Gestión de nivel de servicio: Informe oficial de Mejores Prácticas
Contenido
Introducción
Este documento describe la administración de nivel de servicio y los acuerdos de nivel de servicio (SLA) para las redes de alta disponibilidad. Incluye los factores de éxito importantes para que la administración de nivel de servicio y los indicadores de rendimiento ayuden a evaluar el éxito. El documento también provee detalles significativos de los SLA que siguen pautas de práctica identificadas por el equipo de servicio de gran disponibilidad.
Descripción general de la administración de niveles de servicio
Tradicionalmente, las organizaciones de redes han satisfecho los requisitos de ampliación de la red mediante la creación de infraestructuras de red sólidas y la labor reactiva para hacer frente a los problemas de los servicios individuales. Cuando ocurra una interrupción, la organización construirá nuevos procesos, capacidades de administración o infraestructura para evitar que una interrupción particular vuelva a ocurrir. Sin embargo, debido a una tasa de cambio más alta y a los requisitos de disponibilidad cada vez mayores, ahora necesitamos un modelo mejorado para evitar de forma proactiva el tiempo de inactividad no planificado y reparar rápidamente la red. Muchas organizaciones empresariales y proveedores de servicios han intentado definir mejor el nivel de servicio necesario para alcanzar los objetivos empresariales.
Factores de éxito críticos
Los factores de éxito críticos para los SLA se utilizan para definir elementos clave para crear con éxito niveles de servicio alcanzables y para mantener los SLA. Para calificar como un factor crítico del éxito, un proceso o un paso del proceso debe mejorar la calidad del SLA y beneficiar la disponibilidad de la red en general. El factor crítico del éxito también debe ser cuantificable para que la organización pueda determinar cuán exitoso ha sido con relación al procedimiento definido.
Para obtener más información, consulte Implementación de la administración de nivel de servicio.
Indicadores de rendimiento
Los indicadores de rendimiento brindan el mecanismo por el cual una organización mide los factores de éxito críticos. Normalmente, los revisa mensualmente para asegurarse de que las definiciones de nivel de servicio o los SLA funcionan correctamente. El grupo de operaciones de red y los grupos de herramientas necesarias pueden realizar las siguientes mediciones.
Nota: Para las organizaciones sin SLA, le recomendamos que realice definiciones de nivel de servicio y revisiones de nivel de servicio además de métricas.
Los indicadores de rendimiento comprenden:
-
Definición de nivel de servicio o SLA documentada que incluye disponibilidad, rendimiento, tiempo de respuesta del servicio reactivo, objetivos de resolución de problemas y escalación de problemas.
-
Reunión mensual de revisión del nivel de servicio de redes para revisar el cumplimiento del nivel de servicio e implementar mejoras.
-
Indicadores de rendimiento, que incluyen la disponibilidad, el rendimiento, el tiempo de respuesta del servicio por prioridad, el tiempo de resolución por prioridad y otros parámetros de SLA mensurables.
Consulte Implementación de la administración de nivel de servicio, para obtener más información.
Flujo del proceso de administración de nivel de servicio
El flujo del proceso de alto nivel para la administración de nivel de servicio contiene dos grupos principales:
Haga clic en los objetos del siguiente diagrama para ver los detalles de ese paso.
Implementación de la administración de nivel de servicio
La implementación de la administración de nivel de servicio consta de dieciséis pasos divididos en las dos categorías principales siguientes:
Definición de los Niveles de Servicio de Red
Los administradores de red deben definir las principales reglas mediante las cuales se admite, gestiona y mide la red. Los niveles de servicio representan metas para todo el personal de la red y se pueden utilizar como métrica de la calidad de todo el servicio. También puede usar las definiciones de nivel de servicio como una herramienta para presupuestar los recursos de la red y como evidencia por si fueran necesarios más fondos QoS. También proveen una forma de evaluar al proveedor y el rendimiento de la portadora.
Sin una medición y definición de nivel de servicio, la organización no tiene objetivos bien definidos. La satisfacción del servicio debe regirse por los usuarios sin grandes diferencias entre aplicaciones, operaciones servidor/cliente o soporte de red. La presupuestación puede resultar más difícil porque el resultado final no es claro para la organización y, por último, la organización de red tiende a ser más reactiva, no proactiva, a la hora de mejorar la red y el modelo de soporte.
Recomendamos los siguientes pasos para crear y admitir un modelo de nivel de servicio:
-
Cree perfiles de aplicación que detallen las características de red de las aplicaciones críticas.
-
Defina los estándares de disponibilidad y rendimiento y defina términos comunes.
-
Recopile métricas y supervise la definición de nivel de servicio.
Paso 1: Analizar los objetivos técnicos y las limitaciones
La mejor forma de comenzar a analizar objetivos y restricciones técnicas es generar una tormenta de ideas o investigar objetivos y requisitos técnicos. A veces ayuda invitar a otros técnicos IT para que se sumen al debate ya que ellos tienen objetivos específicos relativos a sus servicios. Entre los objetivos técnicos se incluyen los niveles de disponibilidad, rendimiento, fluctuación, retraso, tiempo de respuesta, requisitos de escalabilidad, introducción de nuevas funciones, introducción de nuevas aplicaciones, seguridad, capacidad de gestión e incluso coste. La organización luego debe investigar las limitaciones para alcanzar esos objetivos dados los recursos disponibles. Puede crear una hoja de trabajo para cada objetivo con una explicación de las restricciones. Inicialmente, puede parecer que la mayoría de los objetivos no se pueden alcanzar. Luego, comience a priorizar los objetivos o a disminuir las expectativas que aún pueden cumplir con los requisitos de la empresa.
Por ejemplo, puede tener un nivel de disponibilidad del 99,999% o 5 minutos de tiempo de inactividad al año. Hay varias restricciones para alcanzar este objetivo, por ejemplo, puntos individuales de errores en el hardware, Tiempo intermedio para reparar (MTTR) hardware dañado en ubicaciones remotas, confiabilidad de la portadora, capacidades de detección de fallas proactivas, velocidades de cambio altas y limitaciones de la capacidad de la red actual. Como resultado, puede ajustar el objetivo a un nivel más alcanzable. El modelo de disponibilidad de la sección siguiente puede ayudarle a establecer objetivos realistas.
También puede considerar proporcionar una mayor disponibilidad en ciertas áreas de la red que poseen menos restricciones. Cuando la organización de la red publica estándares de servicio para disponibilidad, los grupos de negocios dentro de la organización pueden hallar inaceptable este nivel. Éste es, entonces, un punto natural para iniciar discusiones SLA o modelos de financiación/presupuesto que puedan satisfacer los requisitos comerciales.
Haga lo necesario para identificar todas las restricciones o riesgos que conlleva la realización del objetivo técnico. Dé prioridad a las restricciones en función del riesgo o impacto al objetivo deseado. Esto ayuda a la organización a priorizar las iniciativas de mejora de la red y a determinar con qué facilidad se puede hacer frente a las restricciones. Hay tres tipos de restricciones:
-
Tecnología de red, resistencia y configuración
-
Prácticas del ciclo de vida, incluidas la planificación, el diseño, la implementación y el funcionamiento
-
Carga de tráfico actual o comportamiento de la aplicación
La tecnología de red, la resistencia y las restricciones de configuración son limitaciones o riesgos asociados a la tecnología, el hardware, los enlaces, el diseño o la configuración actuales. Las limitaciones de la tecnología abarcan cualquier restricción que pueda presentar la tecnología en si misma. Por ejemplo, ninguna tecnología actual permite tiempos de convergencia de menos de un segundo en entornos de red redundantes, lo que puede ser fundamental para mantener las conexiones de voz a través de la red. Otro ejemplo puede ser la velocidad en bruto que los datos pueden recorrer en los enlaces terrestres, que es de aproximadamente 100 millas por milisegundo.
Las investigaciones de riesgo de resistencia de hardware de red deben centrarse en la topología de hardware, la jerarquía, la modularidad, la redundancia y el MTBF a lo largo de las rutas definidas en la red. Las limitaciones de los enlaces de red deben centrarse en los enlaces de red y la conectividad de los operadores para las organizaciones empresariales. Las restricciones de enlace pueden incluir redundancia de enlaces y diversidad, limitaciones de medios, infraestructuras de cableado, conectividad de loop local y conectividad de larga distancia. Las restricciones de diseño se relacionan con el diseño físico o lógico de la red e incluyen todo, desde el espacio disponible para el equipo hasta la escalabilidad de la implementación del protocolo de ruteo. Todos los diseños de protocolos y medios deben tenerse en cuenta en relación con la configuración, disponibilidad, escalabilidad, rendimiento y capacidad. También deben tenerse en cuenta las restricciones de los servicios de red, como el protocolo de configuración dinámica de host (DHCP), el sistema de nombres de dominio (DNS), los firewalls, los traductores de protocolos y los traductores de direcciones de red.
Las prácticas del ciclo de vida definen los procesos y la gestión de la red que se utilizan para implementar soluciones de forma uniforme, detectar y reparar problemas, evitar problemas de capacidad o rendimiento y configurar la red para lograr coherencia y modularidad. Debe considerar esta área porque la falta de disponibilidad generalmente depende de la experiencia y los procesos. El ciclo de vida de la red se refiere al ciclo de planificación, diseño, implementación y operaciones. Dentro de cada una de estas áreas, usted debe entender la funcionalidad de la administración de red, tales como la administración de rendimiento, la administración de configuración, el tratamiento de fallas y la seguridad. Los servicios de servicios de alta disponibilidad (HAS) de Cisco NSA ofrecen una evaluación del ciclo de vida de la red que muestra las actuales limitaciones de disponibilidad de la red asociadas a las prácticas del ciclo de vida de la red.
La carga de tráfico actual o las restricciones de las aplicaciones simplemente hacen referencia al impacto del tráfico y las aplicaciones actuales.
Desafortunadamente, muchas aplicaciones tienen restricciones significativas que requieren una administración cuidadosa. Los requisitos de fluctuación, retraso, rendimiento y ancho de banda para las aplicaciones actuales suelen tener muchas restricciones. La forma en que se ha escrito la aplicación también puede causar restricciones. La definición de perfiles de aplicaciones le ayuda a comprender mejor estos problemas; la siguiente sección cubre esta función. La investigación de la disponibilidad, el tráfico, la capacidad y el rendimiento actuales en general también ayuda a los administradores de red a comprender las expectativas y los riesgos actuales del nivel de servicio. Esto se consigue normalmente con un proceso denominado establecimiento de líneas de base de red, que ayuda a definir los promedios de rendimiento, disponibilidad o capacidad de la red durante un período de tiempo definido, normalmente de aproximadamente un mes. Esta información se utiliza normalmente para la planificación de la capacidad y las tendencias, pero también se puede utilizar para comprender los problemas de nivel de servicio.
La siguiente hoja de trabajo usa el ya mencionado método objetivo/limitación para el ejemplo del objetivo de prevención de un ataque a la seguridad o un ataque de Negación de servicio (DoS). También puede utilizar esta hoja de cálculo para ayudar a determinar la cobertura del servicio para minimizar los ataques de seguridad.
| Riesgo o restricción | Tipo de restricción | Impacto potencial |
|---|---|---|
| Las herramientas de detección de DoS disponibles no pueden detectar todos los tipos de ataques de DoS. | Tecnología/resistencia | Alto |
| No cuente con el personal y el proceso necesarios para reaccionar ante las alertas. | Prácticas del ciclo de vida | Alto |
| Las políticas de acceso a la red actuales no están implementadas. | Prácticas del ciclo de vida | Medio |
| La conexión a Internet de menor ancho de banda actual puede ser un factor si se utiliza la congestión del ancho de banda para los ataques. | Capacidad de red | Medio |
| Es posible que la configuración de seguridad actual para ayudar a evitar ataques no sea exhaustiva. | Tecnología/resistencia | Medio |
Paso 2: Determinar el presupuesto de disponibilidad
Un presupuesto de disponibilidad es la disponibilidad teórica esperada de la red entre dos puntos definidos. La información teórica precisa es útil de varias maneras:
-
La organización puede utilizar esto como objetivo de disponibilidad interna y las desviaciones pueden ser definidas y solucionadas rápidamente.
-
Los planificadores de la red pueden utilizar la información al determinar la disponibilidad del sistema para ayudar a garantizar que el diseño reunirá los requisitos del negocio.
Entre los factores que contribuyen a la falta de disponibilidad o al tiempo de interrupción se incluyen la falla de hardware, la falla de software, los problemas de energía y ambientales, la falla de link o portadora, el diseño de la red, los errores humanos o la falta de proceso. Deberá evaluar detenidamente cada uno de estos parámetros al considerar el presupuesto de disponibilidad general para la red.
