Comprensión de los Mensajes de Estado de Failover para FTD
Opciones de descarga
-
ePub (561.4 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (467.0 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe cómo comprender los mensajes de estado de conmutación por error en Secure Firewall Threat Defence (FTD).
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas:
- Configuración de alta disponibilidad (HA) para Cisco Secure FTD
- Uso básico de Cisco Firewall Management Center (FMC)
Componentes Utilizados
La información que contiene este documento se basa en las siguientes versiones de software y hardware.
- Cisco FMC v7.2.5
- Cisco Firepower serie 9300 v7.2.5
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
Descripción General de Failover Health Monitoring:
El dispositivo FTD monitorea cada unidad para ver el estado general y el estado de la interfaz. El FTD realiza pruebas para determinar el estado de cada unidad basándose en la supervisión del estado de la unidad y la supervisión de la interfaz. Cuando una prueba para determinar el estado de cada unidad en el par HA falla, se activan eventos de failover.
Mensajes de estado de failover
Caso práctico: enlace de datos inactivo sin conmutación por fallo
Cuando la supervisión de la interfaz no está habilitada en el FTD HA y en caso de una falla del link de datos, no se activa un evento de failover ya que no se realizan las pruebas de supervisión de estado para las interfaces.
Esta imagen describe las alertas de una falla de link de datos pero no se disparan alertas de failover.
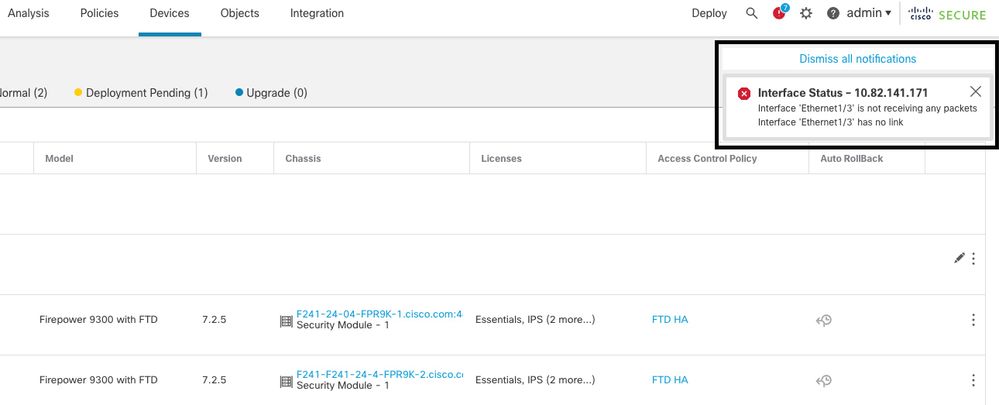 alerta de link caído
alerta de link caído
Para verificar el estado y el estado de los links de datos, utilice este comando:
show failover- Muestra la información sobre el estado de failover de cada unidad e interfaz.
Monitored Interfaces 1 of 1291 maximum
...
This host: Primary - Active
Active time: 3998 (sec)
slot 0: UCSB-B200-M3-U hw/sw rev (0.0/9.18(3)53) status (Up Sys)
Interface DMZ (192.168.10.1): Normal (Waiting)
Interface INSIDE (172.16.10.1): No Link (Not-Monitored)
Interface OUTSIDE (192.168.20.1): Normal (Waiting)
Interface diagnostic (0.0.0.0): Normal (Not-Monitored)
...
Other host: Secondary - Standby Ready
Active time: 0 (sec)
slot 0: UCSB-B200-M3-U hw/sw rev (0.0/9.18(3)53) status (Up Sys)
Interface DMZ (192.168.10.2): Normal (Waiting)
Interface INSIDE (172.16.10.2): Normal (Waiting)
Interface OUTSIDE (192.168.20.2): Normal (Waiting)
Interface diagnostic (0.0.0.0): Normal (Not-Monitored)
Cuando el estado de la interfaz es 'En espera', significa que la interfaz está activa, pero aún no ha recibido un paquete de saludo de la interfaz correspondiente en la unidad de peer.
Por otro lado, el estado 'Sin link (no monitoreado)' significa que el link físico para la interfaz está inactivo pero no es monitoreado por el proceso de failover.
Para evitar una interrupción, se recomienda habilitar Interface Health Monitor en todas las interfaces sensibles con sus direcciones IP en espera correspondientes.
Para habilitar el Monitoreo de la Interfaz, navegue hastaDevice > Device Management > High Availability > Monitored Interfaces.
