Sustitución de la placa base en el servidor Ultra-M UCS 240M4 - CPS
Opciones de descarga
-
ePub (297.5 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (270.5 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos necesarios para sustituir una placa madre defectuosa de un servidor en una configuración Ultra-M que aloja las funciones de red virtual (VNF) de CPS.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizada validada y empaquetada previamente diseñada para simplificar la implementación de VNF. OpenStack es el Virtualized Infrastructure Manager (VIM) para Ultra-M y consta de estos tipos de nodos:
- Informática
- Disco de almacenamiento de objetos - Compute (OSD - Compute)
- Controlador
- Plataforma OpenStack: Director (OSPD)
La arquitectura de alto nivel de Ultra-M y los componentes involucrados se ilustran en esta imagen:
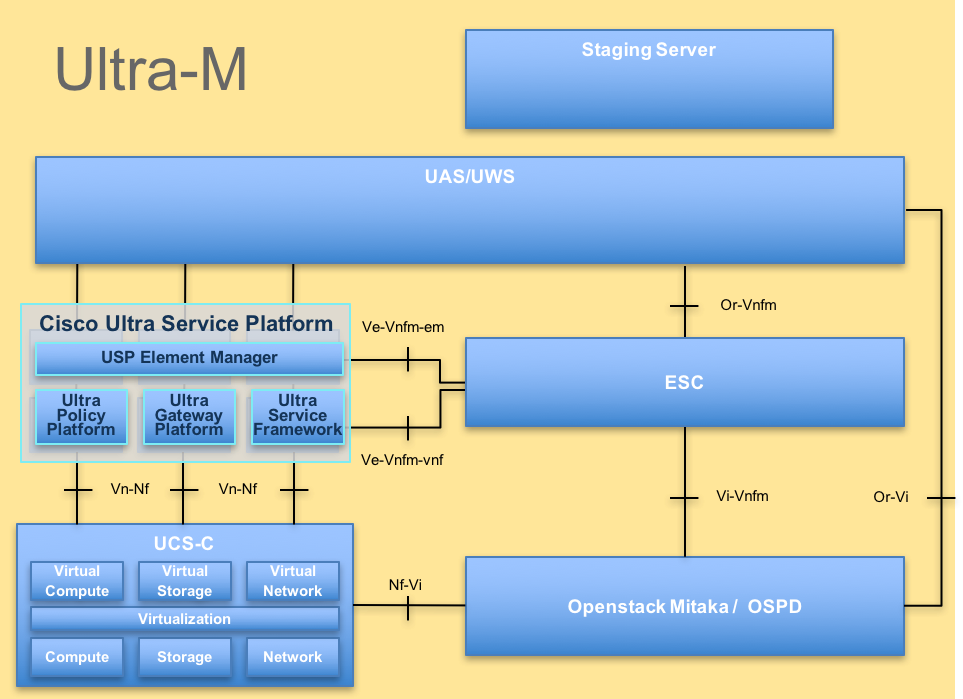
Este documento está dirigido al personal de Cisco que está familiarizado con la plataforma Cisco Ultra-M y detalla los pasos que se deben realizar a nivel de VNF de StarStack y OpenStack en el momento de la sustitución de la placa base en un servidor.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
Abreviaturas
| VNF | Función de red virtual |
| ESC | Controlador de servicio elástico |
| MOP | Método de procedimiento |
| OSD | Discos de almacenamiento de objetos |
| HDD | Unidad de disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador de infraestructura virtual |
| VM | Máquina virtual |
| EM | Administrador de elementos |
| UAS | Servicios de ultra automatización |
| UUID | Identificador único universal |
Flujo de trabajo del MoP
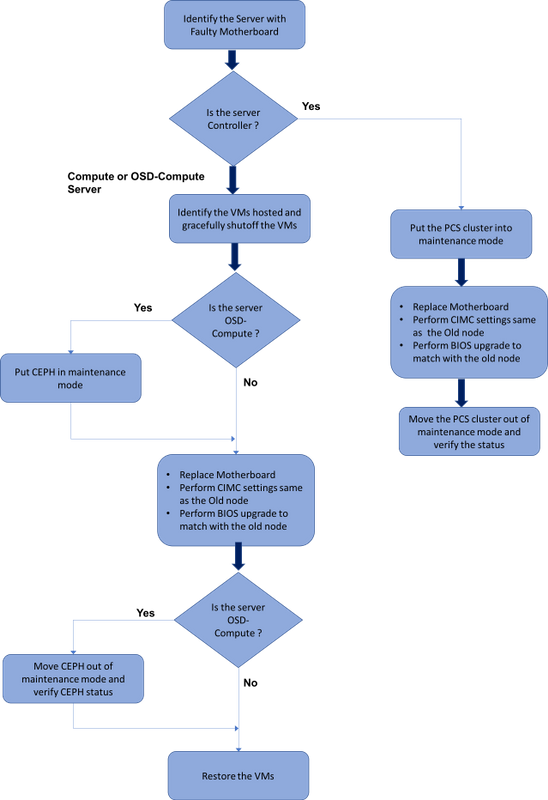
Sustitución de la placa base en la configuración Ultra-M
En una configuración Ultra-M, puede haber situaciones en las que se requiera un reemplazo de placa base en los siguientes tipos de servidor: Compute, OSD-Compute y Controller.
