Servidores UCS serie B: La sustitución de un controlador RAID por un firmware más antiguo puede provocar la falla del montaje del almacén de datos en los hosts ESXi
Opciones de descarga
-
ePub (648.1 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (349.4 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Declaración de problema:
Después de la sustitución del controlador RAID, el ID de NAA del VD se cambió durante la importación de configuración externa y eso causó que el montaje del almacén de datos fallara.
Hardware afectado:
UCSB-MRAID12G
UCSC-MRAID12G
Servidores con Controladores RAID UCSB-MRAID12G:
UCS B200 M4
UCS B200 M5
UCS B480 M5
UCS B420 M4
UCS C220 M4
UCS C240 M4
Firmware afectado:
Firmware del controlador RAID: 24.5.x.x y 24.6.x.x
Ejemplo n.º
***mrsasctlr.24.5.0-0043_6.19.05.0_NA.bin
24.5.x.x firmware del controlador se ve en todas las versiones de UCSM anteriores a 3.2.*
Notas de la versión 3.1 #
https://www.cisco.com/c/en/us/td/docs/unified_computing/ucs/release/notes/CiscoUCSManager-RB-3-1.htmlhttps://www.cisco.com/c/en/us/td/docs/unified_computing/ucs/release/notes/CiscoUCSManager-RB-3-1.html
SO afectado:
VMware ESXi
Causa:
Con las versiones de firmware anteriores, si se encuentra una discordancia de versión del espacio de trabajo DDF(Device Data Format), el FW del controlador no puede restaurar la ID de NAA desde DDF durante la importación externa.
MR 6.4 tiene DDF_WORK_SPACE versión 1, mientras que MR 6.10 tiene DDF_WORK_SPACE versión 3. Versiones posteriores de FW posteriores a MR 6.4, se hicieron correcciones que permiten al controlador FW restaurar NAA IDD desde DDF incluso si se encuentra una discordancia en el espacio de trabajo DDF. La ID de NAA no se puede analizar correctamente cuando el firmware del controlador de reemplazo es antiguo(Ejemplo: 24.5.x y 24.6.x). Sin embargo, la versión 24.12.x puede analizar correctamente el ID de NAA.
| Antes de la sustitución: Servidor 2/2: Nombre del producto equipado: Servidor blade de 2 zócalos Cisco UCS B200 M5 PID equipada: UCSB-B200-M5 VID equipado: V06 Serie equipada (SN): FCH22973K5 Estado de ranura: Equipado Nombre del producto reconocido: Servidor blade de 2 zócalos Cisco UCS B200 M5 PID reconocido: UCSB-B200-M5 VID reconocido: V06 Serie confirmada (SN): FCH22973K5 Memoria reconocida (MB): 524288 Memoria efectiva (MB) reconocida: 524288 Números reconocidos: 28 Adaptadores reconocidos: 1 Unidad virtual 0: Tipo: RAID 1 duplicado Tamaño del bloque: 512 Bloques: 1560545280 Operabilidad: Operable Presencia: Equipado Tamaño: 761985 Ciclo de vida: Asignado Estado de la unidad: Óptimo Tamaño de tira (KB): 64 Política de acceso: Lectura y escritura Política de lectura: Normal Política de escritura de caché configurada: Escritura Política de caché de escritura real: Escritura Política de E/S: DIRECT Caché de unidad: Sin cambios Inicio: Verdadero Identificador único: bcc0dd21-2006-4189-86c1-132017ad0958 Identificador único del proveedor: 618e7283-72eb-6460-240f-d02c0bbd9310 <<<<<<<<<<< Después del reemplazo: Servidor 2/2: Unidad virtual 0:
En este caso, la ID del servidor 2/2 de [identificador único del proveedor] cambió de [618e7283-72eb-6460-240f-d02c0bbd9310] a [618e7283-72ea-3f222 0-ff00-005a0574b04b] |
¿Cómo evitar que el problema llegue?
Este problema se puede evitar actualizando el firmware del controlador de reemplazo antes de insertar el VD / disco.
