Fehlerbehebung ACI-Fehlercode F199144, F93337, F381328, F93241, F450296: TCA
Download-Optionen
-
ePub (692.1 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
Dieses Dokument beschreibt die Schritte zur Behebung der ACI-Fehlercodes: F199144, F93337, F381328, F93241, F450296
Hintergrund
Wenn Sie eine Intersight Connected ACI-Fabric nutzen, wurde in Ihrem Auftrag eine Serviceanfrage erstellt, um anzugeben, dass eine Instanz dieses Fehlers in Ihrer Intersight Connected ACI-Fabric gefunden wurde.
Dies wird im Rahmen der proaktiven ACI-Initiativen aktiv überwacht.
In diesem Dokument werden die nächsten Schritte zur Behebung des folgenden Fehlers beschrieben:
Fehler: F199144
"Code" : "F199144",
"Description" : "TCA: External Subnet (v4 and v6) prefix entries usage current value(eqptcapacityPrefixEntries5min:extNormalizedLast) value 91% raised above threshold 90%",
"Dn" : "topology/pod-1/node-132/sys/eqptcapacity/fault-F199144"
Dieser spezielle Fehler wird ausgelöst, wenn die aktuelle Nutzung des externen Subnetzpräfixes 99 % überschreitet. Dies legt eine Hardware-Beschränkung hinsichtlich der von diesen Switches verarbeiteten Routen nahe.
Schnellstart zur Fehlerbehebung: F199144
1. Befehl "show platform internal hal l3 routing threshold"
module-1# show platform internal hal l3 routingthresholds
Executing Custom Handler function
OBJECT 0:
trie debug threshold : 0
tcam debug threshold : 3072
Supported UC lpm entries : 14848
Supported UC lpm Tcam entries : 5632
Current v4 UC lpm Routes : 19526
Current v6 UC lpm Routes : 0
Current v4 UC lpm Tcam Routes : 404
Current v6 UC lpm Tcam Routes : 115
Current v6 wide UC lpm Tcam Routes : 24
Maximum HW Resources for LPM : 20480 < ------- Maximum hardware resources
Current LPM Usage in Hardware : 20390 < ------------Current usage in Hw
Number of times limit crossed : 5198 < -------------- Number of times that limit was crossed
Last time limit crossed : 2020-07-07 12:34:15.947 < ------ Last occurrence, today at 12:34 pm2. Befehl "show platform internal hal health-stats"
module-1# show platform internal hal health-stats
No sandboxes exist
|Sandbox_ID: 0 Asic Bitmap: 0x0
|-------------------------------------
L2 stats:
=========
bds: : 249
...
l2_total_host_entries_norm : 4
L3 stats:
=========
l3_v4_local_ep_entries : 40
max_l3_v4_local_ep_entries : 12288
l3_v4_local_ep_entries_norm : 0
l3_v6_local_ep_entries : 0
max_l3_v6_local_ep_entries : 8192
l3_v6_local_ep_entries_norm : 0
l3_v4_total_ep_entries : 221
max_l3_v4_total_ep_entries : 24576
l3_v4_total_ep_entries_norm : 0
l3_v6_total_ep_entries : 0
max_l3_v6_total_ep_entries : 12288
l3_v6_total_ep_entries_norm : 0
max_l3_v4_32_entries : 49152
total_l3_v4_32_entries : 6294
l3_v4_total_ep_entries : 221
l3_v4_host_uc_entries : 6073
l3_v4_host_mc_entries : 0
total_l3_v4_32_entries_norm : 12
max_l3_v6_128_entries : 12288
total_l3_v6_128_entries : 17
l3_v6_total_ep_entries : 0
l3_v6_host_uc_entries : 17
l3_v6_host_mc_entries : 0
total_l3_v6_128_entries_norm : 0
max_l3_lpm_entries : 20480 < ----------- Maximum
l3_lpm_entries : 19528 < ------------- Current L3 LPM entries
l3_v4_lpm_entries : 19528
l3_v6_lpm_entries : 0
l3_lpm_entries_norm : 99
max_l3_lpm_tcam_entries : 5632
max_l3_v6_wide_lpm_tcam_entries: 1000
l3_lpm_tcam_entries : 864
l3_v4_lpm_tcam_entries : 404
l3_v6_lpm_tcam_entries : 460
l3_v6_wide_lpm_tcam_entries : 24
l3_lpm_tcam_entries_norm : 15
l3_v6_lpm_tcam_entries_norm : 2