Nota: Los discos de arranque con la instalación de openstack se sustituyen después de la sustitución de la placa base. Por lo tanto, no es necesario volver a agregar el nodo a la nube excesiva. Una vez que el servidor se enciende después de la actividad de reemplazo, se inscribe de nuevo en la pila de nube superpuesta.
Sustitución de la placa base en el nodo informático
Antes de la actividad, las máquinas virtuales alojadas en el nodo Informática se apagan correctamente. Una vez que se ha reemplazado la placa base, se restauran las máquinas virtuales.
Identificación de las VM alojadas en el nodo de informática
Identifique las VM alojadas en el servidor informático.
El servidor informático contiene VM CPS o Elastic Services Controller (ESC):
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
Nota: En el resultado que se muestra aquí, la primera columna corresponde al identificador único universal (UUID), la segunda columna es el nombre de la máquina virtual y la tercera es el nombre de host donde está presente la máquina virtual. Los parámetros de este resultado se utilizarán en secciones posteriores.
Apagado Graceful
Host de nodo de cálculo VM CPS/ESC
Paso 1. Inicie sesión en el nodo ESC que corresponde al VNF y verifique el estado de las VM.
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
Paso 2. Detenga las VM CPS una por una con el uso de su nombre de máquina virtual. (Nombre de VM indicado en la sección Identifique las VM alojadas en el nodo de cálculo).
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
Paso 3. Después de que se detenga, las VM deben ingresar el estado SHUTOFF.
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
Paso 4. Inicie sesión en el ESC alojado en el nodo de cálculo y verifique si se encuentra en el estado principal. En caso afirmativo, cambie el modo ESC al modo de espera:
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
Copia de seguridad ESC
Paso 1. ESC tiene redundancia 1:1 en la solución UltraM. 2 Las VM ESC se implementan y admiten una única falla en UltraM. es decir, el sistema se recupera si hay una única falla en el sistema.
Nota: Si hay más de una falla, no se admite y puede que sea necesario reimplementar el sistema.
Detalles de la copia de seguridad ESC:
- Configuración en ejecución
- Base de datos CDB de ConfD
- Registros ESC
- Configuración de Syslog
Paso 2. La frecuencia de respaldo de la base de datos ESC es complicada y debe manejarse cuidadosamente mientras ESC monitorea y mantiene las diversas máquinas de estado para diversas VM de VNF implementadas. Se recomienda que estas copias de seguridad se realicen después de realizar las siguientes actividades en un VNF/POD/Site determinado.
Paso 3. Verifique que el estado de ESC sea bueno para usar el script health.sh.
[root@auto-test-vnfm1-esc-0 admin]# escadm status
0 ESC status=0 ESC Master Healthy
[root@auto-test-vnfm1-esc-0 admin]# health.sh
esc ui is disabled -- skipping status check
esc_monitor start/running, process 836
esc_mona is up and running ...
vimmanager start/running, process 2741
vimmanager start/running, process 2741
esc_confd is started
tomcat6 (pid 2907) is running... [ OK ]
postgresql-9.4 (pid 2660) is running...
