Field Notice: FN - 63249 - MGX: A software bug CSCea28215 in VxWorks caused incorrect handling of rollover tick counter, various MGX Modules may require reset after 466 days - Workaround Provided
Available Languages
Notice
THIS FIELD NOTICE IS PROVIDED ON AN "AS IS" BASIS AND DOES NOT IMPLY ANY KIND OF GUARANTEE OR WARRANTY, INCLUDING THE WARRANTY OF MERCHANTABILITY. YOUR USE OF THE INFORMATION ON THE FIELD NOTICE OR MATERIALS LINKED FROM THE FIELD NOTICE IS AT YOUR OWN RISK. CISCO RESERVES THE RIGHT TO CHANGE OR UPDATE THIS FIELD NOTICE AT ANY TIME.
Revision History
| Revision | Publish Date | Comments |
|---|---|---|
1.0 |
19-Oct-10 |
Initial Release |
10.0 |
12-Oct-17 |
Migration to new field notice system |
10.1 |
30-Jul-18 |
Updated the Concept Tags |
Products Affected
| Affected OS Type | Affected Release | Affected Release Number | Comments |
|---|---|---|---|
NON-IOS |
1.3 |
1.3(1) |
Defect Information
| Defect ID | Headline |
|---|---|
| CSCea28215 | VxWorks timer failing after 466+ days |
Problem Description
This field notice augments the Field Notice 24094. It provides additional information specific to MGX2 modules.
If a PXM or a service module is up for more than 466 days, PXM or a service module can become unresponsive. These are other symptoms that can surface:
- Unable to change Card with CC CLI
- Statistics collection slows down or stops
- Standby PXM or service module may not get updates
- dspcduptime and dsprmrsrcs CLIs can show incorrect value of card uptime
- In some instances, added ports may not register on PXM or service module
The condition can be observered on one or more of the MGX modules listed here:
- PXM1E (All models)
- PXM45 (All models)
- AXSM (All models)
- AXSM/E (All models)
- AXSM-XG (All models)
- MPSM (All models)
- VXSM (All models)
- VISM(All models)
MGX models impacted are 8850, 8830, 8880 and 8950.
In the subsequent discussion of this field notice, the term Module refers to any of these modules, unless otherwise specified.
Background
This bug resulted in mishandling of a system clock rollover counter in VxWorks Operating System and can exhibit symptom based on the task scheduled.
The Operating System simultaneously maintains two independent data structures that are used to keep an accurate representation of the time. One of the 32-bit counters reflects the number of ticks, 1 tick = 10 msec, since the card reset. This counter rolls over every (2^32/100) seconds or 497.1 days.
In a real-time preemptive multitasking environment, the Operating System allows tasks to schedule delays. The delay scheduling feature is used extensively by the MGX application software. This condition arises when a delay is scheduled to expire after the 32-bit counter rolls over. The clock value can be incorrect by the amount of the scheduled delay due to a software bug in the VxWorks Operating System, depending on the value of the delay. Values as large as 31 days are used in application software.
The timer counter value is local to the card. Inconsistencies arise between the card and external entities (e.g. statistics collectors) and can impact time base activities run by the software. An incorrect timer counter value can lead to unpredictable timer expiration and a rapid-fire software task sequence, some immediately. This failure of the timer infrastructure can be observed in symptoms such as excessive CPU utilization and message flooding, which results in severe degradation of the node.
Based on the task schedule, the rollover of value 0xF0000000 can exhibit different symptoms.
The VxWorks version affected 5.3.1 or 5.4.2, based on the MGX module and the MGX software version that is used in theMGX products.
Problem Symptom
These are the various possible symptoms:
- The system date can change to another date often to a date one month ahead
- User unable to change card (cc)
- Statistics task can not run
- Database errors can occur
- dspcduptime and dsprmrsrcs CLIs can show incorrect value of card uptime
Workaround/Solution
User Alert Mechanisms User alert mechanisms are available through the CLI and trap as listed here:
- dspcduptime CLI returns PXM and Service modules Card uptime information.
- dsprmrsrcs CLI provides information about thresholds for alarm severities for card uptime.