Esta imagen muestra la ficha Interfaces supervisadas:
 interfaces supervisadas
interfaces supervisadas
Para verificar el estado de las interfaces monitoreadas y las direcciones IP en espera, ejecute este comando:
show failover- Muestra la información sobre el estado de failover de cada unidad e interfaz.
Monitored Interfaces 3 of 1291 maximum
...
This host: Primary - Active
Active time: 3998 (sec)
slot 0: UCSB-B200-M3-U hw/sw rev (0.0/9.18(3)53) status (Up Sys)
Interface DMZ (192.168.10.1): Normal (Monitored)
Interface INSIDE (172.16.10.1): No Link (Monitored)
Interface OUTSIDE (192.168.20.1): Normal (Monitored)
Interface diagnostic (0.0.0.0): Normal (Waiting)
...
Other host: Secondary - Standby Ready
Active time: 0 (sec)
slot 0: UCSB-B200-M3-U hw/sw rev (0.0/9.18(3)53) status (Up Sys)
Interface DMZ (192.168.10.2): Normal (Monitored)
Interface INSIDE (172.16.10.2): Normal (Monitored)
Interface OUTSIDE (192.168.20.2): Normal (Monitored)
Interface diagnostic (0.0.0.0): Normal (Waiting)
Caso práctico: falla de estado de la interfaz
Cuando una unidad no recibe mensajes de saludo en una interfaz monitoreada durante 15 segundos y si la prueba de interfaz falla en una unidad pero funciona en la otra unidad, se considera que la interfaz ha fallado.
Si se alcanza el umbral definido para el número de interfaces fallidas y la unidad activa tiene más interfaces fallidas que la unidad standby, entonces ocurre una conmutación por fallas.
Para modificar el umbral de la interfaz, navegue hasta Devices > Device Management > High Availability > Failover Trigger Criteria.
Esta imagen describe las alertas generadas en una falla de interfaz:
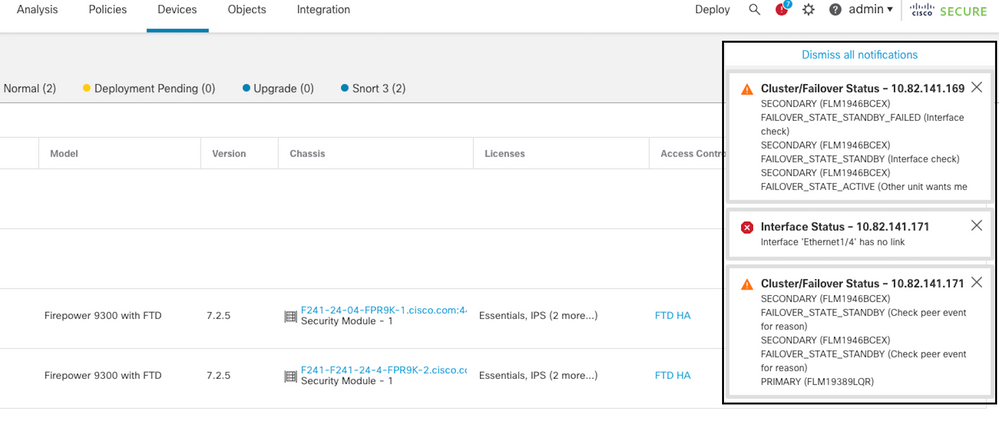 evento de falla con link inactivo
evento de falla con link inactivo
Para verificar la razón de la falla, utilice estos comandos:
show failover state- Este comando muestra el estado de failover de ambas unidades y el último motivo reportado para el failover.
firepower# show failover state
This host - Primary
Active Ifc Failure 19:14:54 UTC Sep 26 2023
Other host - Secondary
Failed Ifc Failure 19:31:35 UTC Sep 26 2023
OUTSIDE: No Link
show failover history- Muestra el historial de fallas. El historial de conmutación por error muestra los cambios de estado de conmutación por error pasados y el motivo del cambio de estado.
firepower# show failover history
==========================================================================
From State To State Reason
==========================================================================
19:31:35 UTC Sep 26 2023
Active Failed Interface check
This host:1
single_vf: OUTSIDE
Other host:0
Caso práctico: uso intensivo del disco
En caso de que el espacio en disco de la unidad activa esté más del 90% lleno, se activa un evento de failover.