ESC service is running...
Active VIM = OPENSTACK
ESC Operation Mode=OPERATION
/opt/cisco/esc/esc_database is a mountpoint
============== ESC HA (MASTER) with DRBD =================
DRBD_ROLE_CHECK=0
MNT_ESC_DATABSE_CHECK=0
VIMMANAGER_RET=0
ESC_CHECK=0
STORAGE_CHECK=0
ESC_SERVICE_RET=0
MONA_RET=0
ESC_MONITOR_RET=0
=======================================
ESC HEALTH PASSED
Paso 4. Realice una copia de seguridad de la configuración en ejecución y transfiera el archivo al servidor de copia de seguridad.
[root@auto-test-vnfm1-esc-0 admin]# /opt/cisco/esc/confd/bin/confd_cli -u admin -C
admin connected from 127.0.0.1 using console on auto-test-vnfm1-esc-0.novalocal
auto-test-vnfm1-esc-0# show running-config | save /tmp/running-esc-12202017.cfg
auto-test-vnfm1-esc-0#exit
[root@auto-test-vnfm1-esc-0 admin]# ll /tmp/running-esc-12202017.cfg
-rw-------. 1 tomcat tomcat 25569 Dec 20 21:37 /tmp/running-esc-12202017.cfg
Base de datos ESC de reserva
Paso 1. Inicie sesión en ESC VM y ejecute este comando antes de realizar la copia de seguridad.
[admin@esc ~]# sudo bash
[root@esc ~]# cp /opt/cisco/esc/esc-scripts/esc_dbtool.py /opt/cisco/esc/esc-scripts/esc_dbtool.py.bkup
[root@esc esc-scripts]# sudo sed -i "s,'pg_dump,'/usr/pgsql-9.4/bin/pg_dump," /opt/cisco/esc/esc-scripts/esc_dbtool.py
#Set ESC to mainenance mode
[root@esc esc-scripts]# escadm op_mode set --mode=maintenance
Paso 2. Verifique el modo ESC y asegúrese de que está en modo de mantenimiento.
[root@esc esc-scripts]# escadm op_mode show
Paso 3. Copia de seguridad de la base de datos mediante la herramienta de restauración de copias de seguridad de la base de datos disponible en ESC.
[root@esc scripts]# sudo /opt/cisco/esc/esc-scripts/esc_dbtool.py backup --file scp://
:
@
:
Paso 4. Vuelva a establecer ESC en Modo de funcionamiento y confirme el modo.
[root@esc scripts]# escadm op_mode set --mode=operation
[root@esc scripts]# escadm op_mode show
Paso 5. Navegue hasta el directorio de scripts y recopile los registros.
[root@esc scripts]# /opt/cisco/esc/esc-scripts
sudo ./collect_esc_log.sh
Paso 6. Para crear una instantánea del ESC, cierre primero el ESC.
shutdown -r now
Paso 7. Desde OSPD, cree una instantánea de imagen.
-
nova image-create --poll esc1 esc_snapshot_27aug2018
Paso 8. Verifique que se haya creado la instantánea
openstack image list | grep esc_snapshot_27aug2018
Paso 9. Iniciar ESC desde OSPD
nova start esc1
Paso 10. Repita el mismo procedimiento en la VM ESC en espera y transfiera los registros al servidor de respaldo.
Paso 11. Recopile la copia de seguridad de la configuración de syslog en el ESC VMS y transfiérelos al servidor de respaldo.
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
Sustitución de la placa madre
Paso 1. Los pasos para reemplazar la placa base en un servidor UCS C240 M4 se pueden referir desde:
Guía de instalación y servicio del servidor Cisco UCS C240 M4
Paso 2. Inicie sesión en el servidor con la IP de CIMC.
Paso 3. Realice la actualización del BIOS si el firmware no se ajusta a la versión recomendada utilizada anteriormente. Los pasos para la actualización del BIOS se indican a continuación:
Guía de actualización del BIOS del servidor de montaje en bastidor Cisco UCS C-Series
Restauración de las VM
CPS de host de nodo de cómputo, ESC
Recuperación de VM ESC
Paso 1. La VM ESC se puede recuperar si la VM se encuentra en estado de error o de apagado y se reinicia con dificultad para activar la VM afectada. Ejecute estos pasos para recuperar ESC.
