Gestion de la défaillance des deux disques de démarrage sur le serveur UCS 240M4 - CPAR
Options de téléchargement
-
ePub (541.4 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (199.1 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document décrit les étapes requises pour remplacer les deux disques durs défectueux du serveur dans une configuration Ultra-M. Cette procédure s'applique à un environnement OpenStack avec l'utilisation de la version NEWTON où ESC ne gère pas Cisco Prime Access Registrar (CPAR) et CPAR est installé directement sur la machine virtuelle déployée sur OpenStack.
Contribué par Karthikeyan Dachanamoorthy et Harshita Bhardwaj, Services avancés Cisco.
Informations générales
Ultra-M est une solution de coeur de réseau de paquets mobiles virtualisés prépackagée et validée conçue pour simplifier le déploiement des VNF. OpenStack est le gestionnaire d'infrastructure virtualisée (VIM) pour Ultra-M et comprend les types de noeuds suivants :
- Calcul
- Disque de stockage d'objets - Calcul (OSD - Calcul)
- Contrôleur
- Plate-forme OpenStack - Director (OSPD)
L'architecture de haut niveau d'Ultra-M et les composants impliqués sont représentés dans cette image :
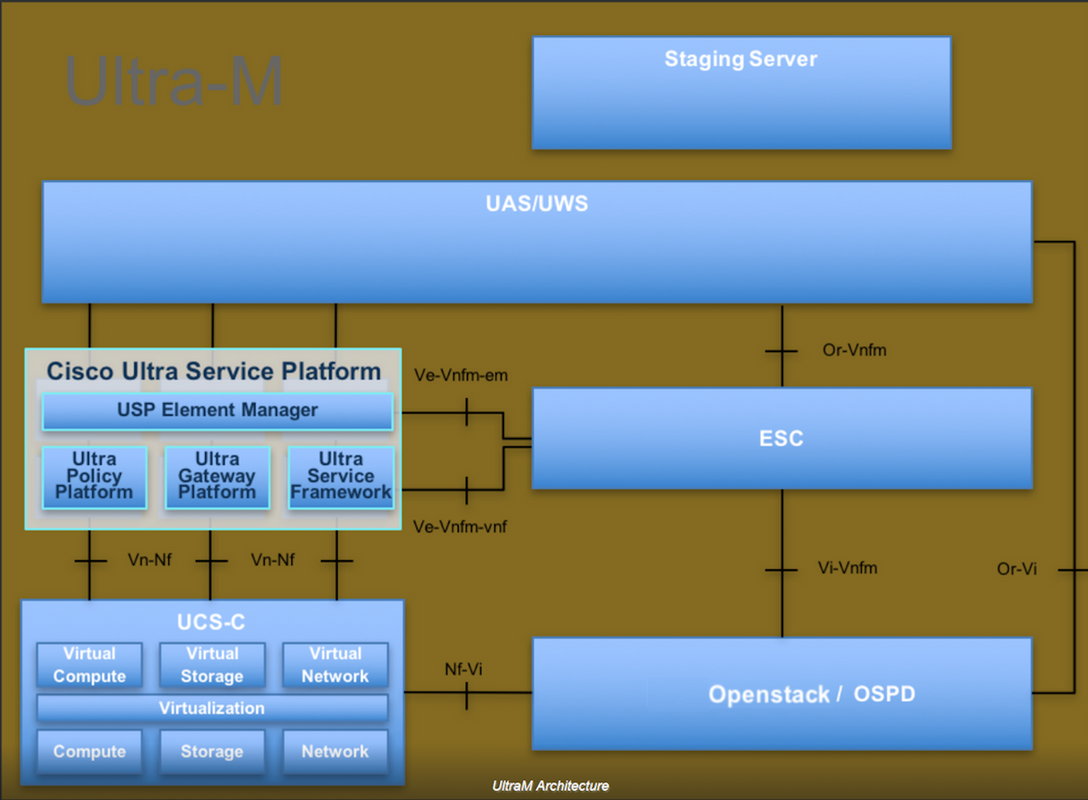
Ce document s'adresse au personnel Cisco qui connaît la plate-forme Cisco Ultra-M et décrit les étapes à suivre dans les systèmes d'exploitation OpenStack et Redhat.