Si la organización mide actualmente la disponibilidad, es posible que no necesite un presupuesto de disponibilidad. Use la medición de la disponibilidad como línea de base para estimar el nivel de servicio actual usado para una definición del nivel del servicio. Sin embargo, puede que le interese comparar ambos para comprender la disponibilidad teórica potencial comparada con el resultado real medido.
La disponibilidad es la probabilidad de que un producto o servicio funcione cuando sea necesario. Consulte las siguientes definiciones:
-
Disponibilidad
-
1 - (tiempo total de interrupción de la conexión) / (tiempo total de conexión en servicio)
-
1 - [Sigma(conexiones num afectadas en la interrupción i X duración de la interrupción i)] / (num contiene en el tiempo de funcionamiento del servicio X)
-
-
Falta de disponibilidad
1 – Disponibilidad o tiempo de interrupción total de la conexión debido a (falla de hardware, falla de software, problemas de entorno y de energía, falla de link o de portadora, diseño de red, o error de usuario y falla de proceso).
-
Disponibilidad del hardware
El primer área que hay que investigar es la posible falla de hardware y el efecto en la indisponibilidad. Para determinar esto, la organización debe comprender el MTBF de todos los componentes de la red y el MTTR para los problemas de hardware de todos los dispositivos en un trayecto entre dos puntos. Si la red es modular y jerárquica, la disponibilidad del hardware será la misma entre casi dos puntos cualesquiera. La información de MTBF está disponible para todos los componentes de Cisco y está disponible bajo petición a un gerente de cuentas local. El programa Cisco NSA HAS también utiliza una herramienta para ayudar a determinar la disponibilidad de hardware en los trayectos de redes, aún cuando existe redundancia de módulo, chasis y trayectos en el sistema. Un factor importante de la confiabilidad del hardware es el MTTR. Las organizaciones deben evaluar con qué rapidez pueden reparar el hardware dañado. Si la organización no tiene un plan de reserva y confía en un acuerdo estándar Cisco SMARTnet™, el tiempo medio de sustitución potencial es aproximadamente de 24 horas. En un entorno LAN típico con redundancia de núcleo y sin redundancia de acceso, la disponibilidad aproximada es del 99,99% con un MTTR de 4 horas.
-
Disponibilidad de software
El siguiente área de investigación son las fallas de software. Para fines de medición, Cisco define las fallas de software como el inicio en frío del dispositivo debido a un error de software. Cisco ha realizado importantes avances en la comprensión de la disponibilidad del software; sin embargo, las versiones más recientes tardan en medirse y se consideran menos disponibles que el software de implementación general. El software de implementación general, como la versión 11.2(18) del IOS, se ha medido en más del 99,9999 por ciento de disponibilidad. Esto se calcula en base al inicio sin presencia de red vigente en los routers Cisco usando seis minutos como tiempo de reparación (tiempo para que el router se recargue). Se supone que las organizaciones con diferentes versiones tienen una menor disponibilidad debido a la complejidad añadida, la interoperatividad y el aumento en los tiempos de resolución de problemas. Se espera que las organizaciones que poseen las últimas versiones de software tengan una menor disponibilidad. La distribución para la no disponibilidad también es bastante amplia, lo que implica que los clientes podrían experimentar una significativa no disponibilidad o disponibilidad cercana a la versión de despliegue general.
-
Disponibilidad de energía y medio ambiente
Debe también considerar problemas de entorno y de energía en disponibilidad. Los problemas ambientales se refieren a la desintegración de los sistemas de refrigeración necesarios para mantener el equipo a una temperatura de funcionamiento determinada. Muchos dispositivos de Cisco simplemente se apagarán cuando se encuentren fuera de las especificaciones en lugar de correr el riesgo de sufrir daños en todo el hardware. A efectos de un presupuesto de disponibilidad, se utilizará la energía porque es la principal causa de no disponibilidad en esta área.
Aunque los fallos de alimentación son un aspecto importante para determinar la disponibilidad de la red, esta conversación es limitada porque el análisis teórico de la potencia no se puede realizar con precisión. Lo que debe evaluar la organización para asegurar una energía de calidad consistente para todos los dispositivos, es una medida aproximada de la disponibilidad de energía para sus dispositivos de acuerdo a su experiencia en el área geográfica, la cantidad de energía de respaldo disponible y los procesos implementados.
Para una evaluación conservadora, podemos decir que una organización con generadores de respaldo, sistemas de fuente de alimentación ininterrumpida (UPS) y procesos de implementación de energía de calidad puede experimentar seis nueves de disponibilidad, o el 99,9999 por ciento, mientras que las organizaciones sin estos sistemas pueden experimentar una disponibilidad del 99,99 por ciento, o aproximadamente 36 minutos de tiempo de inactividad anualmente. Por supuesto, puede ajustar estos valores a valores más realistas en función de la percepción o los datos reales de la organización.
-
Falla de link o portadora
Los fallos de enlaces y operadores son los principales factores relacionados con la disponibilidad en los entornos WAN. Tenga en cuenta que los entornos WAN son simplemente otras redes que están sujetas a los mismos problemas de disponibilidad que la red de la organización, incluidos fallos de hardware, fallos de software, errores de usuario y fallos de alimentación.
Muchas redes de operadores ya han realizado un presupuesto de disponibilidad en sus sistemas, pero obtener esta información puede resultar difícil. Tenga en cuenta que los operadores también suelen tener niveles de garantía de disponibilidad que tienen poca o ninguna base sobre un presupuesto de disponibilidad real. Estos niveles de garantía son a veces simplemente métodos de comercialización y venta utilizados para promover al transportista. En algunos casos, estas redes también publican estadísticas de disponibilidad que parecen extremadamente buenas. Tenga en cuenta que estas estadísticas pueden aplicarse solamente a redes de núcleo completamente redundantes y no tienen en cuenta la falta de disponibilidad debido al acceso de loop local, que es un factor importante para la no disponibilidad en redes WAN.
La creación de una estimación de la disponibilidad para los entornos WAN debe basarse en la información real del operador y en el nivel de redundancia para la conectividad WAN. Si una organización cuenta con varias instalaciones de entrada a edificios, proveedores de bucle local redundantes, acceso local a Synchronous-Optical-Network (SONET) y operadores de larga distancia redundantes con diversidad geográfica, la disponibilidad de WAN mejorará considerablemente.
El servicio telefónico es un presupuesto de disponibilidad bastante preciso para conectividad de red no redundante en entornos WAN. La conectividad de extremo a extremo para teléfonos tiene un presupuesto de disponibilidad aproximado del 99,94% utilizando una metodología de presupuesto de disponibilidad similar a la descrita en esta sección. Esta metodología se ha utilizado con éxito en entornos de datos con una leve variación únicamente y, en la actualidad, se utiliza como objetivo en la especificación del cable de paquetes para redes de cable de proveedores de servicio. Si aplicamos este valor a un sistema completamente redundante, podemos suponer que la disponibilidad de la WAN estará cerca del 99,9999% disponible. Por supuesto, muy pocas organizaciones cuentan con sistemas WAN completamente redundantes y geográficamente dispersos debido a los gastos y la disponibilidad, por lo que deben tener en cuenta esta capacidad.
Las fallas de link en un entorno LAN son menos probables. Sin embargo, es posible que los planificadores deseen asumir un pequeño tiempo de inactividad debido a conectores sueltos o rotos. Para las redes LAN, una estimación conservadora es aproximadamente del 99,9999% de disponibilidad, es decir, unos 30 segundos al año.
-
Diseño de red
El diseño de la red es otro factor importante para la disponibilidad. Los diseños no escalables, los errores de diseño y el tiempo de convergencia de la red afectan negativamente a la disponibilidad.
Nota: A efectos de este documento, los errores de diseño o diseño no escalables se incluyen en la siguiente sección.
El diseño de red se limita entonces a un valor medible basado en fallos de software y hardware en la red que provocan el reenrutamiento del tráfico. Habitualmente, este valor se denomina “tiempo de traspaso del sistema” y es un factor de las capacidades de reparación propia del protocolo dentro del sistema.
Calcule la disponibilidad simplemente utilizando los mismos métodos para los cálculos del sistema. Sin embargo, esto no es válido a menos que el tiempo de conmutación de la red cumpla los requisitos de las aplicaciones de red. Si el tiempo de switchover es aceptable, quítelo del cálculo. Si el tiempo de switchover no es aceptable, debe agregarlo a los cálculos. Un ejemplo puede ser la voz sobre IP (VoIP) en un entorno en el que el tiempo de conmutación estimado o real es de 30 segundos. En este ejemplo, los usuarios simplemente colgarán el teléfono y posiblemente lo intentarán de nuevo. Seguramente, los usuarios considerarán a este período de tiempo como de no disponibilidad, pero no se ha calculado en el presupuesto de disponibilidad.
Calcule la falta de disponibilidad debido al tiempo de conmutación del sistema observando la disponibilidad teórica del software y el hardware a lo largo de las rutas redundantes, porque el switchover ocurrirá en esta área. Debe saber el número de dispositivos que pueden fallar y causar el intercambio en el trayecto redundante, el MTFB de esos dispositivos y el tiempo de intercambio. Un ejemplo sencillo sería un MTBF de 35.433 horas para cada uno de los dos dispositivos idénticos redundantes y un tiempo de conmutación de 30 segundos. Dividiendo 35 433 por 8766 (el promedio de horas al año incluía años bisiestos), vemos que el dispositivo fallará una vez cada cuatro años. Si utilizamos 30 segundos como tiempo de switchover, entonces podemos suponer que cada dispositivo experimentará, en promedio, 7,5 segundos por año de no disponibilidad debido al switchover. Dado que los usuarios pueden atravesar cualquiera de las rutas, el resultado se duplica a 15 segundos al año. Cuando esto se calcula en términos de segundos por año, la cantidad de disponibilidad debida al switchover se puede calcular como disponibilidad del 99.9999785% en este simple sistema. Esto puede ser mayor en otros entornos debido a la cantidad de dispositivos redundantes en la red en la cual hay posibilidades de que ocurra una conmutación.
-
Error de usuario y proceso
Las causas más importantes de no disponibilidad en empresas y redes portadoras son los errores del usuario y los problemas de disponibilidad del proceso. Aproximadamente el 80% de la falta de disponibilidad se produce debido a problemas como la no detección de errores, fallos de cambios y problemas de rendimiento.
Las organizaciones simplemente no querrán usar cuatro veces el resto de la no disponibilidad teórica para determinar el presupuesto de disponibilidad, sin embargo, las pruebas sugieren de manera concluyente que esto es lo que ocurre en muchos entornos. En la siguiente sección se desarrolla este aspecto de no disponibilidad más detenidamente.
Puesto que teóricamente no puede calcular la cantidad de no disponibilidad debido a errores de usuario y procesos, le recomendamos que elimine esta cantidad del presupuesto de disponibilidad y que las organizaciones se esfuercen por alcanzar la perfección. La única advertencia es que las organizaciones deben comprender el riesgo actual de disponibilidad en sus propios procesos y niveles de experiencia. Una vez que comprendan mejor estos riesgos e inhibidores, es posible que los planificadores de la red deseen contabilizar alguna cantidad de no disponibilidad debido a estos inconvenientes. El programa NSA HAS de Cisco investiga estos problemas y puede ayudar a las organizaciones a entender una no disponibilidad potencial debido al proceso, a un error de usuario o a problemas de conocimiento.
-
Determinación del presupuesto de disponibilidad final
Puede determinar el presupuesto general de disponibilidad al multiplicar la disponibilidad para cada una de las áreas definidas anteriormente. Esto se hace típicamente en entornos homogéneos en los que la conectividad es similar entre dos puntos, como por ejemplo un entorno LAN jerárquico modular o un entorno WAN jerárquico estándar.
En este ejemplo, el presupuesto de disponibilidad se realiza para un entorno de LAN modular jerárquico. El entorno utiliza generadores de respaldo y sistemas de UPS para todos los componentes de red y gestiona adecuadamente la alimentación. La organización no utiliza VoIP y no desea incluir como factor el tiempo de intercambio de software. Los cálculos son:
-
Disponibilidad de la ruta de hardware entre dos terminales = disponibilidad del 99,99%
-
La disponibilidad de software usando como referencia la confiabilidad del software GD = 99.9999 % de disponibilidad
-
Disponibilidad ambiental y energética con sistemas de copia de seguridad = disponibilidad del 99,999%
-
Falla de link en el entorno LAN = disponibilidad del 99,9999 por ciento
-
Tiempo de conmutación del sistema sin tener en cuenta = disponibilidad del 100%
-
Error de usuario y disponibilidad de proceso perfectos = disponibilidad del 100 por ciento
El presupuesto final de disponibilidad que deben buscar las organizaciones equivale a 0.9999 X 0.999999 X 0.999999 X 0.999999 = 0.999896, o una disponibilidad del 99.9896 por ciento. Si tenemos en cuenta la posible no disponibilidad debido a un error de usuario o de proceso y asumimos que la no disponibilidad es 4 veces la disponibilidad debido a factores técnicos, podríamos suponer que el presupuesto de disponibilidad es del 99,95%.