l3_host_uc_entries : 6090
l3_v4_host_uc_entries : 6073
l3_v6_host_uc_entries : 17
max_uc_ecmp_entries : 32768
uc_ecmp_entries : 250
uc_ecmp_entries_norm : 0
max_uc_adj_entries : 8192
uc_adj_entries : 261
uc_adj_entries_norm : 3
vrfs : 150
infra_vrfs : 0
tenant_vrfs : 148
rtd_ifs : 2
sub_ifs : 2
svi_ifs : 185
Nächste Schritte Fehler: F199144
1. Reduzieren Sie die Anzahl der Routen, die jeder Switch bewältigen muss, sodass Sie die für das Hardwaremodell definierte Skalierbarkeit erfüllen. Den Skalierbarkeitsleitfaden finden Sie hier https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/4-x/verified-scalability/Cisco-ACI-Verified-Scalability-Guide-412.html
2. Ändern Sie das Weiterleitungsskalierungsprofil basierend auf der Skalierung. https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/all/forwarding-scale-profiles/cisco-apic-forwarding-scale-profiles/m-overview-and-guidelines.html
3. Entfernen des Subnetzes 0.0.0.0/0 aus L3Out und nur Konfigurieren der erforderlichen Subnetze
4. Wenn Sie Gen 1 verwenden, aktualisieren Sie Ihre Hardware von Gen 1 auf Gen 2, da Gen 2-Switches mehr als 20.000 externe v4-Routen zulassen.
Fehler: F93337
"Code" : "F93337",
"Description" : "TCA: memory usage current value(compHostStats15min:memUsageLast) value 100% raised above threshold 99%",
"Dn" : "comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/fault-F93337"Dieser spezielle Fehler wird ausgelöst, wenn der Host des virtuellen Systems mehr Speicher als den Schwellenwert belegt. Der APIC überwacht diese Hosts über VCenter. Comp:HostStats15min ist eine Klasse, die die aktuellsten Statistiken für den Host in einem Samplingintervall von 15 Minuten darstellt. Diese Klasse wird alle 5 Minuten aktualisiert.
Schnellstart zur Fehlerbehebung: F93337
1. Befehl "moquery -d 'comp/prov-VMware/ctrlr-[<DVS>]-<VCenter>/vm-vm-<VM-ID aus der DN des Fehlers>"
Dieser Befehl gibt Informationen über die betroffene VM
# comp.Vm
oid : vm-1071
cfgdOs : Ubuntu Linux (64-bit)
childAction :
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071
ftRole : unset
guid : 501030b8-028a-be5c-6794-0b7bee827557
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T17:16:06.572+05:30
monPolDn : uni/tn-692673613-VSPAN/monepg-test
name : VM3
nameAlias :
os :
rn : vm-vm-1071
state : poweredOn
status :
template : no
type : virt
uuid : 4210b04b-32f3-b4e3-25b4-fe73cd3be0ca2. Befehl "moquery -c compRsHv | grep 'vm-1071'"
Dieser Befehl gibt Informationen über den Host an, auf dem VM gehostet wird. In diesem Beispiel befindet sich die virtuelle Maschine auf host-347.
apic2# moquery -c compRsHv | grep vm-1071
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/rshv-[comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068]3. Befehl "moquery -c compHv -f 'comp.Hv.oid=="host-1068""
Dieser Befehl enthält Details zum Host.
apic2# moquery -c compHv -f 'comp.Hv.oid=="host-1068"'
Total Objects shown: 1
# comp.Hv
oid : host-1068
availAdminSt : gray
availOperSt : gray
childAction :
countUplink : 0
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068
enteringMaintenance : no
guid : b1e21bc1-9070-3846-b41f-c7a8c1212b35
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T14:23:26.654+05:30
monPolDn : uni/infra/moninfra-default
name : myhost
nameAlias :
operIssues :
os :
rn : hv-host-1068
state : poweredOn
status :
type : hv
uuid :Nächste Schritte Fehler: F93337
1. Ändern Sie den zugewiesenen Speicher für die VM auf dem Host.
