Fallo en el disco duro único Ultra-M UCS 240M4 - Procedimiento intercambiable en caliente - CPAR
Opciones de descarga
-
ePub (618.9 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (250.5 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos necesarios para sustituir la unidad de disco duro (HDD) defectuosa en un servidor en una configuración Ultra-M.
Este procedimiento se aplica a un entorno Openstack con la versión NEWTON en el que ESC no administra CPAR y CPAR se instala directamente en la máquina virtual (VM) implementada en Openstack.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizada validada y empaquetada previamente diseñada para simplificar la implementación de funciones de red virtual (VNF). OpenStack es el Virtual Infrastructure Manager (VIM) para Ultra-M y consta de estos tipos de nodos:
- Informática
- Disco de almacenamiento de objetos - Compute (OSD - Compute)
- Controlador
- Plataforma OpenStack: Director (OSPD)
La arquitectura de alto nivel de Ultra-M y los componentes involucrados se ilustran en esta imagen:
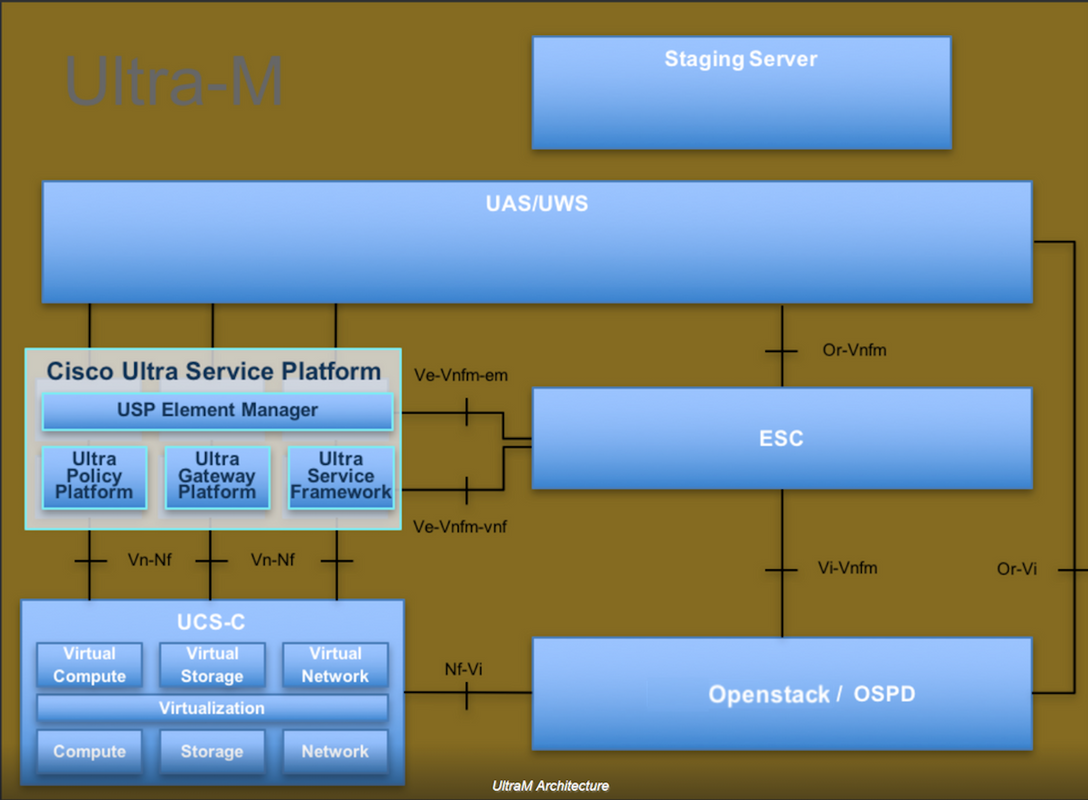
Este documento está dirigido al personal de Cisco familiarizado con la plataforma Cisco Ultra-M y detalla los pasos necesarios para llevarse a cabo a nivel de OpenStack en el momento de la sustitución del servidor OSPD.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
Abreviaturas
| VNF | Función de red virtual |
| MoP | Método de procedimiento |
| OSD | Discos de almacenamiento de objetos |
| OSPD | Director de plataforma OpenStack |
| HDD | Unidad de disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador de infraestructura virtual |
| VM | Máquina virtual |
| EM | Administrador de elementos |
| UAS | Servicios de ultra automatización |
| UUID | Identificador Universalmente Único |
Flujo de trabajo de MoP
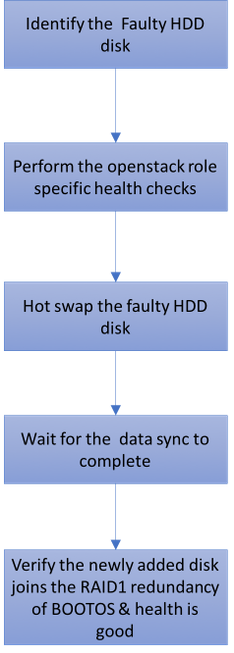
Fallo único del disco duro
- Cada servidor Baremetal se suministra con dos unidades HDD para actuar como DISCO BOOT en la configuración Raid 1. En caso de fallo único del disco duro, ya que hay redundancia de nivel RAID 1, la unidad de disco duro defectuosa puede intercambiarse en caliente.