Este ejemplo de análisis indica, entonces, que la disponibilidad de LAN caería, en promedio, entre un 99.95 y 99.989 por ciento. Estos números se pueden usar ahora como un objetivo de nivel de servicio para la organización de la red. Puede obtener un valor adicional al medir la disponibilidad en el sistema y determinar el porcentaje de no disponibilidad debido a cada una de las anteriores seis áreas. Esto le permite a la organización evaluar de manera apropiada a los proveedores, empresas de comunicaciones, procesos y al personal. El número también se puede usar para establecer las expectativas dentro del negocio. Si el número es inaceptable, presupuestar recursos adicionales para obtener los niveles deseados.
Puede resultar útil para los administradores de redes comprender la cantidad de tiempo de inactividad en cualquier nivel de disponibilidad concreto. La cantidad de tiempo de inactividad en minutos durante un periodo de un año, en cualquier nivel de disponibilidad, es:
Minutos de tiempo de inactividad en un año = 525600 - (Nivel de disponibilidad X 5256)
Si utiliza el nivel de disponibilidad del 99,95%, esto resulta ser igual a 525600 - (99,95 X 5256) o 262,8 minutos de tiempo de inactividad. Para la definición de disponibilidad anterior, esto equivale a la cantidad media de tiempo de inactividad de todas las conexiones en servicio dentro de la red.
-
Paso 3: Crear perfiles de aplicación
Los perfiles de aplicación ayudan a la organización de redes a comprender y definir los requisitos de nivel de servicio de red para aplicaciones individuales. Esto lo ayuda a asegurarse de que la red soporte requisitos de aplicación individuales y servicios de red generales. Los perfiles de aplicación también pueden servir como una línea de base documentada para el soporte del servicio de red cuando los grupos de aplicaciones o servidores señalan la red como el problema. En última instancia, los perfiles de aplicación ayudan a alinear los objetivos del servicio de red con los requerimientos de aplicación o de negocios mediante la comparación de los requisitos de aplicación, como el rendimiento y la disponibilidad, con los objetivos realistas de servicio de red o las limitaciones actuales. Es importante no sólo para la administración de nivel de servicio, sino también para el diseño general descendente de la red.
Cree perfiles de aplicación cada vez que introduzca nuevas aplicaciones en la red. Es posible que sea necesario establecer un acuerdo entre el grupo de aplicación de IT, los grupos de administración de servidores y la conexión en red para ayudar a imponer la creación de perfiles de aplicación para los servicios nuevos y los que ya existen. Perfiles de aplicaciones completos para aplicaciones empresariales y aplicaciones del sistema. Las aplicaciones empresariales pueden incluir correo electrónico, transferencia de archivos, exploración web, imágenes médicas o fabricación. Las aplicaciones del sistema pueden incluir la distribución del software, la autenticación del usuario, el respaldo de la red y la administración de la red.
Un analista de red y una aplicación de soporte de servidor o aplicación deben crear el perfil de aplicación. Las nuevas aplicaciones pueden requerir el uso de un analizador de protocolos y un emulador WAN con emulación de demora para caracterizar correctamente los requisitos de las aplicaciones. Esto ayuda a identificar el ancho de banda necesario, el retraso máximo para la utilidad de la aplicación y los requerimientos de fluctuación. Esto puede realizarse en un entorno de laboratorio siempre que tenga los servidores requeridos. En otros casos, como en el caso de VoIP, los requisitos de red, incluidos la fluctuación, el retraso y el ancho de banda, se publican correctamente y no se necesitarán pruebas de laboratorio. Un perfil de aplicación debe incluir los siguientes elementos:
-
Nombre de la aplicación
-
Tipo de aplicación
-
¿Nueva aplicación?
-
Importancia empresarial
-
Requisitos de disponibilidad
-
Protocolos y puertos utilizados
-
Ancho de banda de usuario estimado (kbps)
-
Número y ubicación de los usuarios
-
Requisitos de transferencia de archivos (incluidos el tiempo, el volumen y los terminales)
-
Impacto de las interrupciones en la red
-
Requisitos de disponibilidad, fluctuación y retraso
El objetivo del perfil de aplicación es comprender los requisitos comerciales para la aplicación, el carácter crítico del negocio y los requisitos de la red como el ancho de banda, el retardo y la fluctuación. Además, la organización de redes debe comprender el impacto del tiempo de inactividad de la red. En algunos casos, necesitará reiniciar el servidor o la aplicación que aumente significativamente el tiempo de inactividad general de la aplicación. Cuando completa el perfil de la aplicación, puede comparar las capacidades generales de la red y contribuir a alinear los niveles de servicio de la red con los requisitos comerciales y de la aplicación.
Paso 4: Definir estándares de disponibilidad y rendimiento
Los estándares de disponibilidad y rendimiento establecen las expectativas de servicio para la organización. Éstos pueden ser definidos para distintas áreas de la red o para aplicaciones específicas. El rendimiento también se puede definir en términos de demora de ida y vuelta, fluctuación, rendimiento máximo, compromisos de ancho de banda y escalabilidad general. Además de establecer las expectativas de los servicios, la organización también debe tener cuidado de definir cada uno de los estándares de servicio para que los usuarios y los grupos de TI que trabajan con redes comprendan completamente el estándar de servicio y cómo se relaciona con sus requisitos de administración de aplicaciones o servidores. Los grupos de usuarios y de IT también deben comprender cómo se debe medir el estándar de servicio.
Los resultados de los pasos de definición de nivel del servicio previo ayudarán a crear el estándar. En este punto, la organización de redes debe tener una clara comprensión de los riesgos y limitaciones actuales de la red, una comprensión del comportamiento de las aplicaciones y un análisis teórico de la disponibilidad o una línea de base de disponibilidad.
-
Defina las áreas geográficas o de aplicaciones en las que se aplicarán los estándares de servicio.
Podría incluir áreas como la LAN de oficinas centrales, la WAN local, extranet o la conectividad asociada. En algunos casos, la organización puede tener diferentes objetivos de nivel de servicio dentro de un área. Este no es común para las empresas o las organizaciones proveedoras de servicios. En estos casos, no sería raro crear diferentes estándares de nivel de servicio basados en los requisitos de servicio individuales. Se pueden clasificar como estándares de servicio de oro, plata y bronce dentro de un área geográfica o de servicio.
-
Defina los parámetros estándar de servicio.
La disponibilidad y el retraso de ida y vuelta son los estándares de servicio de red más comunes. También se puede incluir el rendimiento máximo, el compromiso de ancho de banda mínimo, la fluctuación, las tasas de error aceptables y las capacidades de escalabilidad según sea necesario. Tenga cuidado al revisar el parámetro de servicio para los métodos de medición. Si el parámetro avanza hacia la SLA o no, la organización debe pensar en cómo se debería medir o justificar el parámetro de servicio cuando ocurren problemas o desacuerdos de servicio.
Después de definir las áreas de servicio y los parámetros de servicio, utilice la información de los pasos anteriores para crear una matriz de estándares de servicio. La organización también tendrá que definir áreas que puedan resultar confusas para los usuarios y los grupos de TI. Por ejemplo, el tiempo máximo de respuesta será muy diferente para un ping de ida y vuelta que para la tecla Intro en una ubicación remota para una aplicación específica. En la tabla siguiente se muestran los objetivos de rendimiento dentro de los Estados Unidos.
| Área de red | Objetivo de disponibilidad | Método de medición | Tiempo promedio de respuesta de la red | Tiempo máximo de respuesta aceptado | Método de medición del tiempo de respuesta |
|---|---|---|---|---|---|
| LAN | 99.99% | Minutos de usuario afectados | Menos de 5 ms | 10 ms | Respuesta de ping de ida y vuelta |
| WAN | 99.99% | Minutos de usuario afectados | Menos de 100 ms (ping de ida y vuelta) | 150 ms | Respuesta de ping de ida y vuelta |
| WAN crítica y extranet | 99.99% | Minutos de usuario afectados | Menos de 100 ms (ping de ida y vuelta) | 150 ms | Respuesta de ping de ida y vuelta |
Paso 5: Definir servicio de red
Este es el último paso hacia la administración de nivel de servicio básico; define los procesos reactivos y proactivos y las capacidades de administración de red que se implementan para alcanzar los objetivos de nivel de servicio. El documento final se denomina normalmente plan de soporte de operaciones. La mayoría de los planes de soporte de aplicaciones solo incluyen requisitos de soporte reactivos. En entornos de alta disponibilidad, la organización también debe considerar procesos de administración proactivos que se utilizarán para aislar y resolver problemas de red antes de iniciar las llamadas de servicio de usuario. En general, el documento final debe:
-
Describa el proceso reactivo y proactivo utilizado para alcanzar el objetivo de nivel de servicio
-
Cómo se gestionará el proceso de servicio
-
Cómo se medirán el objetivo del servicio y el proceso del servicio.
Esta sección contiene ejemplos de definiciones de servicio reactivas y definiciones de servicio proactivas que se deben tener en cuenta para muchas organizaciones empresariales y proveedores de servicios. El objetivo de elaborar las definiciones del nivel de servicio es ofrecer un servicio que cumpla con los objetivos de rendimiento y disponibilidad. Para lograrlo, la organización debe desarrollar el servicio con las restricciones técnicas actuales, el presupuesto de disponibilidad y los perfiles de aplicación en mente. En concreto, la organización debe definir y crear un servicio que identifique y resuelva los problemas de forma rápida y coherente en el plazo asignado por el modelo de disponibilidad. La organización también debe definir un servicio que pueda identificar y solucionar con rapidez los problemas de servicio potenciales que afectarán la disponibilidad y el rendimiento si se los ignora.
No alcanzará el nivel de servicio deseado de la noche a la mañana. Los defectos tales como baja experiencia, limitaciones del proceso actual o niveles de personal inadecuados pueden evitar que la organización alcance los estándares u objetivos deseados, aun luego de los pasos previos del análisis del servicio. No existe un método preciso para coincidir exactamente el nivel de servicio requerido con los objetivos deseados. Para ello, la organización debe medir los estándares de servicio y medir los parámetros de servicio utilizados para respaldar los estándares de servicio. Cuando la organización no cumple los objetivos de servicio, debe recurrir a las métricas de servicio para comprender el problema. En muchos casos, se pueden hacer aumentos presupuestarios para mejorar los servicios de apoyo y hacer las mejoras necesarias para alcanzar los objetivos de servicios deseados. Con el transcurso del tiempo la organización puede realizar varios ajustes, tanto a los objetivos de los servicios como a la definición de los servicios, a fin de alinear los servicios de red y los requisitos comerciales.
Por ejemplo, una organización podría lograr una disponibilidad del 99% cuando el objetivo era mucho mayor con una disponibilidad del 99,9%. Al observar el servicio y las mediciones de soporte, los representantes de la organización encontraron que el reemplazo de hardware llevó aproximadamente 24 horas, mucho más que el tiempo estimado originalmente ya que la organización había presupuestado únicamente cuatro. Además, la organización descubrió que se ignoraban las capacidades de gestión proactiva y que no se reparaban los dispositivos de red redundantes. También descubrieron que no tenían el personal para hacer mejoras. Como resultado, tras considerar la reducción de los objetivos de servicios actuales, la organización presupuestó recursos adicionales necesarios para alcanzar el nivel de servicio deseado.
Las definiciones de servicio deben incluir definiciones de soporte reactivo y definiciones proactivas. Las definiciones reactivas definen cómo reaccionará la organización a los problemas después de que se hayan identificado desde las capacidades de gestión de redes o quejas de los usuarios. Las definiciones proactivas describen cómo la organización identificará y resolverá los posibles problemas de red, incluida la reparación de componentes de red "en espera" rotos, la detección de errores y los umbrales y actualizaciones de capacidad. Las siguientes secciones proporcionan información sobre las definiciones de nivel de servicio reactivo y proactivo.
