Introducción
Este documento describe diferentes tipos de errores de disco, cómo clasificarlos y las herramientas que puede utilizar para identificarlos.
Prerequisites
Requirements
No hay requisitos específicos para este documento.
Componentes Utilizados
La información de este documento se basa en discos duros de Unified Computing System (UCS).
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). If your network is live, make sure that you understand the potential impact of any command.
Antecedentes
El documento también describe la función del controlador de la unidad de disco duro (HDD) y la matriz redundante de discos independientes (RAID) cuando se identifican errores medios en las unidades.
Nota: Los errores medios también se conocen como errores de medios
Gestión de errores medios de HDD
¿Qué causa los errores de medios HDD?
La causa más común de errores medios es una amplitud de señal deficiente que resulta en
- Ubicación de lectura de dirección de bus lógico (LBA) no fiable. A veces recuperable con varios reintentos.
- Condiciones transitorias, escrituras de moscas altas causadas por partículas blandas.
- Condiciones transitorias causadas por choques temporales, vibraciones o eventos acústicos que resultan en escrituras fuera de pista.
- Deficiente función de mapa de errores en la fabricación del disco duro que da como resultado el relleno de las ubicaciones de defecto principal actuales.
¿Cómo detecta el disco duro el error medio?
Paso 1.El disco duro realiza periódicamente exploraciones de medios en segundo plano para detectar errores.
Paso 2. El disco duro intenta leer de los medios y, por alguna razón, no puede recuperar los datos que se escribieron.
Paso 3. Cuando el disco duro no puede recuperar los datos que se escribieron, invoca el código de recuperación del disco duro, que intentará varios pasos de recuperación de errores para leer correctamente los datos de los medios.
Paso 4. Si todos los pasos de recuperación fallan, la unidad generará un error 03/11/0x de vuelta al host y los LBA se colocarán en la lista de defectos pendientes.
¿Cómo detecta el controlador Raid los errores medios?
- El controlador RAID se encontrará con errores medios mientras las operaciones de Patrol Reads, Constency Checks, Normal Reads, Rebuilds, y Read / Modify / Write.
- Según la configuración de RAID, es posible que el controlador pueda gestionar el error medio notificado por el disco duro y no se requiera ninguna otra acción.
- En algunos casos, el controlador no podrá manejar el error de medio y pasará el error al host para manejar el error.
¿Cuándo detecta el sistema operativo errores medios?
- Si el disco duro informa de un error medio y el controlador RAID no puede manejar la recuperación, entonces el host será notificado del error.
- Esta notificación ya no es solo un mensaje de aviso que informaría al sistema de que se ha producido el evento, es una solicitud para que el sistema operativo actúe porque el disco duro y el controlador RAID no se pudieron recuperar del error medio.
- Si el sistema operativo tiene el contexto necesario para resolver correctamente el error de medio, debe gestionarlo el sistema operativo
- Si los discos están en Just a Bunch Of Disk (JBOD), el sistema operativo verá los errores ya que el controlador no los corrige. Esto es común en entornos HyperFlex (HX)/Virtual Storage Area Network (VSAN).
Función HDD
Nivel de HDD de defectos de crecimiento (lista G)
Mientras una unidad está en funcionamiento, la cabeza puede encontrarse con un sector con un nivel de lectura magnética debilitado. Los datos siguen siendo legibles, pero podrían quedar por debajo del umbral preferido para niveles de lectura de sectores adecuados. Esta unidad de disco consideraría que se trata de un sector que podría guardar estos datos en una nueva ubicación disponible en la lista de reserva válida conocida. Una vez que se mueven los datos, la dirección del sector antiguo se agrega a la lista de Defectos Crecidos, para no volver a usarse nunca más. Este proceso es un error de medios recuperables. La unidad activará SMART una vez que se agoten la mayoría de los sectores de repuesto que se sabe que son correctos.
Función de controlador RAID
Patrulla Leída
- Patrol Read es una opción definida por el usuario que realiza lecturas de unidad en segundo plano y mapea las áreas dañadas de la unidad.
- Patrol Read comprueba si hay errores de disco físico que puedan provocar un fallo de la unidad. Estas comprobaciones suelen incluir un intento de acción correctiva. La lectura de la patrulla puede activarse o desactivarse con la activación automática o manual.
- Una lectura de patrulla verifica periódicamente todos los sectores de los discos físicos que están conectados a un controlador, que incluyen el área reservada del sistema en las unidades configuradas RAID. Patrol Read funciona para todos los niveles de RAID y todas las unidades de repuesto activas.
- Este proceso se inicia sólo cuando el controlador RAID está inactivo durante un período de tiempo definido y no hay otras tareas en segundo plano activas, aunque puede continuar ejecutándose al mismo tiempo que procesos de entrada/salida (E/S) de gran volumen.
- No puede realizar lecturas de patrulla en unidades configuradas en JBOD.
Nota: Latent Semantic Indexing (LSI) recomienda dejar la frecuencia de lectura de la patrulla y otras configuraciones de lectura de la patrulla en los valores predeterminados para lograr el mejor rendimiento del sistema. Si decide cambiar los valores, registre aquí el valor predeterminado original para poder restaurarlos más tarde.
