CPAR: Graceful Shutdown und Neustart für Computing-Knoten
Download-Optionen
-
ePub (645.6 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einführung
Dieses Dokument beschreibt die Vorgehensweise zum ordnungsgemäßen Herunterfahren und Neustarten des Computing-Knotens.
Dieses Verfahren gilt für eine OpenStack-Umgebung mit NEWTON-Version, in der Cisco Prime Access Registrar (CPAR) von ESC nicht verwaltet wird und CPAR direkt auf dem auf OpenStack bereitgestellten virtuellen System installiert ist. CPAR wird als Computing/VM installiert.
Hintergrundinformationen
Ultra-M ist eine vorkonfigurierte und validierte Kernlösung für virtualisierte mobile Pakete, die die Bereitstellung von VNFs vereinfacht. OpenStack ist der Virtualized Infrastructure Manager (VIM) für Ultra-M und besteht aus den folgenden Knotentypen:
- Computing
- Object Storage Disk - Computing (OSD - Computing)
- Controller
- OpenStack-Plattform - Director (OSPD)
Die High-Level-Architektur von Ultra-M und die beteiligten Komponenten sind in diesem Bild dargestellt:
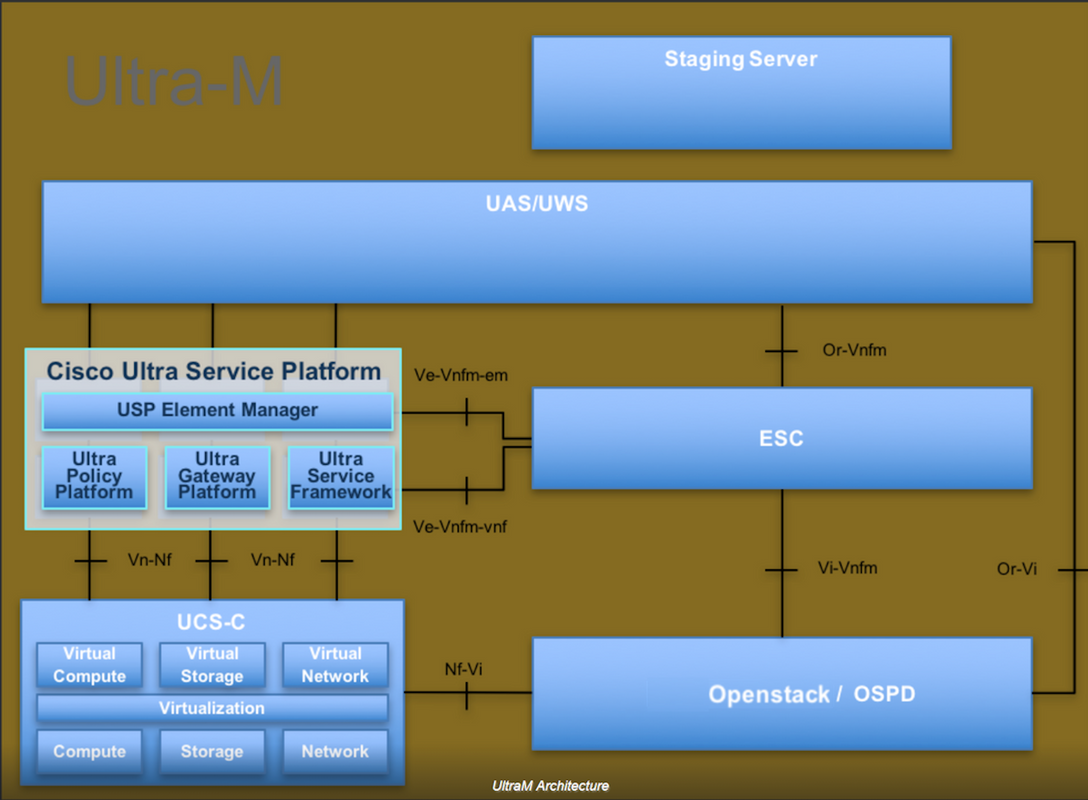
Dieses Dokument richtet sich an Mitarbeiter von Cisco, die mit der Cisco Ultra-M-Plattform vertraut sind. Es beschreibt die Schritte, die für OpenStack und Redhat OS erforderlich sind.
Hinweis: Ultra M 5.1.x wird zur Definition der Verfahren in diesem Dokument berücksichtigt.
Herunterfahren der CPAR-Instanz
Es ist wichtig, nicht alle vier AAA-Instanzen innerhalb eines Standorts (Stadt) gleichzeitig herunterzufahren. Jede AAA-Instanz muss einzeln heruntergefahren werden.
Schritt 1: Herunterfahren der CPAR-Anwendung mit diesem Befehl:
/opt/CSCOar/bin/arserver stop
Eine Meldung mit der Angabe "Herunterfahren des Cisco Prime Access Registrar Server Agent abgeschlossen". Sollte erscheinen
Hinweis: Wenn ein Benutzer eine CLI-Sitzung geöffnet hat, funktioniert der Befehl arserver stop nicht, und die folgende Meldung wird angezeigt:
"FEHLER: Cisco Prime Access Registrar kann nicht während der
CLI wird verwendet. Aktuelle Liste der ausgeführten Elemente
CLI mit Prozess-ID: 2903 /opt/CSCOar/bin/aregcmd -s"
In diesem Beispiel muss die Prozess-ID 2903 beendet werden, bevor CPAR beendet werden kann. Falls dies der Fall ist, beenden Sie diesen Prozess mithilfe des folgenden Befehls:
kill -9 *process_id*
Wiederholen Sie anschließend Schritt 1.
Schritt 2: Stellen Sie sicher, dass die CPAR-Anwendung mit dem folgenden Befehl tatsächlich heruntergefahren wird:
/opt/CSCOar/bin/arstatus
Diese Meldungen sollten angezeigt werden:
Cisco Prime Access Registrar Server Agent wird nicht ausgeführt
Cisco Prime Access Registrar GUI wird nicht ausgeführt
Schritt 3: Geben Sie die Horizon GUI-Website ein, die der aktuell bearbeiteten Website (Stadt) entspricht. Weitere Informationen finden Sie in den IP-Details. Geben Sie bitte mit Autorisierungsdaten für die benutzerdefinierte Ansicht ein:
Schritt 4: Navigieren Sie zu Projekt > Instanzen, wie im Bild gezeigt.

