Überwachung und Fehlerbehebung bei der hohen CPU von Cisco Unified Communications Manager 6.0 mit Real Time Monitoring Tool (RTMT)
Inhalt
Einführung
Dieses Dokument enthält Schritte zur Unterstützung bei der Überwachung und Fehlerbehebung von Problemen im Zusammenhang mit der hohen Prozessorauslastung auf Cisco Unified Communications Manager 6.0 mit RTMT.
Voraussetzungen
Anforderungen
Cisco empfiehlt, über Kenntnisse in diesem Bereich zu verfügen:
-
Cisco Unified Communications Manager
Verwendete Komponenten
Die Informationen in diesem Dokument basieren auf den folgenden Tagesordnungspunkten:
-
Identifizierung des Prozesses, der die meisten CPUs verwendet
-
Identifizierung des Prozesses, der für die Festplatten-E/A verantwortlich ist
-
Code Gelb, aber CPU-Auslastung gesamt beträgt nur 25 % - warum?
Die Informationen in diesem Dokument basieren auf Cisco Unified Communications Manager 6.0.
Die Informationen in diesem Dokument wurden von den Geräten in einer bestimmten Laborumgebung erstellt. Alle in diesem Dokument verwendeten Geräte haben mit einer leeren (Standard-)Konfiguration begonnen. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die potenziellen Auswirkungen eines Befehls verstehen.
Konventionen
Weitere Informationen zu Dokumentkonventionen finden Sie unter Cisco Technical Tips Conventions (Technische Tipps zu Konventionen von Cisco).
Systemzeit, Benutzerzeit, IOWait, Soft IRQ und IRQ
Die Verwendung von RTMT zur Isolierung potenzieller CPU-Probleme kann ein sehr nützlicher Schritt zur Fehlerbehebung sein.
Diese Begriffe stellen die Verwendung von Seitenberichten zur RTMT-CPU und zum Arbeitsspeicher dar:
-
%System: der Prozentsatz der CPU-Auslastung, der bei der Ausführung auf Systemebene (Kernel) aufgetreten ist
-
%Benutzer: der Prozentsatz der CPU-Auslastung, der bei der Ausführung auf Benutzerebene (Anwendung) aufgetreten ist
-
%IOWait: Der Prozentsatz der Zeit, in der die CPU inaktiv war, während sie auf eine ausstehende Festplatten-E/A-Anforderung wartete.
-
%SoftIRQ: Der Prozentsatz der Zeit, in der der Prozessor die verzögerte IRQ-Verarbeitung ausführt (z. B. Verarbeitung von Netzwerkpaketen).
-
%IRQ der Prozentsatz der Zeit, in der der Prozessor die Interrupt-Anfrage ausführt, die Geräten zur Unterbrechung zugewiesen wird, oder ein Signal an den Computer sendet, wenn die Verarbeitung abgeschlossen ist
CPU-Pegging-Warnungen
CPUPegging/CallProcessNodeCPUPegging-Warnungen überwachen die CPU-Auslastung anhand konfigurierter Schwellenwerte:
Hinweis: %CPU wird berechnet als %system + %user + %nice + %iowait + %softirq + %irq
Folgende Warnmeldungen sind verfügbar:
-
%system, %user, %nice, %iowait, %softirq und %irq
-
Der Prozess, der die meisten CPUs verwendet
-
Die Prozesse, die auf unterbrechungsfreien Festplattenschlaf warten
CPU-Pegging-Warnungen können in RTMT auftauchen, da die CPU-Auslastung höher ist als der Wasserzeichen-Level. Da CDR beim Laden eine CPU-intensive Anwendung ist, prüfen Sie, ob die Warnmeldungen in demselben Zeitraum empfangen werden, in dem der CDR für die Ausführung von Berichten konfiguriert ist. In diesem Fall müssen Sie die Schwellenwerte für RTMT erhöhen. Weitere Informationen zu RTMT-Warnungen finden Sie unter Warnungen.
Identifizierung des Prozesses, der die meisten CPUs verwendet
Wenn %system und/oder %user hoch genug ist, um eine CPU-Pegging-Warnung zu generieren, überprüfen Sie in der Warnmeldung, welche Prozesse die meiste CPU verwenden.
