CPAR : Arrêt et redémarrage gracieux du noeud de calcul
Options de téléchargement
-
ePub (644.8 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (282.7 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document décrit la procédure à suivre pour l'arrêt et le redémarrage gracieux du noeud de calcul.
Cette procédure s'applique à un environnement Openstack utilisant la version NEWTON où ESC ne gère pas Cisco Prime Access Registrar (CPAR) et CPAR est installé directement sur la machine virtuelle déployée sur Openstack. Le CPAR est installé en tant que ordinateur/machine virtuelle.
Informations générales
Ultra-M est une solution de coeur de réseau de paquets mobiles virtualisés prépackagée et validée conçue pour simplifier le déploiement des VNF. OpenStack est le gestionnaire d'infrastructure virtualisée (VIM) pour Ultra-M et comprend les types de noeuds suivants :
- Calcul
- Disque de stockage d'objets - Calcul (OSD - Calcul)
- Contrôleur
- Plate-forme OpenStack - Director (OSPD)
L'architecture de haut niveau d'Ultra-M et les composants concernés sont illustrés dans cette image :
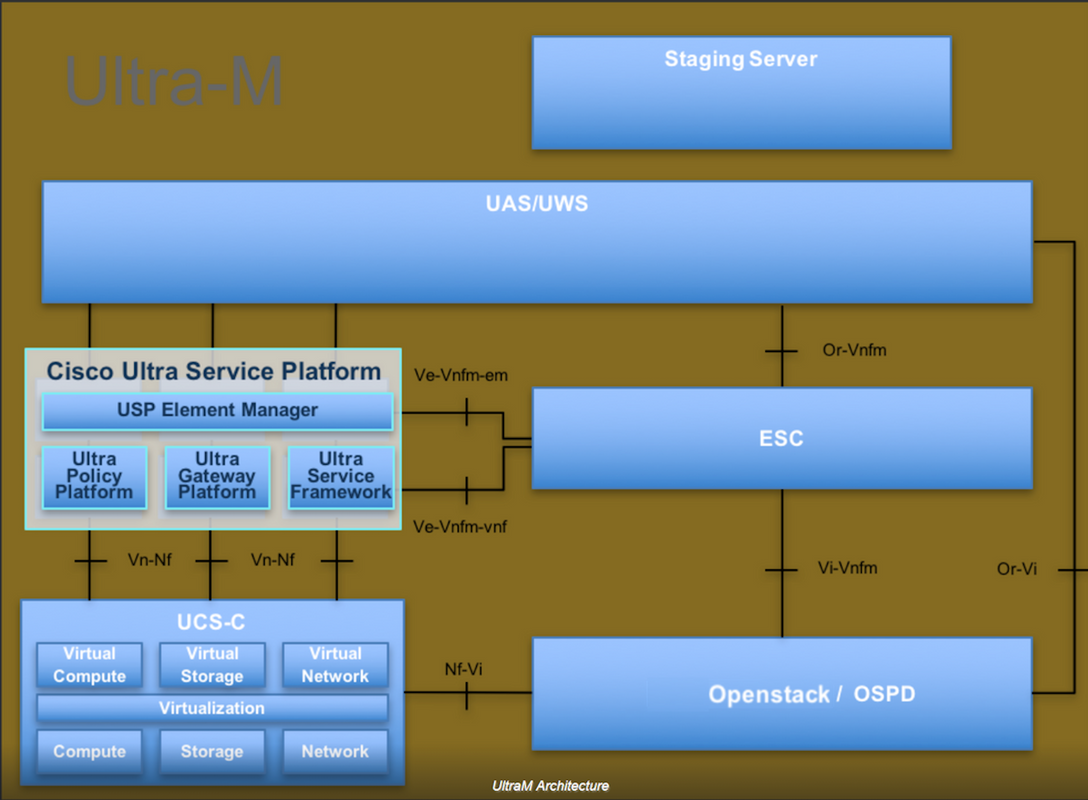
Ce document est destiné au personnel de Cisco qui connaît la plate-forme Cisco Ultra-M et décrit en détail les étapes à suivre dans les systèmes d'exploitation OpenStack et Redhat.
Note: La version Ultra M 5.1.x est prise en compte afin de définir les procédures de ce document.
Arrêt de l'instance CPAR
Il est important de ne pas arrêter simultanément les 4 instances AAA d'un site (ville). Chaque instance AAA doit être arrêtée une par une.
Étape 1. Arrêtez l'application CPAR avec cette commande :
/opt/CSCOar/bin/arserver stop
Message indiquant “ arrêt de Cisco Prime Access Registrar Server Agent terminé. ” Devrait apparaître
Note: Si un utilisateur a laissé une session CLI ouverte, la commande arserver stop ne fonctionnera pas et ce message s'affiche :
« ERREUR : Vous ne pouvez pas arrêter Cisco Prime Access Registrar pendant que
L'interface de ligne de commande est utilisée. Liste actuelle des opérations en cours
CLI avec ID de processus est : 2903 /opt/CSCOar/bin/aregcmd -s »
Dans cet exemple, l'ID de processus 2903 doit être terminé avant que CPAR puisse être arrêté. Si c'est le cas, terminez ce processus à l'aide de cette commande :
kill -9 *process_id*
Répétez ensuite l'étape 1.
Étape 2. Vérifiez que l'application CPAR est bien arrêtée avec cette commande :
/opt/CSCOar/bin/arstatus
Ces messages doivent apparaître :
Agent du serveur Cisco Prime Access Registrar non en cours d'exécution
L'interface utilisateur de Cisco Prime Access Registrar n'est pas en cours d'exécution
Étape 3. Entrez le site Web de l'interface graphique d'Horizon correspondant au site (ville) sur lequel vous travaillez actuellement. Reportez-vous à cette section pour obtenir les détails relatifs à l'adresse IP. Veuillez saisir des informations d'identification par défaut pour la vue personnalisée :
Étape 4. Accédez à Project > Instances, comme illustré dans l'image.