Definiciones de nivel de servicio reactivo
Las siguientes áreas de nivel de servicio se miden generalmente utilizando estadísticas de una base datos del mostrador de informaciones y de auditorías periódicas. Esta tabla muestra un ejemplo de gravedad de problema para una organización. Observe que el gráfico no incluye cómo manejar las solicitudes de nuevos servicios, que pueden ser manejadas por un SLA o un análisis adicional de perfiles y rendimiento de aplicaciones. Típicamente, la gravedad 5 podría ser una solicitud de un nuevo servicio en caso de darle tratamiento por medio del mismo proceso de soporte.
| Gravedad 1 | Gravedad 2 | Gravedad 3 | Gravedad 4 |
|---|---|---|---|
| Impacto empresarial grave del usuario de LAN o del servidor en el sitio de WAN crítico hacia abajo | Alto impacto empresarial por pérdida o degradación, posible solución alternativa en el Campus LAN down; Entre 5 y 99 usuarios se vieron afectados por la caída del sitio WAN nacional en el sitio WAN internacional. Impacto crítico en el rendimiento | Algunas funciones de red específicas se pierden o se degradan, como la pérdida de redundancia en el rendimiento de LAN del campus afectada por la redundancia LAN perdida | Consulta funcional o fallo que no afecta a la empresa |
Cuando se ha definido la gravedad del problema, defina o investigue el proceso de apoyo para crear definiciones de respuesta del servicio. En general, las definiciones de respuesta de servicio requieren una estructura de soporte por niveles, junto con un sistema de soporte de software de soporte técnico para realizar un seguimiento de los problemas a través de las notificaciones de incidencias. Las métricas también deben estar disponibles en tiempo de respuesta y tiempo de resolución para cada prioridad, número de llamadas por prioridad y calidad de respuesta/resolución. Para definir el proceso de soporte, es útil definir los objetivos de cada nivel de soporte en la organización y sus roles y responsabilidades. Esto ayuda a los requerimientos de recursos de comprensión de la organización y a los niveles de conocimiento para cada nivel de soporte. La siguiente tabla brinda un ejemplo de una organización de soporte por niveles con pautas para la solución de problemas.
| Nivel de soporte | Responsabilidad | Objetivos |
|---|---|---|
| Soporte del nivel 1 | Soporte de soporte técnico a tiempo completo Responder llamadas de soporte, realizar notificaciones de problemas, trabajar en problemas hasta 15 minutos, documentar notificaciones y escalar a soporte adecuado de nivel 2 | Resolución del 40% de las llamadas entrantes |
| Soporte del nivel 2 | Supervisión de cola, gestión de red, supervisión de estación Realizar notificaciones de problemas para los problemas identificados por el software Implementar Realizar llamadas desde el nivel 1, el proveedor y la escalada del nivel 3 Asumir la propiedad de la llamada hasta la resolución | Resolución del 100% de las llamadas en el nivel 2 |
| Soporte del nivel 3 | Debe proporcionar soporte inmediato al nivel 2 para todos los problemas de prioridad 1 Acordar ayudar con todos los problemas sin resolver por el nivel 2 dentro del período de resolución de SLA | Sin problema directo |
El siguiente paso es crear la matriz para la respuesta del servicio y la definición del servicio de resolución de servicio. Esto establece metas para la rapidez con que los problemas se resuelven, inclusive el reemplazo del hardware. Es importante establecer objetivos en esta área porque el tiempo de respuesta del servicio y el tiempo de recuperación afectan directamente a la disponibilidad de la red. Los tiempos de resolución de problemas también deben adaptarse al presupuesto de disponibilidad. Si en el presupuesto de disponibilidad no se tiene en cuenta un gran número de problemas de gravedad alta, la organización puede trabajar para comprender la fuente de estos problemas y un posible remedio. Vea la tabla siguiente:
| Gravedad del problema | Respuesta del soporte técnico | Respuesta de Nivel 2 | Nivel 2 en el sitio | Reemplazo de hardware | Solución del problema |
|---|---|---|---|---|---|
| 1 | Escalado inmediato al nivel 2, administrador de operaciones de red | 5 minutos | 2 horas | 2 horas | 4 horas |
| 2 | Escalado inmediato al nivel 2, administrador de operaciones de red | 5 minutos | 4 horas | 4 horas | 8 horas |
| 3 | 15 minutos | 2 horas | 12 horas | 24 horas | 36 horas |
| 4 | 15 minutos | 4 horas | 3 días | 3 días | 6 días |
Además de la respuesta del servicio y la resolución del servicio, cree una matriz para la escalada. La matriz de derivación ayuda a garantizar que los recursos disponibles se centran en los problemas que afectan gravemente al servicio. En general, cuando los analistas se centran en solucionar los problemas, rara vez se centran en aportar recursos adicionales al problema. La definición de cuándo deben notificarse los recursos adicionales ayuda a promover la concienciación sobre los problemas en la gestión y, en general, puede contribuir a la adopción de futuras medidas proactivas o preventivas. Vea la tabla siguiente:
| Tiempo transcurrido | Gravedad 1 | Gravedad 2 | Gravedad 3 | Gravedad 4 |
|---|---|---|---|---|
| 5 minutos | Director de operaciones de red, soporte de nivel 3, director de redes | |||
| 1 hora | Actualizar al administrador de operaciones de red, soporte de nivel 3, director de interconexiones de red | Actualizar al administrador de operaciones de red, soporte de nivel 3, director de interconexiones de red | ||
| 2 horas | Derivación a vicepresidente, actualización al director, administrador de operaciones | |||
| 4 horas | El análisis de la causa raíz no resuelto que se efectuó a VP, director, administrador de operaciones y soporte de nivel 3 requiere notificación de CEO | Derivación a vicepresidente, actualización al director, administrador de operaciones | ||
| 24 horas | Administrador de operaciones de red | |||
| 5 días | Administrador de operaciones de red |
Hasta ahora, las definiciones de nivel de servicio se centraron en cómo la organización de soporte de las operaciones reacciona ante los problemas una vez que se identifican. Durante años, las organizaciones de operaciones han creado planes de soporte operacional con información similar a la mencionada anteriormente. Sin embargo, lo que falta en estos casos es cómo la organización identificará los problemas y qué problemas identificará. Las organizaciones de redes más sofisticadas han intentado resolver este problema simplemente creando objetivos para el porcentaje de problemas que se identifican de forma proactiva, en lugar de problemas identificados de forma reactiva por el informe de problemas de los usuarios o la queja.
La siguiente tabla muestra cómo una organización puede desear evaluar las capacidades de soporte proactivo y el soporte proactivo en general.
| Área de red | Relación de identificación del problema proactivo | Relación de identificación de problemas reactiva |
|---|---|---|
| LAN | 80 % | 20 % |
| WAN | 80 % | 20 % |
Este es un buen comienzo para definir definiciones de soporte más proactivas, ya que es sencillo y bastante fácil de medir, especialmente si las herramientas proactivas generan automáticamente notificaciones de problemas. Esto también ayuda a centrar las herramientas/la información de administración de la red en resolver los problemas de forma proactiva en lugar de ayudar con la causa principal. Sin embargo, el problema principal de este método es que no define los requisitos de soporte proactivo. Por lo general, esto crea brechas en las capacidades de administración de soporte proactivo y tiene como resultado riesgos de disponibilidad adicionales.
Definiciones de nivel de servicio proactivas
Una metodología más completa para crear definiciones de nivel de servicio incluye más detalles sobre cómo se monitorea la red y cómo reacciona la organización de operaciones a los umbrales definidos de estación de administración de red (NMS) 7 x 24. Esto puede parecer una tarea imposible debido al elevado número de variables de Base de información para administración (MIB) y la cantidad de información de administración de la red disponible pertinente para la integridad de la misma. También podría ser extremadamente costoso y requerir muchos recursos. Desafortunadamente, estas objeciones evitan, en muchos casos, que se implemente una definición de servicio proactivo que, por naturaleza, debe ser simple, bastante fácil de seguir y aplicable sólo a los mayores riesgos de disponibilidad o rendimiento de la red. Si una organización ve valor en las definiciones de servicios proactivos básicos, se pueden agregar más variables con el tiempo sin que ello repercuta significativamente, siempre y cuando se implemente un enfoque por fases.
Incluya el primer área de definiciones de servicio proactivas en todos los planes de soporte de operaciones. La definición de servicio simplemente indica cómo el grupo de operaciones identificará y responderá de forma proactiva a las condiciones de red o de link inactivo en diferentes áreas de la red. Sin esta definición (o soporte de administración), la organización puede esperar soporte variable, expectativas de usuarios irreales y, en última instancia, una disponibilidad de red menor.
La siguiente tabla muestra cómo una organización puede crear una definición de servicio para condiciones de link/dispositivo fuera de funcionamiento. El ejemplo muestra una organización empresarial que quizás tenga diferentes requerimientos de notificaciones y de respuestas según el momento del día y el área de la red.
| Dispositivo de red o enlace inactivo | Método de detección | 5 x 8 notificación | 7 x 24 notificación | Resolución 5 x 8 | Resolución 7 x 24 |
|---|---|---|---|---|---|
| LAN principal | Dispositivo SNMP y consulta de links, trampas | NOC crea un ticket de problemas, localizador de servicio LAN de página | Localizador de tareas LAN de página automática, persona de servicio LAN crea un ticket de problema para cola LAN principal | Analista de LAN asignado en 15 minutos por NOC, reparación según la definición de respuesta de servicio | Prioridades 1 y 2 Investigación inmediata y resolución Prioridades 3 y 4 esperan resolución por la mañana |
| WAN doméstica | Dispositivo SNMP y consulta de links, trampas | NOC crea un ticket de problemas, localizador de tareas WAN de página | Localizador de tareas WAN de página automática, el encargado de WAN crea un ticket de problema para cola WAN | Analista de WAN asignado en 15 minutos por NOC, reparación como definición de respuesta por servicio. | Prioridades 1 y 2 Investigación inmediata y resolución Prioridades 3 y 4 esperan resolución por la mañana |
| Extranet | Dispositivo SNMP y consulta de links, trampas | NOC crea un ticket de problemas, localizador de tareas para partners de página | Localizador de tareas de partner de página automática, el responsable de servicio del partner crea un ticket de problemas para la cola del partner | Analista asociado asignado dentro de los 15 minutos por NOC, reparación según definición de repuesta del servicio | Investigación y resolución inmediatas de las prioridades 1 y 2; Las prioridades 3 y 4 quedan pendientes para resolverse luego |
Las definiciones de nivel de servicio proactivo restantes se pueden dividir en dos categorías: errores de red y problemas de capacidad/rendimiento. Sólo un pequeño porcentaje de las organizaciones de red poseen definiciones de nivel de servicio en éstas áreas. Como resultado, estos problemas se ignoran o se manejan esporádicamente. Esto puede ser adecuado para algunos entornos de red, pero los entornos con alta disponibilidad necesitan generalmente una administración de servicio uniforme y proactiva.
Las organizaciones de redes suelen tener problemas con las definiciones de servicios proactivos por varios motivos. Esto se debe principalmente a que no realizaron un análisis de requisitos con respecto a definiciones de servicio proactivo en base a riesgos de disponibilidad, presupuesto de disponibilidad y problemas de aplicación. Esto da lugar a requisitos poco claros para las definiciones de servicios proactivos y a beneficios poco claros, especialmente porque pueden necesitarse recursos adicionales.
El segundo motivo implica el equilibrio de la cantidad de administración preactiva que puede realizarse con los recursos existentes o los recientemente definidos. Sólo genere aquellas alertas que tienen un potencial impacto severo en la disponibilidad o en el rendimiento. También debe tener en cuenta la administración de correlación de eventos o los procesos para asegurarse de que no se generen varios tickets de problemas proactivos para el mismo problema. La última razón por la cual las organizaciones pueden ofrecer resistencia es que la creación de un nuevo conjunto de alertas proactivas puede, con cierta frecuencia, llegar a generar una inundación inicial de mensajes que pasaron previamente desapercibidos. El grupo de operaciones debe estar preparado para esta inundación inicial de problemas y recursos adicionales a corto plazo para reparar o resolver estas condiciones que anteriormente no se detectaban.
La primera categoría de definiciones de nivel de servicio proactivo es errores de red. Los errores de red pueden subdividirse en errores del sistema que incluyen errores de software o de hardware, errores de protocolo, errores de control de medios, errores de precisión y advertencias ambientales. El desarrollo de una definición de nivel de servicio comienza con una comprensión general de cómo se detectarán estas condiciones de problema, quién las examinará y qué ocurrirá cuando se produzcan. Agregue mensajes específicos o problemas a la definición de nivel de servicio si surge la necesidad. Es posible que también sea necesario trabajar en las siguientes áreas para garantizar el éxito:
-
Responsabilidades de soporte de nivel 1, nivel 2 y nivel 3
-
Equilibrar la prioridad de la información de administración de la red con la cantidad de trabajo proactivo que el grupo de operaciones puede manejar de manera eficaz
-
Requisitos de capacitación para asegurar que el equipo de soporte pueda encargarse de forma efectiva de las alertas definidas.