Esta imagen describe las alertas generadas cuando el disco está lleno:
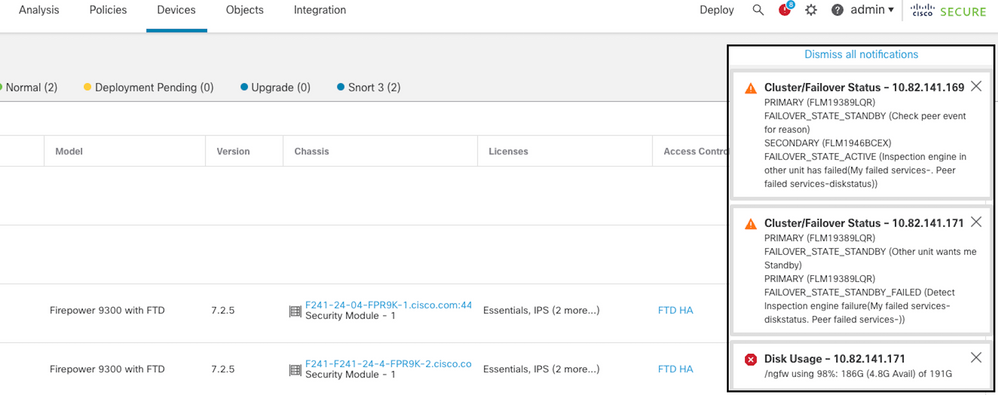 failover with disk usage
failover with disk usage
Para verificar la razón de la falla, utilice estos comandos:
show failover history- Muestra el historial de fallas. El historial de failover muestra los cambios de estado de failover pasados y el motivo de los cambios de estado.
firepower# show failover history
==========================================================================
From State To State Reason
==========================================================================
20:17:11 UTC Sep 26 2023
Active Standby Ready Other unit wants me Standby
Inspection engine in other unit has failed)
20:17:11 UTC Sep 26 2023. Standby Ready Failed Detect Inspection engine failure
Active due to disk failure
show failover- Muestra la información sobre el estado de failover de cada unidad.
firepower# show failover | include host|disk
This host: Primary - Failed
slot 2: diskstatus rev (1.0) status (down)
Other host: Secondary - Active
slot 2: diskstatus rev (1.0) status (up)
-
df -h- Muestra la información sobre todos los sistemas de archivos montados, que incluye el tamaño total, el espacio utilizado, el porcentaje de uso y el punto de montaje.
admin@firepower:/ngfw/Volume/home$ df -h /ngfw
Filesystem Size Used Avail Use% Mounted on
/dev/sda6 191G 186G 4.8G 98% /ngfw
Caso práctico: seguimiento de Lina
En el caso de un seguimiento de línea, se puede activar un evento de failover.
Esta imagen describe las alertas generadas en el caso de seguimiento de línea:
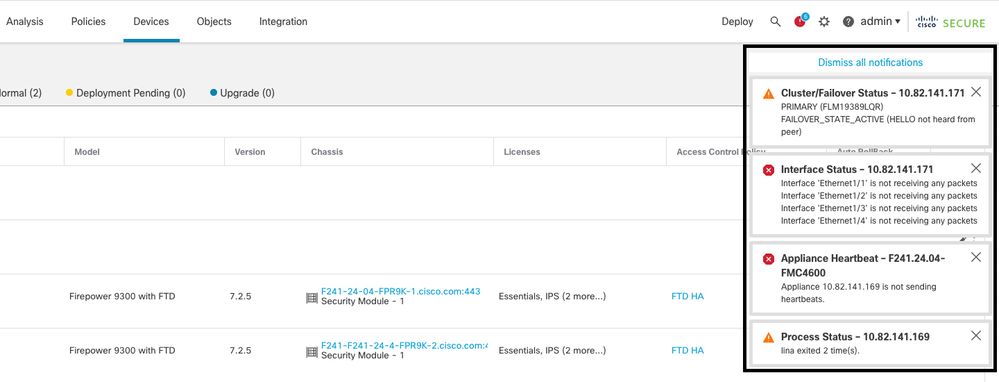 failover with lina traceback
failover with lina traceback
Para verificar la razón de la falla, utilice estos comandos:
show failover history- Muestra el historial de fallas. El historial de conmutación por fallas muestra los cambios de estado de conmutación por fallas pasados y la razón del cambio de estado.