2. Wenn der Speicher erwartet wird, können Sie den Fehler beheben, indem Sie eine Statistiksammelrichtlinie erstellen, um den Schwellenwert zu ändern.
a. Erstellen Sie unter dem Tenant des virtuellen Systems eine neue Überwachungsrichtlinie.

b. Wählen Sie unter Ihrer Überwachungsrichtlinie die Statistiksammelrichtlinie aus.
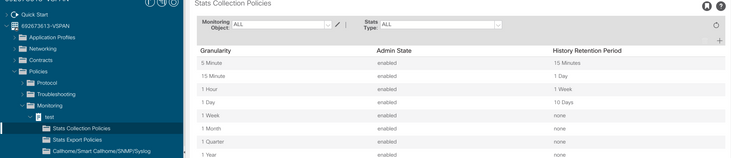
c. Klicken Sie auf das Bearbeitungssymbol neben dem Dropdown-Menü Überwachungsobjekt, und überprüfen Sie die virtuelle Maschine (comp.Vm) als Überwachungsobjekt. Wählen Sie nach dem Einreichen das compVm-Objekt aus dem Dropdown-Menü Überwachungsobjekt aus.

d. Klicken Sie auf das Symbol Edit (Bearbeiten) neben Stats (Statistiktyp), und aktivieren Sie dann CPU Usage (CPU-Nutzung).
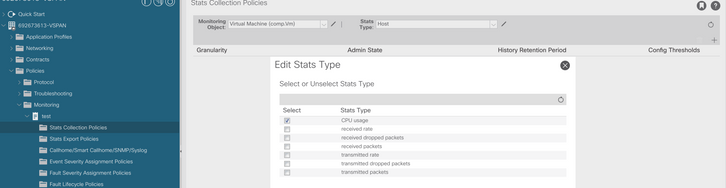
e. Klicken Sie im Statistiktyp Dropdown auf Host auswählen, klicken Sie auf das Pluszeichen (+) und geben Sie Ihre Granularität, den Verwaltungsstatus und den Verlaufszeitraum ein. Klicken Sie dann auf Aktualisieren.

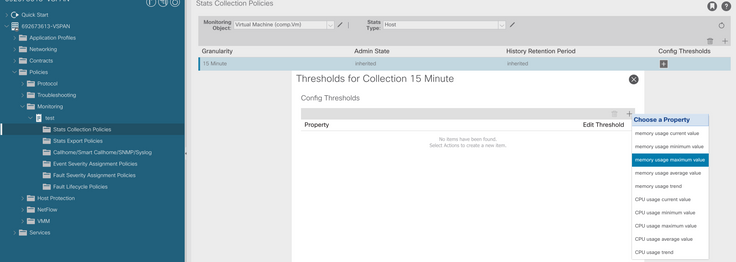
f. Klicken Sie unter dem Konfigurationsschwellenwert auf das +-Zeichen, und fügen Sie als Eigenschaft "Maximalwert für Speichernutzung" hinzu.
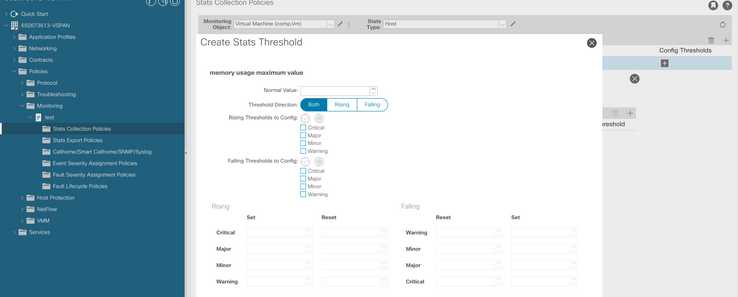
g. Ändern Sie den Normalwert auf den gewünschten Schwellenwert.
