PCRF-Ersatz für OSD-Compute UCS 240M4
Download-Optionen
-
ePub (741.3 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einführung
Dieses Dokument beschreibt die erforderlichen Schritte zum Ersetzen eines fehlerhaften Sd-Computing-Servers in einer Ultra-M-Konfiguration, der Cisco Policy Suite (CPS) Virtual Network Functions (VNFs) hostet.
Hintergrundinformationen
Dieses Dokument richtet sich an Mitarbeiter von Cisco, die mit der Cisco Ultra-M-Plattform vertraut sind. Es enthält eine Beschreibung der Schritte, die auf der Ebene von OpenStack und CPS VNF zum Zeitpunkt des Ersatzes des OSD-Compute-Servers erforderlich sind.
Hinweis: Ultra M 5.1.x wird zur Definition der Verfahren in diesem Dokument berücksichtigt.
Gesundheitskontrolle
Bevor Sie einen Osd-Compute-Knoten austauschen, ist es wichtig, den aktuellen Zustand Ihrer Red Hat OpenStack Platform-Umgebung zu überprüfen. Es wird empfohlen, den aktuellen Zustand zu überprüfen, um Komplikationen zu vermeiden, wenn der Computing-Ersetzungsprozess eingeschaltet ist.
Von OSPD
[root@director ~]$ su - stack
[stack@director ~]$ cd ansible
[stack@director ansible]$ ansible-playbook -i inventory-new openstack_verify.yml -e platform=pcrf
Schritt 1: Überprüfen Sie den Zustand des Systems anhand des in 15 Minuten erstellten Berichts über die ultraviolette Gesundheit.
[stack@director ~]# cd /var/log/cisco/ultram-health
Überprüfen Sie die Datei ultram_health_os.report.
Die einzigen Dienste sollten als XXX Status angezeigt werden sind Neutron-sriov-nic-agent.service.
Schritt 2: Prüfen Sie, ob rabbitmq für alle Controller ausgeführt wird, die wiederum von OSPD ausgehen.
[stack@director ~]# for i in $(nova list| grep controller | awk '{print $12}'| sed 's/ctlplane=//g') ; do (ssh -o StrictHostKeyChecking=no heat-admin@$i "hostname;sudo rabbitmqctl eval 'rabbit_diagnostics:maybe_stuck().'" ) & done
Schritt 3: Stellen Sie sicher, dass Stonith aktiviert ist.
[stack@director ~]# sudo pcs property show stonith-enabled
Für alle Controller überprüfen den PCS-Status
- Alle Controller-Knoten werden unter dem Proxy-Klon gestartet.
- Alle Controller-Knoten sind Master unter galera
- Alle Controller-Knoten werden unter Rabbitmq gestartet.
- 1 Controller-Knoten ist Master und 2 Slaves unter Redundanzen
Von OSPD
[stack@director ~]$ for i in $(nova list| grep controller | awk '{print $12}'| sed 's/ctlplane=//g') ; do (ssh -o StrictHostKeyChecking=no heat-admin@$i "hostname;sudo pcs status" ) ;done
Schritt 4: Überprüfen Sie, ob alle OpenStack-Dienste aktiv sind. Führen Sie von OSPD den folgenden Befehl aus:
[stack@director ~]# sudo systemctl list-units "openstack*" "neutron*" "openvswitch*"
Schritt 5: Überprüfen Sie, ob der CEPH-Status für Controller HEALTH_OK lautet.
[stack@director ~]# for i in $(nova list| grep controller | awk '{print $12}'| sed 's/ctlplane=//g') ; do (ssh -o StrictHostKeyChecking=no heat-admin@$i "hostname;sudo ceph -s" ) ;done
Schritt 6: Überprüfen Sie die Protokolle der OpenStack-Komponente. Suchen Sie nach einem Fehler:
Neutron:
[stack@director ~]# sudo tail -n 20 /var/log/neutron/{dhcp-agent,l3-agent,metadata-agent,openvswitch-agent,server}.log
Cinder:
[stack@director ~]# sudo tail -n 20 /var/log/cinder/{api,scheduler,volume}.log
Glance:
[stack@director ~]# sudo tail -n 20 /var/log/glance/{api,registry}.log
Schritt 7: Führen Sie vom OSPD diese Überprüfungen für API durch.
