إجراءات النسخ الاحتياطي والاستعادة لمختلف مكونات Ultra-M - CPS
خيارات التنزيل
-
ePub (343.3 KB)
العرض في تطبيقات مختلفة على iPhone أو iPad أو نظام تشغيل Android أو قارئ Sony أو نظام التشغيل Windows Phone
لغة خالية من التحيز
تسعى مجموعة الوثائق لهذا المنتج جاهدة لاستخدام لغة خالية من التحيز. لأغراض مجموعة الوثائق هذه، يتم تعريف "خالية من التحيز" على أنها لغة لا تعني التمييز على أساس العمر، والإعاقة، والجنس، والهوية العرقية، والهوية الإثنية، والتوجه الجنسي، والحالة الاجتماعية والاقتصادية، والتمييز متعدد الجوانب. قد تكون الاستثناءات موجودة في الوثائق بسبب اللغة التي يتم تشفيرها بشكل ثابت في واجهات المستخدم الخاصة ببرنامج المنتج، أو اللغة المستخدمة بناءً على وثائق RFP، أو اللغة التي يستخدمها منتج الجهة الخارجية المُشار إليه. تعرّف على المزيد حول كيفية استخدام Cisco للغة الشاملة.
حول هذه الترجمة
ترجمت Cisco هذا المستند باستخدام مجموعة من التقنيات الآلية والبشرية لتقديم محتوى دعم للمستخدمين في جميع أنحاء العالم بلغتهم الخاصة. يُرجى ملاحظة أن أفضل ترجمة آلية لن تكون دقيقة كما هو الحال مع الترجمة الاحترافية التي يقدمها مترجم محترف. تخلي Cisco Systems مسئوليتها عن دقة هذه الترجمات وتُوصي بالرجوع دائمًا إلى المستند الإنجليزي الأصلي (الرابط متوفر).
المقدمة
يصف هذا المستند الخطوات المطلوبة لإجراء نسخ إحتياطي لجهاز ظاهري واستعادته في إعداد Ultra-M يستضيف دوال الشبكة الظاهرية CPS.
معلومات أساسية
Ultra-M هو حل أساسي لحزم الأجهزة المحمولة تم تجميعه مسبقا والتحقق من صحته وافتراضي، وهو مصمم لتبسيط عملية نشر وظائف الشبكات الظاهرية (VNF). يتكون حل Ultra-M من أنواع الأجهزة الافتراضية (VM) التالية:
- وحدة التحكم المرنة في الخدمات (ESC)
- مجموعة سياسات Cisco (CPS)
كما هو موضح في هذه الصورة، البنية عالية المستوى للطراز Ultra-M والمكونات المعنية.
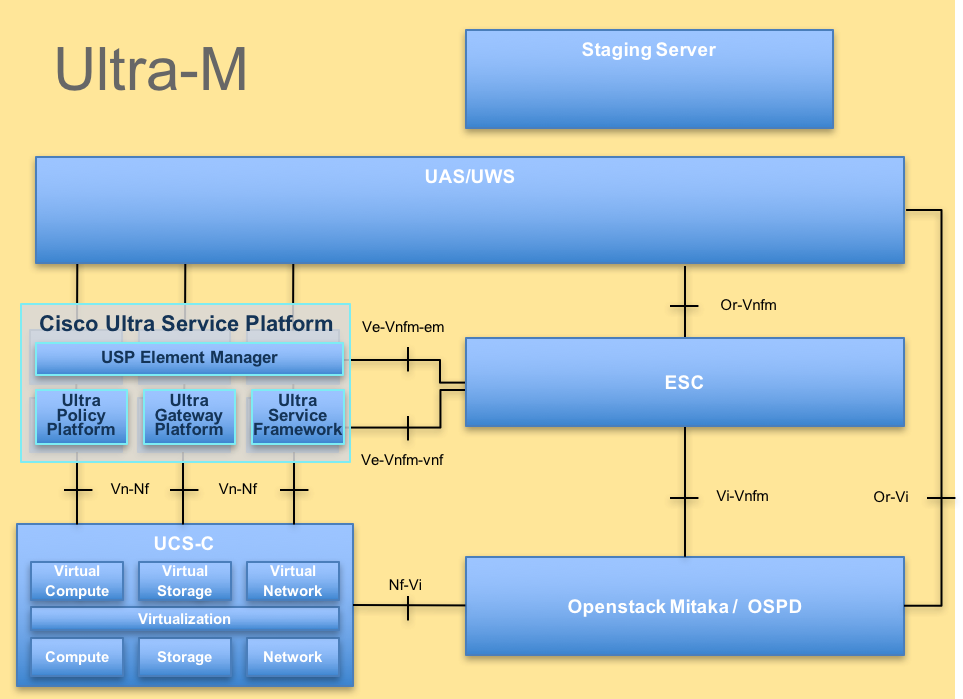

ملاحظة: يتم النظر في الإصدار Ultra M 5.1.x لتحديد الإجراءات الواردة في هذا المستند. هذا المستند مخصص لموظفي Cisco الذين لديهم دراية بنظام Cisco Ultra-M الأساسي.
