1ms, exec=20006ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-2 'unknown error' (1): call=184, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-2 'unknown error' (1): call=177, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:02 2017', queued=0ms, exec=20005ms
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[heat-admin@pod1-controller-0 ~]$ sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v1245812: 704 pgs, 6 pools, 542 GB data, 352 kobjects
1625 GB used, 11767 GB / 13393 GB avail
704 active+clean
client io 21549 kB/s wr, 0 op/s rd, 120 op/s wr
アイデンティティサービス(Keystone)の動作の確認
この手順では、ユーザのリストを照会して、Identity Service Operationsを検証します。
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack user list
+----------------------------------+------------------+
| ID | Name |
+----------------------------------+------------------+
| 69ac2b9d89414314b1366590c7336f7d | admin |
| f5c30774fe8f49d0a0d89d5808a4b2cc | glance |
| 3958d852f85749f98cca75f26f43d588 | heat |
| cce8f2b7f1a843a08d0bb295a739bd34 | ironic |
| ce7c642f5b5741b48a84f54d3676b7ee | ironic-inspector |
| a69cd42a5b004ec5bee7b7a0c0612616 | mistral |
| 5355eb161d75464d8476fa0a4198916d | neutron |
| 7cee211da9b947ef9648e8fe979b4396 | nova |
| f73d36563a4a4db482acf7afc7303a32 | swift |
| d15c12621cbc41a8a4b6b67fa4245d03 | zaqar |
| 3f0ed37f95544134a15536b5ca50a3df | zaqar-websocket |
+----------------------------------+------------------+
[stack@director ~]$
[stack@director ~]$ source <overcloudrc>
[stack@director ~]$ openstack user list
+----------------------------------+------------+
| ID | Name |
+----------------------------------+------------+
| b4e7954942184e2199cd067dccdd0943 | admin |
| 181878efb6044116a1768df350d95886 | neutron |
| 6e443967ee3f4943895c809dc998b482 | heat |
| c1407de17f5446de821168789ab57449 | nova |
| c9f64c5a2b6e4d4a9ff6b82adef43992 | glance |
| 800e6b1163b74cc2a5fab4afb382f37d | cinder |
| 4cfa5a2a44c44c678025842f080e5f53 | heat-cfn |
| 9b222eeb8a58459bb3bfc76b8fff0f9f | swift |
| 815f3f25bcda49c290e1b56cd7981d1b | core |
| 07c40ade64f34a64932129175150fa4a | gnocchi |
| 0ceeda0bc32c4d46890e53adef9a193d | aodh |
| f3caab060171468592eab376a94967b8 | ceilometer |
+----------------------------------+------------+
[stack@director ~]$
将来のノードのイントロスペクション用のイメージのアップロード
これらのすべてのファイルinspector.ipxe、agent.kernel、agent.ramdiskを検証/httpboot。そうでない場合は、次の手順に従ってイメージを更新します。
[stack@director ~]$ ls /httpboot
inspector.ipxe
[stack@director ~]$ source stackrc
[stack@director ~]$ cd images/
[stack@director images]$ openstack overcloud image upload --image-path /home/stack/images
Image "overcloud-full-vmlinuz" is up-to-date, skipping.
Image "overcloud-full-initrd" is up-to-date, skipping.
Image "overcloud-full" is up-to-date, skipping.
Image "bm-deploy-kernel" is up-to-date, skipping.
Image "bm-deploy-ramdisk" is up-to-date, skipping.
[stack@director images]$ ls /httpboot
agent.kernel agent.ramdisk inspector.ipxe
[stack@director images]$
フェンシングの再起動
OSPD回復後、フェンシングが停止状態になる。この手順により、フェンシングが有効になります。
[heat-admin@pod1-controller-0 ~]$ sudo pcs property set stonith-enabled=true
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
[heat-admin@pod1-controller-0 ~]$sudo pcs stonith show
関連情報
シスコ エンジニア提供
- Aaditya DeodharCisco Advanced Services
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)