-
Metodologías de correlación de eventos para garantizar que no se generen varios tickets de problemas para el mismo problema de causa raíz
-
Documentación sobre mensajes específicos o alertas que ayudan con la identificación de eventos en el nivel de soporte de nivel 1
La tabla siguiente muestra un ejemplo de una definición de nivel de servicio para errores de red que sirve para comprender claramente quién es responsable de las alertas de error de la red proactiva, cómo se identificará el problema y qué sucederá cuando aparezca el problema. Es posible que la organización siga necesitando esfuerzos adicionales, como se ha definido anteriormente, para garantizar el éxito
s
| Categoría de error | Método de detección | Umbral | Acción realizada |
|---|---|---|---|
| Errores de software (caídas forzadas por el software) | Revisión diaria de los mensajes de syslog mediante el visor de syslog Hecho por el soporte de nivel 2 | Cualquier aparición de prioridad 0, 1 y 2 Más de 100 ocurrencias de nivel 3 o superior | Revise el problema, cree un ticket con el inconveniente y envíelo si vuelve a ocurrir o si el problema requiere atención |
| Errores de hardware (fallos forzados por el hardware) | Revisión diaria de los mensajes de syslog mediante el visor de syslog Hecho por el soporte de nivel 2 | Cualquier aparición de prioridad 0, 1 y 2 Más de 100 ocurrencias de nivel 3 o superior | Revise el problema, cree un ticket con el inconveniente y envíelo si vuelve a ocurrir o si el problema requiere atención |
| Errores de protocolo (sólo protocolos de routing IP) | Revisión diaria de los mensajes de syslog mediante el visor de syslog Hecho por el soporte de nivel 2 | Diez mensajes por día de las prioridades 0, 1 y 2 Más de 100 apariciones de nivel 3 o superior | Revise el problema, cree un ticket con el inconveniente y envíelo si vuelve a ocurrir o si el problema requiere atención |
| Errores de control de medios (sólo FDDI, POS y Fast Ethernet) | Revisión diaria de los mensajes de syslog mediante el visor de syslog Hecho por el soporte de nivel 2 | Diez mensajes por día de las prioridades 0, 1 y 2 Más de 100 apariciones de nivel 3 o superior | Revise el problema, cree un ticket con el inconveniente y envíelo si vuelve a ocurrir o si el problema requiere atención |
| Mensajes ambientales (potencia y temperatura) | Revisión diaria de los mensajes de syslog mediante el visor de syslog Hecho por el soporte de nivel 2 | Cualquier mensaje | Cree un ticket de problemas y envíelo para nuevos problemas |
| Errores de precisión (errores de entrada de link) | Sondeo SNMP a intervalos de 5 minutos Eventos de umbral recibidos por NOC | Errores de entrada o salida Un error en cualquier intervalo de 5 minutos en cualquier link | Cree un ticket de problemas nuevos y envíelo al soporte de nivel 2 |
La otra categoría de definiciones de nivel de servicio proactivo se aplica al rendimiento y la capacidad. La verdadera administración de capacidad y rendimiento incluye la administración de excepciones, el establecimiento de líneas de base y tendencia y el análisis de ¿qué pasa si…? La definición de nivel de servicio simplemente define los umbrales de excepción de rendimiento y capacidad y los umbrales medios que iniciarán la investigación o la actualización. Estos umbrales pueden utilizarse con los tres procesos de gestión de rendimiento y capacidad de alguna manera.
Las definiciones de nivel de servicio de capacidad y rendimiento se pueden dividir en varias categorías: enlaces de red, dispositivos de red, rendimiento de extremo a extremo y rendimiento de las aplicaciones. El desarrollo de definiciones de nivel de servicio en estas áreas requiere un profundo conocimiento técnico sobre aspectos específicos de la capacidad de los dispositivos, la capacidad de medios, las características de QoS y los requisitos de las aplicaciones. Por este motivo, recomendamos que los arquitectos de red desarrollen definiciones de nivel de servicio relacionadas con el rendimiento y la capacidad con la información del proveedor.
Al igual que los errores de red, el desarrollo de una definición de nivel de servicio para la capacidad y el rendimiento comienza con una comprensión general de cómo se detectarán estas condiciones de problema, quién las examinará y qué ocurrirá cuando se produzcan. Puede agregar definiciones de eventos específicas a la definición del nivel de servicio en caso de necesitarlo. Es posible que también sea necesario trabajar en las siguientes áreas para garantizar el éxito:
-
Una comprensión clara de los requisitos de rendimiento de las aplicaciones
-
Investigación técnica exhaustiva sobre los valores de umbral que tienen sentido para la organización en función de los requisitos empresariales y los costes generales
-
Requisitos de actualización del ciclo presupuestario y fuera del ciclo
-
Responsabilidades de soporte de nivel 1, nivel 2 y nivel 3
-
La prioridad y criticidad de la información de administración de la red equilibrada con la cantidad de trabajo proactivo que el grupo de operaciones puede manejar de manera efectiva
-
Requisitos de formación para garantizar que el personal de soporte entienda los mensajes o alertas y pueda hacer frente de forma eficaz a la condición definida
-
Metodologías o procesos de correlación de eventos para garantizar que no se generen varios tickets de problemas para el mismo problema de causa raíz
-
Documentación sobre mensajes específicos o alertas que ayudan con la identificación de eventos en el nivel de soporte de nivel 1
La siguiente tabla muestra una definición de nivel de servicio de ejemplo para la utilización de links que proporciona una comprensión clara de quién es responsable de las alertas de errores de red proactivas, cómo se identificará el problema y qué ocurrirá cuando ocurra el problema. La organización puede necesitar todavía esfuerzos adicionales para asegurar el éxito, como se definió antes.
| Área de red/medios | Método de detección | Umbral | Acción realizada |
|---|---|---|---|
| Red troncal de LAN de campus y enlaces de distribución | Sondeo SNMP a intervalos de 5 minutos con trampas de excepción RMON en links de núcleo y distribución | Utilización del 50% en intervalos de 5 minutos Utilización del 90% mediante trampa de excepciones | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento para evaluar los requisitos de QoS o planificar la actualización para problemas recurrentes |
| Enlaces WAN nacionales | Consultas SNMP en intervalos de 5 minutos | 75 % de utilización en intervalos de 5 minutos | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento para evaluar los requisitos de QoS o planificar la actualización para problemas recurrentes |
| Enlaces WAN de Extranet | Consultas SNMP en intervalos de 5 minutos | 60% de utilización en intervalos de 5 minutos | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento para evaluar los requisitos de QoS o planificar la actualización para problemas recurrentes |
La tabla siguiente define las definiciones de nivel de servicio para los umbrales de capacidad y rendimiento del dispositivo. Asegúrese de crear umbrales que sean significativos y útiles para evitar problemas de red o problemas de disponibilidad. Esta es un área muy importante porque los problemas de recursos de plano de control de dispositivos no verificados pueden tener un grave impacto en la red.
| 7500 de Cisco | CPU, memoria, memorias intermedias | Sondeo SNMP a intervalos de -5 minutos Notificación RMON para CPU | CPU al 75% durante intervalos de 5 minutos, 99% a través de la notificación RMON Memoria al 50% durante intervalos de 5 minutos Búfers al 99% de utilización | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento y capacidad para resolver problemas o planificar la actualización de la CPU RMON al 99%, colocar el ticket de problemas y el localizador de soporte de nivel 2 de la página |
| Cisco 2600 | CPU, memoria | Consultas SNMP en intervalos de 5 minutos | CPU al 75% durante intervalos de 5 minutos Memoria al 50% durante intervalos de 5 minutos | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento y capacidad para resolver problemas o planificar la actualización |
| Catalyst 5000 | Utilización de la placa de interconexiones, memoria | Consultas SNMP en intervalos de 5 minutos | Placa base con una utilización del 50% Memoria con una utilización del 75% | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento y capacidad para resolver problemas o planificar la actualización |
| Switch ATM LightStream® 1010 | CPU, memoria | Consultas SNMP en intervalos de 5 minutos | CPU con uso del 65% Memoria con uso del 50% | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento y capacidad para resolver problemas o planificar la actualización |
La tabla siguiente especifica definiciones de nivel de servicio para la capacidad y el rendimiento de extremo a extremo. Estos umbrales generalmente se basan en los requisitos de aplicación, pero también pueden utilizarse para indicar algún tipo de problema de rendimiento o capacidad de red. La mayoría de las organizaciones con definiciones de nivel de servicio para el rendimiento solo crean un puñado de definiciones de rendimiento, ya que para medir el rendimiento desde cada punto de la red hasta cualquier otro punto se necesitan recursos significativos y se crea una gran cantidad de sobrecarga de red. Estos problemas de rendimiento de extremo a extremo también se pueden atrapar en umbrales de capacidad del dispositivo o link. Nosotros recomendamos definiciones generales por área geográfica. Si es necesario, se pueden agregar algunos sitios o enlaces críticos.
| Área de red/medios | Método de medición | Umbral | Acción realizada |
|---|---|---|---|
| LAN de campus | Ninguno No se esperaba ningún problema Difícil de medir toda la infraestructura LAN | tiempo de respuesta de viaje de ida y vuelta de 10 milisegundos o menos en todo momento | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento y capacidad para resolver problemas o planificar la actualización |
| Enlaces WAN nacionales | Medición actual de SF a NY y SF a Chicago únicamente mediante eco ICMP de Internet Performance Monitor (IPM) | Tiempo medio de respuesta de ida y vuelta de 75 milisegundos durante un período de 5 minutos | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento para evaluar los requisitos de QoS o planificar la actualización para problemas recurrentes |
| de San Francisco a Tokyo | Medición actual de San Francisco a Bruselas usando eco ICMP y IPM | Tiempo de respuesta de ida y vuelta de 250 milisegundos promedio durante un período de 5 minutos | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento para evaluar los requisitos de QoS o planificar la actualización para problemas recurrentes |
| San Francisco a Bruselas | Medición actual de San Francisco a Bruselas usando eco ICMP y IPM | Tiempo de respuesta de ida y vuelta de 175 milisegundos promedio durante un período de 5 minutos | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento para evaluar los requisitos de QoS o planificar la actualización para problemas recurrentes |
El área final para las definiciones de nivel de servicio es para el rendimiento de las aplicaciones. Las definiciones de nivel de servicio de rendimiento de las aplicaciones son creadas normalmente por el grupo de administración de aplicaciones o servidores, ya que el rendimiento y la capacidad de los propios servidores es probablemente el factor más importante en el rendimiento de las aplicaciones. Las organizaciones de redes pueden obtener enormes beneficios creando definiciones de nivel de servicio para el rendimiento de las aplicaciones de red porque:
-
la medición y las definiciones del nivel de servicio pueden ayudar a eliminar conflictos entre grupos.
-
las definiciones de los niveles de servicio para las aplicaciones individuales son importantes si la calidad de servicio (QoS) está configurada para las aplicaciones principales y el resto del tráfico se considera opcional.
Si decide crear y medir el rendimiento de las aplicaciones, es probable que no mida el rendimiento en el propio servidor. Esto, entonces, nos ayuda a distinguir entre problemas de red y aplicaciones y problemas de servidores. Use sondas o el software agente de disponibilidad del sistema que se ejecuta en los routers de Cisco y el IPM de Cisco que controla el tipo de paquete y la frecuencia de medición.
