Einleitung
In diesem Dokument wird das Verfahren zur Wiederherstellung des Cluster Manager vom ursprünglichen Server in der Konfiguration der Cloud Native Deployment Platform (CNDP) beschrieben.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in folgenden Bereichen verfügen:
- Cisco Subscriber Microservices Infrastructure (SMI)
- 5G CNDP- oder SMI-Bare-Metal-Architektur (BM)
- Distributed Replicate Block Device (DRBD)
Verwendete Komponenten
Die Informationen in diesem Dokument basierend auf folgenden Software- und Hardware-Versionen:
- SMI 2020,02,2,35
- Kubernetes v1.21.0
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Hintergrundinformationen
Was ist SMI Cluster Manager?
Ein Cluster-Manager ist ein Keepalive-Cluster mit zwei Knoten, der als Ausgangspunkt für die Cluster-Bereitstellung auf Kontroll- und Benutzerebene verwendet wird. Es führt einen Kubernetes-Cluster mit einem Knoten und eine Reihe von PODs aus, die für die gesamte Cluster-Einrichtung verantwortlich sind. Nur der primäre Cluster-Manager ist aktiv, und der sekundäre übernimmt nur bei einem Ausfall oder wird aus Wartungsgründen manuell heruntergefahren.
Was ist ein Inception Server?
Dieser Knoten übernimmt die Lebenszyklusverwaltung des zugrunde liegenden Cluster Managers (CM). Von hier aus können Sie die Day0-Konfiguration übertragen.
Dieser Server wird in der Regel regional oder im selben Rechenzentrum wie die übergeordnete Orchestrierungsfunktion (z. B. NSO) bereitgestellt und läuft in der Regel als VM.
Problem
Der Cluster-Manager wird in einem Cluster mit zwei Knoten und verteilten replizierten Blockgeräten (DRBD) gehostet und als primärer Cluster-Manager und sekundärer Cluster-Manager weitergeführt. In diesem Fall schaltet sich der sekundäre Cluster Manager automatisch aus, während das Betriebssystem im UCS initialisiert bzw. installiert wird. Dies weist auf eine Beschädigung des Betriebssystems hin.
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 WFConnection Primary/Unknown UpToDate/DUnknown /mnt/stateful_partition ext4 568G 369G 170G 69%
Verfahren für die Wartung
Dieser Prozess unterstützt die Neuinstallation des Betriebssystems auf dem CM-Server.
Identifizieren von Hosts
Melden Sie sich bei Cluster-Manager an, und identifizieren Sie Hosts:
cloud-user@POD-NAME-cm-primary:~$ cat /etc/hosts | grep 'deployer-cm'
127.X.X.X POD-NAME-cm-primary POD-NAME-cm-primary
X.X.X.X POD-NAME-cm-primary
X.X.X.Y POD-NAME-cm-secondary
Clusterdetails vom Überwachungsserver identifizieren
Melden Sie sich beim Inception-Server an, wechseln Sie zum Deployer, und überprüfen Sie den Clusternamen mit hosts-IP vom Cluster-Manager.
Melden Sie sich nach erfolgreicher Anmeldung beim Inception-Server wie hier gezeigt im Betriebszentrum an.
user@inception-server: ~$ ssh -p 2022 admin@localhost
Überprüfen Sie den Clusternamen von Cluster Manager SSH-IP (ssh-ip = Node SSH IP ip-address = ucs-server cimc ip-address).
[inception-server] SMI Cluster Deployer# show running-config clusters * nodes * k8s ssh-ip | select nodes * ssh-ip | select nodes * ucs-server cimc ip-address | tab
SSH
NAME NAME IP SSH IP IP ADDRESS
------------------------------------------------------------------------------
POD-NAME-deployer cm-primary - X.X.X.X 10.X.X.X ---> Verify Name and SSH IP if Cluster is part of inception server SMI.
cm-secondary - X.X.X.Y 10.X.X.Y
Überprüfen Sie die Konfiguration für den Zielcluster.
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME-deployer
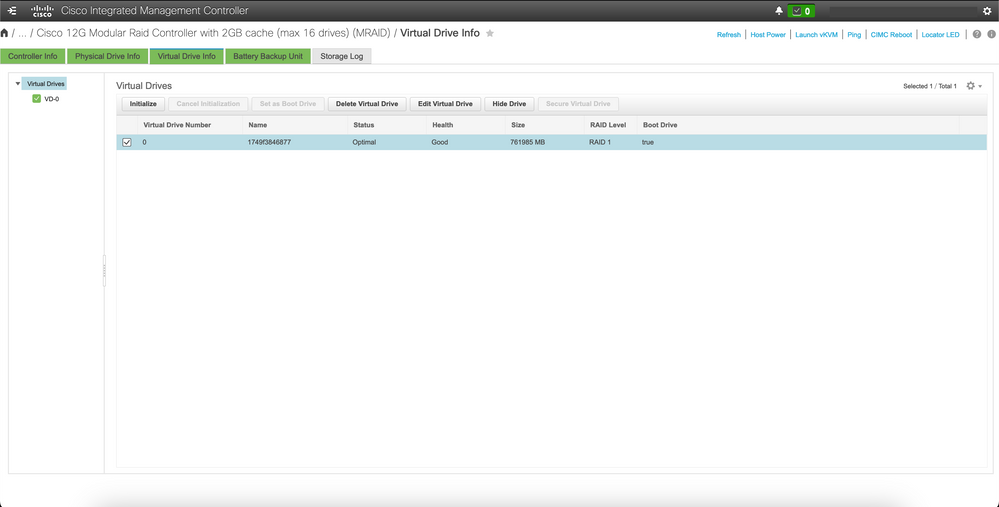
Entfernen Sie das virtuelle Laufwerk, um das Betriebssystem vom Server zu löschen.