Hinweis: Rufen Sie die Seite "RTMT-Prozess" auf, und sortieren Sie nach %CPU, um die CPU-Prozesse mit hoher Auslastung zu identifizieren.
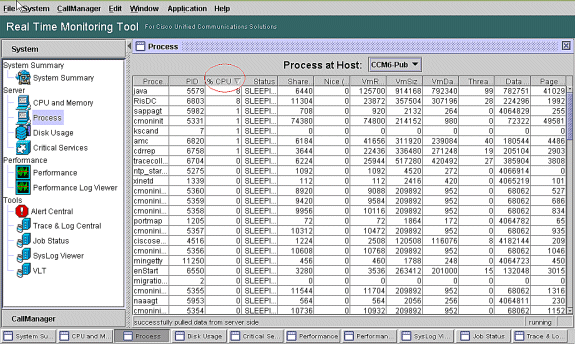
Hinweis: Für die Post-mortem-Analyse verfolgt das RIS-Fehlerbehebungsprotokoll den Prozess %CPU-Auslastung und verfolgt diesen auf Systemebene.
Hoher IOWait
Hoher %IOWait weist auf E/A-Aktivitäten bei hoher Festplatte hin. Berücksichtigen Sie Folgendes:
-
IOWait ist auf einen schweren Speicheraustausch zurückzuführen.
Überprüfen Sie die %CPU-Zeit für die Auslagerungspartition, um festzustellen, ob die Auslagerungsaktivität hoch ist. Da die Muster mindestens 2G RAM haben, ist ein hoher Speicheraustausch aufgrund eines Speicherverlusts wahrscheinlich.
-
IOWait ist auf DB-Aktivität zurückzuführen.
DB ist in erster Linie die einzige, die auf die aktive Partition zugreift. Wenn die %CPU-Zeit für die aktive Partition hoch ist, gibt es wahrscheinlich eine Menge DB-Aktivität.
Hohe IOWait durch gemeinsame Partition
Eine gemeinsame (oder Log-)Partition ist der Speicherort, in dem Ablaufverfolgungs- und Protokolldateien gespeichert werden.
Hinweis: Überprüfen Sie folgende Punkte:
-
Trace & Log Central: Gibt es eine Trace Collection-Aktivität? Wenn die Anrufverarbeitung betroffen ist (d. h. CodeYellow), passen Sie den Zeitplan für die Trace-Auflistung an. Wenn Sie die Zip-Option verwenden, deaktivieren Sie diese ebenfalls.
-
Trace-Einstellung - Auf der Detailed-Ebene generiert CallManager eine ziemlich große Spur. Wenn sich der Wert %IOWait und/oder CCM im CodeYellow-Zustand befindet und die Ablaufverfolgungseinstellung für den CallManager-Dienst "Detailed" lautet, versuchen Sie, die Einstellung auf "Error" zu ändern.
Identifizierung des Prozesses, der für die Festplatten-E/A verantwortlich ist
Die %IOWait-Nutzung pro Prozess kann nicht direkt ermittelt werden. Derzeit besteht die beste Möglichkeit darin, die Prozesse zu überprüfen, die auf der Festplatte warten.
Wenn %IOWait hoch genug ist, um eine CpuPegging-Warnung auszulösen, überprüfen Sie die Warnmeldung, um die Prozesse zu bestimmen, die auf die Festplatten-E/A warten.
-
Rufen Sie die Seite "RTMT-Prozess" auf, und sortieren Sie nach Status. Suchen Sie nach Prozessen im Ruhemodus der Unterbrechungsfreien Festplatte. Der von der TLC für die geplante Auflistung verwendete SFTP-Prozess befindet sich im Ruhezustand der Unterbrechungsfreien Festplatte.
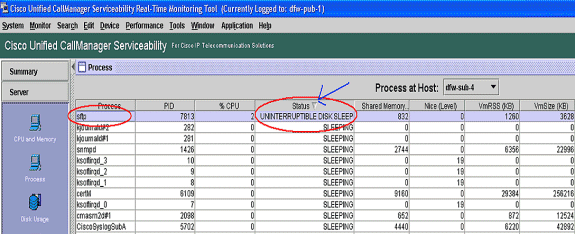
Hinweis: Die Datei RIS Troubleshooting PerfMon Log kann heruntergeladen werden, um den Prozessstatus für längere Zeit zu überprüfen.
