Einleitung
In diesem Dokument werden verschiedene Arten von Datenträgerfehlern beschrieben, wie diese klassifiziert werden, und Tools, mit denen Sie sie identifizieren können.
Voraussetzungen
Anforderungen
Es gibt keine spezifischen Anforderungen für dieses Dokument.
Verwendete Komponenten
Die Informationen in diesem Dokument basieren auf Festplatten des Unified Computing System (UCS).
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netz Live ist, überprüfen Sie, ob Sie die mögliche Auswirkung jedes möglichen Befehls verstehen.
Hintergrundinformationen
Das Dokument beschreibt auch die Rolle des Festplattenlaufwerks (HDD) und des RAID-Controllers (Redundant Array of Independent Disks) bei der Identifizierung von mittelgroßen Fehlern auf den Laufwerken.
Hinweis: mittelgroße Fehler werden auch als Medienfehler bezeichnet.
Fehler bei mittlerer HDD-Kapazität behandeln
Was verursacht HDD-Medienfehler?
Die häufigste Ursache für mittelgroße Fehler ist eine schlechte Signalamplitude, die
- Unzuverlässige LBA-Leseposition (Logical Bus Address). Manchmal wiederherstellbar mit mehreren Wiederholungsversuchen.
- Vorübergehende Bedingungen, hohe Fliegenschreibvorgänge, die durch weiche Partikel verursacht werden.
- Übergangsbedingungen, die durch vorübergehende Erschütterungen, Vibrationen oder akustische Ereignisse verursacht werden und zu Fehlschreibungen führen.
- Schlechte Fehlerzuordnungsfunktion bei der HDD-Herstellung, die zu einer Polsterung der aktuellen primären Fehlerstellen führt.
Wie erkennt die HDD den Medienfehler?
Schritt 1:Die Festplatte führt regelmäßig Scans der Hintergrundmedien durch, um Fehler zu erkennen.
Schritt 2: Die Festplatte versucht, vom Medium zu lesen und kann aus irgendeinem Grund die geschriebenen Daten nicht abrufen.
Schritt 3: Wenn die Festplatte nicht in der Lage ist, die geschriebenen Daten abzurufen, ruft sie den Wiederherstellungscode der Festplatte auf, der verschiedene Schritte zur Fehlerwiederherstellung durchführt, um die Daten erfolgreich vom Medium zu lesen.
Schritt 4: Wenn alle Wiederherstellungsschritte fehlschlagen, generiert das Laufwerk einen 03/11/0x-Fehler zurück zum Host, und die LBA(s) werden in die Liste ausstehender Fehler aufgenommen.
Wie erkennt der RAID-Controller Mediumfehler?
- Der RAID-Controller weist bei Patrol Reads, Consistency Checks, Normal Reads, Rebuilds und Lese-/Änderungs-/Schreibvorgängen mittelgroße Fehler auf.
- Je nach RAID-Konfiguration kann der Controller den von der Festplatte gemeldeten mittleren Fehler möglicherweise verarbeiten, sodass keine weiteren Maßnahmen erforderlich sind.
- In einigen Fällen kann der Controller den Medienfehler nicht beheben und gibt den Fehler an den Host weiter, um den Fehler zu beheben.
Wann treten beim Betriebssystem (OS) mittlere Fehler auf?
- Wenn die Festplatte einen mittleren Fehler meldet und der RAID-Controller die Wiederherstellung nicht verarbeiten kann, wird der Host über den Fehler informiert.
- Diese Benachrichtigung ist nicht mehr nur eine Warnmeldung, die das System darüber informiert, dass das Ereignis eingetreten ist. Es handelt sich um eine Anforderung an das Betriebssystem, da die Festplatte und der RAID-Controller nicht in der Lage waren, nach dem Medienfehler wiederherzustellen.
- Wenn das Betriebssystem über den erforderlichen Kontext verfügt, um den Medienfehler richtig zu beheben, muss es vom Betriebssystem behandelt werden.
- Wenn sich die Datenträger in Just a Bunch Of Disk (JBOD) befinden, werden dem Betriebssystem Fehler angezeigt, da sie vom Controller nicht korrigiert werden. Dies ist in HyperFlex (HX)-/Virtual Storage Area Network (VSAN)-Umgebungen üblich.
