Sostituzione della scheda madre nel server Ultra-M UCS 240M4 - CPAR
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
Questo documento descrive i passaggi necessari per sostituire la scheda madre difettosa di un server in un'installazione Ultra-M.
Questa procedura è valida per un ambiente Openstack che utilizza la versione NEWTON in cui ESC non gestisce CPAR e CPAR è installato direttamente sulla VM distribuita in Openstack.
Premesse
Ultra-M è una soluzione mobile packet core preconfezionata e convalidata, progettata per semplificare l'installazione delle VNF. OpenStack è Virtualized Infrastructure Manager (VIM) per Ultra-M ed è costituito dai seguenti tipi di nodi:
- Calcola
- Disco Object Storage - Compute (OSD - Compute)
- Controller
- Piattaforma OpenStack - Director (OSPD)
L'architettura di alto livello di Ultra-M e i componenti coinvolti sono illustrati in questa immagine:
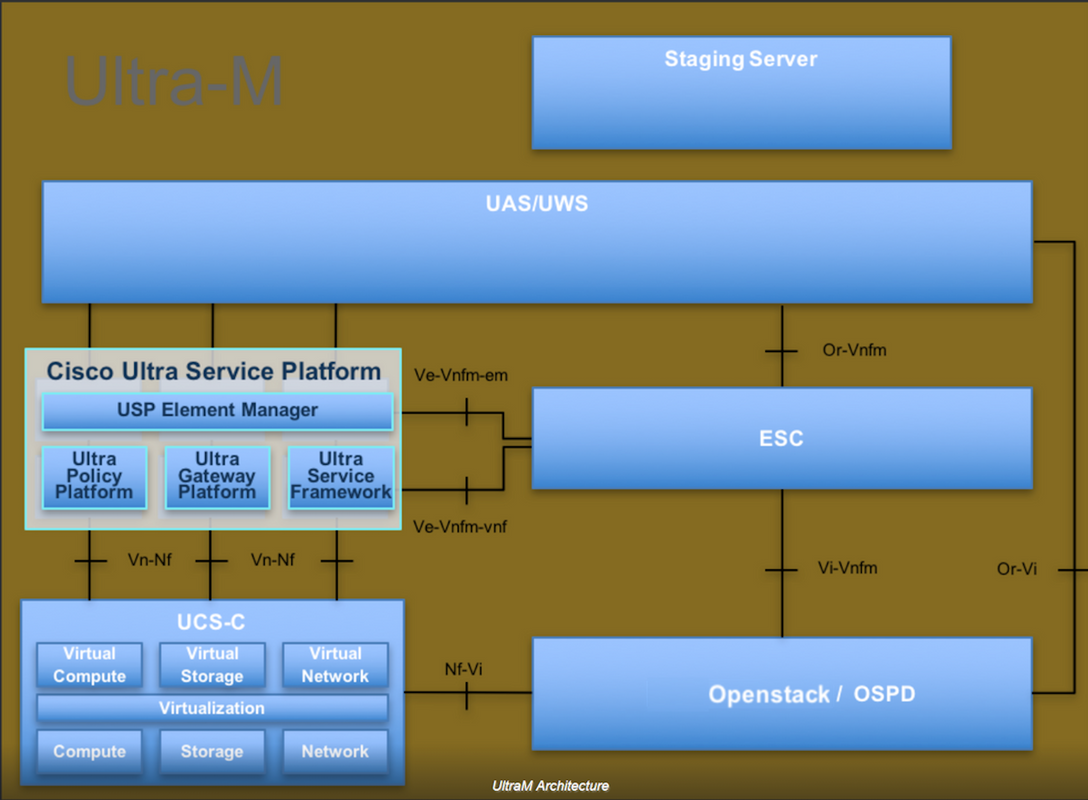
Questo documento è destinato al personale Cisco che ha familiarità con la piattaforma Cisco Ultra-M e descrive i passaggi che devono essere eseguiti in OpenStack e Redhat OS.
Nota: Per definire le procedure descritte in questo documento, viene presa in considerazione la release di Ultra M 5.1.x.
Abbreviazioni
| MOP | Metodo |
| OSD | Dischi Object Storage |
| OSPD | OpenStack Platform Director |
| HDD | Unità hard disk |
| SSD | Unità a stato solido |
| VIM | Virtual Infrastructure Manager |
| VM | Macchina virtuale |
| EM | Gestione elementi |
| UAS | Ultra Automation Services |
| UUID | Identificatore univoco universale |
Flusso di lavoro del piano di mobilità
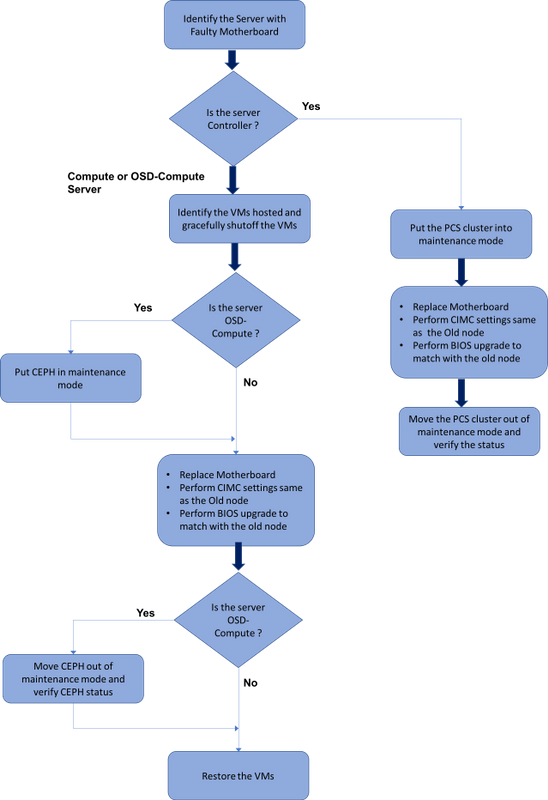
Sostituzione della scheda madre in Ultra-M Setup
In un'installazione Ultra-M possono verificarsi situazioni in cui è necessaria la sostituzione di una scheda madre nei seguenti tipi di server: Compute, OSD-Compute e Controller.
Nota: I dischi di avvio con l'installazione openstack vengono sostituiti dopo la sostituzione della scheda madre. Non è quindi necessario aggiungere nuovamente il nodo all'overcloud. Una volta che il server è stato acceso dopo l'attività di sostituzione, si sarebbe registrato nuovamente nello stack di overcloud.
Prerequisiti
Prima di sostituire un nodo Compute, è importante verificare lo stato corrente dell'ambiente della piattaforma Red Hat OpenStack. Si consiglia di controllare lo stato corrente per evitare complicazioni quando il processo di sostituzione Calcola è attivo. Questo flusso di sostituzione consente di ottenere il risultato desiderato.
In caso di ripristino, Cisco consiglia di eseguire un backup del database OSPD attenendosi alla seguente procedura:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
Questo processo assicura che un nodo possa essere sostituito senza influire sulla disponibilità di alcuna istanza.
Nota: Assicurarsi di disporre dello snapshot dell'istanza in modo da poter ripristinare la VM quando necessario. Seguire questa procedura per creare un'istantanea della VM.
Sostituzione della scheda madre nel nodo di calcolo
Prima dell'attività, le VM ospitate nel nodo Calcola vengono spente normalmente. Una volta sostituita la scheda madre, le VM vengono ripristinate.
Identificare le VM ospitate nel nodo di calcolo
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
Nota: Nell'output mostrato di seguito, la prima colonna corrisponde all'UUID (Universally Unique IDentifier), la seconda colonna è il nome della macchina virtuale e la terza colonna è il nome host in cui la macchina virtuale è presente. I parametri di questo output vengono utilizzati nelle sezioni successive.
Backup: Processo snapshot
Passaggio 1. Chiusura dell'applicazione CPAR.
Passaggio 1. Aprire un client ssh connesso alla rete e connettersi all'istanza CPAR.
È importante non arrestare tutte e 4 le istanze AAA all'interno di un sito contemporaneamente, farlo uno alla volta.
Passaggio 2.Arrestare l'applicazione CPAR con questo comando:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
Se un utente ha lasciato aperta una sessione CLI, il comando arserver stop non funziona e viene visualizzato questo messaggio:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
In questo esempio, è necessario terminare il processo evidenziato con ID 2903 prima di poter arrestare CPAR. In questo caso, terminare il processo con questo comando:
kill -9 *process_id*
Ripetere quindi il punto 1.
Passaggio 3.Verificare che l'applicazione CPAR sia stata effettivamente chiusa eseguendo il comando:
/opt/CSCOar/bin/arstatus
Verranno visualizzati i seguenti messaggi:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
Attività snapshot VM
Passaggio 1.Immettere il sito Web della GUI Horizon corrispondente al Sito (Città) su cui si sta lavorando.
Quando si accede a Horizon, viene visualizzata questa schermata:
Passaggio 2.Passate a Progetto > Varianti, come mostrato nell'immagine.
Se l'utente utilizzato era CPAR, in questo menu vengono visualizzate solo le 4 istanze AAA.
Passaggio 3.Chiudere solo un'istanza alla volta. Ripetere l'intero processo in questo documento.
Per arrestare la VM, passare a Azioni > Arresta istanza e confermare la selezione.

Passaggio 4.Verificare che l'istanza sia stata effettivamente chiusa controllando le opzioni Status = Shutoff e Power State = Shut Down.
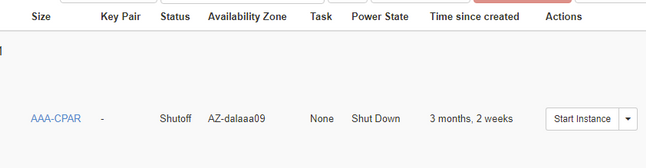
Questo passaggio termina il processo di chiusura CPAR.
