Introduction
Ce document décrit le processus de redéploiement d'un noeud hors connexion dans les clusters Cisco Hyperflex.
Conditions préalables
Exigences
Ceci est pris en charge uniquement pour les clusters Hyperflex déployés à partir d'Intersight et à partir de la version 5.0(2b). Les clusters déployés via le programme d'installation Hyperflex et importés vers Intersight ne sont pas encore pris en charge pour cette fonctionnalité.
Type de scénarios pris en charge pour cette fonctionnalité Intersight :
- Cluster FI/standard, cluster Strech, cluster Edge et cluster DC-No-FI
- Clusters avec SED (disques durs auto-cryptés)
- Clusters déployés à partir d'Intersight uniquement
- Redéploiement d'ESXi et SCVM
- Redéploiement SCVM uniquement
Scénarios non pris en charge
- Clusters 1GbE HyperFlex Edge et Stretch.
- Clusters importés dans Intersight
Licences
Une licence Intersight Essentials ou supérieure est requise pour le redéploiement du noeud HyperFlex. Tous les serveurs du cluster HyperFlex doivent être revendiqués et configurés avec Intersight Essentials ou une licence supérieure.
Composants utilisés
- Cisco Intersight
- Cisco UCSM (en option)
- Serveurs Cisco UCS
- Cisco Hyperflex Cluster version 5.0(2c)
- VMware ESXi
- VMware vCenter
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Informations générales
Maintenir un cluster sain devient une priorité pour plusieurs raisons, mais la plus importante est la redondance pour préserver l'intégrité des données dans la solution de stockage Hypercoverge. Plusieurs scénarios nécessitent le redéploiement simultané d'ESXi et de SCVM (machine virtuelle de contrôleur de stockage), par exemple le remplacement du lecteur de démarrage dans des noeuds de convergence.
Pour les clusters déployés à partir d'Intersight, vous pouvez redéployer le SCVM pour le rajouter au cluster Hyperflex. Cet exercice peut désormais être exécuté sans l'assistance du TAC via Intersight.

Avertissement : il est important de souligner que le fait de ne pas effectuer ce processus correctement peut entraîner des problèmes inattendus dans les clusters, tels que des échecs de mises à niveau de cluster futures et des échecs d'extension de cluster.
Configuration