- El procedimiento para reemplazar un componente defectuoso en el servidor UCS C240 M4 se puede hacer referencia desde: Sustitución de los Componentes del Servidor.
- En caso de fallo único del disco duro, sólo el disco duro defectuoso se intercambia en caliente y, por lo tanto, no se requiere ningún procedimiento de actualización del BIOS después de la sustitución de los discos nuevos.
- Después de la sustitución de los discos, debe esperar la sincronización de los datos entre los discos. Puede tardar horas en completarse.
- En la solución basada en OpenStack (Ultra-M), el servidor de estructura básica UCS 240M4 puede asumir una de estas funciones: Compute, OSD-Compute, Controller y OSPD. Los pasos requeridos para manejar una falla de HDD en cada una de estas funciones de servidor son los mismos y la sección aquí describe las verificaciones de estado que deben realizarse antes del intercambio en caliente del disco.
Fallo de disco duro único en servidor informático
- Si se observa la falla de las unidades HDD en UCS 240M4, que actúa como nodo informático, realice estas comprobaciones de estado antes de realizar el intercambio en caliente del disco defectuoso.
- Identifique las VM que se ejecutan en este servidor y verifique que el estado de las funciones sea bueno.
Identificación de VM alojadas en el nodo informático
Identifique las VM alojadas en el servidor informático y verifique que estén activas y en ejecución.
[stack@director ~]$ nova list | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
Comprobaciones de estado
Paso 1. Ejecute el comando /opt/CSCOar/bin/arstatus a nivel del sistema operativo (OS).
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Paso 2. Ejecute el comando /opt/CSCOar/bin/aregcmd a nivel del sistema operativo e ingrese las credenciales de administración. Compruebe que el CPAR Health es 10 de 10 y salga del CPAR CLI.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
Paso 3. Ejecute el comando netstat | diámetro grep y verifique que se hayan establecido todas las conexiones Diámetro Routing Agent (DRA).
El resultado mencionado aquí es para un entorno en el que se esperan links Diámetro. Si se muestran menos enlaces, esto representa una desconexión del DRA que se debe analizar.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Paso 4. Compruebe que el registro de TPS muestra las solicitudes que está procesando el CPAR. Los valores resaltados representan el TPS y son a los que debe prestar atención.
El valor de TPS no debe ser superior a 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Paso 5. Busque cualquier mensaje de "error" o "alarma" en name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Paso 6. Para verificar la cantidad de memoria que utiliza el proceso CPAR, ejecute el comando:
top | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Este valor resaltado debe ser inferior a 7 Gb, que es el máximo permitido en el nivel de aplicación.
Paso 7. Para verificar la utilización del disco, ejecute el comando df -h.
[root@aaa02 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg_arucsvm51-lv_root 26G 21G 4.1G 84% / tmpfs 1.9G 268K 1.9G 1% /dev/shm /dev/sda1 485M 37M 424M 8% /boot /dev/mapper/vg_arucsvm51-lv_home 23G 4.3G 17G 21% /home
Este valor general debe ser inferior al 80%, si es superior al 80%, identifique los archivos innecesarios y límpielos.
Paso 8. Verifique que no se haya generado ningún archivo "core".
- El archivo principal se genera en caso de que se produzca un fallo en la aplicación cuando el CPAR no puede controlar una excepción y se genera en estas dos ubicaciones:
[root@aaa02 ~]# cd /cisco-ar/ [root@aaa02 ~]# cd /cisco-ar/bin
No debe haber ningún archivo de núcleo ubicado en estas dos ubicaciones. Si se encuentra, cree un caso del TAC de Cisco para identificar la causa raíz de dicha excepción y adjuntar los archivos de núcleo para la depuración.
- Si las comprobaciones de estado están bien, continúe con el procedimiento de intercambio en caliente de disco defectuoso y espere a que se sincronice la información, ya que se tardan horas en completarse .
Sustitución de los componentes del servidor
- Repita los procedimientos de comprobación de estado para confirmar que se ha restaurado el estado de las VM alojadas en el nodo informático.
Fallo de disco duro único en servidor controlador
- Si se observa la falla de las unidades HDD en UCS 240M4, que actúa como nodo Controlador, realice estas comprobaciones de estado antes de realizar el intercambio en caliente del disco defectuoso.
- Verifique el estado del marcapasos en los controladores.
- Inicie sesión en uno de los controladores activos y verifique el estado del marcapasos. Todos los servicios deben estar ejecutándose en los controladores disponibles y se deben detener en el controlador con fallas.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Tue Jul 10 10:04:15 2018Last change: Fri Jul 6 09:03:35 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
- Verifique el estado de MariaDB en los controladores activos.
