Einleitung
Dieses Dokument beschreibt das Verfahren zum Wiederherstellen der CRD-Tabelle (Custom Reference Data) der Cisco Policy Suite (CPS) aus dem BAD-Zustand.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in folgenden Bereichen verfügen:
Cisco empfiehlt, dass Sie über folgende Berechtigungen verfügen müssen:
- Root-Zugriff auf CPS CLI
- "qns-svn"-Benutzerzugriff auf CPS-GUIs (Policy Builder und CPS Central)
Verwendete Komponenten
Die Informationen in diesem Dokument basierend auf folgenden Software- und Hardware-Versionen:
- CPS 20,2
- MongoDB v3.6.17
- UCS B
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die potenziellen Auswirkungen eines Befehls verstehen.
Hintergrundinformationen
In CPS wird die CRD-Tabelle verwendet, um benutzerdefinierte Richtlinienkonfigurationsinformationen zu speichern, die von Policy Builder veröffentlicht werden und mit der CRD DB verknüpft sind, die in der auf sessionmgr gehosteten MongoDB-Instanz vorhanden ist. Export- und Importvorgänge werden in der CRD-Tabelle über die CPS Central-Benutzeroberfläche ausgeführt, um CRD-Tabellendaten zu bearbeiten.
Problem
Wenn beim Importieren aller Vorgänge ein Fehler auftritt, beendet CPS den Prozess, setzt das System in den BAD-Status und blockiert die Ausführung von CRD-APIs. CPS sendet eine Fehlerantwort an den Client, der angibt, dass das System im BAD-Zustand ist. Wenn sich das System im BAD-Zustand befindet und Sie den Quantum Network Suite (QNS)-/User Data Channel (UDC)-Server neu starten, wird der CRD-Cache mithilfe von Gold-Cart-Daten erstellt. Wenn der Systemfehler-Status FALSE ist, wird der CRD-Cache mit MongoDB erstellt.
Nachfolgend finden Sie die CPS Central-Fehlerbilder als Referenz.
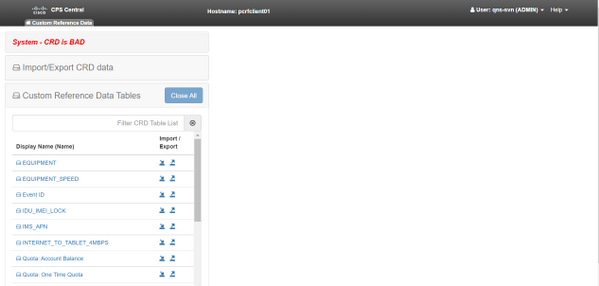
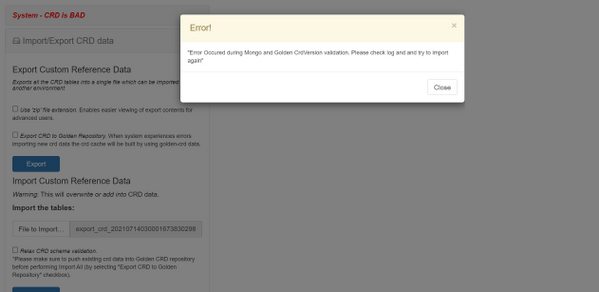
Wenn das CRD-System fehlerhaft ist, gehen Sie wie folgt vor:
- CRD-Manipulation wird blockiert. Sie können nur die Daten anzeigen.
- CRD-APIs, ausgenommen _import_all, _list, _query, werden blockiert.
- Beim QNS-Neustart werden CRD-Daten vom golden-crd-Standort übernommen.
- Bei einem Neustart des QNS/UDC wird der System-BAD-Zustand nicht behoben, und es werden nur CRD-Cache aus golden-crd erstellt.
- CRD-Cache mit Golden-Card-Daten erstellt. Wenn der System-BAD-Zustand FALSE ist, dann wird der CRD-Cache mit MongoDB erstellt.
Nachfolgend sind die zugeordneten Meldungen in CPS qns.log aufgeführt:
qns02 qns02 2021-07-29 11:16:50,820 [pool-50847-thread-1]
INFO c.b.c.i.e.ApplicationInterceptor - System -
CRD is in bad state. All CRD APIs (except import all, list and query),
are blocked and user is not allowed to use.