Dans cet exemple, nous utilisons un cluster de périphérie à 3 noeuds nommé Medellin, qui a corrompu le noeud 3 en raison d'une défaillance du disque M.2
D'Intersight, notre point de départ suppose que quelques aspects sont déjà couverts :
- M.2 Le stockage a déjà été remplacé
- La grappe Hyperflex est toujours défectueuse, car ce noeud est hors ligne
Validation hors connexion du noeud de cluster
Vous pouvez voir que le cluster n'est pas sain comme expliqué et vous devez récupérer le noeud qui est hors ligne maintenant que le problème M.2 a été corrigé
Dans Intersight, accédez à Infrastructure Service > Hyperflex Cluster > Overview > Events. Vous pouvez voir l'état de résilience
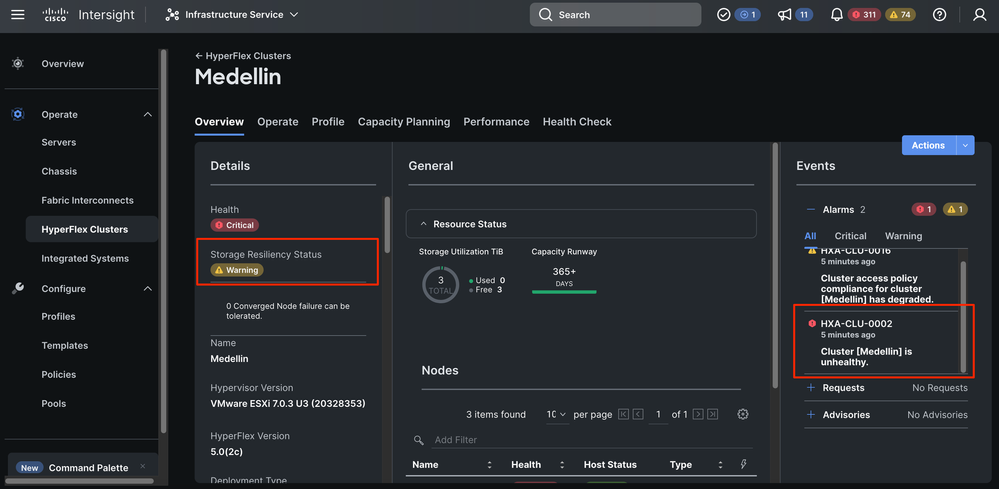
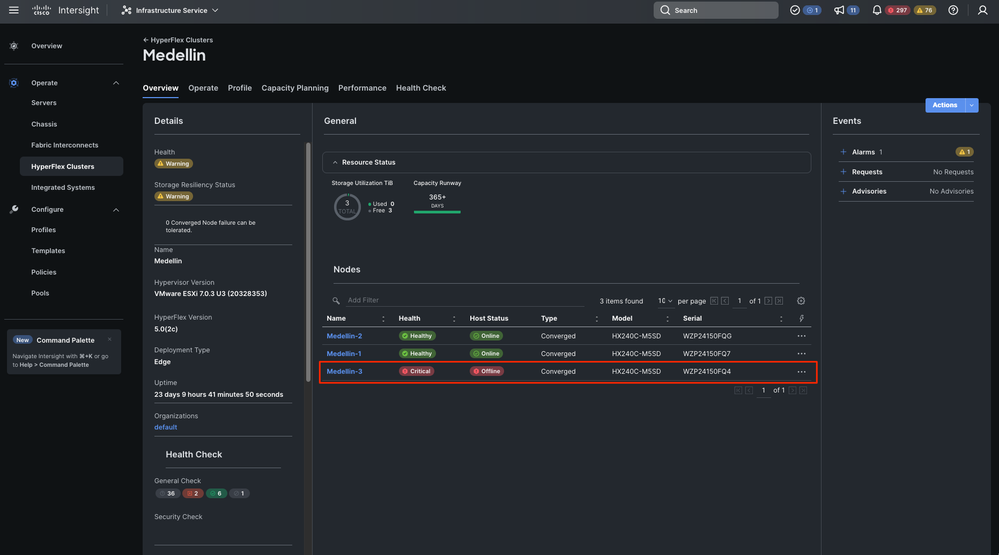
Dans le même onglet Overview, vous pouvez voir quel noeud spécifique est également hors connexion
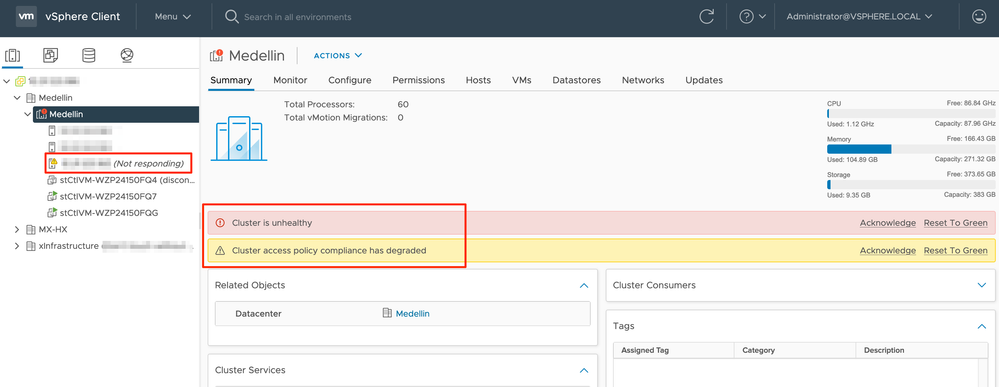
De vCenter, nous recevons également une alerte indiquant que le cluster n'est pas sain
Enfin, à partir de l'interface CLI, vous pouvez également évaluer l'état du cluster :