Snapshot VM
Una volta disattivate le VM CPAR, le istantanee possono essere eseguite in parallelo, in quanto appartengono a computer indipendenti.
I quattro file QCOW2 verranno creati in parallelo.
Creazione di un'istantanea di ciascuna istanza AAA (25 minuti -1 ora) (25 minuti per le istanze che hanno utilizzato un'immagine qws come origine e 1 ora per le istanze che utilizzano un'immagine raw come origine)
Passaggio 1. Accesso all'orizzonte di Openstack del PODGUI.
Passaggio 2. Una volta eseguito l'accesso, passare alla sezione Progetto > Calcola > Istanze nel menu superiore e cercare le istanze AAA.
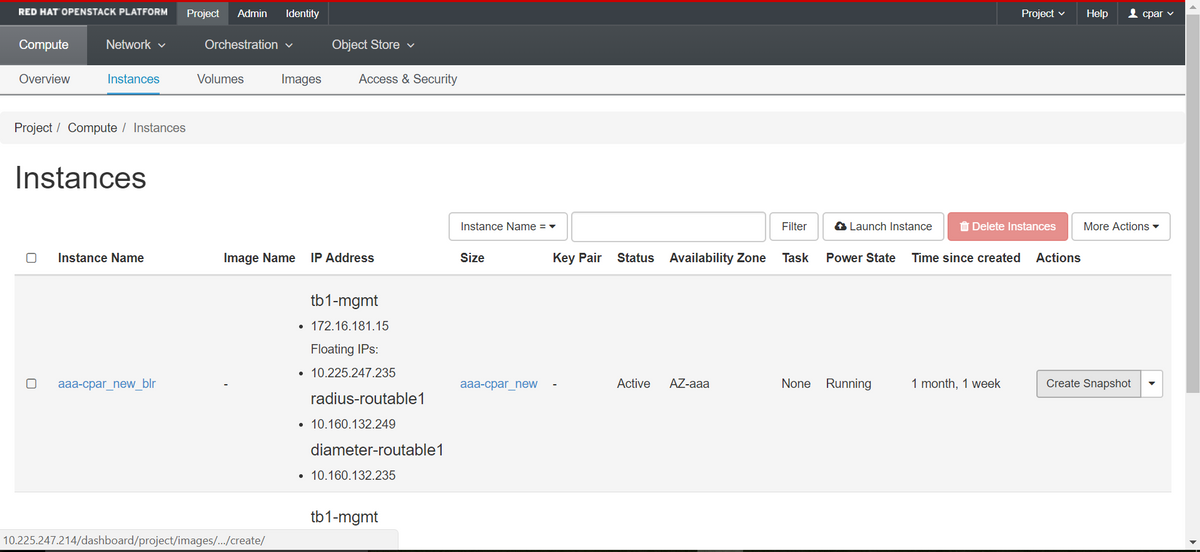
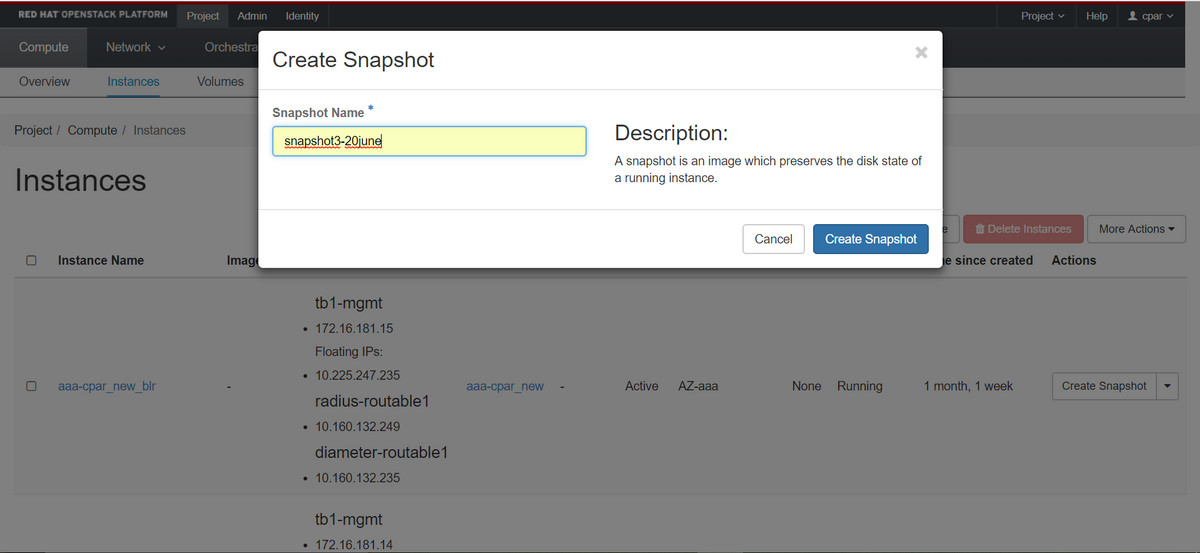
Passaggio 3. Fare clic sul pulsante Crea snapshot per procedere con la creazione dello snapshot (questa operazione deve essere eseguita sull'istanza AAA corrispondente).
Passaggio 4. Una volta eseguita l'istantanea, passare al menu IMAGES (IMMAGINI) e verificare che tutte le operazioni siano completate e che non vengano segnalati problemi.
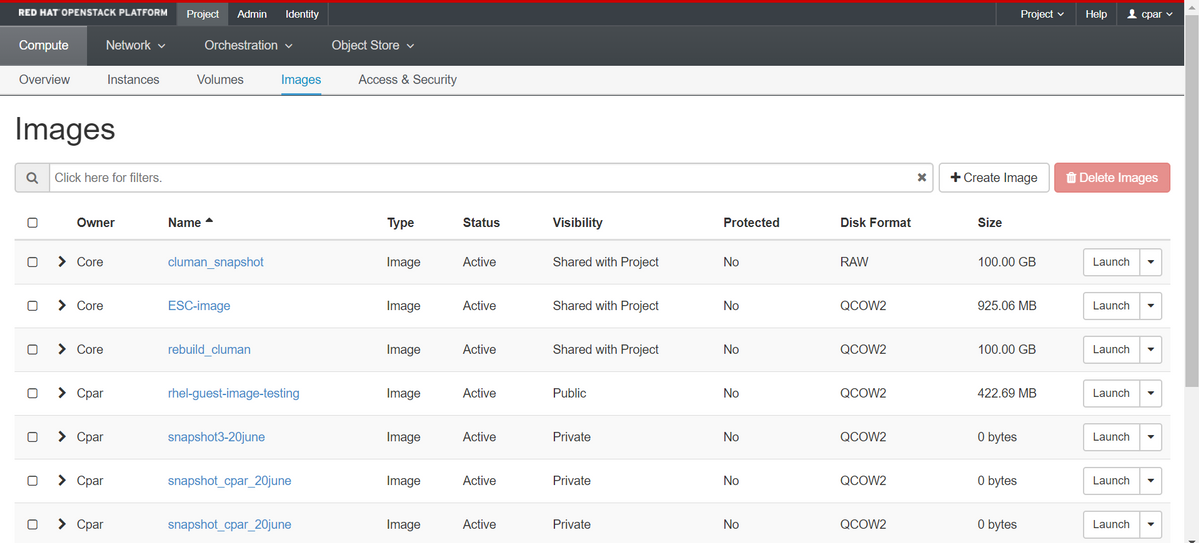
Passaggio 5. Il passaggio successivo consiste nel scaricare la copia istantanea in formato QCOW2 e trasferirla in un'entità remota nel caso in cui l'OSPD venga perso durante questo processo. A tale scopo, identificare la copia istantanea con questo comando glance image-list a livello OSPD.
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
Passaggio 6. Una volta identificata la copia istantanea da scaricare (in questo caso sarà quella contrassegnata in verde sopra), scaricarla in formato QCOW2 utilizzando il comando glance image-download come mostrato di seguito.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- Il simbolo "&" invia il processo in background. Il completamento di questa operazione richiederà del tempo. Al termine, l'immagine può essere individuata nella directory /tmp.
- Quando si invia il processo in background, se la connettività viene persa, anche il processo viene interrotto.
- Eseguire il comando "diswn -h" in modo che, in caso di perdita della connessione SSH, il processo venga eseguito e completato sull'OSPD.
Passaggio 7. Al termine del processo di download, è necessario eseguire un processo di compressione in quanto lo snapshot potrebbe essere riempito con ZEROES a causa di processi, task e file temporanei gestiti dal sistema operativo. Il comando da utilizzare per la compressione dei file è virtualizzato.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
Questo processo richiede un certo tempo (circa 10-15 minuti). Al termine, il file risultante deve essere trasferito a un'entità esterna come specificato nel passo successivo.
Per ottenere questo risultato, è necessario verificare l'integrità del file, eseguire il comando successivo e cercare l'attributo "corrupt" alla fine dell'output.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
Per evitare un problema di perdita dell'OSPD, è necessario trasferire lo snapshot creato di recente in formato QCOW2 a un'entità esterna. Prima di iniziare il trasferimento dei file, è necessario verificare se la destinazione dispone di spazio sufficiente su disco. Per verificare lo spazio di memoria, usare il comando "df -kh". È consigliabile trasferirla temporaneamente nell'OSPD di un altro sito utilizzando SFTP "sftproot@x.x.x.x", dove x.x.x.x è l'IP di un OSPD remoto. Per velocizzare il trasferimento, la destinazione può essere inviata a più OSPD. Allo stesso modo, è possibile utilizzare il seguente comando scp *name_of_the_file*.qws2 root@ x.x.x.x:/tmp (dove x.x.x.x è l'indirizzo IP di un OSPD remoto) per trasferire il file in un altro OSPD.