Nota: Patrol Read no informa sobre su progreso mientras se ejecuta. El estado de lectura de la patrulla se informa solamente en el registro de eventos.
Las opciones de Patrol Read son las que se muestran en la imagen:
 Ejemplos de MegaCli
Ejemplos de MegaCli
Para ver información sobre el estado de lectura de la patrulla y el retraso entre las ejecuciones de lectura de la patrulla:
# MegaCli64 -AdpPR -Info -aALL
Para averiguar la velocidad de lectura de la patrulla actual, ejecute:
# MegaCli64 -AdpGetProp PatrolReadRate -aALL
Para desactivar la patrulla automática, lea:
# MegaCli64 -AdpPR -Dsbl -aALL
Para habilitar la patrulla automática, lea:
#MegaCli64 -AdpPR -EnblAuto -aALL
Para iniciar una exploración de lectura de patrulla manual:
# MegaCli64 -AdpPR -Start -aALL
Para detener una exploración de lectura de patrulla:
# MegaCli64 -AdpPR -Stop -aALL
Comprobación de coherencia
- En RAID, la comprobación de coherencia verifica la exactitud de los datos redundantes de una matriz. Por ejemplo, en un sistema con paridad, comprobar la coherencia significa calcular la paridad de las unidades de datos y comparar los resultados con el contenido de la unidad de paridad.
- JBOD no admite la comprobación de coherencia.
- RAID 0 no admite la comprobación de coherencia.
- RAID 1 utiliza una comparación de datos, no una paridad.
- RAID 6 calcula la paridad de 2 unidades de paridad y verifica ambas.
Nota: se recomienda realizar una comprobación de coherencia al menos una vez al mes.
Las opciones de gestión de comprobación de coherencia son las que se muestran en la imagen:
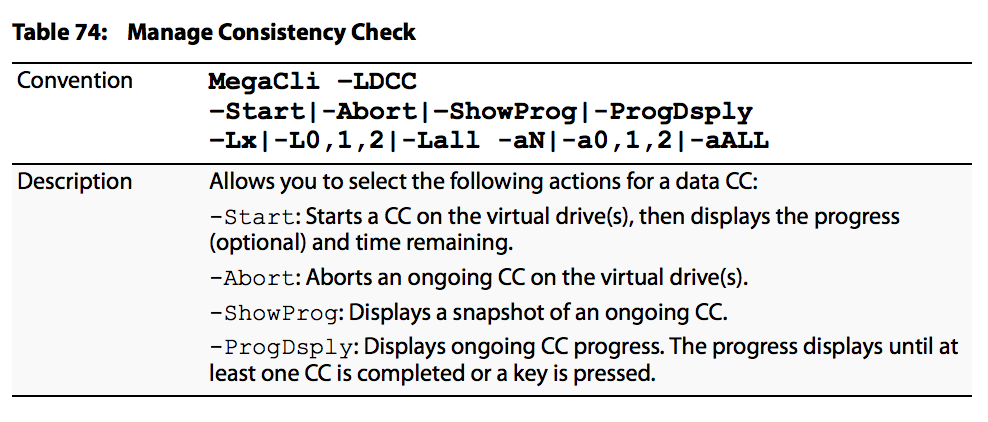
Las opciones de programación de la comprobación de coherencia son las que se muestran en la imagen:

Ejemplos de MegaCli
Para ver la siguiente hora programada de comprobación de coherencia:
#MegaCli64 -AdpCcSched -Info -aALL
Para cambiar la hora de la comprobación de coherencia programada:
#MegaCli64 -AdpCCSched -SetSTartTime 20171028 02 -aALL
Para desactivar la comprobación de coherencia:
#MegaCli64 -AdpCcSched -Dsbl -aALL
Condiciones cuando un controlador RAID no puede reparar un error medio
- En JBOD
- El sistema operativo host es responsable de los errores medios.
- En RAID 0
- No hay redundancia, por lo que el controlador no puede proporcionar al disco duro los datos para escribir en el LBA.
- En RAID 1
- Cuando el controlador no puede decir qué copia reflejada contiene los datos correctos. Esto sólo ocurrirá si se pueden leer ambos LBA, pero los datos no coinciden.
- RAID 5
- Si hay 2 o más errores en la misma banda. Lo más probable es que se produzca cuando se inicia una reconstrucción de una matriz. La unidad que se reconstruye es un error, y un error medio en cualquier reconstrucción de la unidad sería el segundo error. El controlador no podría reconstruir los datos necesarios para reconstruir el LBA en la unidad de reemplazo.
- RAID 6
- Si hay 3 o más errores en la misma banda. Lo más probable es que se produzca cuando se reconstruye una matriz. La unidad que se reconstruye es un error, y un error medio en cualquier otra unidad mientras la reconstrucción está en curso sería un segundo y tercer error, o un error medio y un segundo fallo de la unidad. El controlador no podría reconstruir los datos necesarios para reconstruir los LBA en las unidades con errores.
Información Relacionada
 Comentarios
Comentarios