-
Gehen Sie im Real-Time Monitoring Tool zu System > Tools > Trace > Trace & Log Central.
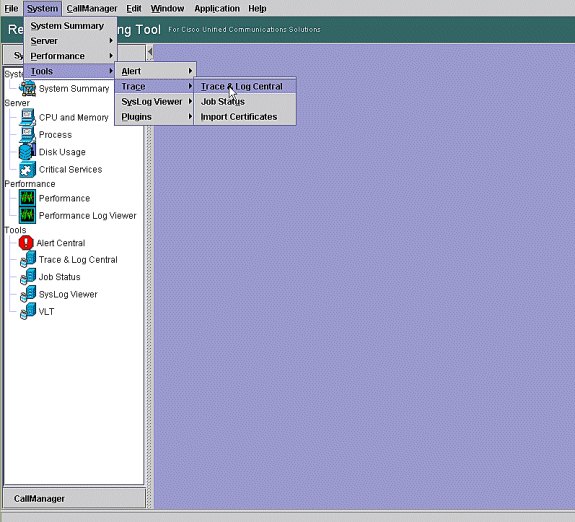
-
Doppelklicken Sie auf Dateien sammeln und wählen Sie Weiter aus.
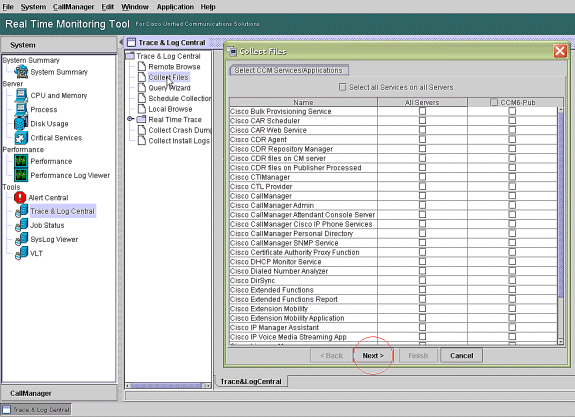
-
Wählen Sie Cisco RIS Data Collector PerfMonLog aus und wählen Sie Weiter.
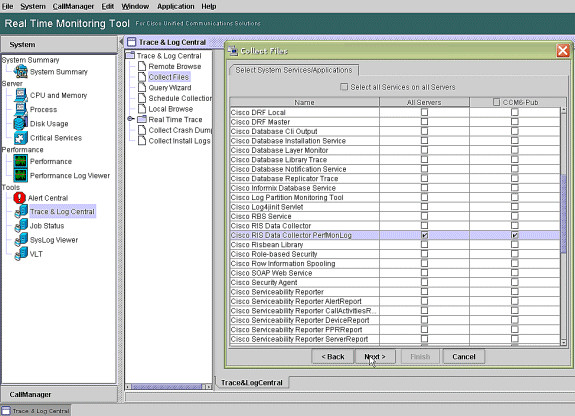
-
Konfigurieren Sie im Feld Collection Time (Erfassungsdauer) die zum Anzeigen von Protokolldateien für den betreffenden Zeitraum erforderliche Zeit. Navigieren Sie im Feld Download File Options (Dateioptionen herunterladen) zu Ihrem Downloadpfad (ein Speicherort, von dem Sie den Windows Performance Monitor starten können, um die Protokolldatei anzuzeigen), wählen Sie Zip Files (Dateien) aus, und wählen Sie Fertig stellen aus.
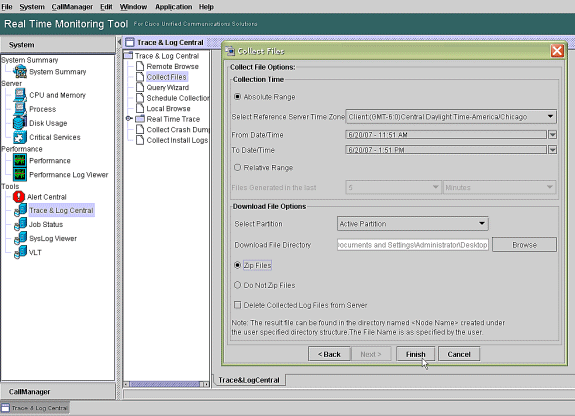
-
Notieren Sie sich den Fortschritt der Dateien sammeln und den Downloadpfad. Hier sollten keine Fehler gemeldet werden.