Spegnimento regolare
Spegni nodo
- Per spegnere l'istanza: nova stop <NOME_ISTANZA>
- A questo punto verrà visualizzato il nome dell'istanza con lo stato Shutoff.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
Sostituisci scheda madre
Per la sostituzione della scheda madre in un server UCS C240 M4, consultare la Guida all'installazione e all'assistenza del server Cisco UCS C240 M4
- Accedere al server utilizzando l'indirizzo IP CIMC.
- Eseguire l'aggiornamento del BIOS se il firmware non è conforme alla versione consigliata utilizzata in precedenza. La procedura per l'aggiornamento del BIOS è illustrata di seguito: Cisco UCS C-Series Rack-Mount Server BIOS Upgrade Guide
Ripristino delle VM
Ripristino di un'istanza tramite snapshot
Processo di ripristino
È possibile ridistribuire l'istanza precedente con l'istantanea eseguita nei passaggi precedenti.
Passaggio 1 [FACOLTATIVO].Se non è disponibile alcuna copia istantanea VM precedente, collegarsi al nodo OSPD in cui è stato inviato il backup e reindirizzarlo al nodo OSPD originale. Utilizzando "sftproot@x.x.x.x" dove x.x.x.x è l'IP dell'OSPD originale. Salvare il file snapshot nella directory /tmp.
Passaggio 2.Connettersi al nodo OSPD in cui l'istanza viene ridistribuita.
 Originare le variabili di ambiente con questo comando:
Originare le variabili di ambiente con questo comando:
# source /home/stack/pod1-stackrc-Core-CPAR
Passaggio 3.Per utilizzare l'istantanea come immagine è necessario caricarla all'orizzonte come tale. A tale scopo, utilizzare il comando successivo.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
Il processo è all'orizzonte.

Passaggio 4.In Orizzonte, selezionare Progetto > Istanze e fare clic su Avvia istanza.

Passaggio 5.Immettere il nome dell'istanza e scegliere la zona di disponibilità.
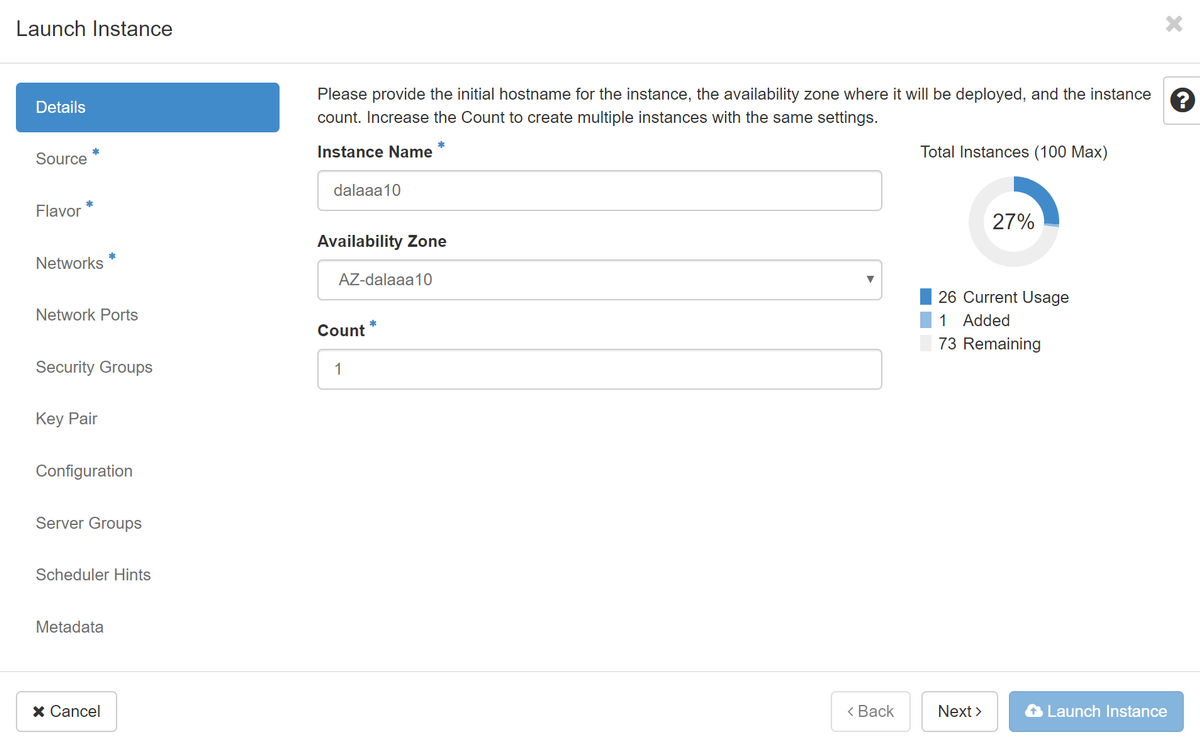
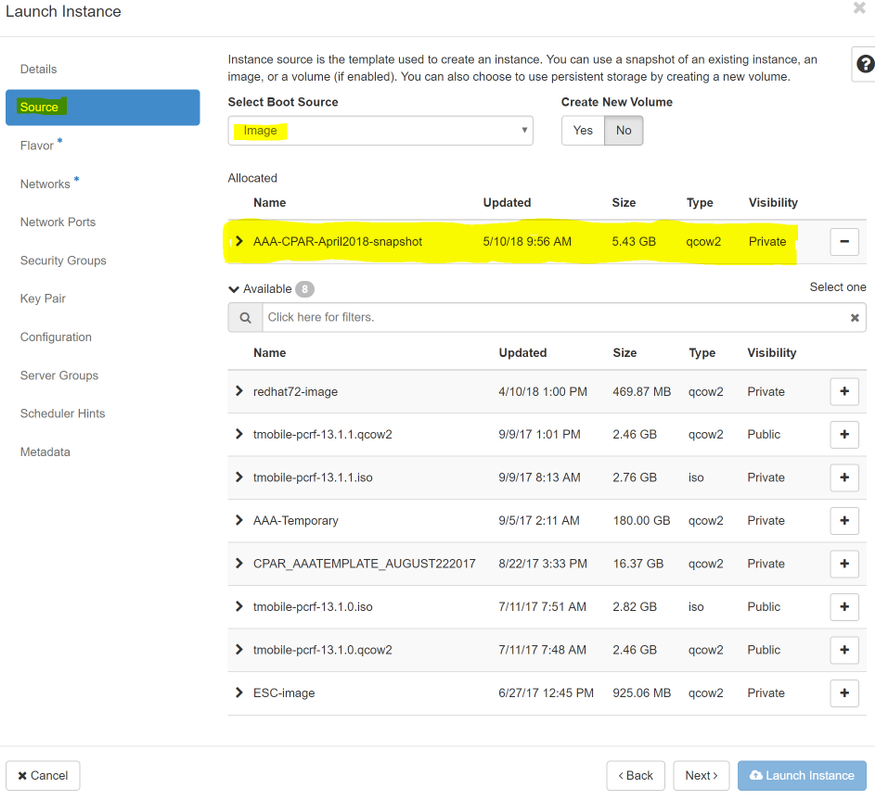
Passaggio 6.Nella scheda Origine, scegliere l'immagine per creare l'istanza. Nel menu Select Boot Source (Seleziona origine di avvio) select image (Seleziona immagine), viene visualizzato un elenco di immagini. Selezionare l'immagine caricata in precedenza facendo clic sul segno +.
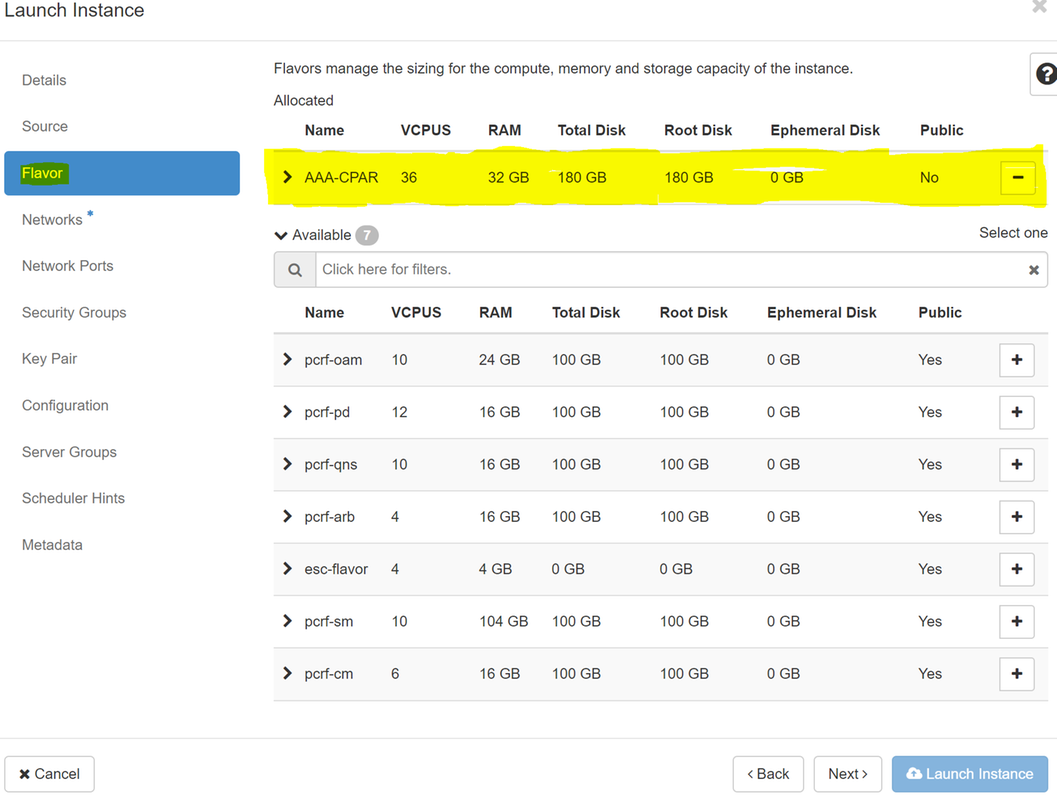
Passaggio 7.Nella scheda Gusto, scegliere il sapore AAA facendo clic sul segno +.
