Introduzione
In questo documento viene descritto un problema relativo al ripristino del database di configurazione non riuscito nell'installazione di vManage per il ripristino di emergenza del cluster.
Problema
Ripristina vManage NMS dal backup: il ripristino del database di configurazione non riesce nella configurazione del ripristino di emergenza del cluster
Dalla CLI, usare il comando request nms configuration-db restore path. Questo comando ripristina il database di configurazione dal percorso dati di individuazione file. In questo esempio, la destinazione è il vManage NMS in standby. Eseguire questi comandi sul server vManage NMS in standby:
vmanage-1# request nms configuration-db restore path /home/admin/cluster-backup.tar.gz
Configuration database is running in a cluster mode
!
!
!
line omitted
!
!
!
.................... 80%
.................... 90%
.................... 100%
Backup complete.
Finished DB backup from: 30.1.1.1
Stopping NMS application server on 30.1.1.1
Stopping NMS application server on 30.1.1.2
Stopping NMS application server on 30.1.1.3
Stopping NMS configuration database on 30.1.1.1
Stopping NMS configuration database on 30.1.1.2
Stopping NMS configuration database on 30.1.1.3
Reseting NMS configuration database on 30.1.1.1
Reseting NMS configuration database on 30.1.1.2
Reseting NMS configuration database on 30.1.1.3
Restoring from DB backup: /opt/data/backup/staging/graph.db-backup
cmd to restore db: sh /usr/bin/vconfd_script_nms_neo4jwrapper.sh restore /opt/data/backup/staging/graph.db-backup
Successfully restored DB backup: /opt/data/backup/staging/graph.db-backup
Starting NMS configuration database on 30.1.1.1
Waiting for 10s before starting other instances...
Starting NMS configuration database on 30.1.1.2
Waiting for 120s for the instance to start...
NMS configuration database on 30.1.1.2 has started.
Starting NMS configuration database on 30.1.1.3
Waiting for 120s for the instance to start...
NMS configuration database on 30.1.1.3 has started.
NMS configuration database on 30.1.1.1 has started.
Updating DB with the saved cluster configuration data
Successfully reinserted cluster meta information
Starting NMS application-server on 30.1.1.1
Waiting for 120s for the instance to start...
Starting NMS application-server on 30.1.1.2
Waiting for 120s for the instance to start...
Starting NMS application-server on 30.1.1.3
Waiting for 120s for the instance to start...
Removed old database directory: /opt/data/backup/local/graph.db-backup
Successfully restored database
vmanage-1#
Passaggio 1. Config-db deve essere ripristinato con questi log, ma esiste uno scenario in cui il backup di config_db non riesce con questi messaggi di errore.
vmanage-1# request nms configuration-db restore path /home/admin/cluster-backup.tar.gz
Configuration database is running in a cluster mode
!
!
line ommited
!
!
2020-08-09 17:13:48.758+0800 INFO [o.n.k.i.s.f.RecordFormatSelector] Selected RecordFormat:StandardV3_2[v0.A.8] record format from store /opt/data/backup/local/graph.db-backup
2020-08-09 17:13:48.759+0800 INFO [o.n.k.i.s.f.RecordFormatSelector] Format not configured. Selected format from the store: RecordFormat:StandardV3_2[v0.A.8]
.................... 10%
.................... 20%
.................... 30%
.................... 40%
.................... 50%
.................... 60%
.................... 70%
...............Checking node and relationship counts
.................... 10%
.................... 20%
.................... 30%
.................... 40%
.................... 50%
.................... 60%
.................... 70%
.................... 80%
.................... 90%
.................... 100% Backup complete.
Finished DB backup from: 30.1.1.1
Stopping NMS application server on 30.1.1.1
Stopping NMS application server on 30.1.1.2
Could not stop NMS application-server on 30.1.1.2
Failed to restore the database
Passaggio 2. Nell'errore menzionato, scenario In Gestione cluster pagina in vmanage, passare ad Amministratore > Gestione cluster > Seleziona gestione adiacente (...) > Modifica

Durante la modifica di vManage nella gestione cluster, l'errore ricevuto è: "Impossibile ottenere un elenco di indirizzi IP configurati - Autenticazione non riuscita"'
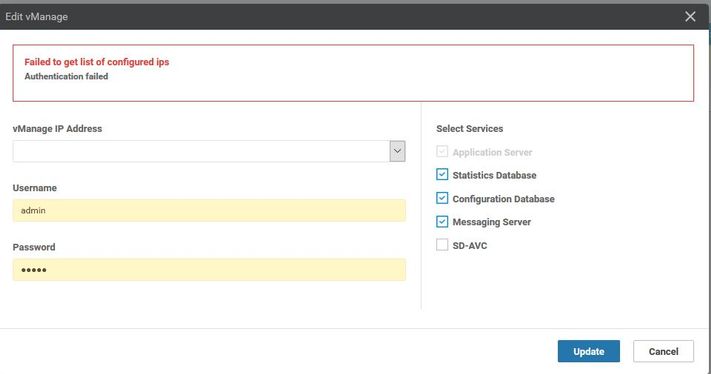
Soluzione
Durante l'operazione di ripristino config-db in un cluster vManage, è necessario avviare/arrestare i servizi sui nodi remoti. Questa operazione viene eseguita da richieste Netconf effettuate al nodo remoto nel cluster.
Se nel cluster è presente una connessione di controllo, provare a autenticare il nodo remoto con la chiave pubblica del nodo remoto per autenticare la richiesta Netconf, in modo analogo al controllo delle connessioni tra dispositivi. In caso contrario, viene eseguito il fallback alle credenziali archiviate nella tabella di database utilizzata per formare il cluster.
Si è verificato un problema: la password è stata modificata tramite CLI ma la password di gestione del cluster nel database non è stata aggiornata. Pertanto, ogni volta che si modifica la password dell'account netadmin utilizzato inizialmente per creare il cluster, è necessario aggiornare la password anche tramite l'operazione di modifica della gestione del cluster. Di seguito sono riportati i passaggi aggiuntivi da seguire.
- Accedere a ciascuna GUI di gestione.
- Passare a Amministratore > Gestione cluster > Seleziona vManage (...) corrispondente > Modifica , come mostrato nell'immagine.
- Aggiorna password equivalente a CLI.
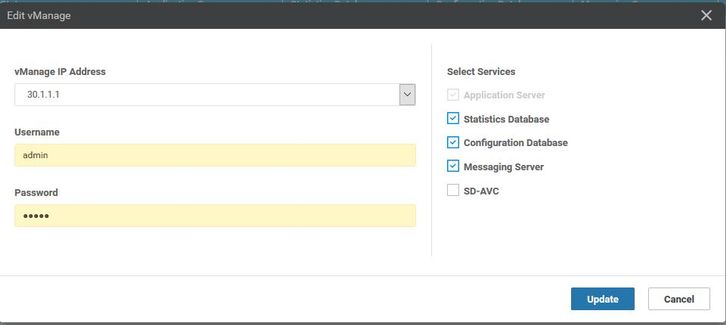
Nota: il rollback della password dalla CLI non è possibile in questo scenario dalla CLI.
Procedure ottimali
Per modificare la password di vManage nel cluster, è consigliabile passare a Amministratore > Gestisci utenti > Aggiorna password.
Questa procedura consente di aggiornare la password in tutti e tre i vManage del cluster, nonché la password di gestione del cluster.
Informazioni correlate
 Feedback
Feedback