Si l'utilisateur utilisé était cpar, seules les 4 instances AAA apparaissent dans ce menu.
Étape 5. Arrêtez une seule instance à la fois. Répétez l'ensemble du processus de ce document.
Pour arrêter la machine virtuelle, accédez à Actions > Arrêt de l'instance :

et confirmez votre sélection.
Étape 6. Vérifiez que l'instance a bien été arrêtée en cochant la case Status = Shutoff and Power State = Shut Down

Cette étape met fin au processus d'arrêt CPAR.
Redémarrage et vérification de l'intégrité de l'application CPAR
Début de l'instance CPAR
Suivez cette procédure, une fois l'activité RMA terminée et les services CPAR rétablis sur le site qui a été arrêté.
Étape 1. Reconnectez-vous à Horizon, accédez à Project > Instance > Start Instance.
Étape 2. Vérifiez que l'état de l'instance est actif et que l'état d'alimentation est En cours d'exécution, comme l'illustre l'image.

Vérification de l'intégrité post-démarrage de l'instance CPAR
Étape 1. Connectez-vous via Secure Shell (SSH) à l'instance CPAR.
Exécuter la commande /opt/CSCOar/bin/arstatus au niveau du système d'exploitation
[root@wscaaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 4834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Étape 2. Exécutez la commande /opt/CSCOar/bin/aregcmd au niveau du système d'exploitation et saisissez les informations d'identification de l'administrateur. Vérifiez que l'intégrité CPAR est 10 sur 10 et quittez l'interface CLI CPAR.
[root@rvraaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is running, its health is 10 out of 10 --> exit
Étape 3. Exécuter la commande netstat | grand diamètre et vérifiez que toutes les connexions DRA sont établies.
Le résultat mentionné ici est pour un environnement où des liaisons de diamètre sont attendues. Si moins de liens sont affichés, cela représente une déconnexion du DRA qui doit être analysée.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Étape 4. Vérifiez que le journal TPS affiche les demandes traitées par CPAR. Les valeurs mises en évidence représentent le TPS et celles qui nécessitent une attention particulière. La valeur de TPS ne doit pas dépasser 1 500.
[root@aaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Étape 5 Recherchez tous les messages de ” d'erreur “ ou “ dans name_radius_1_log.
[root@aaa02 logs]# grep -E « erreur|alarme » name_radius_1_log
Contribution d’experts de Cisco
- Karthikeyan DachanamoorthyCisco Advance Services
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)