[stack@director ~]$ source
[stack@director ~]$ nova list
[stack@director ~]$ glance image-list
[stack@director ~]$ cinder list
[stack@director ~]$ neutron net-list
Schritt 8: Überprüfen Sie den Zustand der Services.
Every service status should be “up”:
[stack@director ~]$ nova service-list
Every service status should be “ :-)”:
[stack@director ~]$ neutron agent-list
Every service status should be “up”:
[stack@director ~]$ cinder service-list
Sicherung
Im Falle einer Wiederherstellung empfiehlt Cisco, eine Sicherung der OSPD-Datenbank mit diesen Schritten durchzuführen.
Schritt 1: Nehmen Sie Mysql dump.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Dieser Prozess stellt sicher, dass ein Knoten ausgetauscht werden kann, ohne dass die Verfügbarkeit von Instanzen beeinträchtigt wird.
Schritt 2: So sichern Sie CPS VMs von Cluster Manager VM:
[root@CM ~]# config_br.py -a export --all /mnt/backup/CPS_backup_$(date +\%Y-\%m-\%d).tar.gz
or
[root@CM ~]# config_br.py -a export --mongo-all --svn --etc --grafanadb --auth-htpasswd --haproxy /mnt/backup/$(hostname)_backup_all_$(date +\%Y-\%m-\%d).tar.gz
Identifizieren der im OSD-Compute-Knoten gehosteten VMs
Identifizieren Sie die VMs, die auf dem Computing-Server gehostet werden:
Schritt 1: Der Computing-Server enthält den Elastic Services Controller (ESC).
[stack@director ~]$ nova list --field name,host,networks | grep osd-compute-1
| 50fd1094-9c0a-4269-b27b-cab74708e40c | esc | pod1-osd-compute-0.localdomain
| tb1-orch=172.16.180.6; tb1-mgmt=172.16.181.3
Hinweis: In der hier gezeigten Ausgabe entspricht die erste Spalte dem Universally Unique Identifier (UUID), die zweite Spalte dem VM-Namen und die dritte Spalte dem Hostnamen, in dem das virtuelle System vorhanden ist. Die Parameter aus dieser Ausgabe werden in den nachfolgenden Abschnitten verwendet.
Hinweis: Wenn der zu ersetzende OSD-Computing-Knoten vollständig ausgefallen ist und nicht darauf zugegriffen werden kann, fahren Sie mit dem Abschnitt "Entfernen Sie den Osd-Compute-Knoten aus der Nova Aggregate List" fort. Fahren Sie andernfalls mit dem nächsten Abschnitt fort.
Schritt 2: Vergewissern Sie sich, dass CEPH über die verfügbare Kapazität verfügt, um das Entfernen eines einzigen OSD-Servers zu ermöglichen.
[root@pod1-osd-compute-0 ~]# sudo ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
13393G 11804G 1589G 11.87
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 3876G 0
metrics 1 4157M 0.10 3876G 215385
images 2 6731M 0.17 3876G 897
backups 3 0 0 3876G 0
volumes 4 399G 9.34 3876G 102373
vms 5 122G 3.06 3876G 31863
Schritt 3: Stellen Sie sicher, dass der Status ceph osd tree auf dem osd-Computing-Server aktiv ist.
[heat-admin@pod1-osd-compute-0 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
Schritt 4: CEPH-Prozesse sind auf dem osd-Computing-Server aktiv.
[root@pod1-osd-compute-0 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
Schritt 5: Deaktivieren und beenden Sie jede ceph-Instanz, entfernen Sie jede Instanz aus SOD, und heben Sie die Bereitstellung des Verzeichnisses auf. Wiederholen Sie diese Schritte für jede ceph-Instanz.
[root@pod1-osd-compute-0 ~]# systemctl disable ceph-osd@11
[root@pod1-osd-compute-0 ~]# systemctl stop ceph-osd@11
[root@pod1-osd-compute-0 ~]# ceph osd out 11
marked out osd.11.
[root@pod1-osd-compute-0 ~]# ceph osd crush remove osd.11
removed item id 11 name 'osd.11' from crush map
[root@pod1-osd-compute-0 ~]# ceph auth del osd.11
updated
[root@pod1-osd-compute-0 ~]# ceph osd rm 11
removed osd.11
[root@pod1-osd-compute-0 ~]# umount /var/lib/ceph/osd/ceph-11
[root@pod1-osd-compute-0 ~]# rm -rf /var/lib/ceph/osd/ceph-11
oder
Schritt 6: Clean.sh-Skript kann für die oben genannte Aufgabe gleichzeitig verwendet werden.