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : WARNING
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 0
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 30.4 GiB
Free Capacity : 3.0 TiB
Compression Savings : 62.06%
Deduplication Savings : 0.00%
Total Savings : 62.06%
# of Nodes Configured : 3
# of Nodes Online : 2
Data IP Address : 169.254.218.1
Resiliency Health : WARNING
Policy Compliance : NON_COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 0
# of persistent device failures tolerable : 1
# of cache device failures tolerable : 1
Zone Type : Unknown
All Flash : No
Redéploiement des étapes
Étape 1. Réinstallez le système d'exploitation ESXi. Pour cela, vous pouvez aller à Servers > Select the Server > Options (three dots) > Select Launch the KVM.
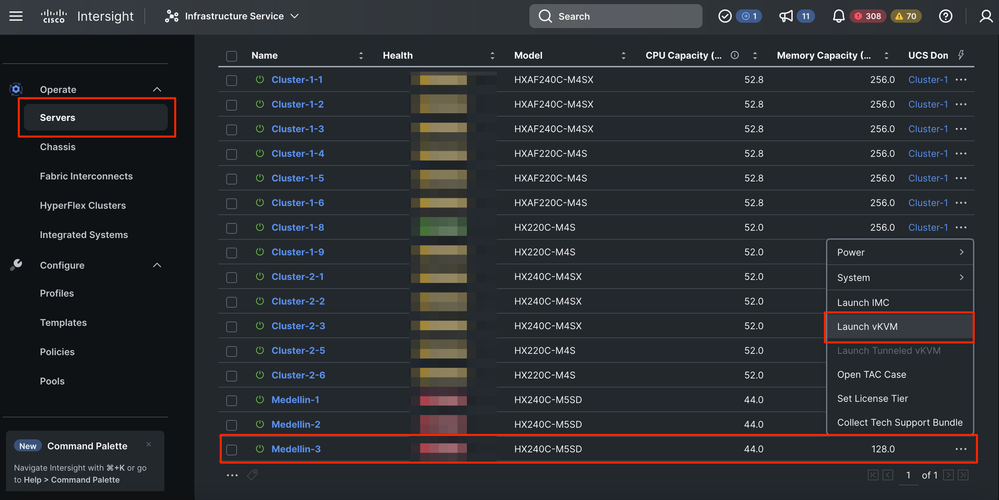
Attention : vous devez télécharger une image personnalisée de Cisco Hyperflex pour la même version d'ESXi que celle utilisée par les autres noeuds du cluster. Vous pouvez le télécharger ici
Une fois le KVM lancé, accédez à Virtual Media > Sélectionnez Activate Virtual Devices