الاختصارات
| VNF | وظيفة الشبكة الافتراضية |
| ESC | وحدة التحكم المرنة في الخدمة |
| MOP | طريقة الإجراء |
| OSD | أقراص تخزين الكائنات |
| HDD | محرك الأقراص الثابتة |
| SSD | محرك الأقراص ذو الحالة الصلبة |
| VIM | Virtual Infrastructure Manager |
| VM | الجهاز الافتراضي |
| UUID | المُعرّف الفريد عالميًا |
إجراء النسخ الاحتياطي
نسخ OSPD الاحتياطي
1. تحقق من حالة مكدس OpenStack وقائمة العقد.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
2. تحقق مما إذا كانت جميع خدمات الشبكة الفرعية في حالة تحميل ونشاط وتشغيل من عقدة OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, for example, generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
3. تأكد من توفر مساحة كافية على القرص قبل إجراء عملية النسخ الاحتياطي. ومن المتوقع أن تبلغ سعة ملف tarball هذا 3.5 جيجابايت على الأقل.
[stack@director ~]$df -h
4. قم بتنفيذ هذه الأوامر كمستخدم جذري لإجراء نسخ إحتياطي للبيانات من العقدة التي تعمل تحت السحابة إلى ملف باسم under cloud-backup-[timestamp].tar.gz ونقلها إلى خادم النسخ الاحتياطي.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
نسخ ESC الاحتياطي
1. تقوم ESC، بدورها، باستحداث وظيفة الشبكة الظاهرية (VNF) من خلال التفاعل مع VIM.
2. يحتوي ESC على معدل تكرار يبلغ 1:1 في حل Ultra-M. يتم نشر جهازي ESC VM ويدعمان عطلا واحدا في Ultra-M. على سبيل المثال، قم باسترداد النظام في حالة حدوث عطل واحد في النظام.
ملاحظة: إذا كان هناك أكثر من فشل واحد، فهو غير مدعوم ويمكن أن يتطلب إعادة توزيع النظام.
تفاصيل النسخ الاحتياطي لـ ESC:
- التكوين الجاري تشغيله
- ConfD CDB DB
- سجلات ESC
- تكوين Syslog
3. معدل تكرار النسخ الاحتياطي باستخدام تقنية ESC DB صعب للغاية ويجب التعامل معه بعناية أثناء قيام مركز الأنظمة الإلكترونية بمراقبة مختلف آلات النسخ الاحتياطي التي تعمل بتقنية VNF ونشرها والاحتفاظ بها. ينصح بإجراء هذه النسخ الاحتياطية بعد القيام بهذه الأنشطة في VNF/POD/Site معين.
4. تأكد من سلامة ESC بشكل جيد باستخدام البرنامج النصي health.sh.
[root@auto-test-vnfm1-esc-0 admin]# escadm status
0 ESC status=0 ESC Primary Healthy
[root@auto-test-vnfm1-esc-0 admin]# health.sh
esc ui is disabled -- skipping status check
esc_monitor start/running, process 836
esc_mona is up and running ...
vimmanager start/running, process 2741
vimmanager start/running, process 2741
esc_confd is started
tomcat6 (pid 2907) is running... [ OK ]
postgresql-9.4 (pid 2660) is running...
