Introduction
Ce document décrit la procédure de restauration de Cluster Manager à partir du serveur de création dans la configuration de la plate-forme de déploiement natif cloud (CNDP).
Conditions préalables
Exigences
Cisco vous recommande de prendre connaissance des rubriques suivantes :
- Infrastructure Cisco Subscriber Microservices (SMI)
- Architecture 5G CNDP ou SMI-Bare-metal (BM)
- DRBD (Distributed Replicated Block Device)
Composants utilisés
Les informations contenues dans ce document sont basées sur les versions de matériel et de logiciel suivantes :
- SMI 2020.02.2.35
- Kubernetes v1.21.0
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Informations générales
Qu'est-ce que SMI Cluster Manager ?
Un gestionnaire de cluster est un cluster de test à 2 noeuds utilisé comme point initial pour le déploiement de cluster de plan de contrôle et de plan utilisateur. Il exécute un cluster Kubernetes à noeud unique et un ensemble de POD qui sont responsables de la configuration complète du cluster. Seul le gestionnaire de cluster principal est actif et le secondaire prend le relais uniquement en cas de panne ou arrêté manuellement pour maintenance.
Qu'est-ce qu'un serveur Inception ?
Ce noeud effectue la gestion du cycle de vie du Gestionnaire de cluster (CM) sous-jacent et à partir de là, vous pouvez envoyer la configuration Day0.
Ce serveur est généralement déployé au niveau de la région ou dans le même data center que la fonction d'orchestration de niveau supérieur (par exemple NSO) et s'exécute généralement en tant que machine virtuelle.
Problème
Le gestionnaire de cluster est hébergé dans un cluster à 2 noeuds avec DRBD (Distributed Replicated Block Device) et est conservé comme principal et secondaire du gestionnaire de cluster. Dans ce cas, Cluster Manager secondaire passe automatiquement à l'état d'arrêt lors de l'initialisation/installation du système d'exploitation dans UCS, ce qui indique que le système d'exploitation est corrompu.
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 WFConnection Primary/Unknown UpToDate/DUnknown /mnt/stateful_partition ext4 568G 369G 170G 69%
Procédure de maintenance
Ce processus permet de réinstaller le système d'exploitation sur le serveur CM.
Identifier les hôtes
Connectez-vous à Cluster-Manager et identifiez les hôtes :
cloud-user@POD-NAME-cm-primary:~$ cat /etc/hosts | grep 'deployer-cm'
127.X.X.X POD-NAME-cm-primary POD-NAME-cm-primary
X.X.X.X POD-NAME-cm-primary
X.X.X.Y POD-NAME-cm-secondary
Identifier les détails du cluster à partir du serveur d'inception
Connectez-vous au serveur Inception, accédez à Deployer et vérifiez le nom du cluster avec hosts-IP à partir de Cluster-Manager.
Après avoir réussi à se connecter au serveur de création, connectez-vous au centre des opérations comme indiqué ici.
user@inception-server: ~$ ssh -p 2022 admin@localhost
Vérifiez le nom du cluster à partir de Cluster Manager SSH-IP (ssh-ip = Noeud SSH IP ip-address = ucs-server cimc ip-address).
[inception-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | tab
SSH
NAME NAME IP SSH IP IP ADDRESS
------------------------------------------------------------------------------
POD-NAME-deployer cm-primary - X.X.X.X 10.X.X.X ---> Verify Name and SSH IP if Cluster is part of inception server SMI.
cm-secondary - X.X.X.Y 10.X.X.Y
Vérifiez la configuration du cluster cible.
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME-deployer
Retirez le lecteur virtuel pour effacer le système d'exploitation du serveur
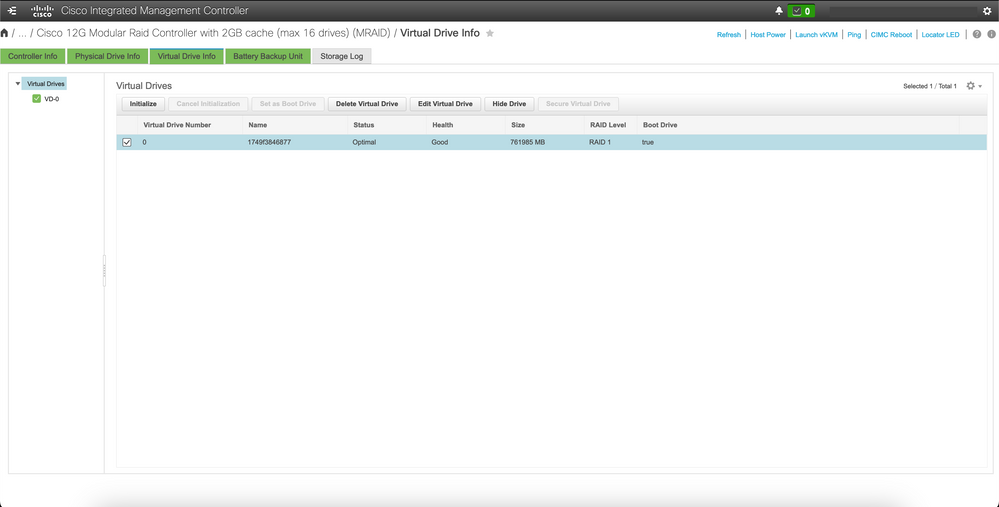
Connectez-vous au CIMC de l'hôte concerné, effacez le lecteur de démarrage et supprimez le lecteur virtuel (VD).