La tabla siguiente muestra una definición de nivel de servicios simple para el rendimiento de la aplicación.
| Aplicación | Método de medición | Umbral | Acción realizada |
|---|---|---|---|
| Aplicación de planificación de recursos empresariales (ERP) Puerto TCP 1529 Bruselas a SF | Bruselas a San Francisco mediante el rendimiento de ida y vuelta del puerto 1529 de medición IPM gateway Bruselas a la gateway 2 de SFO | Tiempo de respuesta de ida y vuelta de 175 milisegundos promedio durante un período de 5 minutos | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento para evaluar problemas o planificar la actualización para problemas recurrentes |
| Aplicación ERP Puerto TCP 1529 Tokio a SF | Bruselas a San Francisco mediante el rendimiento de ida y vuelta del puerto 1529 de medición IPM gateway Bruselas a la gateway 2 de SFO | Tiempo de respuesta de ida y vuelta de 200 milisegundos promedio durante un período de 5 minutos | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento para evaluar problemas o planificar la actualización para problemas recurrentes |
| Aplicación de soporte al cliente Puerto TCP 1702 Sidney a SF | Sidney a San Francisco mediante el rendimiento de ida y vuelta del puerto 1702 de medición IPM gateway de Sidney a la gateway 1 de SFO | Tiempo de respuesta de ida y vuelta de 250 milisegundos promedio durante un período de 5 minutos | Notificación por correo electrónico al grupo de alias de correo electrónico de rendimiento para evaluar problemas o planificar la actualización para problemas recurrentes |
Paso 6: Recopilación de indicadores y supervisión
por sí solas, las definiciones de nivel de servicio no son útiles a menos que la organización recopile las medidas y monitoree el éxito. Al crear una definición de nivel de servicio crítico, defina cómo se medirá e informará el nivel de servicio. La medición del nivel de servicio determina si la organización cumple los objetivos y también identifica la causa principal de los problemas de disponibilidad o rendimiento. Tenga en cuenta también el objetivo al elegir un método para medir la definición del nivel de servicio. Consulte Creación y Mantenimiento de SLAs para obtener más información.
La supervisión de los niveles de servicio entraña la celebración de una reunión periódica de examen, normalmente cada mes, para examinar los servicios periódicos. Debata todas las métricas y si se ajustan a los objetivos. Si no se ajustan, determine la causa raíz del problema e implemente mejoras. Debería también cubrir el progreso y las iniciativas actuales para mejorar situaciones individuales.
Creación y Mantenimiento de SLA
Las definiciones de nivel de servicio son un excelente componente esencial ya que ayudan a crear una calidad de servicio uniforme en toda la organización y facilitan la optimización de la disponibilidad. El siguiente paso son los SLA, que suponen una mejora porque alinean los objetivos empresariales y los requisitos de costes directamente con la calidad del servicio. A continuación, el SLA bien construido sirve como modelo de eficiencia, calidad y sinergia entre la comunidad de usuarios y el grupo de soporte al mantener procesos y procedimientos claros para los problemas o problemas de la red.
Los SLA proporcionan varias ventajas:
-
Los SLA establecen responsabilidad de dos partes para los servicios, lo que significa que los usuarios y los grupos de aplicación también son contables para el servicio de la red. Si no ayudan a crear un SLA para un servicio específico y comunican el impacto empresarial con el grupo de red, es posible que realmente sean responsables del problema.
-
Los SLA determinan las herramientas estándar y los recursos necesarios para satisfacer los requisitos comerciales. Decidir cuántas personas y qué herramientas se deben utilizar sin SLA suele ser una estimación presupuestaria. El servicio puede estar sobrediseñado, lo cual deriva en gastos excesivos; o bien, subdiseñado que resulta en objetivos comerciales no alcanzados. El ajuste de los SLA ayuda a alcanzar el nivel óptimo equilibrado.
-
El SLA documentado crea un método más claro para configurar las expectativas del nivel de servicio.
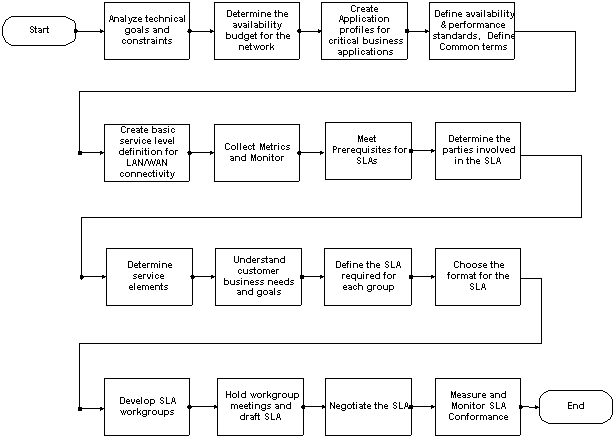
Recomendamos los siguientes pasos para formar SLA una vez que se han creado definiciones de nivel de servicio: Recomendamos los siguientes pasos para formar SLA una vez que se han creado definiciones de nivel de servicio:
7. Cumplir los requisitos previos para los SLA.
8. Determine las partes involucradas en el SLA.
9. Determine los elementos de servicio.
10. Información sobre las Necesidades y los Objetivos Corporativos del Cliente
11. Defina el SLA necesario para cada grupo.
13. Desarrollar grupos de trabajo de SLA
14. Celebrar reuniones de grupos de trabajo y redactar el SLA.
15. Negocie el SLA.
16. Mida y supervise la conformidad con SLA.
Paso 7: Cumplir los requisitos previos para los SLA
Los expertos en desarrollo de SLA de TI identificaron tres requisitos previos para un SLA exitoso. Desafortunadamente, las organizaciones que no alcanzan estos objetivos pueden esperar problemas con el proceso SLA y deberán considerar los problemas potenciales involucrados en el proceso SLA. No implementar los SLA no es perjudicial si la organización de red puede crear definiciones de nivel de servicio que cumplan los requisitos generales del negocio. Los siguientes son requisitos previos para el proceso SLA:
-
Su negocio debe contar con una cultura orientada al servicio.
La organización debe poner las necesidades de los clientes en primer lugar. Necesita un compromiso de prioridad verticalista con el servicio, con lo que se obtiene una comprensión completa de las necesidades y percepciones del cliente. Realizar encuestas de satisfacción del cliente e iniciativas de servicio dirigidas por el cliente.
Otro indicador de servicio puede ser que la organización declara la satisfacción del servicio o del soporte como un objetivo corporativo. Esto no es poco común debido a que ahora, las organizaciones de IT están críticamente relacionadas al éxito general de las organizaciones.
La cultura de servicio es importante porque el proceso SLA se trata principalmente de realizar mejoras según las necesidades y los requerimientos del negocio del cliente. Si las organizaciones no lo han hecho en el pasado, les resultará difícil el proceso SLA.
-
Las iniciativas empresariales y de clientes deben impulsar todas las actividades de TI.
La visión de la compañía o los enunciados de la misión deben estar alineados con las iniciativas del cliente y del negocio que luego conducen a todas las actividad de IT, incluyendo los SLA. Con mucha frecuencia, una red es colocada en un lugar para alcanzar un objetivo en particular aunque el grupo de conexión en red pierde de vista ese objetivo y los posteriores requisitos comerciales. En estos casos, se asigna un presupuesto fijo a la red, que puede reaccionar de forma exagerada a las necesidades actuales o subestimar groseramente el requisito, lo que da lugar a fallos.
Cuando las iniciativas comerciales/de clientes se alinean con las actividades de informática, la organización de la red puede estar en sintonía con los desarrollos, nuevos servicios y otros requerimientos comerciales más fácilmente. La relación y las metas comunes generales de cumplir con los objetivos corporativos están presentes y todos los grupos funcionan como un equipo.
-
Debe comprometerse con el proceso SLA y el contrato.
En primer lugar, debe haber compromiso para aprender el proceso del SLA a fin de elaborar acuerdos eficaces. En segundo lugar, debe cumplir con los requisitos de servicio del contrato. No espere crear SLA de gran alcance sin la participación y el compromiso significativos de todas las personas involucradas. Este compromiso también debe provenir de la administración y de todas las personas asociadas con el proceso SLA.
Paso 8: Determinar las Partes que participan en el SLA
Los SLA de red de nivel empresarial dependen en gran medida de los elementos de red, los elementos de administración del servidor, el soporte técnico, los elementos de las aplicaciones y los requisitos empresariales o de usuario. Normalmente, la administración de cada área participará en el proceso SLA. Este escenario funciona bien cuando la organización construye SLA de soporte reactivos básicos. Las organizaciones empresariales con requisitos de mayor disponibilidad pueden necesitar asistencia técnica durante el proceso de SLA para ayudar con problemas como la presupuestación de disponibilidad, las limitaciones de rendimiento, la definición de perfiles de aplicaciones o las capacidades de administración proactiva. Para aspectos de SLA de gestión más proactivos, recomendamos un equipo técnico de arquitectos de redes y arquitectos de aplicaciones. La asistencia técnica puede ofrecer información mucho más aproximada sobre la disponibilidad y las capacidades de rendimiento de la red y lo que se necesitaría para lograr objetivos específicos.
Los SLA de proveedores de servicios normalmente no incluyen los datos proporcionados por el usuario, ya que se crean con el único propósito de obtener una ventaja competitiva para otros proveedores de servicios. En algunos casos, los altos directivos crearán estos SLA a niveles de alta disponibilidad o alto rendimiento para promover su servicio y proporcionar objetivos internos para los empleados internos. Los proveedores de servicios se concentrarán en los aspectos técnicos de disponibilidad de mejoras mediante la creación de definiciones de niveles de servicios fuertes que son medidos y administrados internamente. En otros casos, ambos esfuerzos se realizan simultáneamente pero no necesariamente juntos o con los mismos objetivos.
La elección de las partes involucradas en el SLA debe basarse en los objetivos del SLA. Algunos objetivos posibles son:
-
Cumplir los objetivos empresariales de soporte reactivo
-
Proporcionar el nivel más alto de disponibilidad mediante la definición de SLA proactivos
-
Promoción o venta de un servicio
Paso 9: Determinación de los elementos de servicio
Comúnmente, el servicio primario/soporte de los SLA tendrá muchos componentes, los cuales incluyen el nivel de soporte, la forma en la que será medido, el trayecto de escalación para la reconciliación de SLA y las preocupaciones relacionadas con el presupuesto general. Los elementos de servicio para entornos de alta disponibilidad deben incluir definiciones de servicios proactivos, así como objetivos reactivos. Los detalles adicionales incluyen lo siguiente:
-
Horas hábiles de soporte en el sitio y los procedimientos de soporte fuera de horario.
-
Definiciones de prioridad, incluido el tipo de problema, el tiempo máximo para comenzar a trabajar en el problema, el tiempo máximo para resolverlo y los procedimientos de derivación
-
Productos y servicios con soporte, categorizados por orden de criticidad comercial.
-
Soporte para expectativas de destreza, expectativas de nivel de rendimiento, generación de informes de estado y responsabilidades del usuario en la solución de problemas
-
Problemas y requisitos de nivel de soporte geográfico o de la unidad empresarial
-
Metodología y procedimientos de administración de problemas (sistema de seguimiento de llamadas)
-
Objetivos del soporte técnico
-
Detección de errores de red y respuesta de servicio
-
Medición y generación de informes de disponibilidad de la red
-
Medición y generación de informes de rendimiento y capacidad de la red
-
Procedimientos de solución de conflictos
-
Financiación del SLA implementado
Los SLA de aplicaciones o servicios en red pueden tener necesidades adicionales en función de los requisitos de los grupos de usuarios y la importancia empresarial. La organización de la red debe escuchar atentamente estos requisitos empresariales y desarrollar soluciones especializadas que encajen en la estructura de soporte general. La integración en la cultura de soporte general es fundamental porque es importante no crear un servicio de primera clase dirigido únicamente a algunas personas o grupos. En muchos casos, estos requisitos adicionales pueden clasificarse en categorías de "solución". Un ejemplo podría ser una solución platinada, dorada y plateada basada en las necesidades empresariales. Consulte los siguientes ejemplos de requisitos SLA para cubrir necesidades comerciales específicas.
Nota: La estructura de soporte, la ruta de derivación, los procedimientos de soporte técnico, las mediciones y las definiciones de prioridad deben permanecer en gran medida iguales para mantener y mejorar una referencia cultural de servicio coherente.