ESC service is running...
Active VIM = OPENSTACK
ESC Operation Mode=OPERATION
/opt/cisco/esc/esc_database is a mountpoint
============== ESC HA (Primary) with DRBD =================
DRBD_ROLE_CHECK=0
MNT_ESC_DATABSE_CHECK=0
VIMMANAGER_RET=0
ESC_CHECK=0
STORAGE_CHECK=0
ESC_SERVICE_RET=0
MONA_RET=0
ESC_MONITOR_RET=0
=======================================
ESC HEALTH PASSED
5. قم بإجراء النسخ الاحتياطي للتكوين الجاري تشغيله ونقل الملف إلى خادم النسخ الاحتياطي.
[root@auto-test-vnfm1-esc-0 admin]# /opt/cisco/esc/confd/bin/confd_cli -u admin -C
admin connected from 127.0.0.1 using console on auto-test-vnfm1-esc-0.novalocal
auto-test-vnfm1-esc-0# show running-config | save /tmp/running-esc-12202017.cfg
auto-test-vnfm1-esc-0#exit
[root@auto-test-vnfm1-esc-0 admin]# ll /tmp/running-esc-12202017.cfg
-rw-------. 1 tomcat tomcat 25569 Dec 20 21:37 /tmp/running-esc-12202017.cfg
النسخ الاحتياطي لقاعدة بيانات ESC
1. سجل الدخول إلى ESC VM وقم بتنفيذ هذا الأمر قبل إجراء النسخ الاحتياطي.
[admin@esc ~]# sudo bash
[root@esc ~]# cp /opt/cisco/esc/esc-scripts/esc_dbtool.py /opt/cisco/esc/esc-scripts/esc_dbtool.py.bkup
[root@esc esc-scripts]# sudo sed -i "s,'pg_dump,'/usr/pgsql-9.4/bin/pg_dump," /opt/cisco/esc/esc-scripts/esc_dbtool.py
#Set ESC to mainenance mode
[root@esc esc-scripts]# escadm op_mode set --mode=maintenance
2. تحقق من وضع ESC وتأكد من أنه في وضع الصيانة.
[root@esc esc-scripts]# escadm op_mode show
3. النسخ الاحتياطي لقاعدة البيانات باستخدام أداة إستعادة النسخ الاحتياطي لقاعدة البيانات المتوفرة في ESC.
[root@esc scripts]# sudo /opt/cisco/esc/esc-scripts/esc_dbtool.py backup --file scp://<username>:<password>@<backup_vm_ip>:<filename>
4. قم بتعيين ESC مرة أخرى إلى وضع التشغيل وتأكيد الوضع.
[root@esc scripts]# escadm op_mode set --mode=operation
[root@esc scripts]# escadm op_mode show
5. انتقل إلى دليل البرامج النصية وتجميع السجلات.
[root@esc scripts]# /opt/cisco/esc/esc-scripts
sudo ./collect_esc_log.sh
6. لإنشاء لقطة ل ESC، قم بإيقاف تشغيل ESC أولا.
shutdown -r now
7. من OSPD، قم بإنشاء لقطة صورة.
nova image-create --poll esc1 esc_snapshot_27aug2018
8. تأكد من إنشاء اللقطة.
openstack image list | grep esc_snapshot_27aug2018
9. بدء تشغيل ESC من OSPD.
nova start esc1
10. كرر نفس الإجراء على ESC VM في وضع الاستعداد ونقل السجلات إلى خادم النسخ الاحتياطي.
11. قم بتجميع النسخ الاحتياطي لتكوين syslog على كل من ESC VMS ونقلها إلى خادم النسخ الاحتياطي.
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
النسخ الاحتياطي ل CPS
الخطوة 1. إنشاء نسخة إحتياطية من برنامج Cluster-Manager لإدارة قطاعات CPS.
أستخدم هذا الأمر لعرض مثيلات Nova وملاحظة اسم مثيل VM الخاص بمدير نظام المجموعة:
nova list
أوقف الكلومان من ESC.