Paso 2. Identifique la VM que se encuentra en estado ERROR o Apagar, una vez que se haya identificado el reinicio duro de la VM ESC. En este ejemplo, reinicie auto-test-vnfm1-ESC-0.
[root@tb1-baremetal scripts]# nova list | grep auto-test-vnfm1-ESC-
| f03e3cac-a78a-439f-952b-045aea5b0d2c | auto-test-vnfm1-ESC-0 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.57.12.11; auto-testautovnf1-uas-management=172.57.11.3 |
| 79498e0d-0569-4854-a902-012276740bce | auto-test-vnfm1-ESC-1 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.57.12.15; auto-testautovnf1-uas-management=172.57.11.5 |
[root@tb1-baremetal scripts]# [root@tb1-baremetal scripts]# nova reboot --hard f03e3cac-a78a-439f-952b-045aea5b0d2c\
Request to reboot server <Server: auto-test-vnfm1-ESC-0> has been accepted.
[root@tb1-baremetal scripts]#
Paso 3. Si se elimina la VM ESC y debe volver a activarse.
[stack@pod1-ospd scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.168.11.14; vnf1-UAS-uas-management=172.168.10.4 |
[stack@pod1-ospd scripts]$ nova delete vnf1-ESC-ESC-1
Request to delete server vnf1-ESC-ESC-1 has been accepted.
Paso 4. En OSPD, verifique que la nueva VM ESC esté ACTIVA/en ejecución:
[stack@pod1-ospd ~]$ nova list|grep -i esc
| 934519a4-d634-40c0-a51e-fc8d55ec7144 | vnf1-ESC-ESC-0 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.168.11.13; vnf1-UAS-uas-management=172.168.10.3 |
| 2601b8ec-8ff8-4285-810a-e859f6642ab6 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.168.11.14; vnf1-UAS-uas-management=172.168.10.6 |
#Log in to new ESC and verify Backup state. You may execute health.sh on ESC Master too.
…
####################################################################
# ESC on vnf1-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@esc-1 ~]$ health.sh
============== ESC HA (BACKUP) =================
=======================================
ESC HEALTH PASSED
[admin@esc-1 ~]$ cat /proc/drbd
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
1: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r-----
ns:0 nr:504720 dw:3650316 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
Paso 5. Si la VM ESC no se puede recuperar y requiere la restauración de la base de datos, restaure la base de datos a partir de la copia de seguridad realizada anteriormente.
Paso 6. Para la restauración de la base de datos ESC, debemos garantizar que el servicio esc se detiene antes de restaurar la base de datos; Para ESC HA, ejecute primero en la VM secundaria y luego en la VM principal.
# service keepalived stop
Paso 7. Verifique el estado del servicio ESC y asegúrese de que todo se detiene en VM primarias y secundarias para HA
# escadm status
Paso 8. Ejecute el script para restaurar la base de datos. Como parte de la restauración de la base de datos a la instancia ESC recién creada, la herramienta promoverá también una de las instancias para ser una ESC principal, montará su carpeta DB en el dispositivo drbd e iniciará la base de datos PostgreSQL.
# /opt/cisco/esc/esc-scripts/esc_dbtool.py restore --file scp://
:
@
:
Paso 9. Reinicie el servicio ESC para completar la restauración de la base de datos.
Para la ejecución de HA en ambas VM, reinicie el servicio keepalived
# service keepalived start
Paso 10. Una vez que la máquina virtual se haya restaurado y ejecutado correctamente; asegúrese de que toda la configuración específica de syslog se restaura desde la copia de seguridad conocida anterior exitosa. Asegúrese de que se restaura en todas las VM ESC
[admin@auto-test-vnfm2-esc-1 ~]$
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
Paso 11. Si el ESC debe reconstruirse a partir de la instantánea OSPD, utilice el siguiente comando usando la instantánea tomada durante la copia de seguridad.