firepower# show failover history
==========================================================================
From State To State Reason
==========================================================================
8:36:02 UTC Sep 27 2023
Standby Ready Just Active HELLO not heard from peer
(failover link up, no response from peer)
18:36:02 UTC Sep 27 2023
Just Active Active Drain HELLO not heard from peer
(failover link up, no response from peer)
18:36:02 UTC Sep 27 2023
Active Drain Active Applying Config HELLO not heard from peer
(failover link up, no response from peer)
18:36:02 UTC Sep 27 2023
Active Applying Config Active Config Applied HELLO not heard from peer
(failover link up, no response from peer)
18:36:02 UTC Sep 27 2023
Active Config Applied Active HELLO not heard from peer
(failover link up, no response from peer)
En el caso de lina traceback, utilice estos comandos para localizar los archivos de núcleo:
root@firepower:/opt/cisco/csp/applications# cd /var/data/cores
root@firepower:/var/data/cores# ls -l
total 29016
-rw------- 1 root root 29656250 Sep 27 18:40 core.lina.11.13995.1695839747.gz
En el caso del rastreo de líneas, se recomienda encarecidamente recopilar los archivos de troubleshooting, exportar los archivos Core y comunicarse con el TAC de Cisco.
Caso práctico: instancia de Snort caída
En caso de que más del 50% de las instancias de Snort en la unidad activa estén inactivas, se activa un failover.
Esta imagen describe las alertas generadas cuando falla el snort:
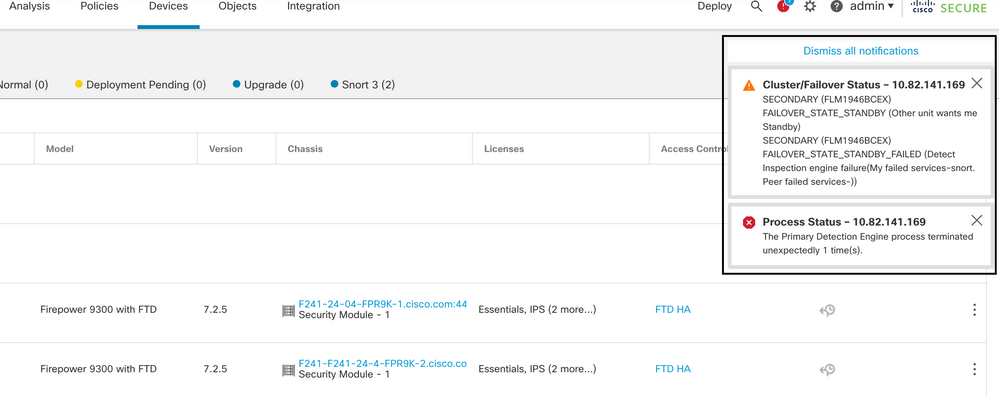 failover con snort traceback
failover con snort traceback
Para poder verifique la razón de la falla, utilice estos comandos:
show failover history- Muestra el historial de fallas. El historial de conmutación por fallas muestra los cambios de estado de conmutación por fallas pasados y la razón del cambio de estado.
firepower# show failover history
==========================================================================
From State To State Reason
==========================================================================
21:22:03 UTC Sep 26 2023
Standby Ready Just Active Inspection engine in other unit has failed
due to snort failure
21:22:03 UTC Sep 26 2023
Just Active Active Drain Inspection engine in other unit has failed
due to snort failure
21:22:03 UTC Sep 26 2023
Active Drain Active Applying Config Inspection engine in other unit has failed
due to snort failure
21:22:03 UTC Sep 26 2023
Active Applying Config Active Config Applied Inspection engine in other unit has failed
due to snort failure
show failover- Muestra la información sobre el estado de failover de la unidad.
firepower# show failover | include host|snort
This host: Secondart - Active
slot 1: snort rev (1.0) status (up)
Other host: Primary - Failed
slot 1: snort rev (1.0) status (down)
Firepower-module1#
En el caso de snort traceback, utilice estos comandos para localizar los archivos crashinfo o core:
For snort3:
root@firepower# cd /ngfw/var/log/crashinfo/
root@firepower:/ngfw/var/log/crashinfo# ls -l
total 4
-rw-r--r-- 1 root root 1052 Sep 27 17:37 snort3-crashinfo.1695836265.851283
For snort2:
root@firepower# cd/var/data/cores
root@firepower:/var/data/cores# ls -al total 256912 -rw-r--r-- 1 root root 46087443 Apr 9 13:04 core.snort.24638.1586437471.gz
En el caso del seguimiento de snort, se recomienda recopilar los archivos de solución de problemas, exportar los archivos de núcleo y ponerse en contacto con el TAC de Cisco.