- Trap cwModuleUptimeReport is sent when a module is up for more than 440 days. Once a module is up for more than 440 days, this trap is sent once every day. The severity of the trap is low if card up time is less than 460 days. The severity of the trap is raised to medium if card up time is more than 460 days.
Event logs are generated to indicate that card up time is more than 440 days and the rollover time is nearing. The traps and event logs are generated in advance, in order to allow operator to choose suitable time when the workaround can be exercised.
There are two methods of evaluating whether an MGX Module is subject to this bug:
Method 1
Use dspcduptime or dsprmrsrcs CLI on the Module to find out the number of days for which a card is up. n212.3.AXSMXG.a > dspcduptime 6 Days 23 Hours 48 Minutes 21 Seconds System Uptime filed can be looked for in the dsprmrsrcs CLI output.
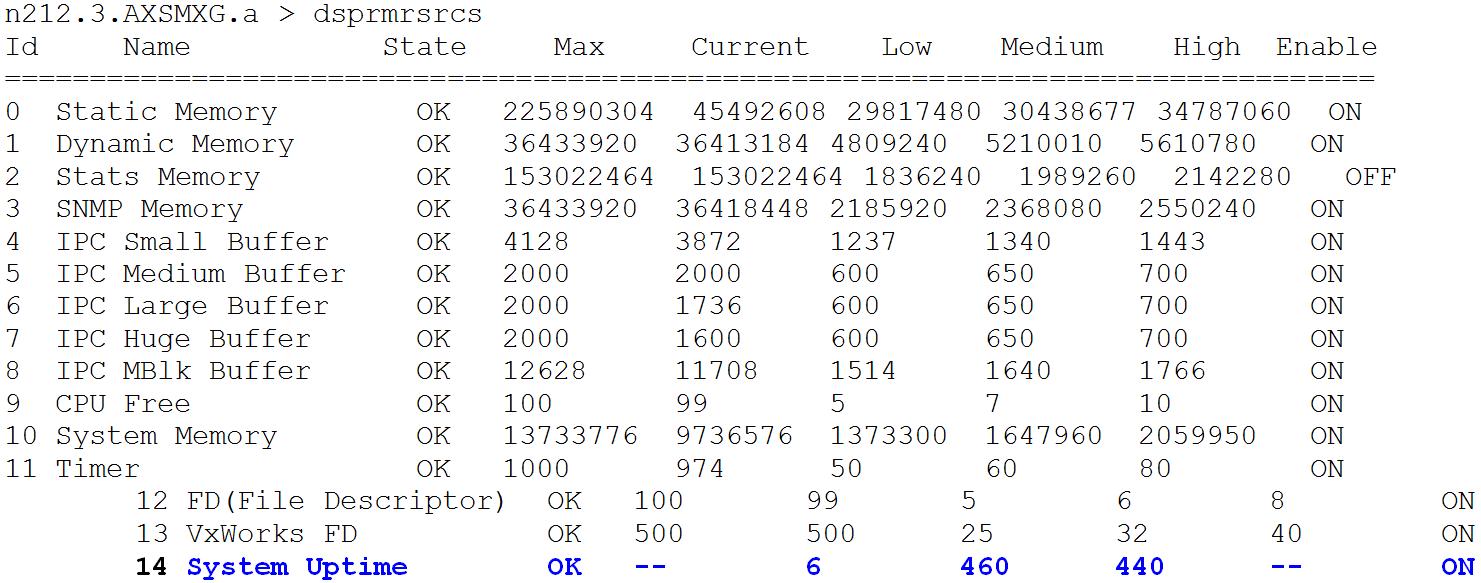
Method 2
Note: This method is for cases where dspcduptime and dsprmrsrcs CLIs are not supported.
Complete these steps in order to determine how close the 466 day threshold is:
- Log into the shell with the shellcon command.
- Execute the sysClkTickGet command.
The response appears in both decimal and hexadecimal notations.
mgx11.1.7.PXM.a > shellcon
-> sysClkTickGet sysClkTickGet value = 132375064 = 0x7e3e218 Decimal Hex
- If the hex value is greater than or equal to 0xF0000000, the card is immediately vulnerable to the problem and a switchover must be scheduled immediately. Note that if the counter exceeds 0xF0000000, the MGX's connection database may not yet be affected. See Secondary Checks for further information.