Wenn der Benutzer cpar verwendet hat, werden in diesem Menü nur die 4 AAA-Instanzen angezeigt.
Schritt 5: Fahren Sie jeweils nur eine Instanz herunter. Wiederholen Sie den gesamten Vorgang in diesem Dokument.
Navigieren Sie zum Herunterfahren der VM zu Aktionen > Instanz abschalten:

und bestätigen Sie Ihre Auswahl.
Schritt 6: Überprüfen Sie, ob die Instanz durch eine Markierung im Status = Shutoff and Power State = Shut Down (Status = Abschaltung und Betriebszustand = Herunterfahren) tatsächlich heruntergefahren wurde.

Mit diesem Schritt wird der CPAR-Abschaltvorgang beendet.
Neustarten von CPAR-Anwendungen und Statusprüfung
CPAR-Instanzstart
Bitte befolgen Sie dieses Verfahren, sobald die RMA-Aktivität abgeschlossen ist und die CPAR-Services auf der heruntergefahrenen Website wiederhergestellt werden können.
Schritt 1: Melden Sie sich wieder bei Horizon an, navigieren Sie zu Projekt > Instanz > Instanz starten.
Schritt 2: Stellen Sie sicher, dass der Status der Instanz aktiv ist und der Betriebsstatus "Ausführen" lautet, wie im Bild gezeigt.

Statusprüfung nach dem Start der CPAR-Instanz
Schritt 1: Anmeldung über Secure Shell (SSH) bei der CPAR-Instanz.
Führen Sie den Befehl /opt/CSCOar/bin/arstatus auf Betriebssystemebene aus.
[root@wscaaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 4834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Schritt 2: Führen Sie den Befehl /opt/CSCOar/bin/aregcmd auf Betriebssystemebene aus, und geben Sie die Administratorberechtigungen ein. Stellen Sie sicher, dass CPAR Health 10 von 10 und die CPAR-CLI verlassen.
[root@rvraaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is running, its health is 10 out of 10 --> exit
Schritt 3: Führen Sie den Befehl netstat aus. | grep-Durchmesser und überprüfen, ob alle DRA-Verbindungen hergestellt sind.
Die hier erwähnte Ausgabe ist für eine Umgebung vorgesehen, in der Durchmesser-Links erwartet werden. Wenn weniger Links angezeigt werden, stellt dies eine Trennung von DRA dar, die analysiert werden muss.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Schritt 4: Überprüfen Sie, ob das TPS-Protokoll Anforderungen anzeigt, die von CPAR verarbeitet werden. Die hervorgehobenen Werte repräsentieren die TPS und die Werte, die Ihre Aufmerksamkeit erfordern. Der TPS-Wert darf 1500 nicht überschreiten.
[root@aaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Schritt 5 Suchen Sie nach "error"- oder "alarm"-Meldungen in name_radius_1_log.
[root@aaa02 logs]# grep -E "error|alarm name_radius_1_log
Beiträge von Cisco Ingenieuren
- Karthikeyan DachanamoorthyCisco Advanced Services
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)