[stack@director ~]$ nova list | grep control
| b896c73f-d2c8-439c-bc02-7b0a2526dd70 | pod2-stack-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.113 |
| 2519ce67-d836-4e5f-a672-1a915df75c7c | pod2-stack-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| e19b9625-5635-4a52-a369-44310f3e6a21 | pod2-stack-controller-2 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
[stack@director ~]$ for i in 192.200.0.102 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_ state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st5 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st3 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_st ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_s1 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_9 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local2 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_loca. ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_loc2 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_lo0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_l0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_. ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsre. ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsr1 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'ws2 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'w0 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE '
*** 192.200.0.102 ***
Variable_nameValue
wsrep_local_state_commentSynced
Variable_nameValue
wsrep_cluster_size2
*** 192.200.0.110 ***
Variable_nameValue
wsrep_local_state_commentSynced
Variable_nameValue
wsrep_cluster_size2
- Verifique que estas líneas estén presentes para cada controlador activo:
wsrep_local_state_comment: Synced wsrep_cluster_size: 2
- Verifique el estado Rabbitmq en los controladores activos.
[heat-admin@pod2-stack-controller-0 ~]$ sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod2-stack-controller-0' ...
[{nodes,[{disc,['rabbit@pod2-stack-controller-0',
'rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-2']}]},
{running_nodes,['rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-2',
'rabbit@pod2-stack-controller-0']},
{cluster_name,<<"rabbit@pod2-stack-controller-1.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod2-stack-controller-1',[]},
{'rabbit@pod2-stack-controller-2',[]},
{'rabbit@pod2-stack-controller-0',[]}]}]
- Si las comprobaciones de estado están bien, continúe con el procedimiento de intercambio en caliente de disco defectuoso y espere a que se sincronice la información, ya que se tardan horas en completarse .
Sustitución de los componentes del servidor
- Repita los procedimientos de comprobación de estado para confirmar que se ha restaurado el estado de estado en el controlador.
Fallo de disco duro único en servidor OSD-Compute
- Si se observa la falla de las unidades HDD en UCS 240M4, que actúa como nodo OSD-Compute, realice las comprobaciones de estado antes de realizar el intercambio en caliente del disco defectuoso.
- Identificación de las VM alojadas en el nodo de informática OSD
- Identificar las VM alojadas en el servidor informático
[stack@director ~]$ nova list | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
- Los procesos CEPH están activos en el servidor de osd-compute.
[heat-admin@pod2-stack-osd-compute-1 ~]$ systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d1.mount loaded active mounted /var/lib/ceph/osd/ceph-1
var-lib-ceph-osd-ceph\x2d10.mount loaded active mounted /var/lib/ceph/osd/ceph-10
var-lib-ceph-osd-ceph\x2d4.mount loaded active mounted /var/lib/ceph/osd/ceph-4
var-lib-ceph-osd-ceph\x2d7.mount loaded active mounted /var/lib/ceph/osd/ceph-7
ceph-osd@1.service loaded active running Ceph object storage daemon
ceph-osd@10.service loaded active running Ceph object storage daemon
ceph-osd@4.service loaded active running Ceph object storage daemon
ceph-osd@7.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
14 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
- Compruebe que la asignación de OSD (disco duro) al Diario (SSD) sea correcta.
[heat-admin@pod2-stack-osd-compute-1 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
- Verifique que el estado de la ceph y el mapeo del árbol osd sean buenos.
[heat-admin@pod2-stack-osd-compute-1 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e81: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v23095222: 704 pgs, 6 pools, 809 GB data, 424 kobjects
2418 GB used, 10974 GB / 13393 GB avail
704 active+clean
client io 1329 kB/s wr, 0 op/s rd, 122 op/s wr
[heat-admin@pod2-stack-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod2-stack-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod2-stack-osd-compute-1
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod2-stack-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
- Si las comprobaciones de estado son correctas, continúe con el procedimiento de intercambio en caliente de disco defectuoso y espere a que se sincronice la información, ya que tarda horas en completarse.
Sustitución de los componentes del servidor
- Repita los procedimientos de comprobación de estado para confirmar que se ha restaurado el estado de las VM alojadas en el nodo OSD-Compute.
Fallo de disco duro único en servidor OSPD
- Si se observa la falla de las unidades HDD en UCS 240M4, que actúa como nodo OSPD, realice las comprobaciones de estado antes de realizar el intercambio en caliente del disco defectuoso.
- Verifique el estado de la pila openstack y la lista de nodos.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
- Compruebe si todos los servicios de la nube inferior están en estado cargado, activo y en ejecución desde el nodo OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-metadata-agent.service loaded active running OpenStack Neutron Metadata Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
lines 1-43
lines 2-44 37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
lines 4-46/46 (END) lines 4-46/46 (END) lines 4-46/46 (END) lines 4-46/46 (END) lines 4-46/46 (END)
- Si las comprobaciones de estado son correctas, continúe con el procedimiento de intercambio en caliente de disco defectuoso y espere a que se sincronice la información, ya que tarda horas en completarse.
Sustitución de los componentes del servidor
- Repita los procedimientos de comprobación de estado para confirmar que se restaura el estado de estado del nodo OSPD.
Con la colaboración de ingenieros de Cisco
- Karthikeyan DachanamoorthyCisco Advanced Services
- Harshita BhardwajCisco Advanced Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)