[heat-admin@pod1-osd-compute-0 ~]$ sudo ls /var/lib/ceph/osd
ceph-11 ceph-3 ceph-6 ceph-8
[heat-admin@pod1-osd-compute-0 ~]$ /bin/sh clean.sh
[heat-admin@pod1-osd-compute-0 ~]$ cat clean.sh
#!/bin/sh
set -x
CEPH=`sudo ls /var/lib/ceph/osd`
for c in $CEPH
do
i=`echo $c |cut -d'-' -f2`
sudo systemctl disable ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo systemctl stop ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd out $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd crush remove osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph auth del osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd rm $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo umount /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
sudo rm -rf /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
done
sudo ceph osd tree
Nachdem alle OSD-Prozesse migriert/gelöscht wurden, kann der Knoten aus der Overcloud entfernt werden.
Hinweis: Wenn CEPH entfernt wird, wechselt VNF HD RAID in den Zustand "Degraded" (Heruntergestuft), aber die Festplatte muss weiterhin zugänglich sein.
Graceful Power Aus
Migration von ESC in den Standby-Modus
Schritt 1: Melden Sie sich beim im Computing-Knoten gehosteten ESC an, und prüfen Sie, ob er sich im Master-Status befindet. Wenn ja, schalten Sie den ESC in den Standby-Modus um.
[admin@esc esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@esc ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@esc ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@esc ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
Schritt 2: Entfernen Sie den Osd-Computing-Knoten aus der Nova Aggregate List.
- Listen Sie die nova-Aggregate auf, und identifizieren Sie die Aggregate, die dem von ihm gehosteten VNF-Server entsprechen. In der Regel sind dies die Formate <VNFNAME>-EM-MGMT<X> und <VNFNAME>-CF-MGMT<X>.
[stack@director ~]$ nova aggregate-list
+----+------+-------------------+
| Id | Name | Availability Zone |
+----+------+-------------------+
| 3 | esc1 | AZ-esc1 |
| 6 | esc2 | AZ-esc2 |
| 9 | aaa | AZ-aaa |
+----+------+-------------------+
In unserem Fall gehört der osd-Computing-Server zu esc1. Die Aggregate, die entsprechen, sind esc1.
Schritt 3: Entfernen Sie den osd-Computing-Knoten aus der identifizierten Aggregatzuordnung.
nova aggregate-remove-host
[stack@director ~]$ nova aggregate-remove-host esc1 pod1-osd-compute-0.localdomain
Schritt 4: Überprüfen Sie, ob der Knoten für die Datenverarbeitung aus den Aggregaten entfernt wurde. Stellen Sie nun sicher, dass der Host nicht unter den Aggregaten aufgeführt ist.
nova aggregate-show
[stack@director ~]$ nova aggregate-show esc1
[stack@director ~]$
Löschung von Osd-Computing-Knoten
Die in diesem Abschnitt beschriebenen Schritte sind unabhängig von den im Computing-Knoten gehosteten VMs häufig.
Löschen aus der Overcloud
Schritt 1: Erstellen Sie eine Skriptdatei mit dem Namen delete_node.sh, deren Inhalt wie gezeigt angezeigt wird. Stellen Sie sicher, dass die erwähnten Vorlagen mit den Vorlagen übereinstimmen, die im deploy.sh-Skript für die Stackbereitstellung verwendet wurden.
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack
[stack@director ~]$ source stackrc
[stack@director ~]$ /bin/sh delete_node.sh
+ openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod1 49ac5f22-469e-4b84-badc-031083db0533
Deleting the following nodes from stack pod1:
- 49ac5f22-469e-4b84-badc-031083db0533
Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae
real 0m52.078s
user 0m0.383s
sys 0m0.086s
Schritt 2: Warten Sie, bis der OpenStack-Stapelvorgang in den VOLLSTÄNDIGEN Zustand wechselt.
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------
Osd-Computing-Knoten aus der Dienstliste löschen
Löschen Sie den Computing-Service aus der Liste der Dienste.
[stack@director ~]$ source corerc
[stack@director ~]$ openstack compute service list | grep osd-compute-0
| 404 | nova-compute | pod1-osd-compute-0.localdomain | nova | enabled | up | 2018-05-08T18:40:56.000000 |
openstack compute service delete
[stack@director ~]$ openstack compute service delete 404
Neutrale Agenten löschen
Löschen Sie den alten zugeordneten Neutron-Agent und den offenen Switch-Agent für den Computing-Server.