-
Requisitos de ancho de banda y capacidades para ráfaga
-
Requisitos de rendimiento
-
Requisitos y definiciones de QoS
-
Requisitos de disponibilidad y redundancia para crear una matriz de soluciones
-
Requisitos, metodología y procedimientos de supervisión y presentación de informes
-
Criterios de actualización para elementos de aplicaciones/servicios
-
Financiación de las necesidades no presupuestarias o metodología de cobro cruzado
Por ejemplo, puede crear categorías de soluciones para la conectividad de sitios WAN. La solución platino se proporcionaría con servicios twin T1 para el sitio. Una portadora diferente proporcionaría cada línea T1. El sitio tendrá dos routers configurados para que, en caso de que algún T1 o router falle, el sitio no sufra interrupción. El servicio gold tendría dos routers, pero se utilizaría Frame Relay de respaldo. Esta solución podría tener un ancho de banda limitado durante la interrupción. La mejor solución tendría un solo router y un servicio de portadora. Cualquiera de estas soluciones se consideraría para diferentes niveles de prioridad para las notificaciones de problemas. Algunas organizaciones pueden necesitar una solución de platino o de oro si se requiere un ticket de prioridad 1 ó 2 para una interrupción. A continuación, las organizaciones de los clientes pueden financiar el nivel de servicio que necesitan. La siguiente tabla muestra un ejemplo de una organización que ofrece tres niveles de servicio, según la necesidad que presente la empresa de una conectividad de red externa.
| Solución | Platino | Gold | Plata |
|---|---|---|---|
| Dispositivos | Routers redundantes para conectividad WAN | Router redundante para realizar copias de seguridad en el sitio central | Sin redundancia de dispositivo |
| WAN | Conectividad T1 redundante, varias portadoras | Conectividad T1 con copia de seguridad de Frame Relay | Sin redundancia WAN |
| Requisitos de ancho de banda y ráfaga | T1 redundante con distribución de carga para ráfaga. | Uso compartido sin carga, copia de seguridad de Frame Relay sólo para aplicaciones críticas; Frame Relay 64K CIR solamente | Hasta T1 |
| Rendimiento | Tiempo de respuesta de ida y vuelta uniforme de 100 ms o menos | Tiempo de respuesta 100 ms o un 99.9% menos esperado. | Tiempo de respuesta 100 ms o un 99% menos esperado. |
| Requisito de disponibilidad | 99.99% | 99.95% | 99.9% |
| Prioridad del soporte técnico cuando está inactivo | Prioridad 1: el servicio de importancia comercial no funciona | Prioridad 2: el servicio de impacto comercial está fuera de servicio | Prioridad 3: conectividad empresarial inactiva |
Paso 10: Información sobre las Necesidades y los Objetivos Corporativos del Cliente
Este paso le otorga al desarrollador de SLA gran credibilidad. Al comprender las necesidades de los diversos grupos de negocio, el documento de SLA inicial estará mucho más cerca del requisito empresarial y el resultado deseado. Intente comprender el coste del tiempo de inactividad para el servicio al cliente. Estimación en términos de pérdida de productividad, ingresos y buena voluntad del cliente. Tenga en cuenta que incluso las conexiones simples con unas pocas personas pueden afectar seriamente a los ingresos. En este caso, asegúrese de ayudar al cliente a comprender los riesgos de disponibilidad y rendimiento que pueden producirse para que la organización comprenda mejor el nivel de servicio que necesita. Si se pierde este paso, es posible que muchos clientes exijan simplemente una disponibilidad del 100%.
El desarrollador SLA también debería entender los objetivos del negocio y el crecimiento de la organización para alojar actualizaciones de red, la carga de trabajo y el presupuesto. También es útil comprender las aplicaciones que se utilizarán. Ojalá la organización tenga perfiles de aplicación en cada aplicación, pero si no, considere hacer una evaluación técnica de la aplicación para determinar los problemas relacionados con la red.
Paso 11: Definir el SLA necesario para cada grupo
El soporte primario de SLA debe incluir unidades comerciales cruciales y representación de grupos funcionales, como operaciones de red, operaciones de servidor y grupos de soporte de aplicaciones. Estos grupos deben reconocerse de acuerdo con las necesidades comerciales y rol que tienen en el proceso complementario. Tener representación de muchos grupos también ayuda a crear una solución de apoyo general equitativa sin preferencia o prioridad individual de cada grupo. Esto puede llevar a una organización de soporte a ofrecer un servicio de primera a grupos individuales, un escenario que puede obstaculizar la cultura de servicio en general de la organización. Por ejemplo, un cliente podría insistir en que su aplicación es la más importante dentro de la empresa cuando, en realidad, el coste del tiempo de inactividad de esa aplicación es significativamente menor que el de otros en términos de pérdida de ingresos, pérdida de productividad y pérdida de buena voluntad del cliente.
Las distintas unidades empresariales de la organización tendrán requisitos diferentes. Un objetivo de SLA de red debe ser acordar un formato integral que se ajuste a los distintos niveles de servicio. Estos requisitos suelen ser disponibilidad, QoS, rendimiento y MTTR. En el SLA de red, estas variables se gestionan priorizando las aplicaciones empresariales para el posible ajuste de QoS, definiendo las prioridades del soporte técnico para el MTTR de diferentes problemas que afectan a la red y desarrollando una matriz de soluciones que ayudará a gestionar los diferentes requisitos de disponibilidad y rendimiento. Un ejemplo de una matriz de soluciones sencilla para una empresa de fabricación empresarial puede tener un aspecto similar al de la tabla siguiente. Puede agregar información sobre la disponibilidad, Calidad de servicio (QoS) y rendimiento.
| Unidad empresarial | Aplicaciones | Coste del tiempo de inactividad | Prioridad de problemas cuando desciende | Requisito de Servidor/Red |
|---|---|---|---|---|
| Fabricación | ERP | Alto | 1 | Redundancia más alta |
| Soporte de cliente | Atención al cliente | Alto | 1 | Redundancia más alta |
| Ingeniería | Servidor de archivos, diseño ASIC | Medio | 2 | redundancia de núcleo LAN |
| Marketing | Servidor de archivos | Medio | 2 | redundancia de núcleo LAN |
Paso 12: Elija el Formato del SLA
El formato del SLA puede variar según los deseos del grupo o los requisitos de la organización. A continuación se muestra un esquema de ejemplo recomendado para el SLA de red:
-
Objetivo del acuerdo
-
Partes involucradas en el acuerdo
-
Objetivos y objetivos del acuerdo
-
-
Servicios brindados y productos admitidos
-
Servicio de soporte técnico y seguimiento de llamadas
-
Definiciones de la gravedad de los problemas basadas en el impacto comercial para las definiciones MTTR
-
Prioridades de servicio críticas para las definiciones de QoS
-
Categorías de soluciones definidas basadas en los requisitos de disponibilidad y rendimiento
-
Requisitos de formación
-
Requisitos de planificación de la capacidad
-
Requisitos de escalación
-
Informes
-
Soluciones de red proporcionadas
-
Nuevas solicitudes de soluciones
-
Productos o aplicaciones no admitidos
-
-
Políticas empresariales
-
Asistencia durante el horario laboral
-
Definiciones de soporte fuera de hora
-
Cobertura de vacaciones
-
Números de teléfono de contacto
-
Pronóstico de carga de trabajo
-
Resolución de quejas
-
Criterios de asignación de servicios.
-
Responsabilidades de seguridad del usuario y el grupo
-
-
Procedimientos para la administración de problemas
-
Inicio de llamada (usuario y automatizado)
-
Respuesta de primer nivel y proporción de reparación de llamadas
-
Seguimiento y registro de llamadas
-
Responsabilidades de la persona que llama
-
Diagnósticos de problemas y requerimientos del cierre de llamada
-
Detección de problemas de administración de red y respuesta al servicio
-
Definiciones o categorías de resolución de problemas
-
Gestión de problemas crónicos
-
Gestión de problemas críticos/llamadas de excepción
-
-
Objetivos de calidad del servicio
-
Definiciones de calidad
-
Definiciones de medición
-
Metas de calidad
-
Tiempo medio para iniciar la resolución de problemas por prioridad
-
Tiempo medio para resolver el problema por prioridad
-
Tiempo medio para sustituir el hardware por prioridad de problema
-
Disponibilidad y rendimiento de la red
-
Gestión de la capacidad
-
Gestión del crecimiento
-
Generación de informes de calidad
-
-
Personal y presupuestos
-
Modelos de dotación de personal
-
presupuesto de operaciones
-
-
Mantenimiento del acuerdo
-
Calendario de revisión de conformidad
-
Presentación de informes y examen del desempeño
-
Conciliación de métricas de informes
-
Actualizaciones de SLA periódicas
-
-
Aprobaciones
-
Archivos adjuntos y exposiciones
-
diagramas de flujo de llamadas
-
Matriz de derivación
-
Matriz de la solución de red
-
Ejemplos de informe
-
Paso 13: Desarrollar grupos de trabajo SLA
El siguiente paso es identificar a los participantes en el grupo de trabajo SLA, incluido el líder del grupo. El grupo de trabajo puede incluir a usuarios y administradores de unidades comerciales, grupos funcionales o representantes de una base geográfica. Estos individuos comunican los problemas de SLA a sus respectivos grupos de trabajo. Los gerentes y responsables de la toma de decisiones que puedan ponerse de acuerdo sobre los elementos clave del SLA deben participar. Estos individuos puede incluir individuos administradores así como técnicos que pueden ayudar a definir problemas técnicos relacionados con SLA y tomar decisiones a nivel de IT (es decir, administrador del escritorio de ayuda, administrador de operaciones del servidor, administradores de aplicaciones y administrador de operaciones de la red).
El grupo de trabajo SLA de la red debería también consistir en aplicaciones amplias y representaciones comerciales con el propósito de obtener un acuerdo sobre una red SLA que incluya muchas aplicaciones y servicios. El grupo de trabajo debe tener la autoridad para clasificar los procesos y servicios vitales para la red, así como los requisitos de disponibilidad y rendimiento para los servicios individuales. Se utilizará esta información para crear prioridades para diferentes tipos de problemas que impacten a la empresa, para priorizar el tráfico comercial crítico en la red y para crear soluciones futuras de redes estándar basadas en los requerimientos de la empresa.
Paso 14: Celebrar reuniones de grupos de trabajo y redactar el SLA
El grupo de trabajo debería crear un estatuto de grupo de trabajo al comienzo. El informe debe mostrar los objetivos, las iniciativas y las tramas de tiempo para SLA. A continuación, el grupo debe desarrollar planes de tareas específicos y determinar las programaciones y los horarios para desarrollar e implementar el SLA. El grupo también debería desarrollar el proceso de presentación de informes para medir el nivel de apoyo con arreglo a los criterios de apoyo. El paso final es crear el proyecto de acuerdo de SLA.
El grupo de trabajo en red SLA debería reunirse una vez por semana para desarrollar el SLA. Una vez que se ha creado y aprobado el SLA, el grupo puede reunirse mensualmente o incluso trimestralmente para las actualizaciones del SLA.
Paso 15: Negociar el SLA
El último paso para crear el SLA es la negociación final y la firma. Este paso incluye:
-
Examen del proyecto
-
Negociación del contenido
-
Edición y revisión del documento
-
Obtención de la aprobación final
Este ciclo de revisión del borrador, negociación de contenidos y edición puede requerir varios ciclos antes de que la versión final se envíe a la administración para su aprobación.
Desde la perspectiva del administrador de red, es importante negociar resultados alcanzables que se puedan medir. Intente respaldar los acuerdos de rendimiento y disponibilidad con aquellos de otras organizaciones relacionadas. Esto puede incluir definiciones de calidad, definiciones de medición y objetivos de calidad. Recuerde que el servicio agregado es equivalente a un costo extra. Asegúrese de que los grupos de usuarios entienden que los niveles de servicio adicionales costarán más y les permitirán tomar la decisión si se trata de un requisito empresarial fundamental. Puede realizar fácilmente un análisis de los costos en varios aspectos del SLA, tales como el tiempo de reemplazo del hardware.
Paso 16: Medir y Monitorear la Conformidad de SLA
Medir el cumplimiento de los SLA y los resultados de los informes son aspectos importantes del proceso de SLA que ayudan a garantizar la coherencia y los resultados a largo plazo. Por lo general, recomendamos que cualquier componente importante de un SLA sea mensurable y que se establezca una metodología de medición antes de la implementación del SLA. A continuación, lleve a cabo reuniones mensuales entre los grupos de usuarios y de soporte para revisar las mediciones, identificar las causas principales de los problemas y proponer soluciones para cumplir o superar los requisitos de nivel de servicio. Esto ayuda a que el proceso SLA sea similar a cualquier programa de mejora de calidad moderno.
La siguiente sección proporciona detalles adicionales sobre cómo la administración dentro de una organización puede evaluar sus SLA y su administración general del nivel de servicio.
Indicadores de rendimiento de la administración de nivel de servicio
Los indicadores de rendimiento de la administración del nivel de servicio brindan un mecanismo para monitorear y mejorar los niveles de servicio como medida del éxito. Esto permite que la organización reaccione más veloz a los problemas de servicio y comprenda más fácilmente los problemas que impactan al servicio o el costo de tiempo caído en su entorno. Si no se miden las definiciones de nivel de servicio, también se niega cualquier trabajo proactivo positivo realizado porque la organización se ve obligada a adoptar una postura reactiva. Nadie llamará diciendo que el servicio funciona bien, pero muchos usuarios llamarán para decir que el servicio no cumple con sus requisitos.