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP <vm-name>
الخطوة 2. تحقق من أن إدارة نظام المجموعة في حالة إيقاف التشغيل.
admin@esc1 ~]$ /opt/cisco/esc/confd/bin/confd_cli admin@esc1> show esc_datamodel opdata tenants tenant Core deployments * state_machine
الخطوة 3. قم بإنشاء صورة لقطة نوفا كما هو موضح في هذا الأمر:
nova image-create --poll <cluman-vm-name> <snapshot-name>
ملاحظة: تأكد من وجود مساحة كافية على القرص للقطة.
.هام - في حالة تعذر الوصول إلى VM بعد إنشاء لقطة، تحقق من حالة VM باستخدام أمر قائمة نوفا. إذا كان في حالة إيقاف التشغيل، فأنت بحاجة إلى بدء تشغيل الجهاز الظاهري يدويا.
الخطوة 4. عرض قائمة الصور باستخدام هذا الأمر: Nova image-list
الصورة 1: مثال المخرج

الخطوة 5. عند إنشاء لقطة، يتم تخزين صورة اللقطة في نظرة OpenStack. لتخزين اللقطة في مخزن بيانات بعيد، قم بتنزيل اللقطة ونقل الملف الموجود في OSPD إلى (/home/stack/CPS_BACKUP).
لتنزيل الصورة، أستخدم هذا الأمر في OpenStack:
glance image-download –-file For example: glance image-download –-file snapshot.raw 2bbfb51c-cd05-4b7c-ad77-8362d76578db
الخطوة 6. سرد الصور التي تم تنزيلها كما هو موضح في هذا الأمر:
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
الخطوة 7. قم بتخزين لقطة برنامج إدارة نظام المجموعة VM لاستعادتها في المستقبل.
2. النسخ الاحتياطي للتكوين وقاعدة البيانات.
1. config_br.py -a export --all /var/tmp/backup/ATP1_backup_all_$(date +\%Y-\%m-\%d).tar.gz OR 2. config_br.py -a export --mongo-all /var/tmp/backup/ATP1_backup_mongoall$(date +\%Y-\%m-\%d).tar.gz 3. config_br.py -a export --svn --etc --grafanadb --auth-htpasswd --haproxy /var/tmp/backup/ATP1_backup_svn_etc_grafanadb_haproxy_$(date +\%Y-\%m-\%d).tar.gz 4. mongodump - /var/qps/bin/support/env/env_export.sh --mongo /var/tmp/env_export_$date.tgz 5. patches - cat /etc/broadhop/repositories, check which patches are installed and copy those patches to the backup directory /home/stack/CPS_BACKUP on OSPD 6. backup the cronjobs by taking backup of the cron directory: /var/spool/cron/ from the Pcrfclient01/Cluman. Then move the file to CPS_BACKUP on the OSPD.
تحقق من crontab-l إذا كانت هناك حاجة إلى أي نسخ إحتياطي آخر.
قم بنقل جميع عمليات النسخ الاحتياطي إلى OSPD /home/stack/CPS_Backup.
3. نسخ إحتياطي لملف من ESC أساسي.
/opt/cisco/esc/confd/bin/netconf-console --host 127.0.0.1 --port 830 -u <admin-user> -p <admin-password> --get-config > /home/admin/ESC_config.xml
نقل الملف في OSPD /home/stack/CPS_Backup.
4. نسخ إدخالات crontab -l إحتياطيا.
إنشاء ملف txt باستخدام crontab -l وإفلاته إلى موقع بعيد (في OSPD /home/stack/cps_backup).
5. قم بإجراء عملية نسخ إحتياطي لملفات المسار من عميل LB و PCRF.
Collect and scp the configurations from both LBs and Pcrfclients route -n /etc/sysconfig/network-script/route-*
إجراء الاسترداد
استرداد OSPD
يتم تنفيذ إجراء استرداد OSPD بناءً على هذه الافتراضات.
1. يتوفر النسخ الاحتياطي ل OSPD من خادم OSPD القديم.
2. يمكن إجراء إسترداد OSPD على الخادم الجديد الذي هو إستبدال خادم OSPD القديم في النظام. .