PASOS DETALLADOS:
- Apagar el servidor
- Retire todos los discos uno por uno y deje los discos en la misma ranura sin insertarlos completamente para que no se altere su orden de colocación(Si se retira completamente de la ranura, por favor, tenga una nota de la ranura ya que las unidades deben colocarse de nuevo en la misma ranura)
- Instale un nuevo controlador RAID para su reemplazo sin insertar un disco.
- El servidor reconocerá el nuevo controlador RAID
- Actualice el firmware del controlador Raid.
- Después de una actualización de firmware satisfactoria, apague el servidor e inserte el disco en el servidor.
- Ahora encienda el servidor
¿Cómo se recupera si el servidor sufre este problema?
PASOS DETALLADOS:
====================
Procedimiento para restaurar el almacén de datos
====================
1 Inicie sesión en vSphere Client y seleccione el servidor en el panel de inventario.
2 Haga clic en la ficha Configuration (Configuración) y haga clic en Storage (Almacenamiento) en el panel Hardware.
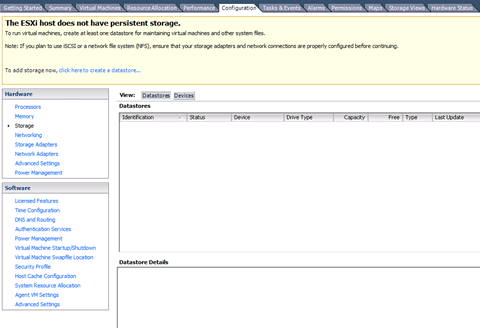
3 Haga clic en Add Storage (Agregar almacenamiento).
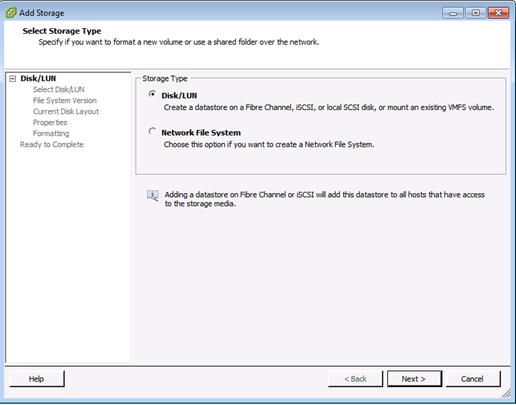
4 Seleccione el tipo de almacenamiento Disk/LUN y haga clic en Next (Siguiente).
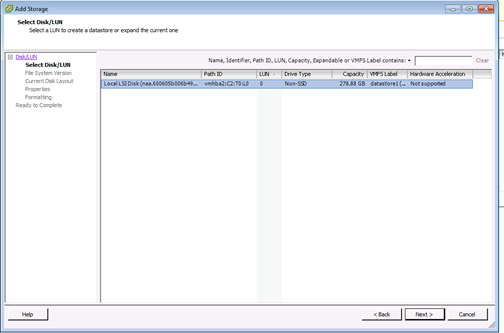
5 En la lista de LUNs, seleccione el LUN que tiene un nombre de almacén de datos que se muestra en la columna VMFS Label y haga clic en Next .
Nota: El nombre presente en la columna VMFS Label indica que el LUN es una copia que contiene una copia de un almacén de datos VMFS existente.
6 En Opciones De Montaje, se muestran estas opciones:
Mantener firma existente: Montaje persistente del LUN (por ejemplo, montaje del LUN a través de reinicios)
Asignar una nueva firma: Refirma del LUN
Formatear el disco: Reformatear el LUN
Notas: Formatear el discoborra cualquier dato existente en el LUN. Antes de intentar volver a firmar, asegúrese de que no haya máquinas virtuales ejecutándose ese volumen VMFS en ningún otro host, ya que esas máquinas virtuales se vuelven inválidas en el inventario del servidor vCenter y se van a registrar de nuevo en sus respectivos hosts.
seleccione Asignar una firma nueva y haga clic en Siguiente.