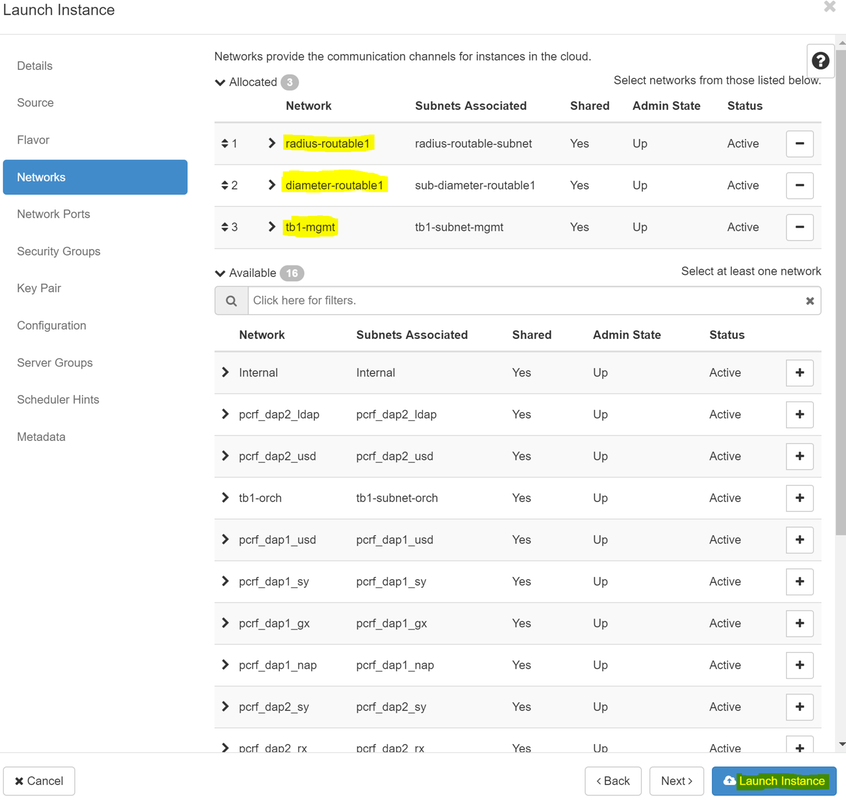
Passaggio 8.Infine, passare alla scheda Rete e scegliere le reti necessarie all'istanza facendo clic sul segno +. In questo caso, selezionare diametralmente-definibile1, radius-routable1 e tb1-mgmt.
Passaggio 9. Infine, fare clic su Avvia istanza per crearla. I progressi possono essere monitorati in Orizzonte:
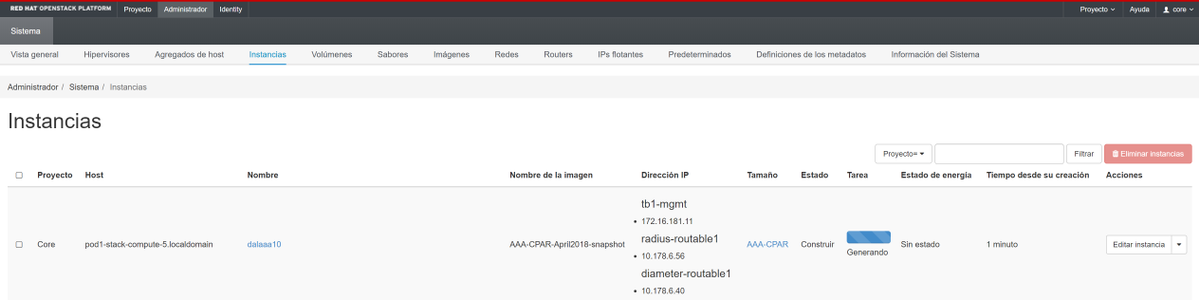
Dopo alcuni minuti, l'istanza è completamente distribuita e pronta per l'utilizzo.

Creazione e assegnazione di un indirizzo IP mobile
Un indirizzo IP mobile è un indirizzo instradabile, ossia è raggiungibile dall'esterno dell'architettura Ultra M/Openstack e può comunicare con altri nodi dalla rete.
Passaggio 1. Nel menu in alto Orizzonte, selezionare Admin > Floating IPs.
Passaggio 2. Fare clic sul pulsante AllocateIP to Project.
Passaggio 3. Nella finestra Alloca IP mobile, selezionare il pool a cui appartiene il nuovo IP mobile, il progetto a cui verrà assegnato e il nuovo indirizzo IP mobile.
Ad esempio:
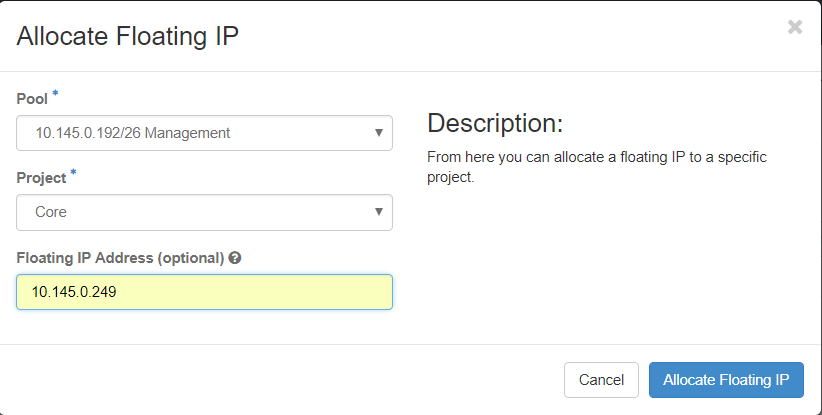
Passaggio 4. Fare clic sul pulsante AllocateFloating IP.
Passaggio 5. Nel menu in alto Orizzonte, passare a Progetto > Istanze.
Passaggio 6.Nella colonna Actionfare clic sulla freccia rivolta verso il basso nel pulsante Crea istantanea. Verrà visualizzato un menu. SelezionareAssocia IP mobile.
Passaggio 7. Selezionare l'indirizzo IP mobile corrispondente che si desidera utilizzare nel campo IP Address, quindi scegliere l'interfaccia di gestione corrispondente (eth0) dalla nuova istanza in cui l'IP mobile verrà assegnato alla porta da associare. Fare riferimento all'immagine seguente come esempio di questa procedura.
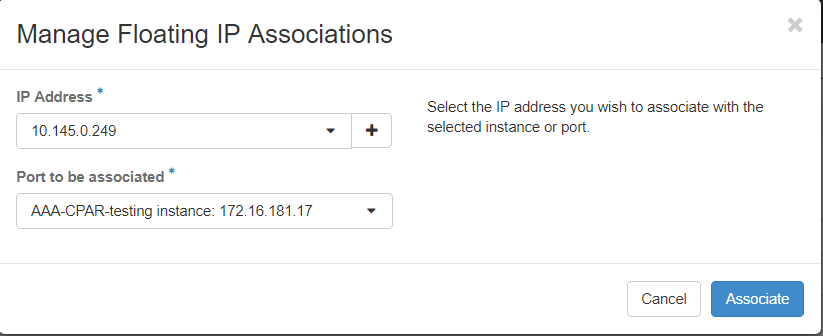
Passaggio 8.Infine, fare clic sul pulsante Associate.
Abilitazione SSH
Passaggio 1.Nel menu in alto Orizzonte, selezionate Progetto > Varianti.
Passaggio 2.Fare clic sul nome dell'istanza o della macchina virtuale creata in sectionLanciare una nuova istanza.
Passaggio 3. Fare clic su Consoletab. Verrà visualizzata l'interfaccia della riga di comando della macchina virtuale.
Passaggio 4.Una volta visualizzata la CLI, immettere le credenziali di accesso appropriate:
Nome utente:root
Password:cisco123
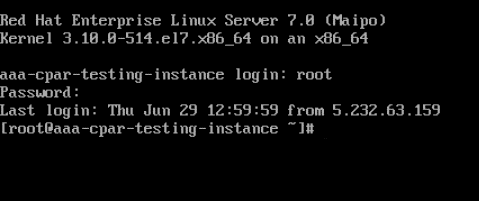
Passaggio 5.Nella CLI, immettere il comando vi /etc/ssh/sshd_configper modificare la configurazione ssh.
Passaggio 6. Una volta aperto il file di configurazione ssh, premere Invio per modificare il file. Cercare quindi la sezione riportata di seguito e modificare la prima riga da PasswordAuthentication a PasswordAuthentication yes.

Passaggio 7.Premere ESC e immettere:wq!per salvare le modifiche al file sshd_config.
Passaggio 8. Eseguire il riavvio del comando sshd.
Passaggio 9. Per verificare che le modifiche alla configurazione SSH siano state applicate correttamente, aprire un client SSH e provare a stabilire una connessione protetta remota usando l'IP mobile assegnato all'istanza (ad esempio 10.145.0.249) e la radice dell'utente.