HDD-Rolle
Wachsende Defekte (G-Liste) HDD-Ebene
Während des Betriebs eines Laufwerks trifft der Kopf möglicherweise auf einen Sektor mit einem geschwächten magnetischen Lesepegel. Die Daten sind noch lesbar, können aber unter den für einen qualifizierten guten Sektor bevorzugten Schwellenwert fallen. Dieses Festplattenlaufwerk würde dies als einen Sektor betrachten, der diese Daten an einem neuen Speicherort speichern könnte und würde, der in der Liste der bekannten Reserven verfügbar ist. Nachdem die Daten verschoben wurden, wird die alte Sektoradresse zur Liste "Grown Defects" (Grown Defects) hinzugefügt und kann nicht mehr verwendet werden. Bei diesem Prozess handelt es sich um einen behebbaren Medienfehler. Das Laufwerk gibt einen SMART-Auslöser aus, sobald die meisten zweifelsfrei funktionierenden Ersatzsektoren erschöpft sind.
RAID-Controller-Rolle
Patrol Read
- Patrol Read ist eine benutzerdefinierbare Option, die Laufwerkslesungen im Hintergrund durchführt und alle fehlerhaften Bereiche des Laufwerks ausweist.
- Patrol Read sucht nach physischen Datenträgerfehlern, die zu einem Laufwerksfehler führen können. Diese Prüfungen beinhalten in der Regel den Versuch, Abhilfe zu schaffen. Patrol Read kann mit automatischer oder manueller Aktivierung aktiviert oder deaktiviert werden.
- Mit Patrol Read werden in regelmäßigen Abständen alle Sektoren physischer Festplatten überprüft, die mit einem Controller verbunden sind. Dazu gehört auch der vom System reservierte Bereich der RAID-konfigurierten Festplatten. Patrol Read funktioniert für alle RAID-Level und alle Hot-Spare-Laufwerke.
- Dieser Prozess startet nur, wenn der RAID-Controller eine bestimmte Zeit lang inaktiv ist und keine anderen Hintergrundaufgaben aktiv sind. Er kann jedoch gleichzeitig mit umfangreichen E/A-Prozessen (Input/Output) ausgeführt werden.
- Patrol Reads können nicht auf Laufwerken durchgeführt werden, die in JBOD konfiguriert sind.
Hinweis: Latent Semantic Indexing (LSI) empfiehlt, die Patrol-Lesefrequenz und andere Patrol-Leseeinstellungen auf den Standardwerten zu belassen, um die beste Systemleistung zu erzielen. Wenn Sie die Werte ändern möchten, notieren Sie sich hier den ursprünglichen Standardwert, damit Sie ihn später wiederherstellen können.
Hinweis: Patrol Read meldet keinen Fortschritt während der Ausführung. Der Status des Patrol-Lesevorgangs wird nur im Ereignisprotokoll angezeigt.
Patrol Leseoptionen sind wie im Bild gezeigt:
 MegaCli - Beispiele
MegaCli - Beispiele
So zeigen Sie Informationen über den Patrol-Lesezustand und die Verzögerung zwischen Patrol-Lesevorgängen an:
# MegaCli64 -AdpPR -Info -aALL
Um die aktuelle Patrol-Leserate zu ermitteln, führen Sie Folgendes aus:
# MegaCli64 -AdpGetProp PatrolReadRate -aALL
So deaktivieren Sie die automatische Überwachung:
# MegaCli64 -AdpPR -Dsbl -aALL
So aktivieren Sie die automatische Überwachung:
#MegaCli64 -AdpPR -EnblAuto -aALL
So starten Sie eine manuelle Überprüfung:
# MegaCli64 -AdpPR -Start -aALL
So stoppen Sie einen Patrouillen-Lesescan:
# MegaCli64 -AdpPR -Stopp -aALL
Konsistenzprüfung
- Bei RAID wird mit der Konsistenzprüfung die Richtigkeit redundanter Daten in einem Array überprüft. In einem System mit Parität bedeutet Konsistenzprüfung beispielsweise, die Parität der Datenlaufwerke zu berechnen und die Ergebnisse mit dem Inhalt des Paritätslaufwerks zu vergleichen.
- JBOD unterstützt keine Konsistenzprüfung.
- RAID 0 unterstützt keine Konsistenzprüfung.