[stack@director ~]$ openstack network agent list | grep osd-compute-0
| c3ee92ba-aa23-480c-ac81-d3d8d01dcc03 | Open vSwitch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-openvswitch-agent |
| ec19cb01-abbb-4773-8397-8739d9b0a349 | NIC Switch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-sriov-nic-agent |
openstack network agent delete
[stack@director ~]$ openstack network agent delete c3ee92ba-aa23-480c-ac81-d3d8d01dcc03
[stack@director ~]$ openstack network agent delete ec19cb01-abbb-4773-8397-8739d9b0a349
Löschen aus der Nova- und Ironic-Datenbank
Löschen Sie einen Knoten aus der Nova-Liste zusammen mit der ironischen Datenbank, und überprüfen Sie ihn anschließend.
[stack@director ~]$ source stackrc
[stack@al01-pod1-ospd ~]$ nova list | grep osd-compute-0
| c2cfa4d6-9c88-4ba0-9970-857d1a18d02c | pod1-osd-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.114 |
[stack@al01-pod1-ospd ~]$ nova delete c2cfa4d6-9c88-4ba0-9970-857d1a18d02c
nova show| grep hypervisor
[stack@director ~]$ nova show pod1-osd-compute-0 | grep hypervisor
| OS-EXT-SRV-ATTR:hypervisor_hostname | 4ab21917-32fa-43a6-9260-02538b5c7a5a
ironic node-delete
[stack@director ~]$ ironic node-delete 4ab21917-32fa-43a6-9260-02538b5c7a5a
[stack@director ~]$ ironic node-list (node delete must not be listed now)
Installation des neuen Computing-Knotens
Die Schritte zur Installation eines neuen UCS C240 M4 Servers sowie die Schritte zur Ersteinrichtung finden Sie im Cisco UCS C240 M4 Server Installations- und Serviceleitfaden.
Schritt 1: Nach der Installation des Servers legen Sie die Festplatten in die entsprechenden Steckplätze als alten Server ein.
Schritt 2: Melden Sie sich mithilfe der CIMC IP beim Server an.
Schritt 3: Führen Sie ein BIOS-Upgrade durch, wenn die Firmware nicht der zuvor verwendeten empfohlenen Version entspricht. Schritte für BIOS-Upgrades finden Sie hier: BIOS-Upgrade-Leitfaden für Cisco UCS Rackmount-Server der C-Serie
Schritt 4: Überprüfen Sie den Status der physischen Laufwerke. Es muss unbeschränkt gut sein.
Schritt 5: Erstellen Sie eine virtuelle Festplatte von den physischen Laufwerken mit RAID Level 1.
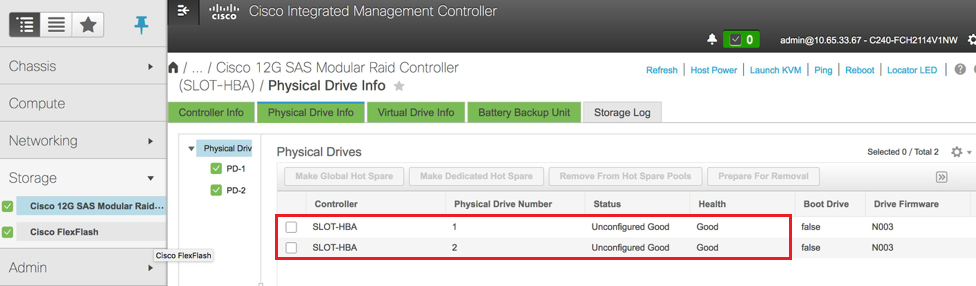
Schritt 6: Navigieren Sie zum Speicherbereich, wählen Sie den Cisco 12G SAS Modular RAID Controller aus, und überprüfen Sie den Status und die Integrität des RAID-Controllers, wie im Bild gezeigt.
Hinweis: Das obige Bild dient lediglich zur Veranschaulichung. Im OSD-Compute-CIMC werden sieben physische Laufwerke in Steckplätzen [1,2,3,7,8,9,10] im nicht konfigurierten "Good"-Zustand angezeigt, da aus ihnen keine virtuellen Laufwerke erstellt werden.