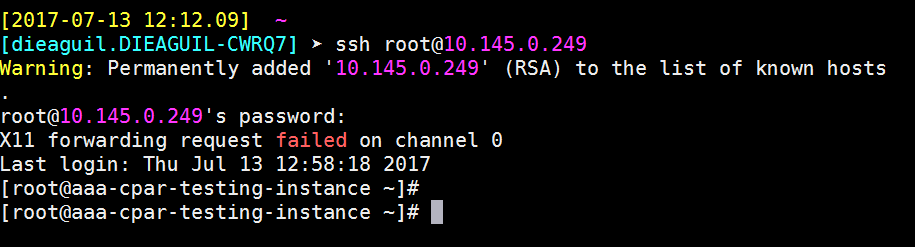
Definizione di una sessione SSH
Aprire una sessione SSH utilizzando l'indirizzo IP della macchina virtuale/server corrispondente in cui è installata l'applicazione.

Avvio istanza CPAR
Una volta completata l'attività, sarà possibile ristabilire i servizi CPAR nel Sito che è stato chiuso.
- Per accedere nuovamente a Orizzonte, selezionare Progetto > Istanza > Avvia istanza.
- Verificare che lo stato dell'istanza sia attivo e che lo stato di alimentazione sia in esecuzione:
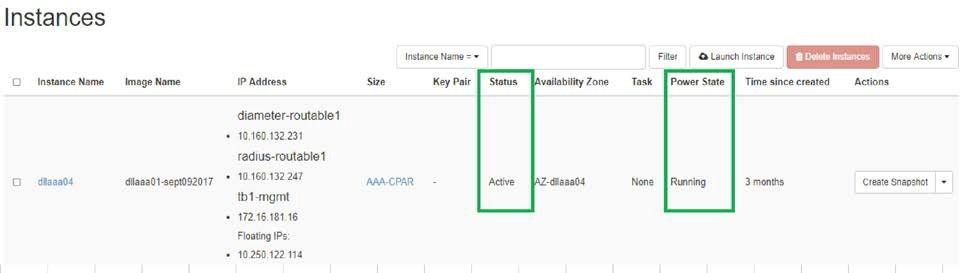
Controllo dello stato post-attività
Passaggio 1. Eseguire il comando /opt/CSCOar/bin/arstatus a livello di sistema operativo.
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Passaggio 2. Eseguire il comando /opt/CSCOar/bin/aregcmd a livello di sistema operativo e immettere le credenziali dell'amministratore. Verificare che CPAR Health sia 10 su 10 e che l'uscita da CPAR CLI sia corretta.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
Passaggio 3.Eseguire il comando netstat | diametro grep e verificare che tutte le connessioni DRA siano stabilite.
L'output riportato di seguito è relativo a un ambiente in cui sono previsti collegamenti con diametro. Se vengono visualizzati meno collegamenti, si tratta di una disconnessione da DRA che deve essere analizzata.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Passaggio 4. Verificare che nel registro TPS siano visualizzate le richieste elaborate da CPAR. I valori evidenziati rappresentano i TPS e quelli a cui dobbiamo prestare attenzione.
Il valore di TPS non deve superare 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Passaggio 5.Cercare eventuali messaggi "error" o "alarm" in name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Passaggio 6.Verificare la quantità di memoria utilizzata dal processo CPAR utilizzando il seguente comando:
inizio | raggio grep
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Il valore evidenziato deve essere inferiore a: 7 Gb, il massimo consentito a livello di applicazione.
Sostituzione della scheda madre in OSD Compute Node
Prima dell'attività, le VM ospitate nel nodo Calcola vengono spente e il CEPH viene messo in modalità manutenzione. Una volta sostituita la scheda madre, le VM vengono ripristinate e CEPH viene disattivato dalla modalità di manutenzione.
Identificare le VM ospitate nel nodo di calcolo Osd
Identificare le VM ospitate nel server di elaborazione OSD.
[stack@director ~]$ nova list --field name,host | grep osd-compute-0 | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
Backup: Processo snapshot
Arresto applicazione CPAR
Passaggio 1. Aprire un client ssh connesso alla rete e connettersi all'istanza CPAR.
È importante non arrestare tutte e 4 le istanze AAA all'interno di un sito contemporaneamente, farlo uno alla volta.
Passaggio 2.Arrestare l'applicazione CPAR con questo comando:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
Nota: Se un utente ha lasciato aperta una sessione CLI, il comando arserver stop non funziona e viene visualizzato il seguente messaggio:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
In questo esempio, è necessario terminare il processo evidenziato con ID 2903 prima di poter arrestare CPAR. In questo caso, terminare il processo con questo comando:
kill -9 *process_id*
Ripetere quindi il punto 1.
Passaggio 3.Verificare che l'applicazione CPAR sia stata effettivamente chiusa con questo comando:
/opt/CSCOar/bin/arstatus
Vengono visualizzati i seguenti messaggi:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
Attività snapshot VM
Passaggio 1.Immettere il sito Web della GUI Horizon corrispondente al Sito (Città) su cui si sta lavorando.
Quando si accede a Orizzonte, viene osservata l'immagine mostrata:
Passaggio 2. Passare a Progetto > Istanze, come mostrato nell'immagine.
Se l'utente utilizzato era CPAR, in questo menu vengono visualizzate solo le 4 istanze AAA.
Passaggio 3.Chiudere solo un'istanza alla volta. Ripetere l'intero processo in questo documento.
Per arrestare la VM, passare a Azioni > Arresta istanza e confermare la selezione.

Passaggio 4.Verificare che l'istanza sia stata effettivamente chiusa controllando le opzioni Status = Shutoff e Power State = Shut Down.
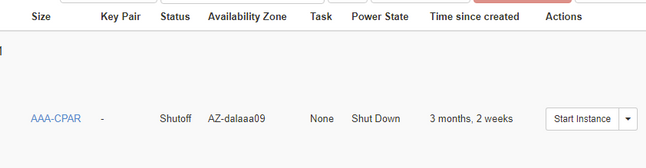
Questo passaggio termina il processo di chiusura CPAR.
Snapshot VM
Una volta disattivate le VM CPAR, le istantanee possono essere eseguite in parallelo, in quanto appartengono a computer indipendenti.
I quattro file QCOW2 vengono creati in parallelo.
Eseguire un'istantanea di ogni istanza AAA (25 minuti -1 ora) (25 minuti per le istanze che hanno utilizzato un'immagine qws come origine e 1 ora per le istanze che utilizzano un'immagine raw come origine)
Passaggio 1. Accedere all'interfaccia utente HorizonGUI del POD Openstack.
Passaggio 2. Una volta eseguito l'accesso, passare alla sezione Progetto > Calcola > Istanze nel menu superiore e cercare le istanze AAA.
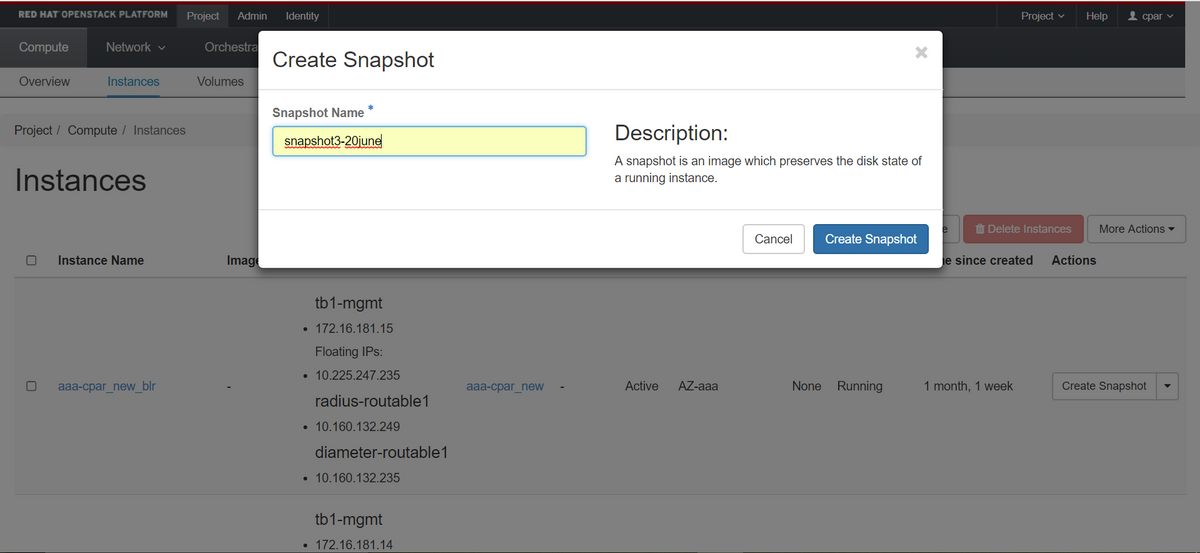
Passaggio 3. Fare clic sul pulsante Crea snapshot per procedere con la creazione dello snapshot (questa operazione deve essere eseguita sull'istanza AAA corrispondente).
Passaggio 4. Una volta eseguita l'istantanea, passare al menu IMAGES (IMMAGINI) e verificare che tutte le operazioni siano completate e che non vengano segnalati problemi.