استرداد ESC
1. يكون ESC VM قابلا للاسترداد إذا كان VM في حالة خطأ أو في حالة إيقاف التشغيل فعليك إجراء إعادة تمهيد ثابت لإظهار VM المتأثر. نفّذ هذه الخطوات لاسترداد ESC.
2. حدد الجهاز الظاهري (VM) الذي يكون في حالة الخطأ أو حالة إيقاف التشغيل، بمجرد التعرف على إعادة تمهيد ESC VM بشكل ثابت. في هذا المثال، تقوم بإعادة تمهيد الاختبار التلقائي-vnfm1-ESC-0.
[root@tb1-baremetal scripts]# nova list | grep auto-test-vnfm1-ESC-
| f03e3cac-a78a-439f-952b-045aea5b0d2c | auto-test-vnfm1-ESC-0 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.11; auto-testautovnf1-uas-management=172.31.11.3 |
| 79498e0d-0569-4854-a902-012276740bce | auto-test-vnfm1-ESC-1 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.15; auto-testautovnf1-uas-management=172.31.11.15 |
[root@tb1-baremetal scripts]# [root@tb1-baremetal scripts]# nova reboot --hard f03e3cac-a78a-439f-952b-045aea5b0d2c\
Request to reboot server <Server: auto-test-vnfm1-ESC-0> has been accepted.
[root@tb1-baremetal scripts]#
3. إذا تم حذف ESC VM ويلزم إظهاره مرة أخرى. أستخدم تسلسل الخطوات هذا.
[stack@pod1-ospd scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.16.11.14; vnf1-UAS-uas-management=172.16.10.4 |
[stack@pod1-ospd scripts]$ nova delete vnf1-ESC-ESC-1
Request to delete server vnf1-ESC-ESC-1 has been accepted.
4. إذا كان ESC VM غير قابل للاسترداد ويتطلب إستعادة قاعدة البيانات، فقم باستعادة قاعدة البيانات من النسخة الاحتياطية التي تم الحصول عليها مسبقا.
5. لاستعادة قاعدة بيانات ESC، يجب التأكد من إيقاف خدمة ESC قبل إستعادة قاعدة البيانات، وبالنسبة ل ESC HA، قم بالتنفيذ في الجهاز الظاهري الثانوي أولا، ثم الجهاز الظاهري الرئيسي.
# service keepalived stop
6. تحقق من حالة خدمة ESC وتأكد من إيقاف كل شيء في الأجهزة الافتراضية الأساسية والثانوية للحصول على HA.
# escadm status
7. قم بتنفيذ البرنامج النصي لاستعادة قاعدة البيانات. كجزء من إستعادة قاعدة البيانات إلى مثيل ESC الذي تم إنشاؤه حديثا، يمكن للأداة أيضا ترقية أحد المثيلات ليكون ESC أساسي، وتحميل مجلد DB الخاص بها إلى الجهاز DRBD، كما يمكنها بدء تشغيل قاعدة بيانات PostGreSQL.
# /opt/cisco/esc/esc-scripts/esc_dbtool.py restore --file scp://<username>:<password>@<backup_vm_ip>:<filename>
8. قم بإعادة تشغيل خدمة ESC لإكمال إستعادة قاعدة البيانات. لتنفيذ التوافر العالي (HA) في الجهازَين الافتراضيين، أعِد تشغيل خدمة الاحتفاظ برسائل تنشيط الاتصال.
# service keepalived start
9. بمجرد إستعادة VM وتشغيله بنجاح؛ تأكد من إستعادة جميع التكوين المحدد syslog من النسخ الاحتياطي السابق المعروف. تأكد من استعادته في جميع أجهزة ESC VMs.