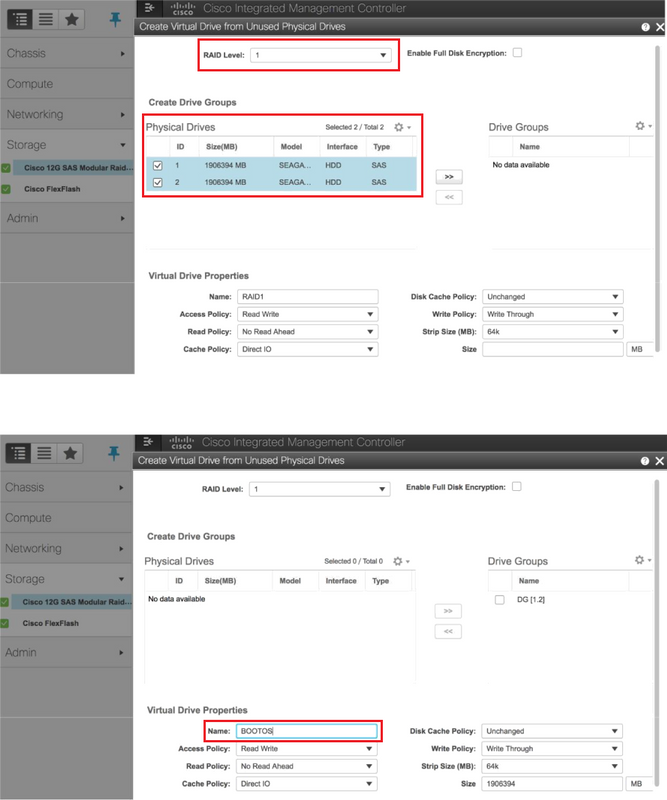
Schritt 7: Erstellen Sie jetzt unter dem Cisco 12G SAS Modular RAID Controller eine virtuelle Festplatte aus einer nicht verwendeten physischen Festplatte über die Controller-Informationen.

Schritt 8: Wählen Sie die VD aus, und konfigurieren Sie sie als Boot-Laufwerk.
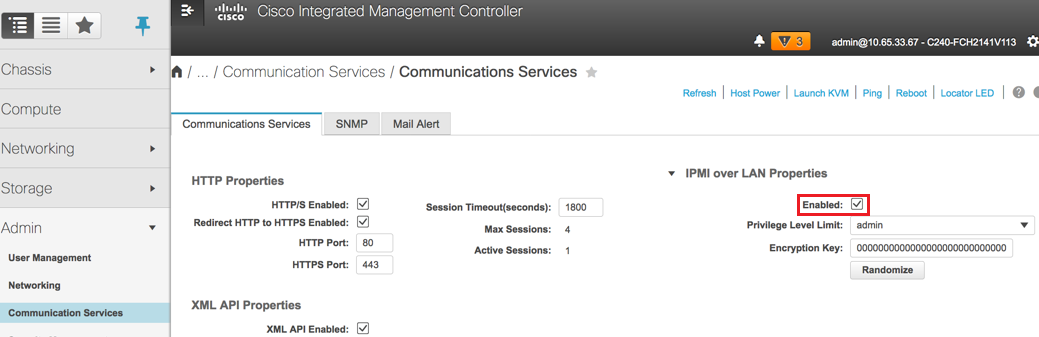
Schritt 9: Aktivieren Sie IPMI over LAN von Kommunikationsdiensten auf der Registerkarte "Admin".
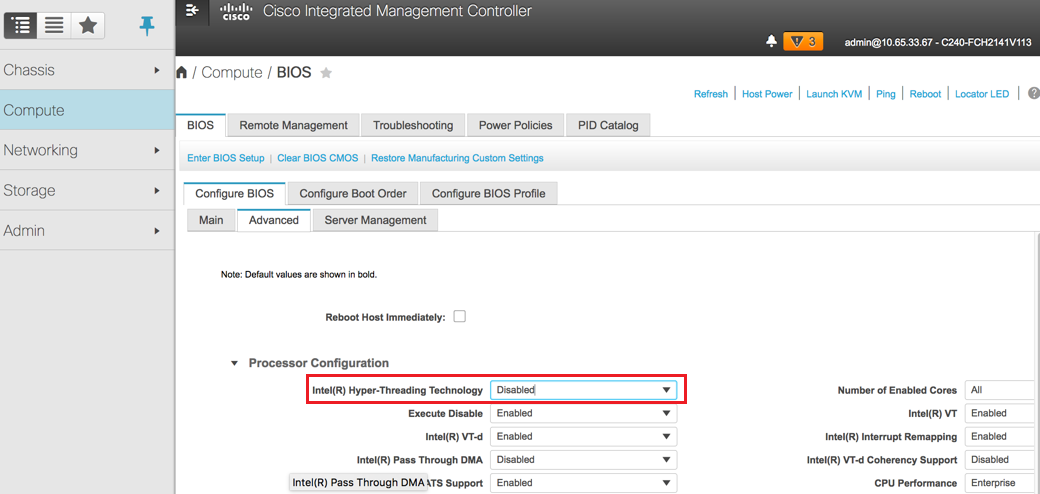
Schritt 10: Deaktivieren Sie Hyper-Threading in der erweiterten BIOS-Konfiguration unter dem Knoten Computing, wie im Bild gezeigt.