Los indicadores de rendimiento de la administración de niveles de servicio son, por lo tanto, el requisito principal para la administración de niveles de servicio, dado que proporcionan los medios para comprender cabalmente los niveles de servicio existentes y para realizar ajustes en función de los problemas actuales. Esta es la base para brindar soporte proactivo y hacer mejoras en la calidad. Cuando la organización realiza un análisis sobre el origen de los problemas y optimiza la calidad, ésta puede ser la mejor metodología a fin de mejorar la disponibilidad, el rendimiento y la calidad de servicio disponibles.
Por ejemplo, considere el siguiente escenario real. La empresa X estaba recibiendo numerosas quejas de los usuarios por el hecho de que la red se encontraba a menudo inactiva durante largos períodos de tiempo. Al medir la disponibilidad, la empresa encontró que el problema principal eran unos pocos sitios WAN. Una investigación más estrecha de estos puntos de vista reveló que la mayoría de los problemas se encontraban en unos pocos sitios WAN. Se encontró la causa principal y la organización resolvió el problema. Luego, la organización estableció objetivos de nivel de servicio para la disponibilidad y celebró acuerdos con grupos de usuarios. Las mediciones futuras identificaron problemas rápidamente debido a la falta de conformidad con el SLA. A continuación, se consideró que el grupo de redes contaba con una mayor profesionalidad, experiencia y un activo general para la organización. El grupo se movió efectivamente de reactivo a proactivo en naturaleza y la línea inferior de la compañía colaboró en esto.
Desafortunadamente, la mayoría de las organizaciones de redes cuentan con definiciones limitadas de niveles de servicio y no poseen indicadores de rendimiento. Como resultado, dedican la mayor parte del tiempo a reaccionar ante las quejas o los problemas de los usuarios en lugar de identificar de forma proactiva la causa principal y crear un servicio de red que cumpla los requisitos empresariales.
Utilice los siguientes indicadores de rendimiento de SLA para determinar el éxito del proceso de administración de niveles de servicio:
-
Definición de nivel de servicio o SLA documentada que incluye disponibilidad, rendimiento, tiempo de respuesta del servicio reactivo, objetivos de resolución de problemas y escalación de problemas
-
Las mediciones de indicador de rendimiento, incluyen disponibilidad, rendimiento, tiempo de respuesta del servicio por medio de prioridad, tiempo para resolver por prioridad y otros parámetros de SLA que se pueden medir.
-
Reuniones mensuales de gestión de nivel de servicio de redes para revisar el cumplimiento de nivel de servicio e implementar mejoras
Contrato de nivel de servicio documentado o definición de nivel de servicio
El primer indicador de rendimiento es simplemente un documento que detalla el SLA o la definición del nivel de servicio. Los objetivos primordiales de la definición de nivel de servicio deben ser la disponibilidad y el rendimiento dado que son los requisitos principales de los usuarios.
Los objetivos secundarios son importantes porque ayudan a definir cómo se alcanzarán los niveles de disponibilidad o rendimiento. Por ejemplo, si la organización tiene objetivos de rendimiento y disponibilidad agresivos, será importante evitar que se produzcan problemas y solucionarlos rápidamente cuando se produzcan. Los objetivos secundarios ayudan a definir los procesos necesarios para alcanzar los niveles de disponibilidad y rendimiento deseados.
Los objetivos secundarios reactivos incluyen:
-
Tiempo de respuesta de servicio reactivo por prioridad de llamada
-
Objetivos de resolución de problemas o MTTR
-
Procedimientos para el incremento de la gravedad de los problemas.
Los objetivos secundarios proactivos incluyen:
-
Detección de dispositivos inactivos o de enlaces inactivos
-
Detección de errores de red
-
Detección de problemas de capacidad o rendimiento.
La definición del nivel de servicio para metas primarias, disponibilidad y rendimiento debe incluir:
El objetivo
-
Cómo se medirá el objetivo
-
Partes responsables de medir la disponibilidad y el rendimiento
-
Partes responsables de los objetivos de disponibilidad y rendimiento
-
Procesos de no conformidad
De ser posible, recomendamos que las partes responsables de la medición y las partes responsables de los resultados sean diferentes para evitar un conflicto de intereses. De vez en cuando, también puede que tenga que ajustar los números de disponibilidad debido a errores de adición/movimiento/cambio, errores no detectados o problemas de medición de disponibilidad. La definición del nivel de servicio también puede incluir un proceso para la modificación de resultados que ayude a mejorar la exactitud y prevenir ajustes inapropiados. Consulte la siguiente sección sobre las metodologías para medir disponibilidad y rendimiento.
La definición de nivel de servicio para objetivos secundarios reactivos especifica cómo responderá la organización a problemas de IT o la red, una vez que se hayan identificado, que incluyen:
-
Definiciones de prioridad de problema
-
Tiempo de respuesta de servicio reactivo por prioridad de llamada
-
Objetivos de la solución de problemas o MTTR
-
Procedimientos para el incremento de la gravedad de los problemas
En general, estos objetivos definen quién será responsable de los problemas en un momento dado y en qué medida los responsables deben abandonar sus tareas actuales para trabajar en los problemas definidos. Al igual que otras definiciones de nivel de servicio, el documento de nivel de servicio debería detallar cómo se medirán los objetivos, las partes responsables de la medición y los procesos de no conformidad.
La definición del servicio para objetivos secundarios proactivos, define cómo la organización proporciona soporte proactivo, incluyendo las condiciones de identificación de caída de la red, del link o de los dispositivos, las condiciones de error de la red y los umbrales de capacidad de la red. Establezca objetivos que promuevan la gestión proactiva porque la gestión proactiva de calidad ayuda a eliminar los problemas y a solucionar los problemas más rápidamente. Generalmente se logra esto fijando un objetivo de la cantidad de casos proactivos creados y resueltos sin notificación del usuario. Muchas organizaciones configuran un indicador en el software de soporte técnico para identificar casos proactivos frente a casos reactivos con este fin. El documento de nivel del servicio debería contener también información sobre la forma en que se medirá el objetivo, las partes responsables de la medición y los procesos de no conformidad.
Métricas del Indicador de rendimiento
Siempre recomendamos que toda meta definida de nivel de servicio sea cuantificable, de manera tal que la organización pueda medir los niveles de servicio, identificar los problemas de causas raíz del servicio que dificultan la meta principal de disponibilidad y desempeño y efectuar mejoras dirigidas a objetivos específicos. A nivel general, las mediciones son sólo una herramienta que permite a los administradores de la red gestionar la coherencia en el nivel de los servicios y hacer mejoras de acuerdo a los requerimientos comerciales.
Desafortunadamente, muchas organizaciones no recolectan información sobre la disponibilidad, el rendimiento y otras mediciones. Las organizaciones atribuyen esto a la incapacidad de proporcionar una precisión completa, costes, sobrecarga de red y recursos disponibles. Estos factores pueden impactar en la capacidad de medición de los niveles de servicio, pero la organización debe concentrarse en los objetivos generales de administración y mejora de esos niveles. Muchas organizaciones han podido crear métricas de bajo coste y bajo consumo que pueden no proporcionar una precisión completa, pero que cumplen estos objetivos principales.
La medición de la disponibilidad y el rendimiento es un área que a menudo se descuida en las métricas de nivel de servicio. Las organizaciones que implementan exitosamente estas métricas usan dos métodos bastante simples. Un método consiste en enviar paquetes de ping de Protocolo de control de mensajes de Internet (ICMP) desde una ubicación central en la red hacia los bordes. También puede obtener rendimiento a través de este método. Las organizaciones que son exitosas con este método también agrupan dispositivos parecidos en "grupos de disponibilidad", como dispositivos LAN u oficinas de campo domésticas. Esto también resulta atractivo porque las organizaciones suelen tener diferentes objetivos de nivel de servicio para diferentes áreas geográficas o empresariales críticas de la red. Esto permite que las métricas promedien todos los dispositivos con el grupo de disponibilidad para obtener un resultado razonable.
El otro método exitoso para calcular la disponibilidad es utilizar tickets de problema y una medición denominada minutos de usuarios impactados (IUM). Este método tabula la cantidad de usuarios que han sido afectados por una interrupción y lo multiplica por la cantidad de minutos de la interrupción. Cuando se expresa como un porcentaje de minutos totales en el periodo, se puede convertir fácilmente a disponibilidad. En cualquier caso, también puede ser útil identificar y medir la causa raíz del tiempo de inactividad para que la mejora pueda ser más fácil de enfocar. Las categorías de causas de los problemas incluyen problemas de hardware, software, link o portadora, potencia o entorno, fallas de cambios y errores de los usuarios.
Los objetivos de soporte reactivo cuantificables incluyen:
-
Tiempo de respuesta de servicio reactivo por prioridad de llamada
-
Objetivos de la solución de problemas o MTTR
-
Tiempo del problema de escalación
Mida los objetivos de soporte reactivo generando informes desde las bases de datos del soporte técnico, incluidos los campos siguientes:
-
La hora en que se informó una llamada inicialmente (o se ingresó a la base de datos).
-
La hora en que la persona que estaba trabajando en el problema aceptó la llamada
-
La hora en la que se escaló el problema
-
La hora en la que se cerró el problema
Estas métricas pueden requerir la influencia de la administración para ingresar regularmente problemas en la base de datos y actualizarlos en tiempo real. En algunos casos, las organizaciones pueden generar automáticamente notificaciones de incidencias para eventos de red o solicitudes de correo electrónico. Esto ayuda a proporcionar precisión para identificar la hora de inicio de un problema. Normalmente, los informes generados desde este tipo de métrica clasifican los problemas por prioridad, grupo de trabajo y personas para ayudar a determinar los problemas potenciales.
Medir los procesos de soporte proactivo es más difícil porque requiere que supervise el trabajo proactivo y calcule alguna medida de su eficacia. Se ha hecho poco en esta esfera. Sin embargo, está claro que sólo un pequeño porcentaje de personas informará realmente de los problemas de red a un soporte técnico y, cuando lo haga, se necesitará tiempo para explicar el problema o aislarlo como relacionado con la red. No todos los casos proactivos tendrán un efecto inmediato en la disponibilidad y el rendimiento, ya sea por la falla de los dispositivos redundantes o de los enlaces, lo que tendrá poco impacto en los usuarios finales.
Las organizaciones que implementan las definiciones o acuerdos de nivel de servicio proactivos hacen eso a causa de los requisitos comerciales y el riesgo potencial de disponibilidad. La medición se realiza en términos de la cantidad o el porcentaje de casos proactivos, a diferencia de los casos reactivos generados por los usuarios. Es una buena idea medir también la cantidad de casos proactivos en cada área. Estas categorías incluirían dispositivos inactivos, links inactivos, errores de red y violaciones de capacidad. También se puede realizar un trabajo con el modelado de la disponibilidad y los casos proactivos para determinar el efecto en la disponibilidad logrado al implementar las definiciones de servicio proactivo.
Revisión de la administración de nivel de servicio
Otra medida del éxito de la administración del nivel de servicio es la revisión de la administración del nivel de servicio. Esto debe hacerse ya sea que existan o no SLA (contratos de nivel de servicio). Ejecute la revisión de la administración de nivel de servicio en una reunión mensual con individuos responsables de medir y proveer niveles de servicios definidos. Los grupos de usuarios también pueden estar presentes cuando están involucrados los SLA. El objetivo de la reunión es evaluar el rendimiento de las definiciones del nivel de servicio medido y realizar mejoras.
Cada reunión debería tener un programa definido que incluya:
-
Revisión de los niveles de servicio para el período determinado.
-
Revise las iniciativas de mejora definidas para las áreas individuales.
-
Métricas de nivel de servicio actuales
-
Un debate sobre las mejoras necesarias en función del conjunto actual de métricas.
Con el tiempo, la organización también puede promover el cumplimiento del nivel de servicio para determinar la eficacia del grupo. Este proceso no es distinto a un círculo de calidad o proceso de mejoramiento de calidad. La reunión ayuda a identificar problemas individuales y a determinar soluciones basadas en la causa raíz.
Resumen de administración de nivel de servicio
En resumen, la gestión de nivel de servicio permite a una organización pasar de un modelo de soporte reactivo a un modelo de soporte proactivo en el que la disponibilidad y los niveles de rendimiento de la red se determinan por los requisitos empresariales, no por el último conjunto de problemas. El proceso ayuda a crear un entorno de mejoras continuas en el nivel del servicio continua y aumenta la competitividad comercial. La administración del nivel de servicio también es el componente de administración más importante para la administración proactiva de la red. Por esta razón, la administración del nivel de servicio se recomienda en gran medida en cualquier fase de planificación y diseño de la red y debe comenzar con cualquier arquitectura de red recientemente definida. Este permite que la organización implemente soluciones de forma correcta desde la primera vez, con la menor cantidad de tiempo de inactividad o de corrección.
Información Relacionada
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)