- If the value is less than 0xF0000000, the number of days uptime can be calculated from the shellconn prompt: /100/60/60/24. The value of this computation is the number of days.
Rationale for Field Notice
This bug requires changes in the operating kernel as well as in MGX software.
This bug exists in all the versions of the VxWorks operating system utilized by MGX platform.
This is a system limitation and applies to all the MGX releases. This limitation can not be fixed completely through software changes.
Prevention and Recovery Mechanisms
Note: If the problem already manifests itself, RMA of a Module card set does not help since the MGX needs to be recovered manually. If you wait for an RMA to arrive, it simply delays the recovery process. You do not need to open an RMA. Instead, use the steps in the Prevention/Recovery Procedure sections of this field notice.
Preventive Measures
Complete this procedure if the card uptime is less than 466 days.
Before the card is up for 466 days, a redundant switchover must be induced or the module must be reset in case of non-redundancy.
Preventive Measures for Redundant Module
Complete these steps in order to reset both clock counters. This activity must be performed prior to 466 days and before the problem symptom occurs.
- Reset the Standby Module.
- Wait for the Standby Module to come back to Standby state. The clock on the Standby Module resets back to the initial time after the reset.
- Switch Active and Standby Modules. Use the switchcc command for PXM and use the switchredcd command for the service modules.
- Wait for the formerly Active Module to come to Standby state.
The formerly Active Module re-initializes the counter after the switch over, which delays the onset of the 466+ wraparound.
This procedure must be repeated as the 466+ threshold approaches.
Note: Any switchover on the Module results in a re-initialization of the clock of the formerly Active Module.
Preventive Measures for Non-Redundant Module
Note: For non-redundant modules, the preventive measures must be performed in maintenance window.
Complete these steps through the MGX Console port in case of PXM45 and PXM1E.
- Reset the Module.
- Wait until the Module comes back to Active.
- Verify access to, and responsiveness of, the command line interface. Verify traffic passes normally.
Recovery Procedure
Use these procedures if the card uptime is more than 466 days.
Note: For non-redundant modules, the recovery procedure must be performed in the maintenance window.
Complete these steps through the MGX Console port in case of PXM45 and PXM1E.
- As a safety measure, save a copy of the switch working configuration. This step can be skipped only if the configuration was saved recently.
- In case of redundant modules, reset both the modules simultaneously.
- In case of non-redundant modules, reset the module.
- Wait until the Modules come back to Active and Standby (if redundant).
- Verify access to, and responsiveness of, the command line interface. Verify traffic passes normally.
- If the issue impacts the database, one needs to load the previously saved working configuration.
This decision tree can be used in order to implement the workaround:
Note: This hierarchical approach is acceptable because a standby card cannot be up longer than its associated active card.

Additional Information
Frequently Asked Questions (FAQs)
Question: Are system uptime related alarms cleared if a module is up for more than 497 days?
Answer: No.
Question: Is there a provision to do automatic switchover in case the uptime for a card is more than 466 days?
Answer: No. The switchover needs to be planned by the operator, which is preferably done in a maintenance window. For non-redundant modules, the switchover must be done in a maintenance window.
Question: Why can't the automatic switchover or reset be done once it is detected that a card is up for more than 466 days?
Answer: Automatic switchover or reset initiated by the system can impact service. As a result, this is deliberately left out of the software.
Question: Is there an MGX software release in which this issue is completely fixed?
Answer: No. Only Workaround is available.
Question: Is there a planned MGX release in which this issue can be completely fixed?
Answer: No.
Question: How much time does the recovery take?
Answer: Depending on whether the module is a service module or PXM and based on the configuration size, the recovery time can vary from a few seconds to a few minutes.
For More Information
If you require further assistance, or if you have any further questions regarding this field notice, please contact the Cisco Systems Technical Assistance Center (TAC) by one of the following methods:
Receive Email Notification For New Field Notices
Cisco Notification Service—Set up a profile to receive email updates about reliability, safety, network security, and end-of-sale issues for the Cisco products you specify.
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)
This Document Applies to These Products
Unleash the Power of TAC's Virtual Assistance