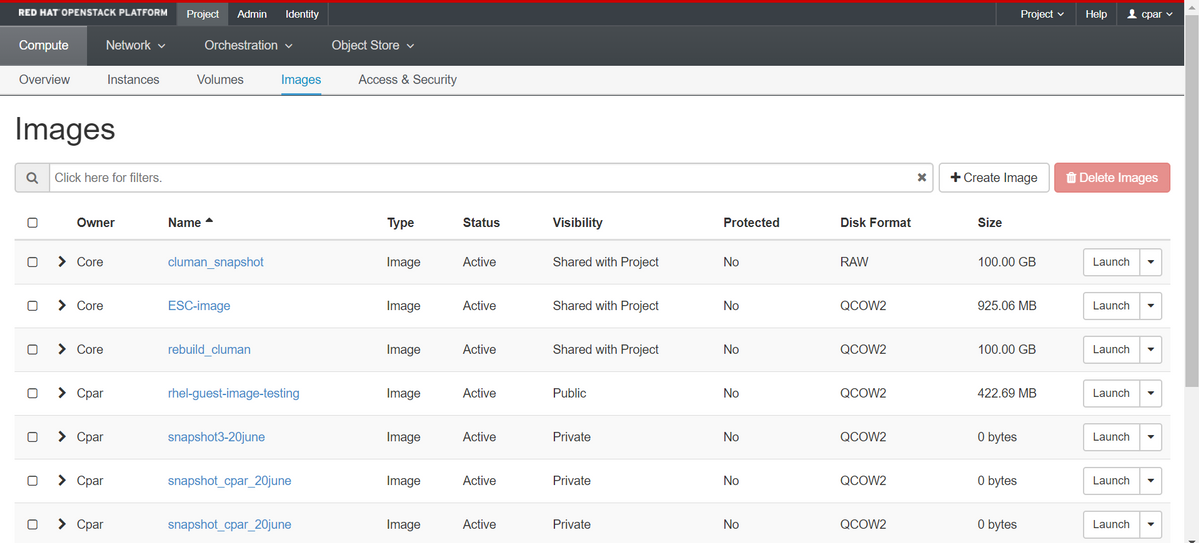
Passaggio 5. Il passaggio successivo consiste nel scaricare la copia istantanea in formato QCOW2 e trasferirla in un'entità remota nel caso in cui l'OSPD venga perso durante questo processo. A tale scopo, identificare la copia istantanea con questo comando glance image-list a livello OSPD.
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
Passaggio 6. Una volta identificata la copia istantanea da scaricare (in questo caso sarà quella contrassegnata in verde sopra), scaricarla ora in formato QCOW2 con questo comando glance image-download come mostrato di seguito.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- Il simbolo "&" invia il processo in background. Il completamento di questa operazione richiederà del tempo. Al termine, l'immagine può essere individuata nella directory /tmp.
- Quando si invia il processo in background, se la connettività viene persa, anche il processo viene interrotto.
- Eseguire il comando "diswn -h" in modo che, in caso di perdita della connessione SSH, il processo venga eseguito e completato sull'OSPD.
7. Al termine del processo di download, è necessario eseguire un processo di compressione poiché lo snapshot può essere riempito con ZEROES a causa di processi, task e file temporanei gestiti dal sistema operativo. Il comando da utilizzare per la compressione dei file è virtualizzato.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
Questo processo richiede un certo tempo (circa 10-15 minuti). Al termine, il file risultante deve essere trasferito a un'entità esterna come specificato nel passo successivo.
Per ottenere questo risultato, è necessario verificare l'integrità del file, eseguire il comando successivo e cercare l'attributo "corrupt" alla fine dell'output.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
Per evitare un problema di perdita dell'OSPD, è necessario trasferire lo snapshot creato di recente in formato QCOW2 a un'entità esterna. Prima di iniziare il trasferimento dei file, è necessario verificare se la destinazione dispone di spazio sufficiente su disco. Per verificare lo spazio di memoria, usare il comando "df -kh". È consigliabile trasferirla temporaneamente nell'OSPD di un altro sito utilizzando SFTP "sftproot@x.x.x.x", dove x.x.x.x è l'IP di un OSPD remoto. Per velocizzare il trasferimento, la destinazione può essere inviata a più OSPD. Allo stesso modo, è possibile utilizzare il seguente comando scp *name_of_the_file*.qws2 root@ x.x.x.x:/tmp (dove x.x.x.x è l'indirizzo IP di un OSPD remoto) per trasferire il file in un altro OSPD.
Metti CEPH in modalità di manutenzione
Passaggio 1. Verificare che lo stato dell'albero di ceph osd sia attivo nel server
[heat-admin@pod2-stack-osd-compute-0 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod2-stack-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod2-stack-osd-compute-1
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod2-stack-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
Passaggio 2. Accedere al nodo di calcolo OSD e impostare CEPH in modalità di manutenzione.
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e79: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v22844323: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3858 kB/s wr, 0 op/s rd, 546 op/s wr
Nota: Quando il CEPH viene rimosso, VNF HD RAID entra nello stato Degraded ma hd-disk deve ancora essere accessibile
Spegnimento regolare
Spegni nodo
- Per spegnere l'istanza: nova stop <NOME_ISTANZA>
- Viene visualizzato il nome dell'istanza con lo stato Shutoff.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
Sostituisci scheda madre
Per la sostituzione della scheda madre in un server UCS C240 M4, consultare la Guida all'installazione e all'assistenza del server Cisco UCS C240 M4
- Accedere al server utilizzando l'indirizzo IP CIMC.
- Eseguire l'aggiornamento del BIOS se il firmware non è conforme alla versione consigliata utilizzata in precedenza. La procedura per l'aggiornamento del BIOS è illustrata di seguito: Cisco UCS C-Series Rack-Mount Server BIOS Upgrade Guide
Sposta CEPH fuori dalla modalità di manutenzione
Accedere al nodo di calcolo OSD e spostare CEPH fuori dalla modalità di manutenzione.
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e81: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v22844355: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3658 kB/s wr, 0 op/s rd, 502 op/s wr
Ripristino delle VM
Ripristino di un'istanza tramite snapshot
Processo di ripristino:
È possibile ridistribuire l'istanza precedente con l'istantanea eseguita nei passaggi precedenti.
Passaggio 1 [FACOLTATIVO].Se non è disponibile alcuna copia istantanea VM precedente, collegarsi al nodo OSPD in cui è stato inviato il backup e reindirizzarlo al nodo OSPD originale. Utilizzando "sftproot@x.x.x.x" dove x.x.x.x è l'IP dell'OSPD originale. Salvare il file snapshot nella directory /tmp.
Passaggio 2.Connettersi al nodo OSPD in cui viene ridistribuita l'istanza.

Originare le variabili di ambiente con questo comando:
# source /home/stack/pod1-stackrc-Core-CPAR
Passaggio 3.Per utilizzare l'istantanea come immagine è necessario caricarla all'orizzonte come tale. A tale scopo, utilizzare il comando successivo.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
Il processo è all'orizzonte.

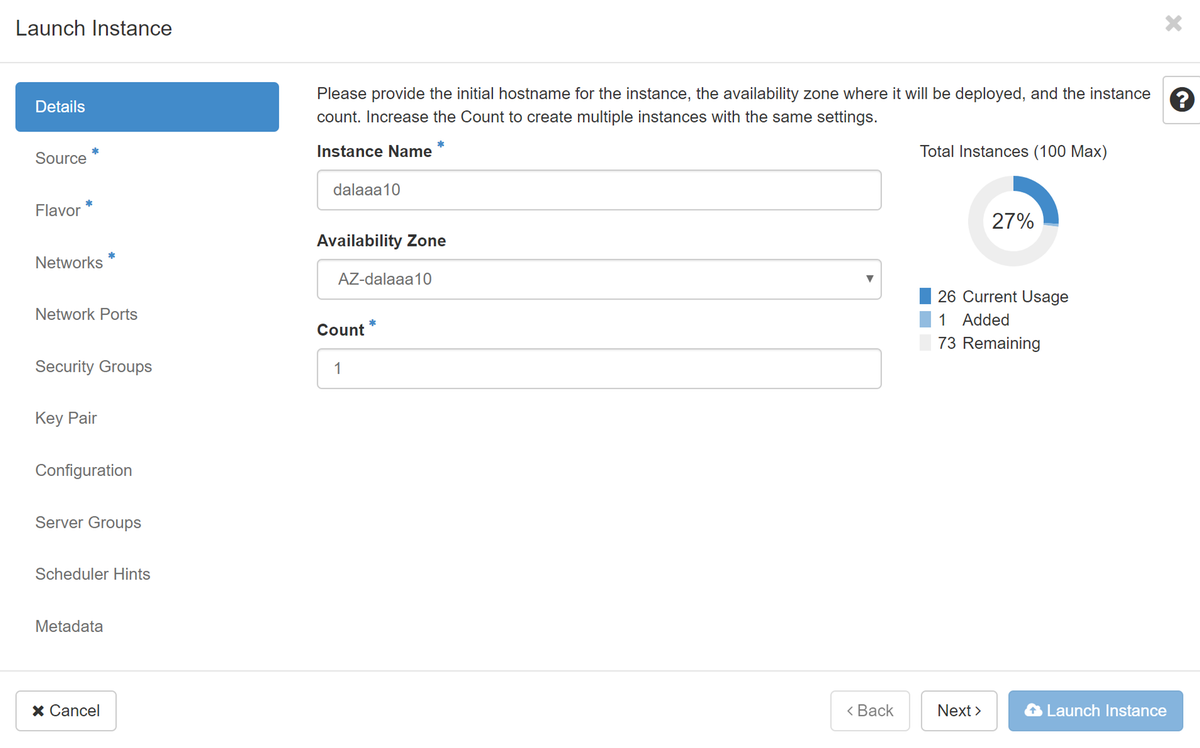
Passaggio 4.In Orizzonte, selezionare Progetto > Istanze e fare clic su Avvia istanza.

Passaggio 5.Immettere il nome dell'istanza e scegliere la zona di disponibilità.