nova rebuild --poll --name esc_snapshot_27aug2018 esc1
Paso 12. Compruebe el estado del ESC después de que se complete la reconstrucción.
nova list --fileds name,host,status,networks | grep esc
Paso 13. Verifique el estado de ESC con el siguiente comando.
health.sh
Copy Datamodel to a backup file
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli get esc_datamodel/opdata > /tmp/esc_opdata_`date +%Y%m%d%H%M%S`.txt
Restauración de las VM CPS
La VM CPS se encontraría en estado de error en la lista nova:
[stack@director ~]$ nova list |grep VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d | ERROR | - | NOSTATE |
Recupere la VM CPS de ESC:
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
Monitoree el archivo yangesc.log:
admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d].
Cuando ESC no puede iniciar VM
Paso 1. En algunos casos, ESC no podrá iniciar la VM debido a un estado inesperado. Una solución alternativa es realizar un switchover ESC reiniciando el ESC maestro. La conmutación ESC tardará aproximadamente un minuto. Ejecute health.sh en el nuevo Master ESC para verificar que está activo. Cuando ESC se convierte en Master, ESC puede corregir el estado de la VM e iniciar la VM. Puesto que esta operación está programada, debe esperar de 5 a 7 minutos para que se complete.
Paso 2. Puede supervisar /var/log/esc/yangesc.log y /var/log/esc/escmanager.log. Si NO ve que se recupera la máquina virtual después de 5-7 minutos, el usuario tendría que ir y realizar la recuperación manual de las máquinas virtuales afectadas.
Paso 3. Una vez que la máquina virtual se haya restaurado y ejecutado correctamente; asegúrese de que toda la configuración específica de syslog se restaura desde la copia de seguridad conocida anterior exitosa. Asegúrese de que se restaura en todas las VM ESC.
root@autotestvnfm1esc2:/etc/rsyslog.d# pwd
/etc/rsyslog.d
root@autotestvnfm1esc2:/etc/rsyslog.d# ll
total 28
drwxr-xr-x 2 root root 4096 Jun 7 18:38 ./
drwxr-xr-x 86 root root 4096 Jun 6 20:33 ../]
-rw-r--r-- 1 root root 319 Jun 7 18:36 00-vnmf-proxy.conf
-rw-r--r-- 1 root root 317 Jun 7 18:38 01-ncs-java.conf
-rw-r--r-- 1 root root 311 Mar 17 2012 20-ufw.conf
-rw-r--r-- 1 root root 252 Nov 23 2015 21-cloudinit.conf
-rw-r--r-- 1 root root 1655 Apr 18 2013 50-default.conf
root@abautotestvnfm1em-0:/etc/rsyslog.d# ls /etc/rsyslog.conf
rsyslog.conf
Sustitución de la placa base en el nodo de cómputo OSD
Antes de la actividad, las VM alojadas en el nodo Compute se apagan con gracia y el CEPH se pone en modo de mantenimiento. Una vez que se ha reemplazado la placa base, se restauran las máquinas virtuales y se elimina el CEPH del modo de mantenimiento.
Poner CEPH en modo Mantenimiento
Paso 1. Verificar que el estado del árbol ODS de la ceph esté activo en el servidor
[heat-admin@pod1-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
Paso 2. Inicie sesión en el nodo OSD Compute y coloque CEPH en el modo de mantenimiento.
[root@pod1-osd-compute-1 ~]# sudo ceph osd set norebalance
[root@pod1-osd-compute-1 ~]# sudo ceph osd set noout
[root@pod1-osd-compute-1 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e194: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v584865: 704 pgs, 6 pools, 531 GB data, 344 kobjects
1585 GB used, 11808 GB / 13393 GB avail
704 active+clean
client io 463 kB/s rd, 14903 kB/s wr, 263 op/s rd, 542 op/s wr
Nota: Cuando se elimina CEPH, el RAID HD VNF entra en el estado Degradado, pero el disco duro aún debe estar accesible
Identificación de las VM alojadas en el nodo Osd-Compute
Identifique las VM alojadas en el servidor informático OSD.