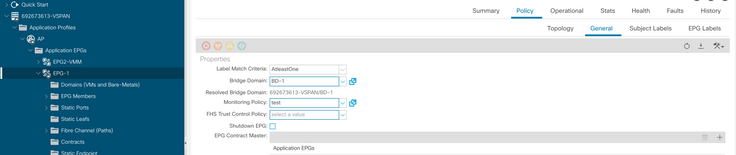
h. Anwendung der Überwachungsrichtlinie auf die EPG
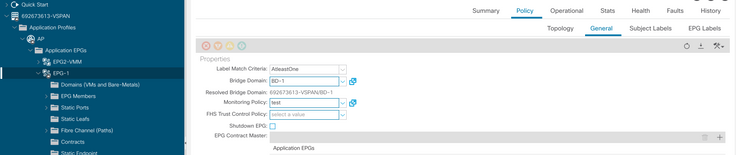
I. Um zu bestätigen, ob die Richtlinie auf den virtuellen Rechner angewendet wird, führen Sie "moquery -c compVm -f 'comp.Vm.oid = "vm-<vm-id>" aus."
apic1# moquery -c compVm -f 'comp.Vm.oid == "vm-1071"' | grep monPolDn
monPolDn : uni/tn-692673613-VSPAN/monepg-test <== Monitoring Policy test has been applied
Fehler: F93241
"Code" : "F93241",
"Description" : "TCA: CPU usage average value(compHostStats15min:cpuUsageAvg) value 100% raised above threshold 99%",
"Dn" : "comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/fault-F93241"Dieser spezielle Fehler wird ausgelöst, wenn der Host des virtuellen Systems CPU mehr als den Schwellenwert belegt. Der APIC überwacht diese Hosts über VCenter. Comp:HostStats15min ist eine Klasse, die die aktuellsten Statistiken für den Host in einem Samplingintervall von 15 Minuten darstellt. Diese Klasse wird alle 5 Minuten aktualisiert.
Schnellstart zur Fehlerbehebung: F93241
1. Befehl "moquery -d 'comp/prov-VMware/ctrlr-[<DVS>]-<VCenter>/vm-vm-<VM-ID aus der DN des Fehlers>"
Dieser Befehl gibt Informationen über die betroffene VM
# comp.Vm
oid : vm-1071
cfgdOs : Ubuntu Linux (64-bit)
childAction :
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071
ftRole : unset
guid : 501030b8-028a-be5c-6794-0b7bee827557
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T17:16:06.572+05:30
monPolDn : uni/tn-692673613-VSPAN/monepg-test
name : VM3
nameAlias :
os :
rn : vm-vm-1071
state : poweredOn
status :
template : no
type : virt
uuid : 4210b04b-32f3-b4e3-25b4-fe73cd3be0ca2. Befehl "moquery -c compRsHv | grep 'vm-1071'"
Dieser Befehl gibt Informationen über den Host an, auf dem VM gehostet wird. In diesem Beispiel befindet sich die virtuelle Maschine auf host-347.
apic2# moquery -c compRsHv | grep vm-1071
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/rshv-[comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068]3. Befehl "moquery -c compHv -f 'comp.Hv.oid=="host-1068""
Dieser Befehl enthält Details zum Host.
apic2# moquery -c compHv -f 'comp.Hv.oid=="host-1068"'
Total Objects shown: 1
# comp.Hv
oid : host-1068
availAdminSt : gray
availOperSt : gray
childAction :
countUplink : 0
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068
enteringMaintenance : no
guid : b1e21bc1-9070-3846-b41f-c7a8c1212b35
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T14:23:26.654+05:30
monPolDn : uni/infra/moninfra-default
name : myhost
nameAlias :
operIssues :
os :
rn : hv-host-1068
state : poweredOn
status :
type : hv
uuid :Nächste Schritte Fehler: F93241
1. Aktualisieren Sie die zugewiesene CPU für die VM auf dem Host.
2. Wenn die CPU erwartet wird, können Sie den Fehler unterdrücken, indem Sie eine Statistiksammelrichtlinie erstellen, um den Schwellenwert zu ändern.
a. Erstellen Sie unter dem Tenant des virtuellen Systems eine neue Überwachungsrichtlinie.