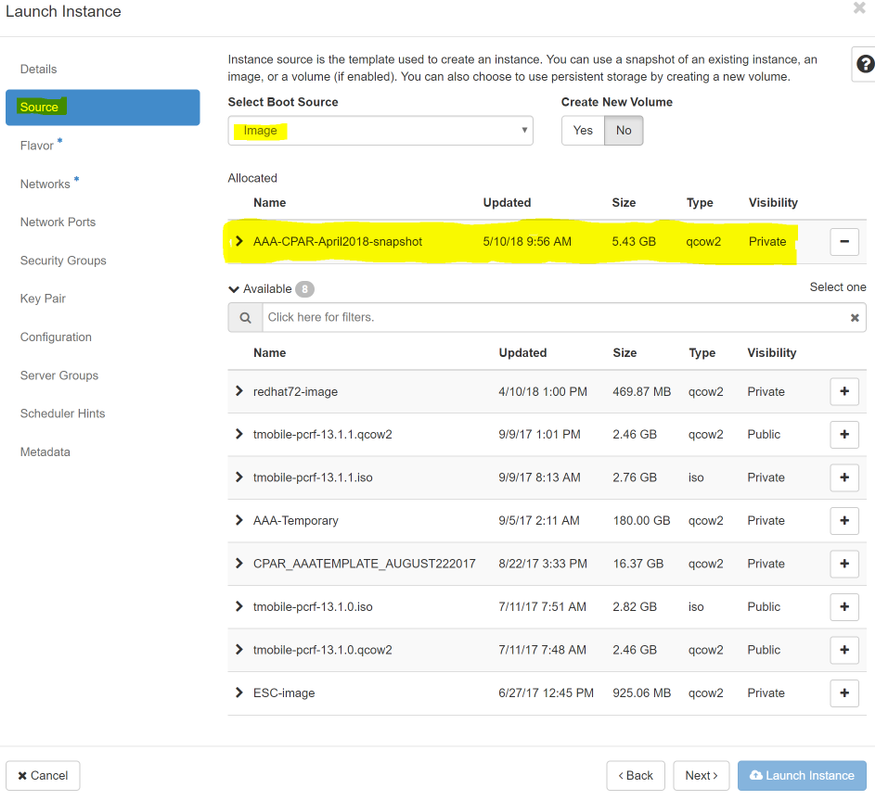
Passaggio 6.Nella scheda Origine, scegliere l'immagine per creare l'istanza. Nel menu Select Boot Source (Seleziona origine di avvio) select image (Seleziona immagine), viene visualizzato un elenco di immagini. Selezionare l'immagine caricata in precedenza facendo clic sul segno +.
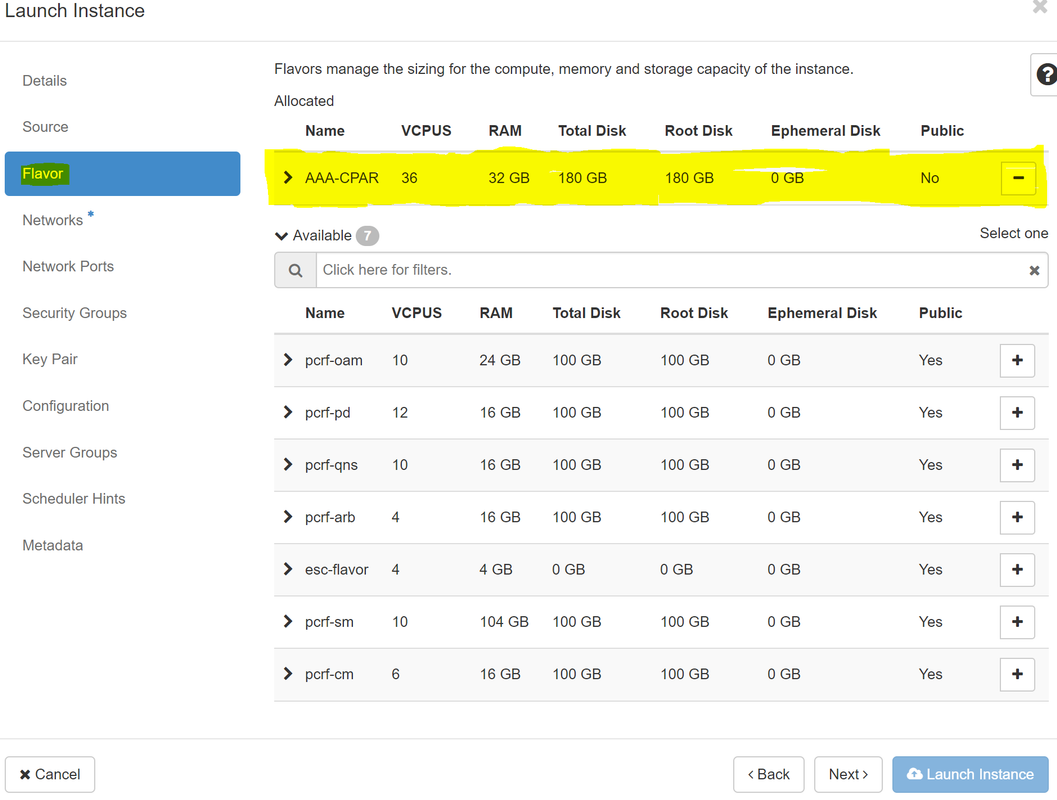
Passaggio 7.Nella scheda Gusto, scegliere il sapore AAA facendo clic sul segno +.
Passaggio 8.Infine, passare alla scheda Rete e scegliere le reti necessarie all'istanza facendo clic sul segno +. In questo caso, selezionare diametralmente-definibile1, radius-routable1 e tb1-mgmt.
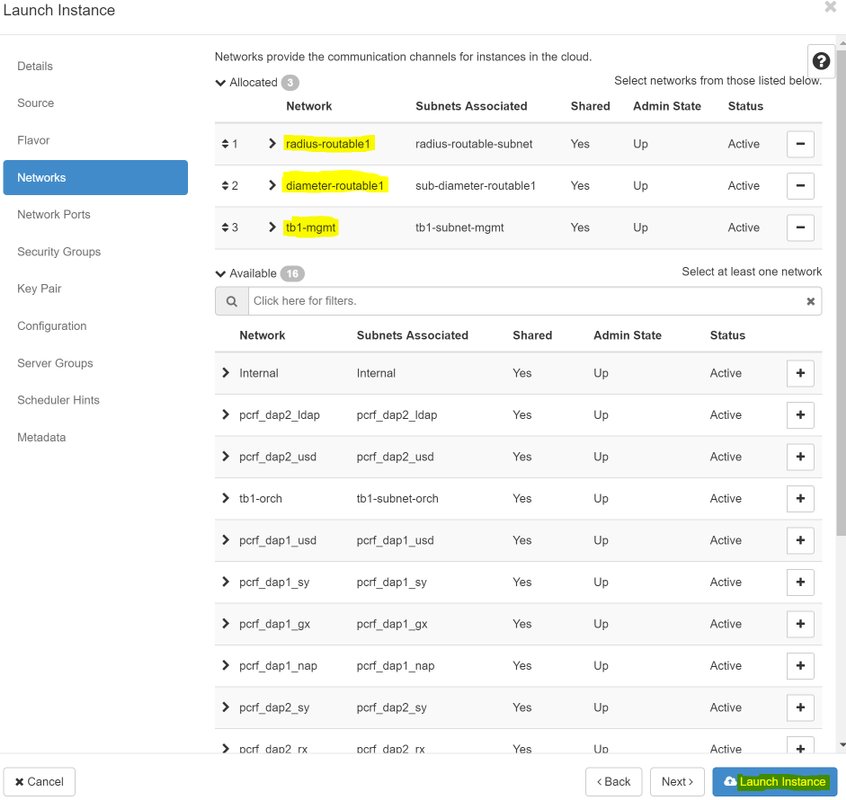
Passaggio 9. Infine, fare clic su Avvia istanza per crearla. I progressi possono essere monitorati in Orizzonte:
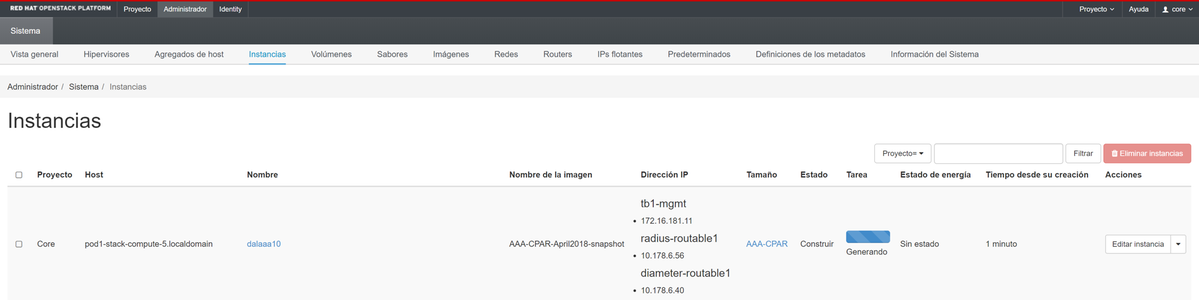
Dopo alcuni minuti, l'istanza è completamente distribuita e pronta per l'utilizzo.

Creazione e assegnazione di un indirizzo IP mobile
Un indirizzo IP mobile è un indirizzo instradabile, ossia è raggiungibile dall'esterno dell'architettura Ultra M/Openstack e può comunicare con altri nodi dalla rete.
Passaggio 1. Nel menu in alto Orizzonte, selezionare Admin > Floating IPs.
Passaggio 2.Fare clic sul pulsante AllocateIP to Project.