Schritt 11: Erstellen Sie ähnlich wie BOOTOS VD mit den physischen Laufwerken 1 und 2 vier weitere virtuelle Laufwerke wie
JOURNAL - Von physischer Laufwerksnummer 3
OSD1 - Von physischer Laufwerksnummer 7
OSD2 - Von der Nummer 8 des physischen Laufwerks
OSD3 - Von physischer Laufwerksnummer 9
OSD4 - Von physischer Laufwerksnummer 10
Schritt 7: Am Ende müssen die physischen und virtuellen Laufwerke ähnlich sein.
Hinweis: Das hier abgebildete Image und die in diesem Abschnitt beschriebenen Konfigurationsschritte beziehen sich auf die Firmware-Version 3.0(3e). Wenn Sie an anderen Versionen arbeiten, kann es zu geringfügigen Abweichungen kommen.
Hinzufügen des neuen OSD-Compute-Knotens zur Overcloud
Die in diesem Abschnitt beschriebenen Schritte sind unabhängig von der vom Computing-Knoten gehosteten VM identisch.
Schritt 1: Hinzufügen eines Compute-Servers mit einem anderen Index
Erstellen Sie eine Datei add_node.json, die nur die Details des neuen Computing-Servers enthält, der hinzugefügt werden soll. Stellen Sie sicher, dass die Indexnummer für den neuen osd-Computing-Server noch nicht verwendet wurde. Erhöhen Sie in der Regel den nächsthöchsten Rechenwert.
Beispiel: Höchste Vorgeschichte wurde sod-compute-0 so erstellt osd-compute-3 im Falle des 2-vnf-Systems.
Hinweis: Achten Sie auf das Json-Format.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:osd-compute-3,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
Schritt 2: Importieren Sie die Json-Datei.
[stack@director ~]$ openstack baremetal import --json add_node.json
Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d
Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e
Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e
Successfully set all nodes to available.
Schritt 3: Führen Sie eine Knotenintrospektion mithilfe der UUID aus, die im vorherigen Schritt angegeben wurde.
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e
[stack@director ~]$ ironic node-list |grep 7eddfa87
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False |
[stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide
Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9
Successfully set all nodes to available.
[stack@director ~]$ ironic node-list |grep available
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
Schritt 4: Fügen Sie unter OsdComputeIPs IP-Adressen zu custom-templates/layout.yml hinzu. Wenn Sie in diesem Fall osd-compute-0 ersetzen, fügen Sie diese Adresse zum Ende der Liste für jeden Typ hinzu.
OsdComputeIPs:
internal_api:
- 11.120.0.43
- 11.120.0.44
- 11.120.0.45
- 11.120.0.43 <<< take osd-compute-0 .43 and add here
tenant:
- 11.117.0.43
- 11.117.0.44
- 11.117.0.45
- 11.117.0.43 << and here
storage:
- 11.118.0.43
- 11.118.0.44
- 11.118.0.45
- 11.118.0.43 << and here
storage_mgmt:
- 11.119.0.43
- 11.119.0.44
- 11.119.0.45
- 11.119.0.43 << and here
Schritt 5: Führen Sie deploy.sh-Skript aus, das zuvor für die Bereitstellung des Stacks verwendet wurde, um den neuen Computing-Knoten dem Overcloud-Stack hinzuzufügen.