Stellen Sie eine Verbindung zum CIMC des betroffenen Hosts her, löschen Sie das Boot-Laufwerk, und löschen Sie das virtuelle Laufwerk.
a) CIMC > Storage > Cisco 12G Modular Raid Controller > Storage Log > Clear Boot Drive
b) CIMC > Storage > Cisco 12G Modular Raid Controller > Virtual drive > Select the virtual drive > Delete Virtual Drive
Cluster-Synchronisierung ausführen
Führen Sie die standardmäßige Cluster-Synchronisierung für den Cluster-Manager vom Initialisierungsserver aus.
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
Wenn die standardmäßige Cluster-Synchronisierung fehlschlägt, führen Sie für eine vollständige Neuinstallation eine Cluster-Synchronisierung mit der Option "force-vm redeploy" durch (die Clustersynchronisierungsaktivität kann ca. 45-55 Minuten in Anspruch nehmen, abhängig von der Anzahl der im Cluster gehosteten Knoten).
[inception-server] SMI Cluster Deployer# clusters POD-NAME-deployer actions sync run debug true force-vm-redeploy true
This will run sync. Are you sure? [no,yes] yes
message accepted
[inception-server] SMI Cluster Deployer#
Überwachen der Cluster-Synchronisierungs-Synchronisierungsprotokolle
[inception-server] SMI Cluster Deployer# monitor sync-logs POD-NAME-deployer
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Cluster name: POD-NAME
2023-02-23 10:15:07.548 DEBUG cluster_sync.POD-NAME: Force VM Redeploy: true
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: Force partition Redeploy: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: reset_k8s_nodes: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: purge_data_disks: false
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: upgrade_strategy: auto
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: sync_phase: all
2023-02-23 10:15:07.549 DEBUG cluster_sync.POD-NAME: debug: true
...
...
...
Der Server wird erneut bereitgestellt und durch erfolgreiche Cluster-Synchronisierung installiert.
PLAY RECAP *********************************************************************
cm-primary : ok=535 changed=250 unreachable=0 failed=0 skipped=832 rescued=0 ignored=0
cm-secondary : ok=299 changed=166 unreachable=0 failed=0 skipped=627 rescued=0 ignored=0
localhost : ok=59 changed=8 unreachable=0 failed=0 skipped=18 rescued=0 ignored=0
Thursday 23 February 2023 13:17:24 +0000 (0:00:00.109) 0:56:20.544 *****. ---> ~56 mins to complete cluster sync
===============================================================================
2023-02-23 13:17:24.539 DEBUG cluster_sync.POD-NAME: Cluster sync successful
2023-02-23 13:17:24.546 DEBUG cluster_sync.POD-NAME: Ansible sync done
2023-02-23 13:17:24.546 INFO cluster_sync.POD-NAME: _sync finished. Opening lock
Verifizierung
Überprüfen Sie, ob der betroffene Cluster-Manager erreichbar ist und ob der DRBD-Überblick über den primären und sekundären Cluster-Manager den Status "UpToDate" aufweist.
cloud-user@POD-NAME-cm-primary:~$ ping X.X.X.Y
PING X.X.X.Y (X.X.X.Y) 56(84) bytes of data.
64 bytes from X.X.X.Y: icmp_seq=1 ttl=64 time=0.221 ms
64 bytes from X.X.X.Y: icmp_seq=2 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=3 ttl=64 time=0.151 ms
64 bytes from X.X.X.Y: icmp_seq=4 ttl=64 time=0.154 ms
64 bytes from X.X.X.Y: icmp_seq=5 ttl=64 time=0.172 ms
64 bytes from X.X.X.Y: icmp_seq=6 ttl=64 time=0.165 ms
64 bytes from X.X.X.Y: icmp_seq=7 ttl=64 time=0.174 ms
--- X.X.X.Y ping statistics ---
7 packets transmitted, 7 received, 0% packet loss, time 6150ms
rtt min/avg/max/mdev = 0.151/0.171/0.221/0.026 ms
cloud-user@POD-NAME-cm-primary:~$ drbd-overview status
0:data/0 Connected Primary/Secondary UpToDate/UpToDate /mnt/stateful_partition ext4 568G 17G 523G 4%
Der betroffene Cluster-Manager wird erfolgreich installiert und im Netzwerk erneut bereitgestellt.
2.2 Überprüfen des Clusternamens von der SSH-IP-Adresse des Clustermanagers
[inception-server] SMI-Cluster-Bereitsteller# show running-config clusters * Knoten * k8s ssh-ip | Knoten auswählen * ssh-ip | Knoten auswählen * ucs-server cimc ip-adresse | Tabulator
SSH
NAME IP SSH IP-ADRESSE
------------------------------------------------------------------------------
POD-NAME cm-primär - 192.X.X.X 10.192.X.X
cm-sekundär - 192.X.X.Y 10.192.X.Y
*SSH-IP = Knoten-SSH-IP
* IP-ADRESSE = ucs-server cimc IP-Adresse
2.3 Überprüfen der Konfiguration für das Ziel-Cluster
[inception-server] SMI Cluster Deployer# show running-config clusters POD-NAME Melden Sie sich beim Inception-Server an, wechseln Sie zum Deployer, und überprüfen Sie den Clusternamen mit hosts-IP vom Cluster-Manager. Melden Sie sich beim Inception-Server an, wechseln Sie zum Deployer, und überprüfen Sie den Clusternamen mit hosts-IP vom Cluster-Manager.
 Feedback
Feedback