Passaggio 3. Nella finestra Alloca IP mobile, selezionare il pool a cui appartiene il nuovo IP mobile, il progetto a cui verrà assegnato e il nuovo indirizzo IP mobile.
Ad esempio:
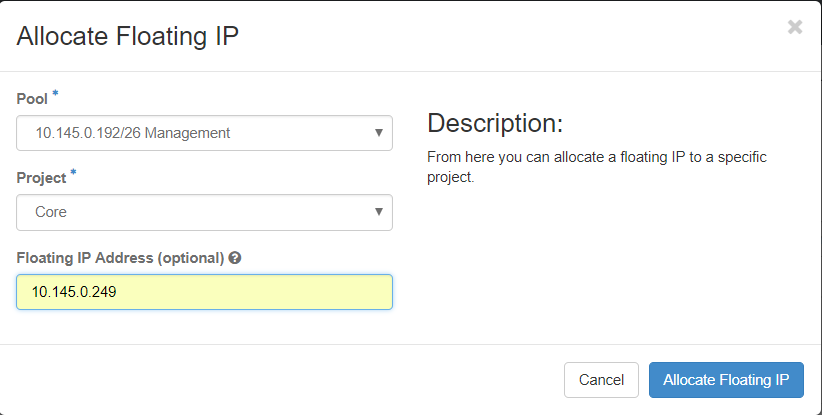
Passaggio 4. Fare clic sul pulsante AllocateFloating IP.
Passaggio 5. Nel menu in alto Orizzonte, passare a Progetto > Istanze.
Passaggio 6. Nella colonna Action (Azione) fare clic sulla freccia rivolta verso il basso nel pulsante Create Snapshotbutton per visualizzare un menu. SelezionareAssocia IP mobile.
Passaggio 7. Selezionare l'indirizzo IP mobile corrispondente che si desidera utilizzare nel campo IP Address, quindi scegliere l'interfaccia di gestione corrispondente (eth0) dalla nuova istanza in cui l'IP mobile verrà assegnato alla porta da associare. Fare riferimento all'immagine seguente come esempio di questa procedura.
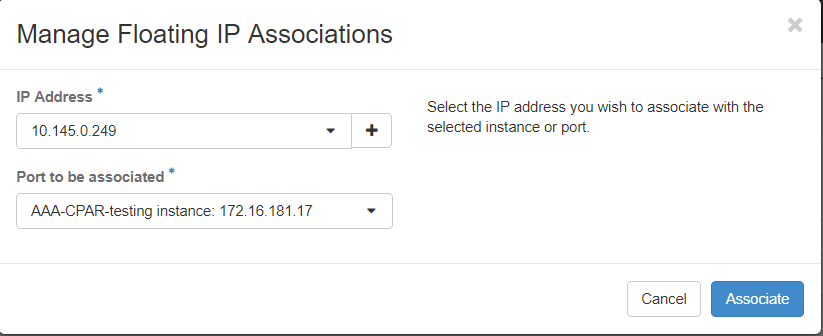
Passaggio 8.Infine, fare clic sul pulsante Associate.
Abilitazione SSH
Passaggio 1.Nel menu in alto Orizzonte, selezionate Progetto > Varianti.
Passaggio 2.Fare clic sul nome dell'istanza o della macchina virtuale creata in sectionLanciare una nuova istanza.
Passaggio 3.Fare clic su Consoletab. Viene visualizzata la CLI della VM.
Passaggio 4. Dopo aver visualizzato la CLI, immettere le credenziali di accesso appropriate:
Nome utente:root
Password:cisco123
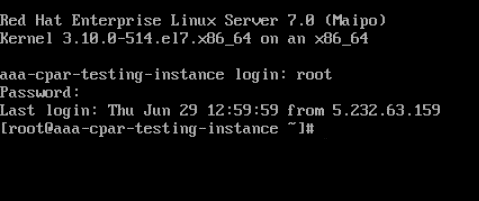
Passaggio 5.Nella CLI, immettere il comando vi /etc/ssh/sshd_configper modificare la configurazione ssh.
Passaggio 6. Una volta aperto il file di configurazione ssh, premere Invio per modificare il file. Cercare quindi la sezione visualizzata e modificare la prima riga da PasswordAuthentication a PasswordAuthentication yes.

Passaggio 7.Premere ESC e immettere:wq!per salvare le modifiche al file sshd_config.
Passaggio 8. Eseguire il comando sshd restart.
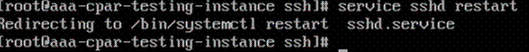
Passaggio 9. Per verificare che le modifiche alla configurazione SSH siano state applicate correttamente, aprire un client SSH e provare a stabilire una connessione protetta remota usando l'IP mobile assegnato all'istanza (ad esempio 10.145.0.249) e la radice dell'utente.
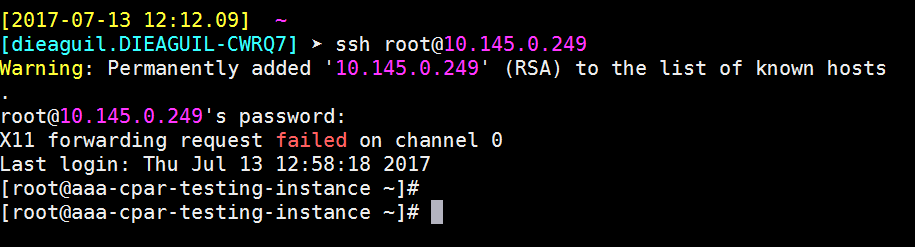
Stabilire una sessione SSH
Aprire una sessione SSH utilizzando l'indirizzo IP della macchina virtuale/server corrispondente in cui è installata l'applicazione.

Avvio istanza CPAR
Una volta completata l'attività, sarà possibile ristabilire i servizi CPAR nel Sito che è stato chiuso.
- Accedere nuovamente a Orizzonte, selezionare Progetto > Istanza > Avvia istanza.
- Verificare che lo stato dell'istanza sia attivo e che lo stato di alimentazione sia in esecuzione:
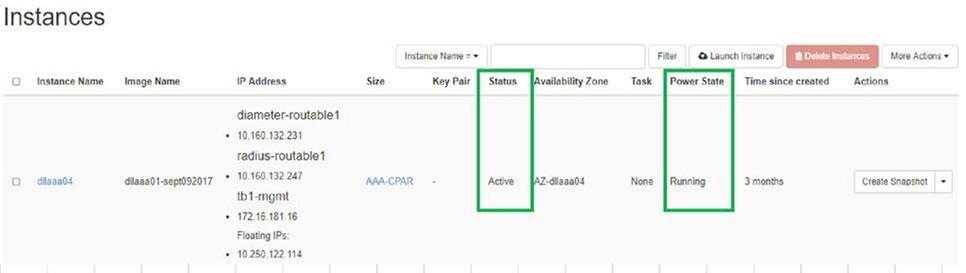
Controllo dello stato post-attività
Passaggio 1. Eseguire il comando /opt/CSCOar/bin/arstatus a livello di sistema operativo.
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Passaggio 2. Eseguire il comando /opt/CSCOar/bin/aregcmd a livello di sistema operativo e immettere le credenziali dell'amministratore. Verificare che CPAR Health sia 10 su 10 e che l'uscita da CPAR CLI sia corretta.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
Passaggio 3.Eseguire il comando netstat | diametro grep e verificare che tutte le connessioni DRA siano stabilite.
L'output qui menzionato è relativo a un ambiente in cui sono previsti collegamenti con diametro. Se vengono visualizzati meno collegamenti, si tratta di una disconnessione da DRA che deve essere analizzata.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Passaggio 4. Verificare che nel registro TPS siano visualizzate le richieste elaborate da CPAR. I valori evidenziati rappresentano i TPS e quelli a cui dobbiamo prestare attenzione.
Il valore di TPS non deve superare 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Passaggio 5.Cercare eventuali messaggi "error" o "alarm" in name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Passaggio 6.Verificare la quantità di memoria utilizzata dal processo CPAR con questo comando:
inizio | raggio grep
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Il valore evidenziato deve essere inferiore a: 7 Gb, il massimo consentito a livello di applicazione.
Sostituzione della scheda madre nel nodo del controller
Verifica dello stato del controller e attiva la modalità di manutenzione per il cluster
Da OSPD, effettuare il login al controller e verificare che il pc sia in buono stato - tutti e tre i controller Online e galera mostrano tutti e tre i controller come Master.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:02:52 2018Last change: Mon Jul 2 12:49:52 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Attivare la modalità manutenzione per il cluster
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:10 2018Last change: Fri Jul 6 09:03:06 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Node pod2-stack-controller-0: standby
Online: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-1 ]
Stopped: [ pod2-stack-controller-0 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Sostituisci scheda madre
Per informazioni sulla procedura di sostituzione della scheda madre in un server UCS C240 M4, consultare la Guida all'installazione e all'assistenza del server Cisco UCS C240 M4
- Accedere al server utilizzando l'indirizzo IP CIMC.
- Eseguire l'aggiornamento del BIOS se il firmware non è conforme alla versione consigliata utilizzata in precedenza. Le fasi per l'aggiornamento del BIOS sono riportate di seguito:
Guida all'aggiornamento del BIOS dei server con montaggio in rack Cisco UCS serie C
Ripristina stato cluster
Accedere al controller interessato, rimuovere la modalità standby impostando unstandby. Verificare che il controller sia online con il cluster e che galera mostri tutti e tre i controller come Master. L'operazione potrebbe richiedere alcuni minuti.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:37 2018Last change: Fri Jul 6 09:03:35 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Contributo dei tecnici Cisco
- Karthikeyan DachanamoorthyCisco Advanced Services
- Harshita BhardwajCisco Advanced Services
 Feedback
Feedback