Please verify your crd schema/crd data and try again!
qns02 qns02 2021-07-28 11:33:59,788 [pool-50847-thread-1]
WARN c.b.c.i.CustomerReferenceDataManager -
System is in BAD state. Data will be fetched from svn golden-crd repository.
qns01 qns01 2021-07-28 11:55:24,256 [pool-50847-thread-1]
WARN c.b.c.i.e.ApplicationInterceptor - ApplicationInterceptor: Is system bad: true
Verfahren zum Wiederherstellen von CRD aus dem BAD-Zustand
Ansatz 1:
Um den Systemstatus zu löschen, müssen Sie ein gültiges und korrektes CRD-Schema aus Policy Builder importieren, das den Import gültiger CRD-Daten aus CPS Central beinhaltet. Wenn der Import alle erfolgreich ist, wird der Systemstatus gelöscht, und alle CRD-APIs und -Operationen werden deaktiviert.
Im Folgenden sind die einzelnen Schritte aufgeführt:
Schritt 1: Führen Sie diesen Befehl aus, um die CRD-Datenbank zu sichern.
Command template:
#mongodump --host <session_manager> --port <cust_ref_data_port>
--db cust_ref_data -o cust_ref_data_backup
Sample command:
#mongodump --host sessionmgr01 --port 27717 --db cust_ref_data -o cust_ref_data_backup
Anmerkung: Informationen zu CRD DB-Host und -Port finden Sie unter Benutzerdefinierte Referenzdatenkonfiguration in PB, wie in diesem Bild gezeigt.
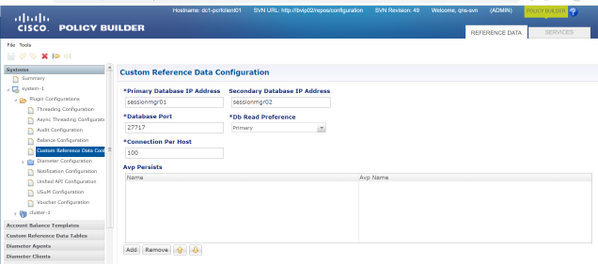
Schritt 2: Löschen Sie die CRD-Tabelle (die gesamte DB) mit diesem Verfahren.
Schritt 2.1: Melden Sie sich bei der Mongo-Instanz an, in der CRD DB vorhanden ist.
Command template:
#mongo --host <sessionmgrXX> --port <cust_ref_data_port>
Sample command:
#mongo --host sessionmgr01 --port 27717
Schritt 2.2: Führen Sie diesen Befehl aus, um alle DBs anzuzeigen, die in der Mongo-Instanz vorhanden sind.
set01:PRIMARY> show dbs
admin 0.031GB
config 0.031GB
cust_ref_data 0.125GB
local 5.029GB
session_cache 0.031GB
sk_cache 0.031GB
set01:PRIMARY>
Schritt 2.3: Führen Sie diesen Befehl aus, um zu CRD DB zu wechseln.
set01:PRIMARY> use cust_ref_data
switched to db cust_ref_data
set01:PRIMARY
Schritt 2.4: Führen Sie diesen Befehl aus, um CRD DB zu löschen.
set01:PRIMARY> db.dropDatabase()
{
"dropped" : "cust_ref_data",
"ok" : 1,
"operationTime" : Timestamp(1631074286, 13),
"$clusterTime" : {
"clusterTime" : Timestamp(1631074286, 13),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}}}
set01:PRIMARY>
Schritt 3: Vergewissern Sie sich, dass mit dem Befehl show dbs kein db mit dem Namen cust_ref_data vorhanden ist.
set01:PRIMARY> show dbs
admin 0.031GB
config 0.031GB
local 5.029GB
session_cache 0.031GB
sk_cache 0.031GB
set01:PRIMARY>
Schritt 4: Melden Sie sich beim Policy Builder mit dem Benutzer "qns-svn" an, und veröffentlichen Sie ein gültiges CRD-Schema.
Schritt 5: Starten Sie den qns-Prozess auf allen Knoten mit restartall.sh aus Cluster Manager neu.
Schritt 6: Überprüfen Sie, ob die Diagnose in Ordnung ist und keine Einträge in der CRD-Tabelle vorhanden sind. In den CRD-Tabellen darf nur ein Schema vorhanden sein, d. h. ohne Daten.
Schritt 7: Melden Sie sich bei CPS Central mit dem Benutzer "qns-svn" an, und importieren Sie gültige CRD-Daten.