- RAID 1 verwendet einen Datenvergleich und keine Parität.
- RAID 6 berechnet die Parität für 2 Paritätslaufwerke und verifiziert beide.
Hinweis: Es wird empfohlen, mindestens einmal im Monat eine Konsistenzprüfung durchzuführen.
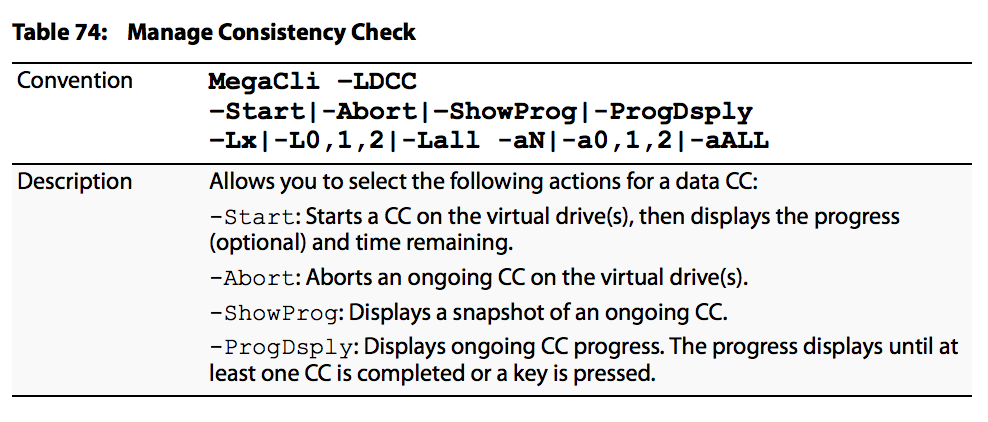
Konsistenzprüfung Verwaltungsoptionen sind wie im Bild gezeigt:
Consistency Check-Planungsoptionen sind wie im Bild dargestellt:

MegaCli - Beispiele
So zeigen Sie die nächste geplante Zeit für die Konsistenzprüfung an:
#MegaCli64 -AdpCcSched -Info -aALL
So ändern Sie die geplante Zeit für die Konsistenzprüfung:
#MegaCli64 -AdpCCSched -SetSTartTime 20171028 02 -aALL
So deaktivieren Sie die Konsistenzprüfung:
#MegaCli64 -AdpCcSched -Dsbl -aALL
Bedingungen, unter denen ein RAID-Controller einen mittleren Fehler nicht beheben kann
- In JBOD
- Das Host-Betriebssystem ist für mittlere Fehler verantwortlich.
- In RAID 0
- Da keine Redundanz vorhanden ist, kann der Controller die Daten, die auf die HDD geschrieben werden sollen, nicht auf die LBA übertragen.
- In RAID 1
- Wenn der Controller nicht erkennen kann, welche Spiegelkopie die richtigen Daten enthält. Dies geschieht nur, wenn beide LBAs gelesen werden können, die Daten jedoch nicht übereinstimmen.
- RAID 5
- Wenn im gleichen Stripe zwei oder mehr Fehler vorliegen. Die wahrscheinlichste Ursache ist, dass nach der Neuerstellung eines Arrays eine Wiederherstellung eingeleitet wird. Bei der neu erstellten Festplatte handelt es sich um einen Fehler, und ein mittlerer Fehler bei der Wiederherstellung einer anderen Festplatte wäre der zweite Fehler. Der Controller wäre nicht in der Lage, die Daten wiederherzustellen, die für die Wiederherstellung des LBA auf dem Ersatzlaufwerk erforderlich sind.
- RAID 6
- Wenn im gleichen Stripe drei oder mehr Fehler vorliegen. Die wahrscheinlichste Ursache ist, dass ein Array neu erstellt wird. Bei der neu erstellten Festplatte handelt es sich um einen Fehler, und ein mittlerer Fehler auf zwei anderen Festplatten während der Wiederherstellung wäre ein zweiter und dritter Fehler, oder ein mittlerer Fehler und ein zweiter Festplattenfehler. Der Controller wäre nicht in der Lage, die Daten wiederherzustellen, die für die Wiederherstellung der LBAs auf den Festplatten mit den Fehlern erforderlich sind.
Zugehörige Informationen
 Feedback
Feedback