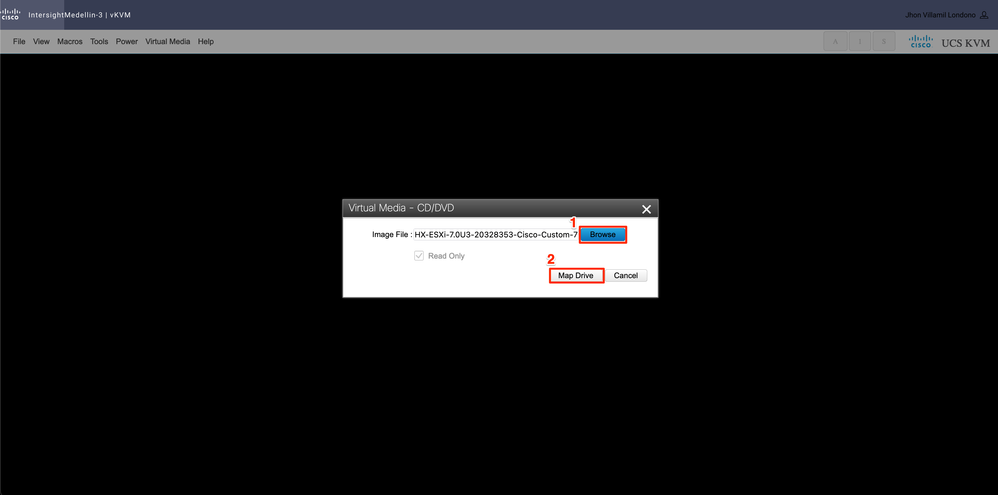
Sélectionnez ensuite Browse > Select the Hyperflex ESXi iso image from your local computer > Select Map Drive
Accédez à Power > selon l'état du serveur, sélectionnez Power on System ou Reset System ou Power Cycle System 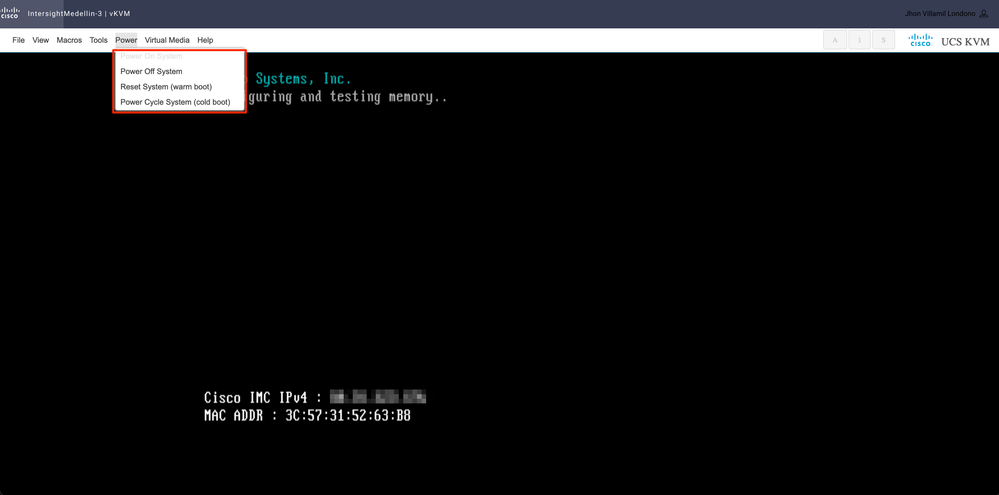
Conseil : Reset System (warm boot) redémarre le système sans le mettre hors tension, tandis que Power Cycle System (cold boot)désactive le système, puis le rallume. Dans ce scénario, SCVM étant corrompu et ESXi étant réinstallé, les deux options remplissent le même objectif
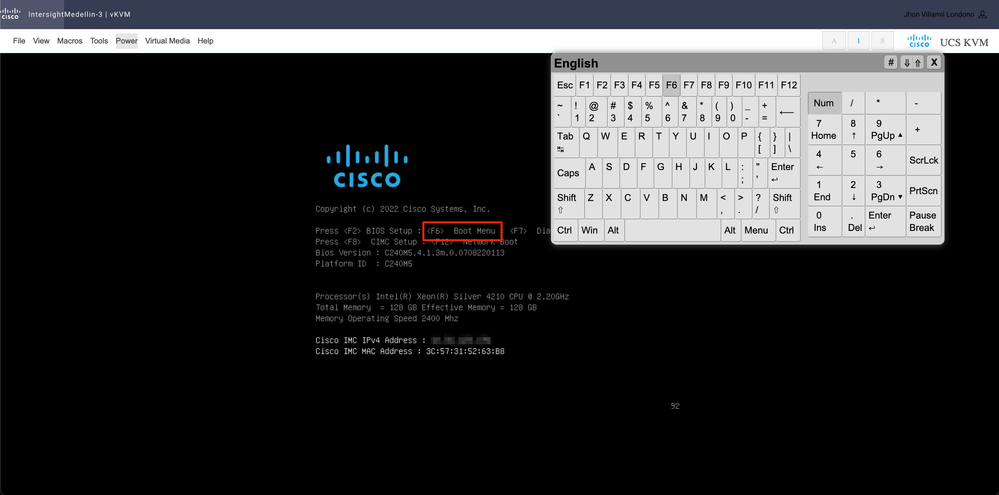
Vous devez démarrer le périphérique virtuel CD/DVD. Accédez à Tools > Select Keyboard > Lorsque vous voyez l'invite Boot Menu, appuyez sur F6
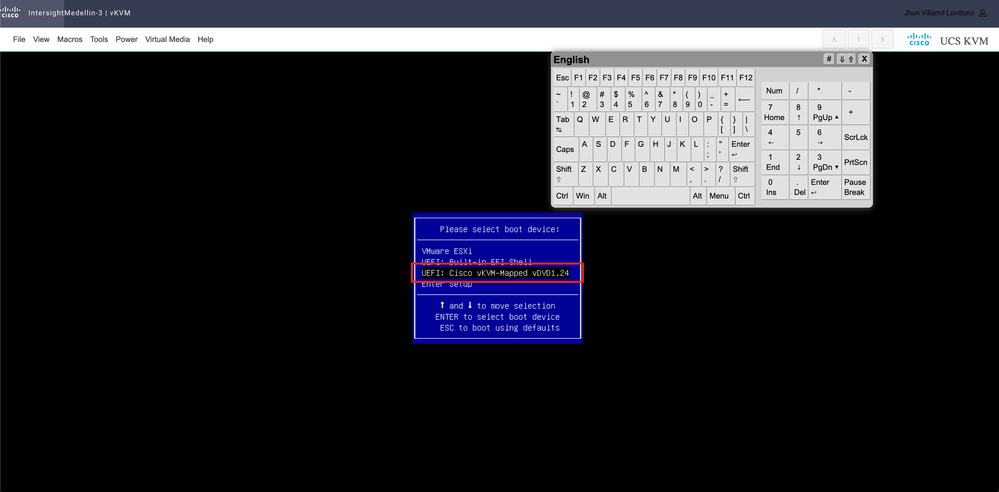
Vous accédez au menu d'amorçage et une fois là, sélectionnez Cisco vKVM-Mapped vDVD1.24 et appuyez sur Entrée
Sélectionnez J'ai lu l'avis ci-dessus et je souhaite continuer et appuyer sur Entrée
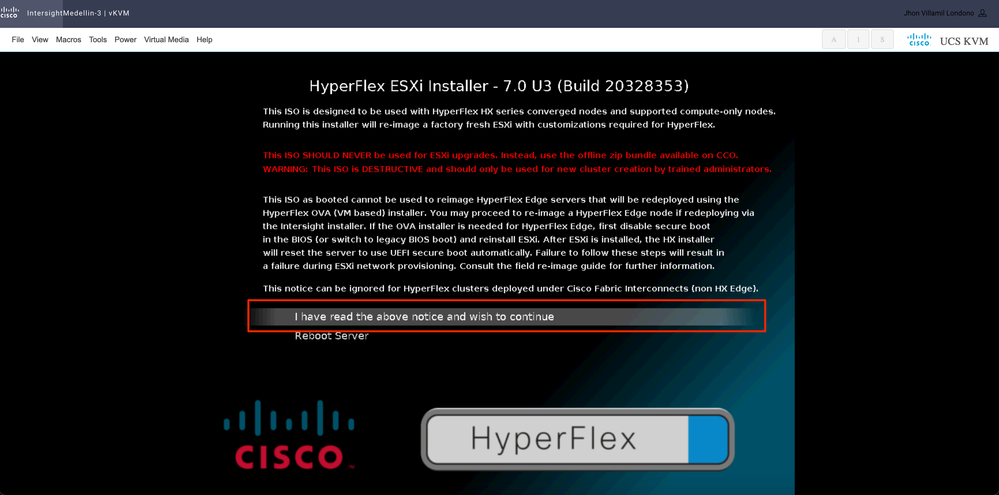
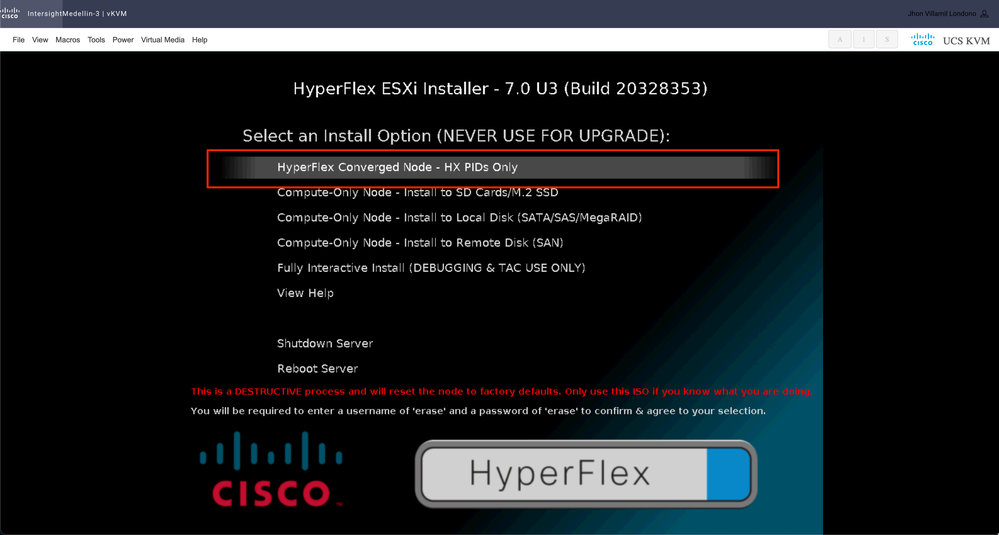