[admin@auto-test-vnfm2-esc-1 ~]$
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
10. إذا كان يلزم إعادة إنشاء ESC من لقطة OSPD، فاستخدم هذا الأمر مع إستخدام اللقطة التي تم التقاطها أثناء النسخ الاحتياطي.
nova rebuild --poll --name esc_snapshot_27aug2018 esc1
11. تحقق من حالة ESC بعد اكتمال عملية إعادة الإنشاء.
nova list --fileds name,host,status,networks | grep esc
12. تحقق من صحة ESC باستخدام هذا الأمر.
health.sh
Copy Datamodel to a backup file
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli get esc_datamodel/opdata > /tmp/esc_opdata_`date +%Y%m%d%H%M%S`.txt
عندما تفشل ESC في بدء تشغيل الجهاز الافتراضي
- في بعض الحالات، يمكن أن يفشل ESC في بدء تشغيل الجهاز الظاهري (VM) بسبب حالة غير متوقعة. الحل البديل هو تنفيذ محول ESC من خلال إعادة تشغيل ESC الأساسي. يمكن أن يستغرق تبديل ESC حوالي دقيقة. قم بتنفيذ health.sh على ESC الأساسي الجديد للتحقق من تشغيله. عندما يصبح ESC أساسيا، يمكن ل ESC إصلاح حالة VM وبدء تشغيل VM. نظرًا لأن هذه العملية مجدولة، يجب أن تنتظر من 5 إلى 7 دقائق حتى تكتمل.
- يمكنك مراقبة /var/log/esc/yangesc.log و/var/log/esc/escmanager.log. إذا لم يظهر لك الجهاز الظاهري الذي تم إسترداده بعد 5 إلى 7 دقائق، فسيحتاج المستخدم إلى الذهاب وإجراء عملية الاسترداد اليدوي للأجهزة الافتراضية (الأجهزة الافتراضية) المتأثرة.
- بمجرد إستعادة VM وتشغيله بنجاح، تأكد من إستعادة جميع التكوين المحدد syslog من النسخ الاحتياطي السابق المعروف. تأكد من استعادته في جميع الأجهزة الافتراضية (ESC)
root@abautotestvnfm1em-0:/etc/rsyslog.d# pwd
/etc/rsyslog.d
root@abautotestvnfm1em-0:/etc/rsyslog.d# ll
total 28
drwxr-xr-x 2 root root 4096 Jun 7 18:38 ./
drwxr-xr-x 86 root root 4096 Jun 6 20:33 ../]
-rw-r--r-- 1 root root 319 Jun 7 18:36 00-vnmf-proxy.conf
-rw-r--r-- 1 root root 317 Jun 7 18:38 01-ncs-java.conf
-rw-r--r-- 1 root root 311 Mar 17 2012 20-ufw.conf
-rw-r--r-- 1 root root 252 Nov 23 2015 21-cloudinit.conf
-rw-r--r-- 1 root root 1655 Apr 18 2013 50-default.conf
root@abautotestvnfm1em-0:/etc/rsyslog.d# ls /etc/rsyslog.conf
rsyslog.conf
إسترداد CPS
برنامج Restore Cluster Manager VM في OpenStack.
الخطوة 1. انسخ لقطة برنامج VM الخاص بإدارة المجموعة إلى الخادم النصلي لوحدة التحكم كما هو موضح في هذا الأمر:
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
الخطوة 2. تحميل صورة اللقطة إلى OpenStack من Datastore:
glance image-create --name --file --disk-format qcow2 --container-format bare
الخطوة 3. تحقق ما إذا كان قد تم تحميل اللقطة باستخدام أمر Nova كما هو موضح في هذا المثال:
nova image-list
الصورة 2: مثال المخرج

الخطوة 4. بناء على ما إذا كان مدير نظام المجموعة VM موجودا أم لا، يمكنك إختيار إنشاء مستنسخ أو إعادة إنشاء مستنسخ:
· إذا لم يكن مثيل نظام المجموعة Cluster Manager VM موجودا، فقم بإنشاء نظام المجموعة الافتراضية (VM) باستخدام أمر Heat أو Nova كما هو موضح في هذا المثال:
قم بإنشاء VM المستنسخ باستخدام ESC.