a) CIMC > Storage > Cisco 12G Modular Raid Controller > Storage Log > Clear Boot Drive
b) CIMC > Storage > Cisco 12G Modular Raid Controller > Virtual drive > Select the virtual drive > Delete Virtual Drive
Exécuter la synchronisation du cluster
Exécutez la synchronisation de cluster par défaut pour Cluster-Manager à partir du serveur de création.
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
Si la synchronisation de cluster par défaut échoue, effectuez la synchronisation de cluster avec l'option de redéploiement force-vm pour une réinstallation complète (l'activité de synchronisation de cluster peut prendre environ 45 à 55 minutes, cela dépend du nombre de noeuds hébergés sur le cluster)
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true force-vm-redeploy true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
Surveiller les journaux de synchronisation de cluster
[inception-server] SMI Cluster Deployer# monitor sync-logs POD-NAME-deployer
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Cluster name: POD-NAME
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Force VM Redeploy: true
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: Force partition Redeploy: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: reset_k8s_nodes: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: purge_data_disks: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: upgrade_strategy: auto
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: sync_phase: all
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: debug: true
...
...
...
Le serveur est réapprovisionné et installé par une synchronisation de cluster réussie.
PLAY RECAP *********************************************************************
cm-primary : ok=535 changed=250 unreachable=0 failed=0 skipped=832 rescued=0 ignored=0
cm-secondary : ok=299 changed=166 unreachable=0 failed=0 skipped=627 rescued=0 ignored=0
localhost : ok=59 changed=8 unreachable=0 failed=0 skipped=18 rescued=0 ignored=0
Thursday 23 February 2023 13:17:24 +0000 (0:00:00.109) 0:56:20.544 *****. ---> ~56 mins to complete cluster sync
===============================================================================
2023-02-23 13:17:24.539 DEBUG cluster_sync.POD-NAME: Cluster sync successful
2023-02-23 13:17:24.546 DEBUG cluster_sync.POD-NAME: Ansible sync done
2023-02-23 13:17:24.546 INFO cluster_sync.POD-NAME: _sync finished. Opening lock
Vérification
Vérifiez que le gestionnaire de cluster affecté est accessible et que DRBD présente les gestionnaires de cluster principal et secondaire à l'état UpToDate.
cloud-user@POD-NAME-cm-primary:~$ ping X.X.X.Y
PING X.X.X.Y (X.X.X.Y) 56(84) bytes of data.
64 bytes from X.X.X.Y: icmp_seq=1 ttl=64 time=0.221 ms
64 bytes from X.X.X.Y: icmp_seq=2 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=3 ttl=64 time=0.151 ms
64 bytes from X.X.X.Y: icmp_seq=4 ttl=64 time=0.154 ms
64 bytes from X.X.X.Y: icmp_seq=5 ttl=64 time=0.172 ms
64 bytes from X.X.X.Y: icmp_seq=6 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=7 ttl=64 time=0.174 ms
--- X.X.X.Y ping statistics ---
7 packets transmitted, 7 received, 0% packet loss, time 6150ms
rtt min/avg/max/mdev = 0.151/0.171/0.221/0.026 ms
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 Connected Primary/Secondary UpToDate/UpToDate /mnt/stateful_partition ext4 568G 17G 523G 4%
Le gestionnaire de cluster affecté est installé et reconfiguré sur le réseau.
2.2 Vérification du nom du cluster à partir du gestionnaire de cluster SSH-IP.
[foundation-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip | sélectionner des noeuds * ssh-ip | sélectionner les noeuds * ucs-server cimc ip-address | tabulation
SSH
NOM IP SSH IP ADRESSE IP
------------------------------------------------------------------------------
POD-NAME cm-primary - 192.X.X.X 10.192.X.X
cm-secondaire - 192.X.X.Y 10.192.X.Y
*SSH IP = Noeud SSH IP
*IP ADDRESS = ucs-server cimc ip-address
2.3 Vérifiez la configuration du cluster cible.
[creation-server] SMI Cluster Deployer# show running-config clusters POD-NAME Connectez-vous au serveur d'inception et accédez à Deployer et vérifiez le nom du cluster avec hosts-IP depuis Cluster-Manager. Connectez-vous au serveur d'inception, accédez à Déployeur et vérifiez le nom de cluster avec hosts-IP à partir de Cluster-Manager.
 Commentaires
Commentaires