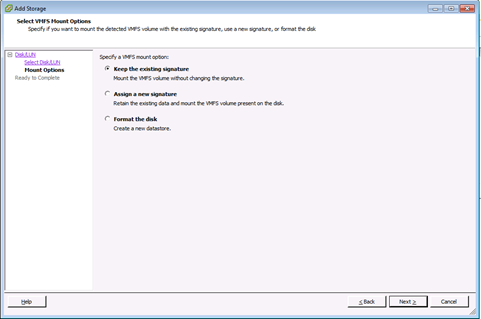
7 Seleccione la opción deseada para el volumen
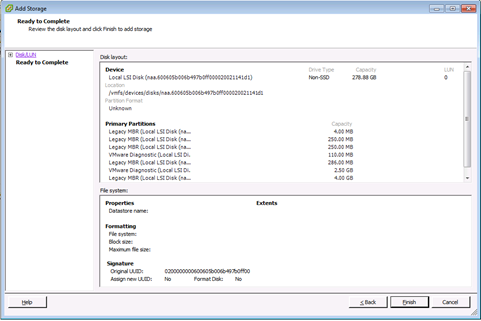
8 En la página Ready to Complete (Listo para completar), revise la información de configuración del almacén de datos y haga clic en Finish (Finalizar).
====================
Pasos Siguientes
==========================
Después de la renuncia, es posible que tenga que hacer lo siguiente:
1 Inicie sesión en vSphere Client, UEn Lista de inventario > Haga clic en Almacén de datos
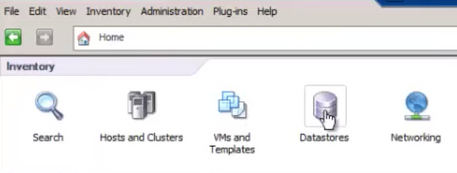
2 Haga clic con el botón derecho del ratón en el almacén de datos y haga clic en "Examinar almacén de datos".
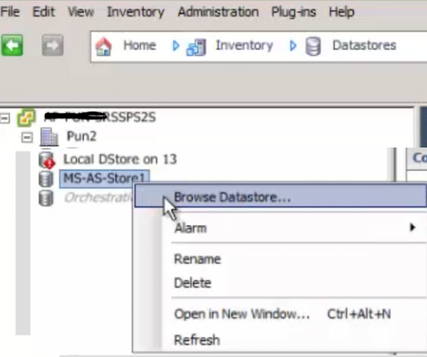
3 En el panel izquierdo, haga clic en una carpeta VM para mostrar el contenido en el panel derecho.

4 En el panel derecho, haga clic con el botón derecho del ratón en el archivo .vmx y seleccione "Agregar al inventario"

5 Tutorial del asistente "Agregar al inventario" para completar la adición de la máquina virtual al host ESXi
6 Repita los pasos para todas las VM restantes
7 Una vez que se hayan vuelto a registrar todas las VM, elimine todas las VM inaccesibles del inventario haciendo clic con el botón derecho del ratón en cada una de ellas y seleccionando "Eliminar del inventario"
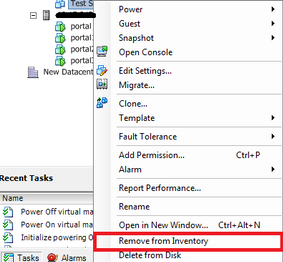
8 Encienda cada VM y verifique que esté operativa y accesible
Nota: Antes de encender la máquina virtual, reinicie el host ESXi y después de volver a estar en línea y de que se pueda acceder a él a través del cliente vSphere, confirme que las máquinas virtuales siguen estando visibles y no han pasado al estado "Inaccesible"
ERROR relacionado: CSCvr11972
CSCvr11972  El identificador único del proveedor cambió después de sustituir el MRAID12G
El identificador único del proveedor cambió después de sustituir el MRAID12G
Con la colaboración de ingenieros de Cisco
- Afroj AhmadTechnical Consulting Engineer - CX
- Yogesha MGTechnical Leader - CX
- Yogindar Das YasodharTechnical Leader - Storage Engineering
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)