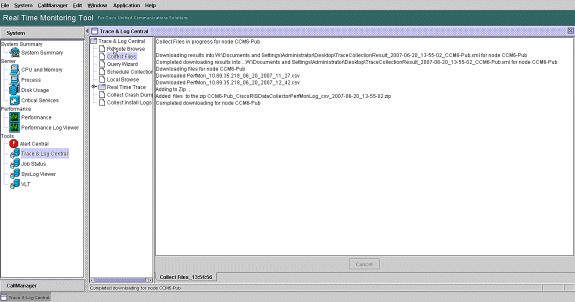
-
Zeigen Sie die Performance-Protokolldateien mit dem Microsoft Performance Monitor-Tool an. Wählen Sie Start > Einstellungen > Systemsteuerung > Verwaltung > Leistung aus.
-
Klicken Sie im Anwendungsfenster mit der rechten Maustaste, und wählen Sie Eigenschaften aus.
-
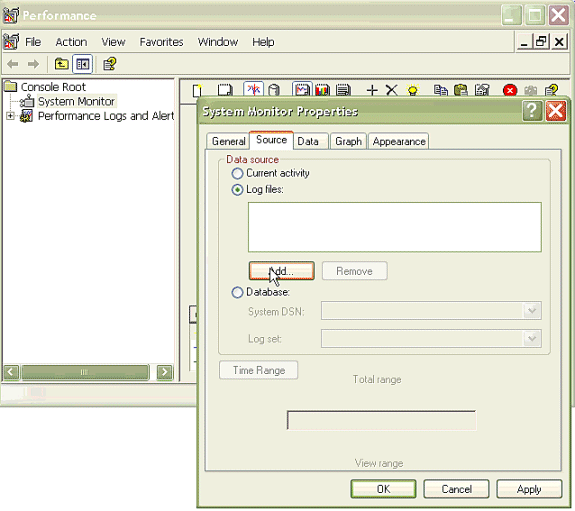
Wählen Sie im Dialogfeld Systemüberwachungseigenschaften die Registerkarte Quelle aus. Wählen Sie Protokolldateien: als Datenquelle, und klicken Sie auf die Schaltfläche Hinzufügen.
-
Durchsuchen Sie das Verzeichnis, in das Sie die PerfMon Log-Datei heruntergeladen haben, und wählen Sie die perfmon csv-Datei aus. Die Protokolldatei enthält die folgende Namenskonvention:
PerfMon_<Node>_<Monat>_<Tag>_<Jahr>_<Stunde>_<Minute>.csv; zum Beispiel PerfMon_10.89.35.218_6_20_2005_11_27.csv.
-
Klicken Sie auf Übernehmen.
-
Klicken Sie auf die Schaltfläche Zeitbereich. Um den Zeitbereich in der PerfMon-Protokolldatei anzugeben, die Sie anzeigen möchten, ziehen Sie die Leiste zur entsprechenden Start- und Endzeit.
-
Um das Dialogfeld Zähler hinzufügen zu öffnen, klicken Sie auf die Registerkarte Daten und dann auf Hinzufügen. Fügen Sie im Dropdown-Feld Performance Object (Leistungsobjekt) Process hinzu. Wählen Sie Prozessstatus aus, und klicken Sie auf Alle Instanzen. Wenn Sie die Zählerauswahl abgeschlossen haben, klicken Sie auf Schließen.