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli edit-config /opt/cisco/esc/cisco-cps/config/gr/tmo/gen/<original_xml_filename>
يمكن إنشاء مجموعة PCRF بمساعدة الأمر السابق، ثم إستعادة تكوينات مدير نظام المجموعة من عمليات النسخ الاحتياطي التي تم إجراؤها باستخدام عملية الاستعادة config_br.py، Mongorestore من عملية التفريغ التي تم إجراؤها أثناء النسخ الاحتياطي.
delete - nova boot --config-drive true --image "" --flavor "" --nic net-id=",v4-fixed-ip=" --nic net-id="network_id,v4-fixed-ip=ip_address" --block-device-mapping "/dev/vdb=2edbac5e-55de-4d4c-a427-ab24ebe66181:::0" --availability-zone "az-2:megh-os2-compute2.cisco.com" --security-groups cps_secgrp "cluman"
· في حالة وجود مثيل Cluster Manager VM، أستخدم الأمر Nova Rebuild لإعادة إنشاء مثيل Cluman VM باستخدام اللقطة التي تم تحميلها كما هو موضح:
nova rebuild <instance_name> <snapshot_image_name>
على سبيل المثال:
nova rebuild cps-cluman-5f3tujqvbi67 cluman_snapshot
الخطوة 5. قم بسرد كافة المثيلات كما هو موضح، وتحقق من إنشاء مثيل مدير نظام المجموعة الجديد وتشغيله:
nova list
الصورة 3. مثال الإخراج

قم باستعادة أحدث برامج التصحيح الموجودة على النظام.
1. Copy the patch files to cluster manager which were backed up in OSPD /home/stack/CPS_BACKUP 2. Login to the Cluster Manager as a root user. 3. Untar the patch by executing this command: tar -xvzf [patch name].tar.gz 4. Edit /etc/broadhop/repositories and add this entry: file:///$path_to_the plugin/[component name] 5. Run build_all.sh script to create updated QPS packages: /var/qps/install/current/scripts/build_all.sh 6. Shutdown all software components on the target VMs: runonall.sh sudo monit stop all 7. Make sure all software components are shutdown on target VMs: statusall.sh
ملاحظة: يجب أن تعرض جميع مكونات البرامج غير خاضعة للمراقبة كالحالة الحالية.
8. Update the qns VMs with the new software using reinit.sh script: /var/qps/install/current/scripts/upgrade/reinit.sh 9. Restart all software components on the target VMs: runonall.sh sudo monit start all 10. Verify that the component is updated, run: about.sh
قم باستعادة Cronjobs.
1. انقل الملف الذي تم نسخه إحتياطيا من OSPD إلى Cluman/PCRFCLIENT01.
2. قم بتشغيل الأمر لتنشيط cronjob من backup.
#crontab Cron-backup
3. تحقق مما إذا كان قد تم تنشيط وظائف cronjobs بواسطة هذا الأمر.
#crontab -l
إستعادة الأجهزة الافتراضية الفردية في نظام المجموعة.
لإعادة نشر PCRFCLIENT01 VM:
الخطوة 1. قم بتسجيل الدخول إلى VM الخاص بإدارة نظام المجموعة كمستخدم جذري.
الخطوة 2. تذكر UID الخاص بمستودع SVN باستخدام هذا الأمر:
svn info http://pcrfclient02/repos | grep UUID
يمكن أن يقوم الأمر بإخراج معرف المستخدم الخاص بالمستودع.
على سبيل المثال: UUID الخاص بالمستودع: ea50bbd2-5726-46b8-b807-10f4a7424f0e
الخطوة 3. قم باستيراد بيانات تكوين Backup Policy Builder على "إدارة نظام المجموعة"، كما هو موضح في هذا المثال:
config_br.py -a import --etc-oam --svn --stats --grafanadb --auth-htpasswd --users /mnt/backup/oam_backup_27102016.tar.gz
ملاحظة: تقوم العديد من عمليات النشر بتشغيل وظيفة cron التي تدعم بيانات التكوين بشكل منتظم. راجع النسخ الاحتياطي للمستودع الفرعي للحصول على مزيد من التفاصيل.
الخطوة 4. لإنشاء ملفات أرشيف VM على "إدارة المجموعة" باستخدام أحدث التكوينات، قم بتنفيذ هذا الأمر:
/var/qps/install/current/scripts/build/build_svn.sh
الخطوة 5. لنشر برنامج VM pcrfclient01، قم بتنفيذ واحد مما يلي:
في OpenStack، أستخدم قالب الحرارة أو الأمر Nova لإعادة إنشاء الجهاز الظاهري. لمزيد من المعلومات، راجع دليل تثبيت CPS ل OpenStack.