Schritt 8: Überprüfen Sie, dass die Meldung "System - CRD is BAD" (System - CRD ist BAD) nicht in CPS Central angezeigt wird und alle zurückgegebenen Meldungen erfolgreich importiert wurden.
Schritt 9: Stellen Sie sicher, dass alle CRD-APIs jetzt nicht mehr blockiert sind. Sie können die CRD-Daten jetzt bearbeiten.
Wenn der erste Ansatz nicht funktioniert hat, gehen Sie zum zweiten Ansatz.
Ansatz 2:
Schritt 1: Identifizieren Sie den Host und den Port, in dem die ADMIN DB Mongo-Instanz mit dem Befehl diagnostics.sh —get_r gehostet wird.
[root@installer ~]# diagnostics.sh --get_r
CPS Diagnostics HA Multi-Node Environment
---------------------------
Checking replica sets...
|----------------------------------------------------------------------------------------------------------------------------------------|
| Mongo:v3.6.17 MONGODB REPLICA-SETS STATUS INFORMATION Date : 2021-09-14 02:56:23 |
|----------------------------------------------------------------------------------------------------------------------------------------|
| SET NAME - PORT : IP ADDRESS - REPLICA STATE - HOST NAME - HEALTH - LAST SYNC - PRIORITY |
|----------------------------------------------------------------------------------------------------------------------------------------|
| ADMIN:set06 |
| Status via arbitervip:27721 sessionmgr01:27721 sessionmgr02:27721 |
| Member-1 - 27721 : - PRIMARY - sessionmgr01 - ON-LINE - -------- - 3 |
| Member-2 - 27721 : - SECONDARY - sessionmgr02 - ON-LINE - 1 sec - 2 |
| Member-3 - 27721 : 192.168.10.146 - ARBITER - arbitervip - ON-LINE - -------- - 0 |
|----------------------------------------------------------------------------------------------------------------------------------------|
Schritt 2: Melden Sie sich bei der Mongo-Instanz an, in der ADMIN DB vorhanden ist.
Command template:
#mongo --host <sessionmgrXX> --port <Admin_DB__port>
Sample Command:
#mongo --host sessionmgr01 --port 27721
Schritt 3: Führen Sie diesen Befehl aus, um alle in der Mongo-Instanz vorhandenen DBs anzuzeigen.
set06:PRIMARY> show dbs
admin 0.078GB
config 0.078GB
diameter 0.078GB
keystore 0.078GB
local 4.076GB
policy_trace 2.078GB
queueing 0.078GB
scheduler 0.078GB
sharding 0.078GB
set06:PRIMARY>
Schritt 4: Führen Sie diesen Befehl aus, um auf die ADMIN DB zu wechseln.
set06:PRIMARY> use admin
switched to db admin
set06:PRIMARY>
Schritt 5: Führen Sie diesen Befehl aus, um alle Tabellen in der ADMIN-DB anzuzeigen.
set06:PRIMARY> show tables
state
system.indexes
system.keys
system.version
set06:PRIMARY>
Schritt 6: Führen Sie diesen Befehl aus, um den aktuellen Status des Systems zu überprüfen.
set06:PRIMARY> db.state.find()
{ "_id" : "state", "isSystemBad" : true, "lastUpdatedDate" : ISODate("2021-08-11T15:01:13.313Z") }
set06:PRIMARY>
Hier sehen Sie, dass "isSystemBad" : Richtig. Daher müssen Sie dieses Feld auf "false" aktualisieren, um den CRD-BAD-Zustand mit dem im nächsten Schritt bereitgestellten Befehl zu löschen.
Schritt 7: Aktualisieren Sie das Feld "isSystemBAD" mit dem Befehl db.state.updateOne({_id:"state"},{$set:{isSystemBad:false}}).
set06:PRIMARY> db.state.updateOne({_id:"state"},{$set:{isSystemBad:false}})
{ "acknowledged" : true, "matchedCount" : 0, "modifiedCount" : 0 }
set06:PRIMARY>
Schritt 8: Führen Sie den Befehl db.state.find() aus, um zu überprüfen, ob derSystemBad-Feldwert in false geändert wurde.
set06:PRIMARY> db.state.find()
{ "_id" : "state", "isSystemBad" : false, "lastUpdatedDate" : ISODate("2021-08-11T15:01:13.313Z") }
set06:PRIMARY>
Schritt 9: Stellen Sie sicher, dass alle CRD-APIs jetzt deaktiviert sind. Sie können die CRD-Daten jetzt bearbeiten.
 Feedback
Feedback