b. Wählen Sie unter Ihrer Überwachungsrichtlinie die Statistiksammelrichtlinie aus.
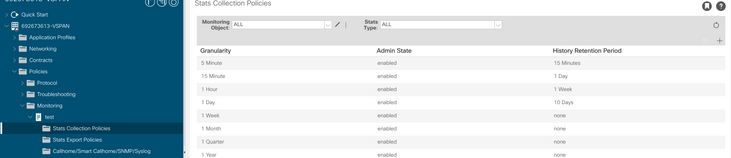
c. Klicken Sie auf das Bearbeitungssymbol neben dem Dropdown-Menü Überwachungsobjekt, und überprüfen Sie die virtuelle Maschine (comp.Vm) als Überwachungsobjekt. Wählen Sie nach dem Einreichen das compVm-Objekt aus dem Dropdown-Menü Überwachungsobjekt aus.

d. Klicken Sie auf das Symbol Edit (Bearbeiten) neben Stats (Statistiktyp), und aktivieren Sie dann CPU Usage (CPU-Nutzung).
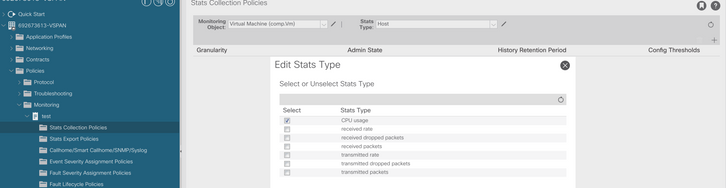
e. Klicken Sie im Statistiktyp Dropdown auf Host auswählen, klicken Sie auf das Pluszeichen (+) und geben Sie Ihre Granularität, den Verwaltungsstatus und den Verlaufszeitraum ein. Klicken Sie dann auf Aktualisieren.

f. Klicken Sie auf das +-Zeichen unter dem Konfigurationsschwellenwert, und fügen Sie "CPU Usage maximum value" als Eigenschaft hinzu.
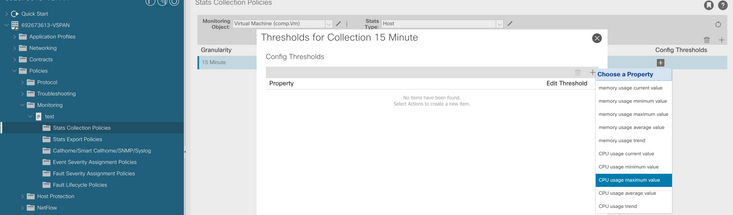
g. Ändern Sie den Normalwert auf den gewünschten Schwellenwert.
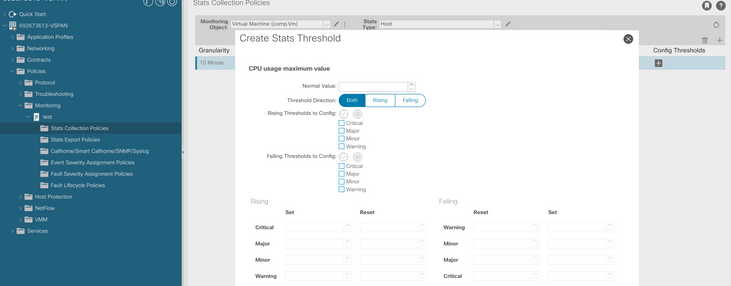
h. Anwendung der Überwachungsrichtlinie auf die EPG
I. Um zu bestätigen, ob die Richtlinie auf den virtuellen Rechner angewendet wird, führen Sie "moquery -c compVm -f 'comp.Vm.oid = "vm-<vm-id>" aus."