Régulièrement, vous voyez différentes options pour les noeuds de calcul en fonction du périphérique de démarrage spécifique utilisé et une autre option pour les noeuds de convergence qui est celle que vous devez sélectionner ici
Ensuite, vous êtes invité à saisir un nom d'utilisateur et un mot de passe. Tapez username erase > appuyez sur Entrée > Tapez password erase > appuyez sur Saisissez
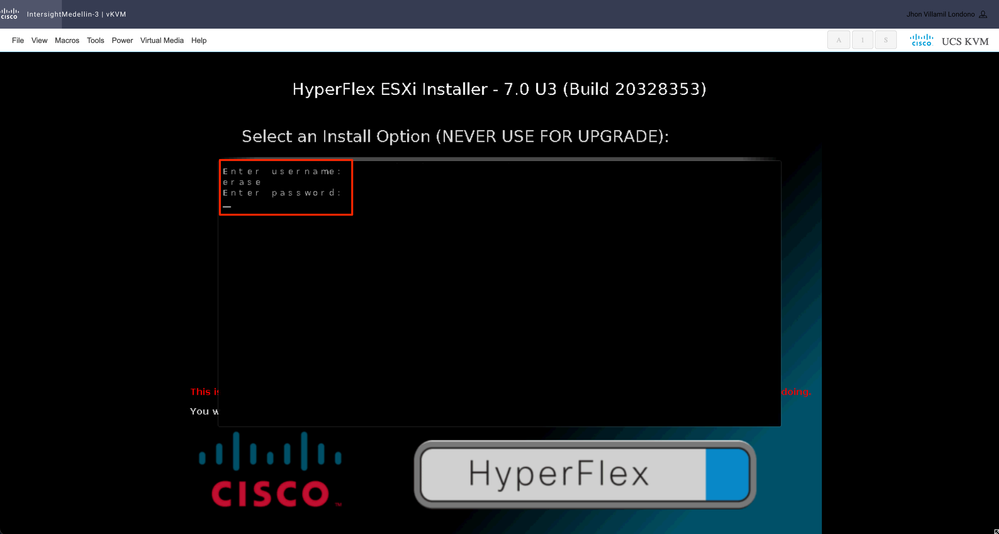
Remarque : si le mot de passe/nom d'utilisateur saisi est incorrect, vous êtes renvoyé d'une étape et vous pouvez réessayer
L'installation commence à ce stade et vous pouvez la surveiller via vKVM
Étape 2. Accédez à Infrastructure Service > Hyperflex Clusters > Sélectionnez votre cluster Hyperflex > Sélectionnez Actions > Sélectionnez Redéployer le noeud
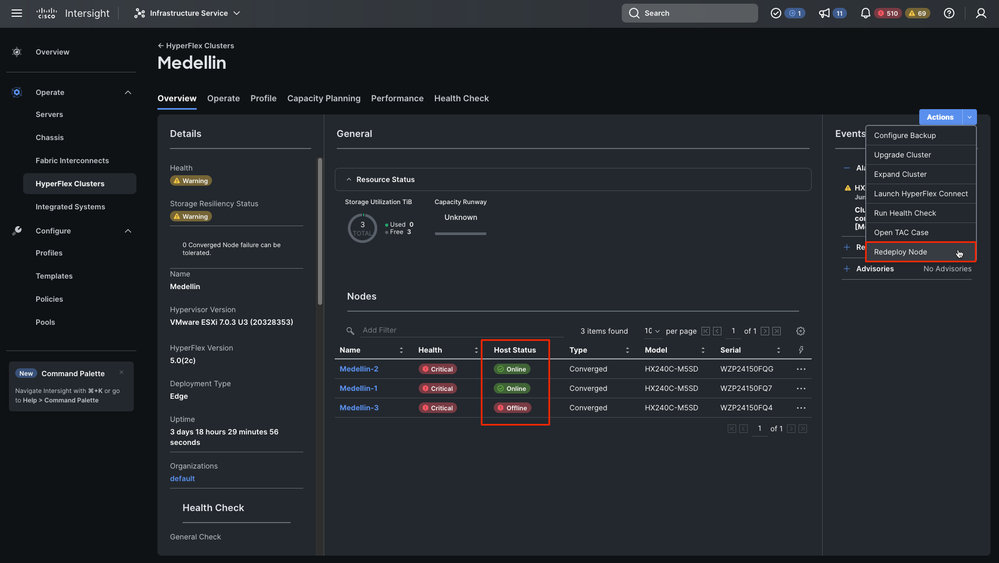

Conseil : si seul SCVM est corrompu et doit être réinstallé, vous devez éteindre le serveur avant de sélectionner Redéployer si vous ne rencontrez pas l'erreur « Redeploy Node ne pas pouvoir être déclenché car il n'y a pas d'hôtes hors ligne dans ce cluster. »
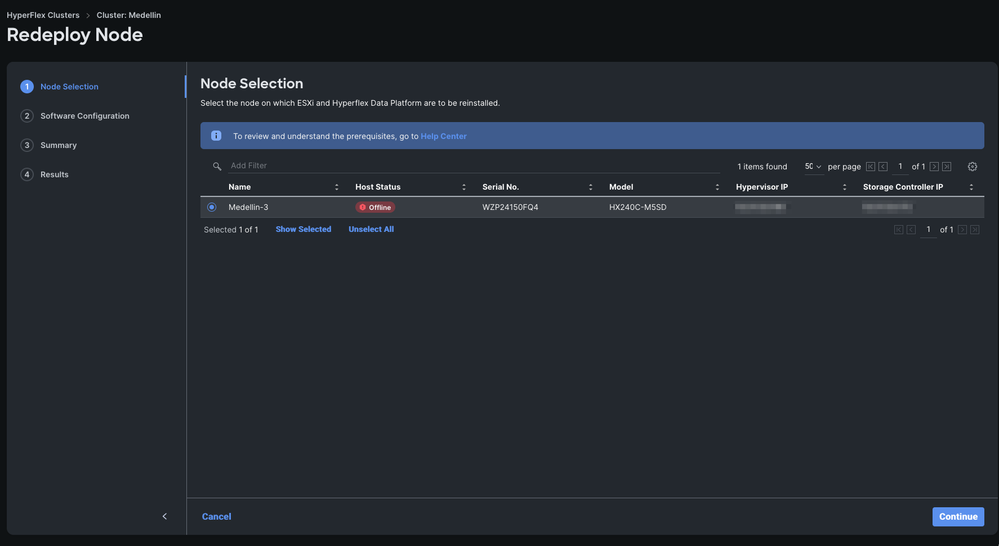