[stack@director ~]$ ./deploy.sh
++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180
…
Starting new HTTP connection (1): 192.200.0.1
"POST /v2/action_executions HTTP/1.1" 201 1695
HTTP POST http://192.200.0.1:8989/v2/action_executions 201
Overcloud Endpoint: http://10.1.2.5:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 38m38.971s
user 0m3.605s
sys 0m0.466s
Schritt 6: Warten Sie, bis der Status des OpenStack abgeschlossen ist.
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
Schritt 7: Überprüfen Sie, ob sich der neue Knoten für die Datenverarbeitung im aktiven Zustand befindet.
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list |grep osd-compute-3
| 0f2d88cd-d2b9-4f28-b2ca-13e305ad49ea | pod1-osd-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.117 |
[stack@director ~]$ source corerc
[stack@director ~]$ openstack hypervisor list |grep osd-compute-3
| 63 | pod1-osd-compute-3.localdomain |
Schritt 8: Melden Sie sich beim neuen osd-Computing-Server an, und überprüfen Sie die ceph-Prozesse. Zunächst befindet sich der Status in HEALTH_WARN, wenn sich ceph erholt.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
223 pgs backfill_wait
4 pgs backfilling
41 pgs degraded
227 pgs stuck unclean
41 pgs undersized
recovery 45229/1300136 objects degraded (3.479%)
recovery 525016/1300136 objects misplaced (40.382%)
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e986: 12 osds: 12 up, 12 in; 225 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v781746: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1553 GB used, 11840 GB / 13393 GB avail
45229/1300136 objects degraded (3.479%)
525016/1300136 objects misplaced (40.382%)
477 active+clean
186 active+remapped+wait_backfill
37 active+undersized+degraded+remapped+wait_backfill
4 active+undersized+degraded+remapped+backfilling
Schritt 9: Nach einem kurzen Zeitraum (20 Minuten) kehrt CEPH jedoch in den Zustand HEALTH_OK zurück.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v784311: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1599 GB used, 11793 GB / 13393 GB avail
704 active+clean
client io 8168 kB/s wr, 0 op/s rd, 32 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 0 host pod1-osd-compute-0
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
Stellen Sie die VMs wieder her
Hinzufügen zur Nova Aggregate-Liste
Fügen Sie den Knoten osd-compute zu den Aggregat-Hosts hinzu, und überprüfen Sie, ob der Host hinzugefügt wird.
nova aggregate-add-host
[stack@director ~]$ nova aggregate-add-host esc1 pod1-osd-compute-3.localdomain
nova aggregate-show
[stack@director ~]$ nova aggregate-show esc1
+----+------+-------------------+----------------------------------------+------------------------------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+------+-------------------+----------------------------------------+------------------------------------------+
| 3 | esc1 | AZ-esc1 | 'pod1-osd-compute-3.localdomain' | 'availability_zone=AZ-esc1', 'esc1=true' |
+----+------+-------------------+----------------------------------------+------------------------------------------+
Wiederherstellung des ESC VM
Schritt 1: Überprüfen Sie den Status des ESC VM in der Nova-Liste, und löschen Sie ihn.
stack@director scripts]$ nova list |grep esc
| c566efbf-1274-4588-a2d8-0682e17b0d41 | esc | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.14; VNF2-UAS-uas-management=172.168.10.4 |
[stack@director scripts]$ nova delete esc
Request to delete server esc has been accepted.
If can not delete esc then use command: nova force-delete esc
Schritt 2: Navigieren Sie in OSPD zum Verzeichnis ECS-Image, und stellen Sie sicher, dass die Dateien bootvm.py und qcow2 für ESC vorhanden sind, wenn nicht in ein Verzeichnis verschoben werden.
[stack@atospd ESC-Image-157]$ ll total 30720136 -rw-r--r--. 1 root root 127724 Jan 23 12:51 bootvm-2_3_2_157a.py -rw-r--r--. 1 root root 55 Jan 23 13:00 bootvm-2_3_2_157a.py.md5sum -rw-rw-r--. 1 stack stack 31457280000 Jan 24 11:35 esc-2.3.2.157.qcow2
Schritt 3: Erstellen Sie das Bild.