apic1# moquery -c compVm -f 'comp.Vm.oid == "vm-1071"' | grep monPolDn
monPolDn : uni/tn-692673613-VSPAN/monepg-test <== Monitoring Policy test has been appliedFehler: F381328
"Code" : "F381328",
"Description" : "TCA: CRC Align Errors current value(eqptIngrErrPkts5min:crcLast) value 50% raised above threshold 25%",
"Dn" : "topology/<pod>/<node>/sys/phys-<[interface]>/fault-F381328"Dieser spezifische Fehler tritt auf, wenn CRC-Fehler an einer Schnittstelle den Schwellenwert überschreiten. Es gibt zwei häufige Arten von CRC-Fehlern: FCS-Fehler und CRC-Stomped-Fehler. CRC-Fehler werden aufgrund eines Cut-Through Switched Path propagiert und sind das Ergebnis anfänglicher FCS-Fehler. Da die ACI dem Cut-Through-Switching folgt, durchlaufen diese Frames letztlich die ACI-Fabric, und Stomp-CRC-Fehler treten auf dem Pfad auf. Dies bedeutet nicht, dass alle Schnittstellen mit CRC-Fehlern Fehler sind. Es wird empfohlen, die Quelle für CRC zu identifizieren und das problematische SFP/Port/Fiber zu beheben.
Schnellstart zur Fehlerbehebung: F381328
1. Speichern Sie die Schnittstellen mit der höchsten Anzahl an CRC in der Fabric.
moquery -c rmonEtherStats -f 'rmon.EtherStats.cRCAlignErrors>="1"' | egrep "dn|cRCAlignErrors" | egrep -o "\S+$" | tr '\r\n' ' ' | sed -re 's/([[:digit:]]+)\s/\n\1 /g' | awk '{printf "%-65s %-15s\n", $2,$1}' | sort -rnk 2
topology/pod-1/node-103/sys/phys-[eth1/50]/dbgEtherStats 399158
topology/pod-1/node-101/sys/phys-[eth1/51]/dbgEtherStats 399158
topology/pod-1/node-1001/sys/phys-[eth2/24]/dbgEtherStats 3991582. Speichern Sie die höchste Anzahl von FCS in der Fabric.
moquery -c rmonDot3Stats -f 'rmon.Dot3Stats.fCSErrors>="1"' | egrep "dn|fCSErrors" | egrep -o "\S+$" | tr '\r\n' ' ' | sed -re 's/topology/\ntopology/g' | awk '{printf "%-65s %-15s\n", $1,$2}' | sort -rnk 2Nächste Schritte Fehler: F381328
1. Wenn FCS-Fehler in der Fabric vorliegen, werden diese Fehler behoben. Diese Fehler weisen in der Regel auf Layer-1-Probleme hin.
2. Wenn CRC-Stomp-Fehler am Port der Frontblende vorliegen, überprüfen Sie das angeschlossene Gerät am Port und ermitteln Sie, warum Stempel von diesem Gerät stammen.
Python-Skript für Fehler : F381328
Dieser gesamte Prozess kann auch mit Python-Skript automatisiert werden. Weitere Informationen finden Sie unter https://www.cisco.com/c/en/us/support/docs/cloud-systems-management/application-policy-infrastructure-controller-apic/217577-how-to-use-fcs-and-crc-troubleshooting-s.html
Fehler: F450296
"Code" : "F450296",
"Description" : "TCA: Multicast usage current value(eqptcapacityMcastEntry5min:perLast) value 91% raised above threshold 90%",
"Dn" : "sys/eqptcapacity/fault-F450296"Dieser spezielle Fehler wird ausgelöst, wenn die Anzahl der Multicast-Einträge den Grenzwert überschreitet.