Note: La version Ultra M 5.1.x est prise en compte afin de définir les procédures de ce document.
Abréviations
| MOP | Méthode de procédure |
| OSD | Disques de stockage d'objets |
| OSPD | OpenStack Platform Director |
| HDD | Disque dur |
| SSD | Disque dur SSD |
| VIM | Gestionnaire d'infrastructure virtuelle |
| VM | Machine virtuelle |
| EM | Gestionnaire d'éléments |
| UAS | Services d’automatisation ultra |
| UUID | Identificateur unique |
Défaillance des deux disques durs
Chaque serveur sans système d'exploitation sera provisionné avec deux disques durs afin d'agir en tant que DISQUE DE DÉMARRAGE dans la configuration Raid 1. En cas de défaillance d'un seul disque dur, car il existe une redondance de niveau RAID 1, le disque dur défectueux peut être remplacé à chaud. Cependant, lorsque les deux disques durs échouent, le serveur est arrêté et vous perdez l'accès au serveur. Pour restaurer l'accès au serveur et aux services, il est nécessaire pour remplacer les deux disques durs et ajouter le serveur à la pile surcloud qui existe déjà.
La procédure de remplacement d'un composant défectueux sur le serveur UCS C240 M4 peut être référencée à l'adresse suivante : Remplacement des composants du serveur.
En cas de défaillance des deux disques durs, remplacez uniquement ces deux disques durs défectueux sur le même serveur UCS 240M4. La procédure de mise à niveau du BIOS n'est donc pas requise après le remplacement des nouveaux disques.
Dans la solution Ultra-M OpenStack, le serveur sans système d'exploitation UCS 240M4 peut assumer l'un des rôles suivants : Compute, OSD-Compute, Controller et OSPD. Les étapes requises pour gérer les deux pannes de disque dur dans chacun de ces rôles de serveur sont mentionnées dans ces sections.
Note: Dans les scénarios où les deux disques durs sont sains mais où un autre matériel est défectueux sur le serveur UCS 240M4, remplacez l'UCS 240M4 par un nouveau matériel, mais réutilisez les mêmes disques durs. Cependant, dans ce cas, seuls les disques durs sont défectueux. Vous pouvez donc réutiliser le même UCS 240M4 et remplacer les disques durs défectueux par de nouveaux disques durs.
Défaillance des deux disques durs sur le serveur de calcul
Si la défaillance des deux disques durs est observée dans l'UCS 240M4 qui fait office de noeud de calcul, suivez la procédure de remplacement décrite à la .
Défaillance des deux disques durs sur le serveur de contrôleur
Si la défaillance des deux disques durs est observée dans l'UCS 240M4 qui fait office de noeud contrôleur, suivez la procédure de remplacement décrite à la . Puisque le serveur contrôleur qui observe la défaillance des deux disques durs ne sera pas accessible via Secure Shell (SSH), vous pouvez vous connecter à un autre noeud contrôleur afin d'exécuter la procédure d'arrêt gracieuse indiquée dans la liaison précédemment mentionnée.
Défaillance des deux disques durs sur le serveur OSD-Compute
Si la défaillance des deux disques durs est observée dans l'UCS 240M4 qui fait office de noeud OSD-Compute, suivez la procédure de remplacement décrite à la . Dans la procédure mentionnée ici, l'arrêt gracieux du stockage Ceph ne peut pas être effectué car les deux pannes entraînent l'inaccessibilité du serveur. Par conséquent, ignorez ces étapes.
Panne des deux disques durs sur le serveur OSPD
Si la défaillance des deux disques durs est observée dans l'UCS 240M4 qui fait office de noeud OSPD, suivez la procédure de remplacement décrite à la . Dans ce cas, la sauvegarde OSPD précédemment stockée est nécessaire pour la restauration après le remplacement de disque dur, sinon elle sera comme un redéploiement complet de la pile.
Reportez-vous à cette .Contribution d’experts de Cisco
- Karthikeyan DachanamoorthyCisco Advanced Services
- Harshita BhardwajCisco Advanced Services
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)