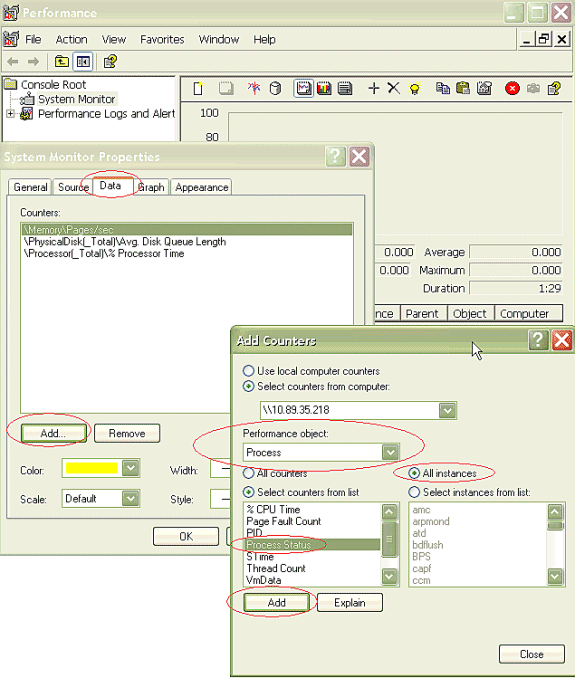
-
Tipps zum Anzeigen des Protokolls:
-
Stellen Sie die vertikale Skalierung des Diagramms auf maximal 6 ein.
-
Konzentrieren Sie sich auf jeden Prozess, und achten Sie auf den maximalen Wert von 2 oder mehr.
-
Löschen Sie Prozesse, die sich nicht im Unterbrechungsfreien Festplattenspeicher befinden.
-
Verwenden Sie die Markierungsoption.
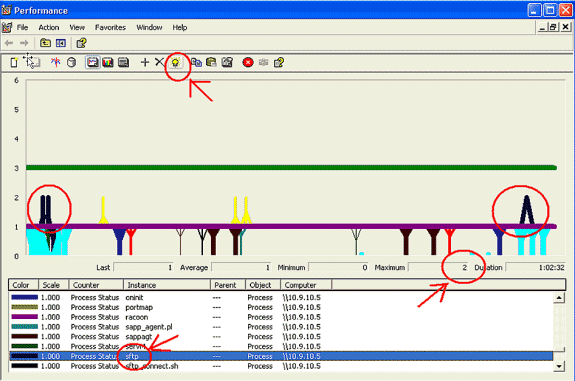
Hinweis: Prozessstatus 2 = Unterbrechungsfreier Festplattenschlaf ist verdächtig. Weitere Statusoptionen sind: 0-Lauf, 1-schlafend, 2-Unterbrechungsfreier Festplattenschlaf, 3-Zombie, 4-Trace oder Stopp, 5-Paging, 6-Unknown
-
Code Gelb
Die Code-Gelb-Warnung wird generiert, wenn der CallManager-Dienst in den Code-Gelb-Zustand wechselt. Weitere Informationen über den Code-Gelb-Status finden Sie unter Call Throttling und Code Yellow State. Die CodeYellow-Warnung kann so konfiguriert werden, dass Trace-Dateien zur Fehlerbehebung heruntergeladen werden.
Der AverageExpectedDelay-Zähler stellt die aktuelle durchschnittliche erwartete Verzögerung bei der Verarbeitung eingehender Nachrichten dar. Wenn der Wert über dem im Dienstparameter "Code Yellow Entry Latency" angegebenen Wert liegt, wird der CodeYellow-Alarm generiert. Dieser Zähler kann ein Schlüsselindikator für die Anrufverarbeitungsleistung sein.
CodeYellow, aber die CPU-Auslastung insgesamt beträgt nur 25 % - warum?
CallManager kann aufgrund fehlender Prozessorressourcen in den CodeYellow-Zustand wechseln, wenn die CPU-Gesamtauslastung in einer Box mit 4 virtuellen Prozessoren nur etwa 25-35 % beträgt.
Hinweis: Bei eingeschaltetem Hyper-Threading verfügt ein Server mit zwei physischen Prozessoren über vier virtuelle Prozessoren.
Hinweis: Auf ähnliche Weise ist CodeYellow auf einem Server mit zwei Prozessoren bei einer CPU-Gesamtauslastung von etwa 50 Prozent möglich.
Warnung: "Service Status is DOWN. Cisco Messaging-Schnittstelle."
Wenn RTMT den Dienststatus sendet, ist dieser DOWN. Cisco Messaging-Schnittstelle. Warnhinweise müssen Sie den Cisco Messaging Interface-Service deaktivieren, wenn CUCM nicht in ein Voice Messaging-System eines Drittanbieters integriert ist. Wenn Sie den Cisco Messaging Interface-Dienst deaktivieren, werden weitere Warnungen von RTMT gestoppt.
Zugehörige Informationen
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)