Schnellstart zur Fehlerbehebung: F450296
1. Befehl "show platform internal hal health-stats asic-unit all"
module-1# show platform internal hal health-stats asic-unit all
|Sandbox_ID: 0 Asic Bitmap: 0x0
|-------------------------------------
L2 stats:
=========
bds: : 1979
max_bds: : 3500
external_bds: : 0
vsan_bds: : 0
legacy_bds: : 0
regular_bds: : 0
control_bds: : 0
fds : 1976
max_fds : 3500
fd_vlans : 0
fd_vxlans : 0
vlans : 3955
max vlans : 3960
vlan_xlates : 6739
max vlan_xlates : 32768
ports : 52
pcs : 47
hifs : 0
nif_pcs : 0
l2_local_host_entries : 1979
max_l2_local_host_entries : 32768
l2_local_host_entries_norm : 6
l2_total_host_entries : 1979
max_l2_total_host_entries : 65536
l2_total_host_entries_norm : 3
L3 stats:
=========
l3_v4_local_ep_entries : 3953
max_l3_v4_local_ep_entries : 32768
l3_v4_local_ep_entries_norm : 12
l3_v6_local_ep_entries : 1976
max_l3_v6_local_ep_entries : 24576
l3_v6_local_ep_entries_norm : 8
l3_v4_total_ep_entries : 3953
max_l3_v4_total_ep_entries : 65536
l3_v4_total_ep_entries_norm : 6
l3_v6_total_ep_entries : 1976
max_l3_v6_total_ep_entries : 49152
l3_v6_total_ep_entries_norm : 4
max_l3_v4_32_entries : 98304
total_l3_v4_32_entries : 35590
l3_v4_total_ep_entries : 3953
l3_v4_host_uc_entries : 37
l3_v4_host_mc_entries : 31600
total_l3_v4_32_entries_norm : 36
max_l3_v6_128_entries : 49152
total_l3_v6_128_entries : 3952
l3_v6_total_ep_entries : 1976
l3_v6_host_uc_entries : 1976
l3_v6_host_mc_entries : 0
total_l3_v6_128_entries_norm : 8
max_l3_lpm_entries : 38912
l3_lpm_entries : 9384
l3_v4_lpm_entries : 3940
l3_v6_lpm_entries : 5444
l3_lpm_entries_norm : 31
max_l3_lpm_tcam_entries : 4096
max_l3_v6_wide_lpm_tcam_entries: 1000
l3_lpm_tcam_entries : 2689
l3_v4_lpm_tcam_entries : 2557
l3_v6_lpm_tcam_entries : 132
l3_v6_wide_lpm_tcam_entries : 0
l3_lpm_tcam_entries_norm : 65
l3_v6_lpm_tcam_entries_norm : 0
l3_host_uc_entries : 2013
l3_v4_host_uc_entries : 37
l3_v6_host_uc_entries : 1976
max_uc_ecmp_entries : 32768
uc_ecmp_entries : 1
uc_ecmp_entries_norm : 0
max_uc_adj_entries : 8192
uc_adj_entries : 1033
uc_adj_entries_norm : 12
vrfs : 1806
infra_vrfs : 0
tenant_vrfs : 1804
rtd_ifs : 2
sub_ifs : 2
svi_ifs : 1978
Mcast stats:
============
mcast_count : 31616 <<<<<<<
max_mcast_count : 32768
Policy stats:
=============
policy_count : 127116
max_policy_count : 131072
policy_otcam_count : 2920
max_policy_otcam_count : 8192
policy_label_count : 0
max_policy_label_count : 0
Dci Stats:
=============
vlan_xlate_entries : 0
vlan_xlate_entries_tcam : 0
max_vlan_xlate_entries : 0
sclass_xlate_entries : 0
sclass_xlate_entries_tcam : 0
max_sclass_xlate_entries : 0Nächste Schritte Fehler: F450296
1. Ziehen Sie in Betracht, einen Teil des Multicast-Datenverkehrs auf andere Leafs zu verlagern.
2. Erkunden Sie verschiedene Weiterleitungs-Skalierungsprofile, um die Multicast-Skalierung zu erhöhen. Weitere Informationen finden Sie unter https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/all/forwarding-scale-profiles/cisco-apic-forwarding-scale-profiles/m-forwarding-scale-profiles-523.html
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
11-Jul-2023 |
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Savinder SinghTAC
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)