Caso práctico: fallo de hardware o alimentación
El dispositivo FTD determina el estado de la otra unidad monitoreando el link de failover con los mensajes hello. Cuando una unidad no recibe tres mensajes hello consecutivos en el link de failover, y las pruebas fallan en las interfaces monitoreadas, se puede activar un evento de failover.
Esta imagen describe las alertas generadas cuando hay una falla de energía:
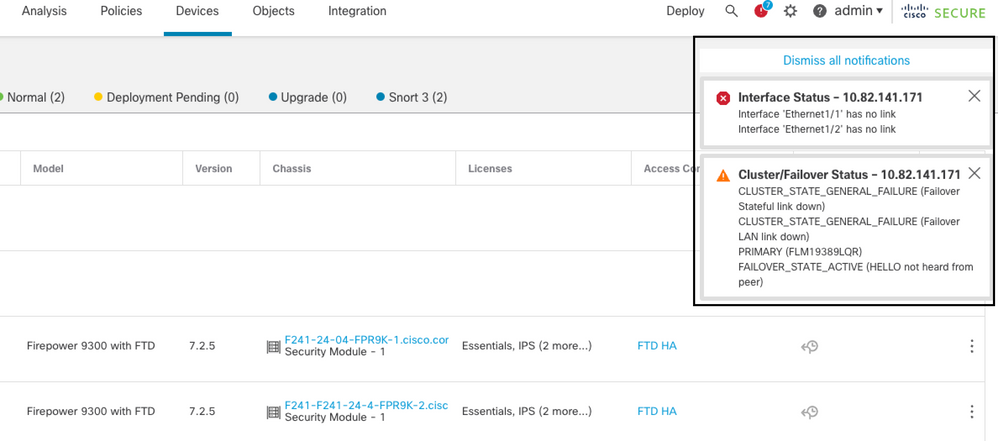 falla con falla de energía
falla con falla de energía
Para poder verifique la razón de la falla, utilice estos comandos:
show failover history- Muestra el historial de fallas. El historial de conmutación por fallas muestra los cambios de estado de conmutación por fallas pasados y la razón del cambio de estado.
firepower# show failover history
==========================================================================
From State To State Reason
==========================================================================
22:14:42 UTC Sep 26 2023
Standby Ready Just Active HELLO not heard from peer
(failover link down)
22:14:42 UTC Sep 26 2023
Just Active Active Drain HELLO not heard from peer
(failover link down
22:14:42 UTC Sep 26 2023
Active Drain Active Applying Config HELLO not heard from peer
(failover link down
22:14:42 UTC Sep 26 2023
Active Applying Config Active Config Applied HELLO not heard from peer
(failover link down)
22:14:42 UTC Sep 26 2023
Active Config Applied Active HELLO not heard from peer
(failover link down)
show failover state- Este comando muestra el estado de failover de ambas unidades y el último motivo reportado para el failover.
firepower# show failover state
State Last Failure Reason Date/Time
This host - Primary
Active None
Other host - Secondary
Failed Comm Failure 22:14:42 UTC Sep 26 2023
Caso práctico: fallo de latido MIO (dispositivos de hardware)
La instancia de la aplicación envía periódicamente latidos al supervisor. Cuando no se reciben las respuestas de latido, se puede activar un evento de failover.
Para poder verifique la razón de la falla, utilice estos comandos:
show failover history- Muestra el historial de fallas. El historial de conmutación por fallas muestra los cambios de estado de conmutación por fallas pasados y la razón del cambio de estado.
firepower# show failover history
==========================================================================
From State To State Reason
==========================================================================
02:35:08 UTC Sep 26 2023
Active Failed MIO-blade heartbeat failure
02:35:12 UTC Sep 26 2023
Failed Negotiation MIO-blade heartbeat recovered
.
.
.
02:37:02 UTC Sep 26 2023
Sync File System Bulk Sync Detected an Active mate
02:37:14 UTC Sep 26 2023
Bulk Sync Standby Ready Detected an Active mate
Cuando MIO-HeartBeat falla, se recomienda recopilar los archivos de solución de problemas, mostrar los registros técnicos de FXOS y ponerse en contacto con el TAC de Cisco.
Para Firepower 4100/9300, recopile el chasis show tech-support y el módulo show tech-support.
Para FPR1000/2100 y Secure Firewall 3100/4200, recopile el formulario show tech-support.
Información Relacionada
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
1.0 |
10-Oct-2023 |
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Oscar Montoya TorresIngeniero del TAC de Cisco
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)