Étape 3. Sélectionnez le noeud hors connexion > Sélectionnez Continuer
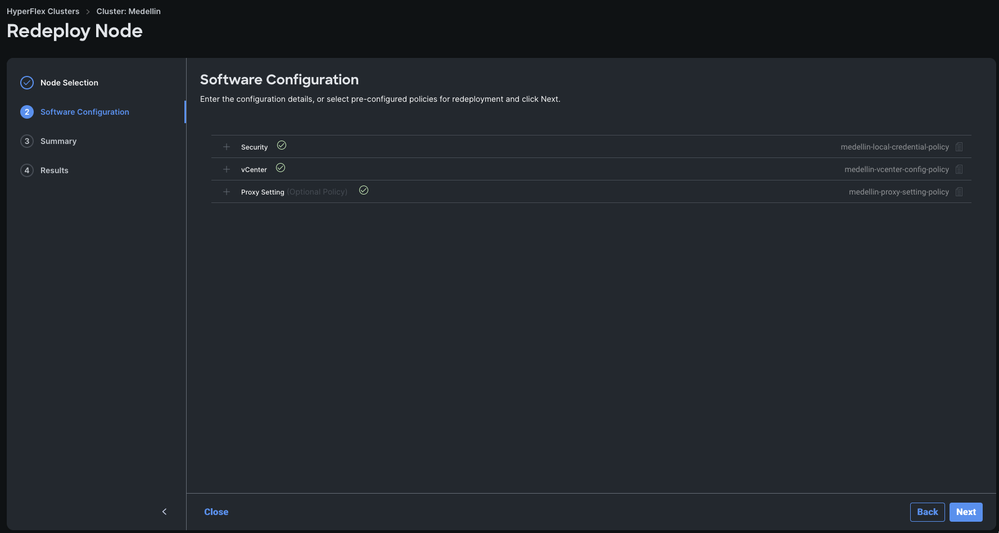
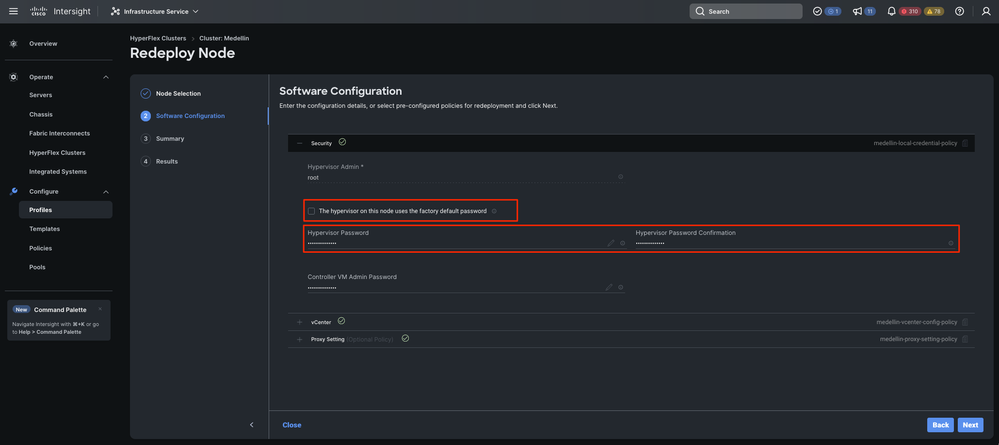
Étape 4. Vérifiez que les stratégies Security, vCenter et Proxy Settings correspondent au même cluster et sélectionnez Next
Cependant, si seul SCVM est redéployé et qu'ESXi est intact, vous devez désélectionner l'option « L'hyperviseur de ce noeud utilise le mot de passe par défaut » de la stratégie de sécurité et vous assurer que le mot de passe ESXi actuel est mis à jour avant de sélectionner Suivant
Étape 5. Sélectionnez Valider et redéployer
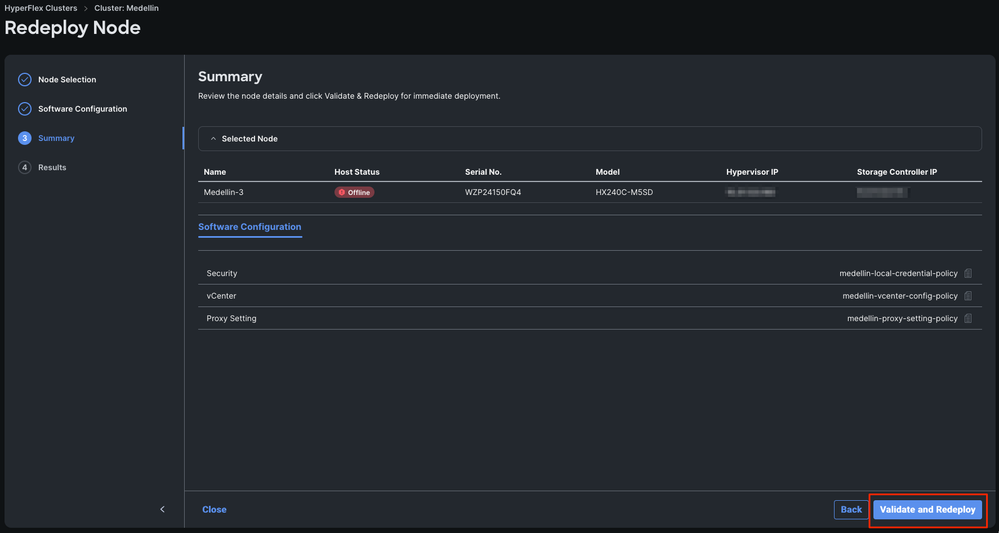
Étape 6. Attendez la fin du workflow
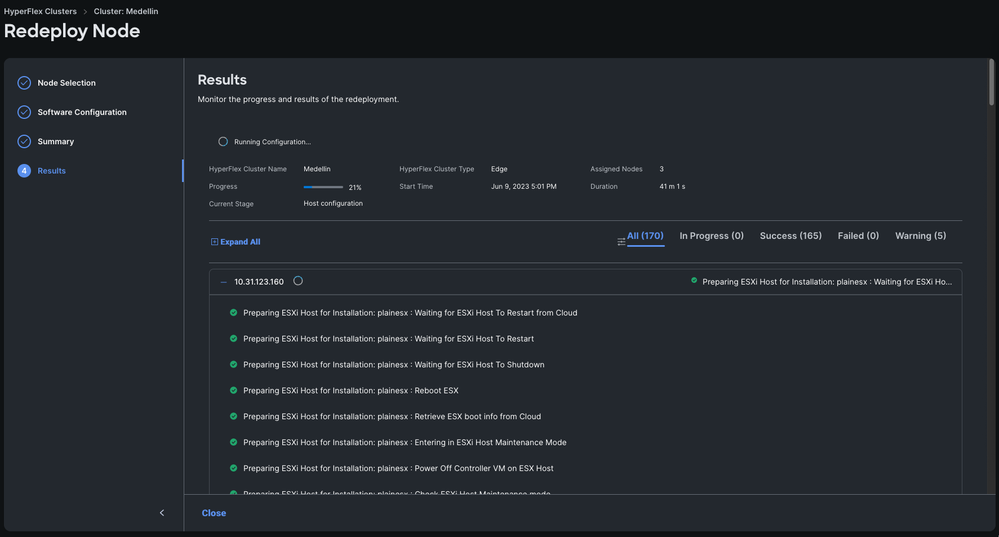
Remarque : Vous pouvez suivre la progression, mais cela prend généralement quelques heures
Enfin, le redéploiement est terminé et le cluster Medellin est de nouveau en bonne santé
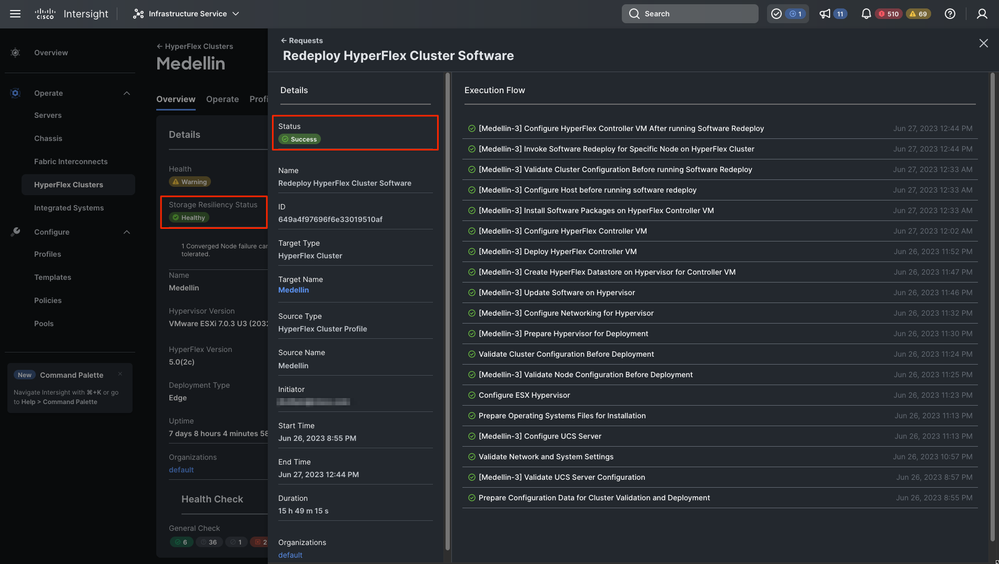
Validation de l'état sain du cluster
Validation de Intersight
Accédez à Hyperflex Clusters > Sélectionnez le cluster > Sélectionnez l'onglet Vue d'ensemble