El servidor informático contiene Elastic Services Controller (ESC) o CPS VM
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
Nota: En el resultado que se muestra aquí, la primera columna corresponde al identificador único universal (UUID), la segunda columna es el nombre de la máquina virtual y la tercera es el nombre de host donde está presente la máquina virtual. Los parámetros de este resultado se utilizarán en secciones posteriores.
Apagado Graceful
Caso 1. OSD-Compute Node Hosts ESC
El procedimiento para alimentar correctamente las VM ESC o CPS es el mismo independientemente de si las VM están alojadas en el nodo Compute o OSD-Compute.
Siga los pasos de "Sustitución de la placa base en el nodo de cómputo" para apagar correctamente las VM.
Sustitución de la placa madre
Paso 1. Los pasos para reemplazar la placa base en un servidor UCS C240 M4 se pueden referir desde:
Guía de instalación y servicio del servidor Cisco UCS C240 M4
Paso 2. Inicie sesión en el servidor con el uso de la IP de CIMC
3. Realice la actualización del BIOS si el firmware no se ajusta a la versión recomendada utilizada anteriormente. Los pasos para la actualización del BIOS se indican a continuación:
Guía de actualización del BIOS del servidor de montaje en bastidor Cisco UCS C-Series
Sacar CEPH del modo de mantenimiento
Inicie sesión en el nodo de cómputo OSD y mueva CEPH fuera del modo de mantenimiento.
[root@pod1-osd-compute-1 ~]# sudo ceph osd unset norebalance
[root@pod1-osd-compute-1 ~]# sudo ceph osd unset noout
[root@pod1-osd-compute-1 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e196: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v584954: 704 pgs, 6 pools, 531 GB data, 344 kobjects
1585 GB used, 11808 GB / 13393 GB avail
704 active+clean
client io 12888 kB/s wr, 0 op/s rd, 81 op/s wr
Restauración de las VM
Caso 1. OSD-Compute que aloja máquinas virtuales ESC o CPS
El procedimiento para restaurar las VM CF/ESC/EM/UAS es el mismo independientemente de si las VM están alojadas en el nodo Compute o OSD-Compute.
Siga los pasos del "Caso 2. Compute Node Hosts CF/ESC/EM/UAS" para restaurar las VM.
Sustitución de la placa madre en el nodo controlador
Verifique el estado del controlador y coloque el clúster en modo Mantenimiento
Desde OSPD, el inicio de sesión en controller y verify pc está en buen estado - los tres controladores Online y galera muestran los tres controladores como Master.
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 00:46:10 2017 Last change: Wed Nov 29 01:20:52 2017 by hacluster via crmd on pod1-controller-0
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-0 pod1-controller-1 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-0
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-0
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Ponga el clúster en modo de mantenimiento.
[heat-admin@pod1-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 00:48:24 2017 Last change: Mon Dec 4 00:48:18 2017 by root via crm_attribute on pod1-controller-0
3 nodes and 22 resources configured
Node pod1-controller-0: standby
Online: [ pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-1 pod1-controller-2 ]
Stopped: [ pod1-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-1 pod1-controller-2 ]
Slaves: [ pod1-controller-0 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-1 ]
Stopped: [ pod1-controller-0 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-2
Sustitución de la placa madre
Paso 1. Los pasos para reemplazar la placa base en un servidor UCS C240 M4 se pueden referir desde:
Guía de instalación y servicio del servidor Cisco UCS C240 M4
Paso 2. Inicie sesión en el servidor con la IP de CIMC.
Paso 3. Realice la actualización del BIOS si el firmware no se ajusta a la versión recomendada utilizada anteriormente. Los pasos para la actualización del BIOS se indican a continuación:
Guía de actualización del BIOS del servidor de montaje en bastidor Cisco UCS C-Series
Restaurar estado del clúster
Inicie sesión en el controlador afectado, quite el modo en espera configurando unstandby. Verify controller viene Online con cluster y galera muestra los tres controladores como Master. Esto puede tardar unos minutos.
[heat-admin@pod1-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 01:08:10 2017 Last change: Mon Dec 4 01:04:21 2017 by root via crm_attribute on pod1-controller-0
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-0 pod1-controller-1 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-2
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enable
Con la colaboración de ingenieros de Cisco
- Nitesh Bansal
- Rishi ShekharCisco Advance Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)