[stack@director ESC-image-157]$ glance image-create --name ESC-2_3_2_157 --disk-format "qcow2" --container "bare" --file /home/stack/ECS-Image-157/ESC-2_3_2_157.qcow2
Schritt 4: Überprüfen Sie, ob das ESC-Bild vorhanden ist.
stack@director ~]$ glance image-list +--------------------------------------+--------------------------------------+ | ID | Name | +--------------------------------------+--------------------------------------+ | 8f50acbe-b391-4433-aa21-98ac36011533 | ESC-2_3_2_157| | 2f67f8e0-5473-467c-832b-e07760e8d1fa | tmobile-pcrf-13.1.1.iso | | c5485c30-45db-43df-831d-61046c5cfd01 | tmobile-pcrf-13.1.1.qcow2 | | 2f84b9ec-61fa-46a3-a4e6-45f14c93d9a9 | tmobile-pcrf-13.1.1_cco_20170825.iso | | 25113ecf-8e63-4b81-a73f-63606781ef94 | wscaaa01-sept072017 | | 595673e8-c99c-40c2-82b1-7338325024a9 | wscaaa02-sept072017 | | 8bce3a60-b3b0-4386-9e9d-d99590dc9033 | wscaaa03-sept072017 | | e5c835ad-654b-45b0-8d36-557e6c5fd6e9 | wscaaa04-sept072017 | | 879dfcde-d25c-4314-8da0-32e4e73ffc9f | WSP1_cluman_12_07_2017 | | 7747dd59-c479-4c8a-9136-c90ec894569a | WSP2_cluman_12_07_2017 | +--------------------------------------+--------------------------------------+
[stack@ ~]$ openstack flavor list +--------------------------------------+------------+--------+------+-----------+-------+-----------+ | ID | Name | RAM | Disk | Ephemeral | VCPUs | Is Public | +--------------------------------------+------------+--------+------+-----------+-------+-----------+ | 1e4596d5-46f0-46ba-9534-cfdea788f734 | pcrf-smb | 100352 | 100 | 0 | 8 | True | | 251225f3-64c9-4b19-a2fc-032a72bfe969 | pcrf-oam | 65536 | 100 | 0 | 10 | True | | 4215d4c3-5b2a-419e-b69e-7941e2abe3bc | pcrf-pd | 16384 | 100 | 0 | 12 | True | | 4c64a80a-4d19-4d52-b818-e904a13156ca | pcrf-qns | 14336 | 100 | 0 | 10 | True | | 8b4cbba7-40fd-49b9-ab21-93818c80a2e6 | esc-flavor | 4096 | 0 | 0 | 4 | True | | 9c290b80-f80a-4850-b72f-d2d70d3d38ea | pcrf-sm | 100352 | 100 | 0 | 10 | True | | e993fc2c-f3b2-4f4f-9cd9-3afc058b7ed1 | pcrf-arb | 16384 | 100 | 0 | 4 | True | | f2b3b925-1bf8-4022-9f17-433d6d2c47b5 | pcrf-cm | 14336 | 100 | 0 | 6 | True | +--------------------------------------+------------+--------+------+-----------+-------+-----------+
Schritt 5: Erstellen Sie diese Datei im Bildverzeichnis, und starten Sie die ESC-Instanz.
[root@director ESC-IMAGE]# cat esc_params.conf openstack.endpoint = publicURL [root@director ESC-IMAGE]./bootvm-2_3_2_157a.py esc --flavor esc-flavor --image ESC-2_3_2_157 --net tb1-mgmt --gateway_ip 172.16.181.1 --net tb1-orch --enable-http-rest --avail_zone AZ-esc1 --user_pass "admin:Cisco123" --user_confd_pass "admin:Cisco123" --bs_os_auth_url http://10.250.246.137:5000/v2.0 --kad_vif eth0 --kad_vip 172.16.181.5 --ipaddr 172.16.181.4 dhcp --ha_node_list 172.16.181.3 172.16.181.4 --esc_params_file esc_params.conf
Hinweis: Nachdem die problematische ESC VM mit dem gleichen bootvm.py-Befehl wie bei der Erstinstallation neu bereitgestellt wurde, führt ESC HA automatisch eine Synchronisierung ohne manuelle Schritte durch. Stellen Sie sicher, dass ESC Master aktiviert ist und ausgeführt wird.
Schritt 6: Melden Sie sich beim neuen ESC an, und überprüfen Sie den Backup-Zustand.
[admin@esc ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@VNF2-esc-esc-1 ~]$ health.sh
============== ESC HA (BACKUP) ===================================================
ESC HEALTH PASSED
Beiträge von Cisco Ingenieuren
- Vaibhav BandekarCisco Advanced Services
- Aaditya DeodharCisco Advanced Services
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)