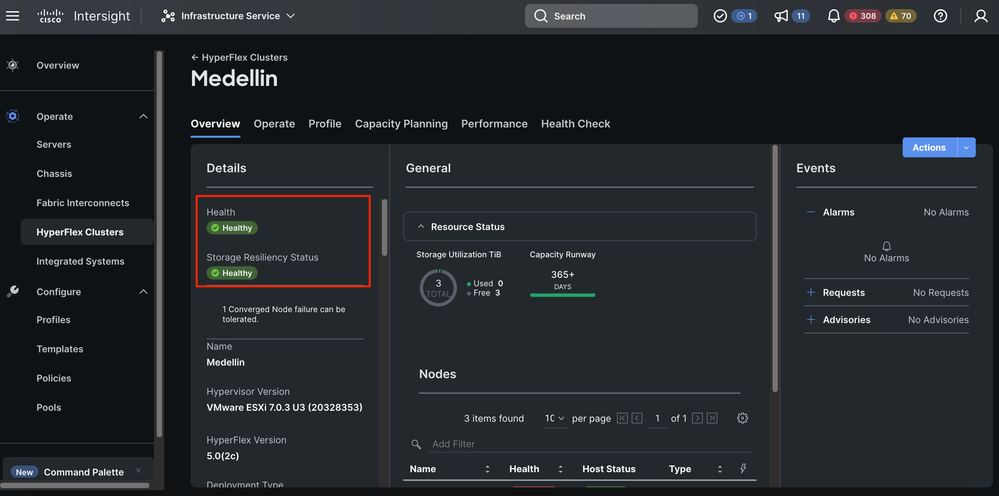
Validation à partir d'Hyperflex Connect
Déjeuner HXDP d'Intersight pour valider le statut à partir de là
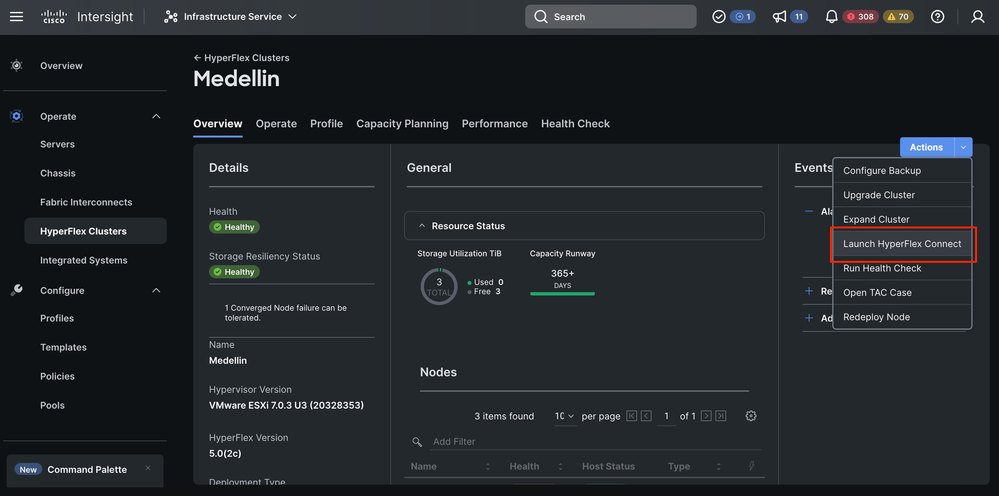
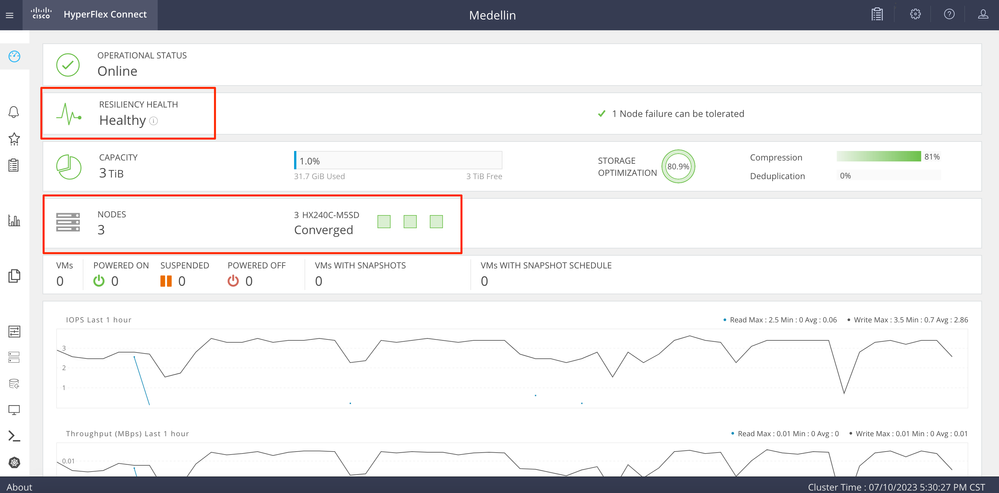
Validation à partir de CLI
À partir de l'interface de ligne de commande, vous pouvez utiliser des commandes telles que : hxcli cluster status , hxcli cluster info, hxcli cluster health, hxcli node list
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : HEALTHY
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 1
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 31.7 GiB
Free Capacity : 3.0 TiB
Compression Savings : 80.90%
Deduplication Savings : 0.00%
Total Savings : 80.90%
# of Nodes Configured : 3
# of Nodes Online : 3
Data IP Address : 169.254.218.1
Resiliency Health : HEALTHY
Policy Compliance : COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 1
# of persistent device failures tolerable : 2
# of cache device failures tolerable : 2
Zone Type : Unknown
All Flash : No
Informations connexes
Workflow de redéploiement de noeud HyperFlex
 Commentaires
Commentaires