الخطوة 6. قم بإعادة إنشاء مزامنة SVN الأساسية/الثانوية بين pcrfClient01 و pcrfclient02 مع pcrfclient01 كإجراء أساسي من خلال تنفيذ سلسلة الأوامر هذه.
إذا كان SVN متزامن بالفعل، فلا تقم بإصدار هذه الأوامر.
للتحقق من مزامنة SVN، قم بتشغيل هذا الأمر من pcrfclient02.
إذا تم إرجاع قيمة، فإن SVN يكون متزامنا بالفعل:
/usr/bin/svn propget svn:sync-from-url --revprop -r0 http://pcrfclient01/repos
تنفيذ هذه الأوامر من pcrfclient01:
/bin/rm -fr /var/www/svn/repos /usr/bin/svnadmin create /var/www/svn/repos /usr/bin/svn propset --revprop -r0 svn:sync-last-merged-rev 0 http://pcrfclient02/repos-proxy-sync /usr/bin/svnadmin setuuid /var/www/svn/repos/ "Enter the UUID captured in step 2" /etc/init.d/vm-init-client / var/qps/bin/support/recover_svn_sync.sh
الخطوة 7. إذا كانت PCRFclient01 أيضا هو جهاز التحكم VM، فعليك بتنفيذ الخطوات التالية:
أ) إنشاء البرامج النصية أحادية الإتجاه للبداية/الإيقاف استنادا إلى تكوين النظام. ليست جميع عمليات النشر قد تم تكوين جميع قواعد البيانات هذه.
ملاحظة: ارجع إلى /etc/broadhop/mongoConfig.cfg لتحديد قواعد البيانات التي يجب إعدادها.
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
ب) بدء عملية التحول:
/usr/bin/systemctl start sessionmgr-XXXXX
ج) انتظر حتى يبدأ المحكم، ثم قم بتشغيل diagnostic.sh — get_replica_status للتحقق من صحة مجموعة النسخ المتماثلة.
لإعادة نشر PCRFCLIENT02 VM:
الخطوة 1. قم بتسجيل الدخول إلى VM الخاص بإدارة نظام المجموعة كمستخدم جذري.
الخطوة 2. لإنشاء ملفات أرشيف VM على "إدارة المجموعة" باستخدام أحدث التكوينات، قم بتنفيذ هذا الأمر:
/var/qps/install/current/scripts/build/build_svn.sh
الخطوة 3. لنشر جهاز VM pcrfclient02، قم بتنفيذ واحد مما يلي:
في OpenStack، أستخدم قالب الحرارة أو الأمر Nova لإعادة إنشاء الجهاز الظاهري. لمزيد من المعلومات، راجع دليل تثبيت CPS ل OpenStack.
الخطوة 4. طبقة الأمان إلى pcrfclient01:
ssh pcrfclient01
الخطوة 5. قم بتشغيل هذا البرنامج النصي لاستعادة رسائل SVN من pcrfclient01:
/var/qps/bin/support/recover_svn_sync.sh
لإعادة نشر معرف فئة مورد (VM) جلسة عمل:
الخطوة 1. قم بتسجيل الدخول إلى VM الخاص بإدارة نظام المجموعة كمستخدم جذري.
الخطوة 2. لنشر VM الخاص بجلسة العمل واستبدال VM الفاشل أو الفاسد، قم بتنفيذ واحد مما يلي:
في OpenStack، أستخدم قالب الحرارة أو الأمر Nova لإعادة إنشاء الجهاز الظاهري. لمزيد من المعلومات، راجع دليل تثبيت CPS ل OpenStack.
الخطوة 3. قم بإنشاء البرامج النصية أحادية الإتجاه للبداية/الإيقاف استنادا إلى تكوين النظام.
ليست جميع عمليات النشر قد تم تكوين جميع قواعد البيانات هذه. ارجع إلى /etc/broadhop/mongoConfig.cfg لتحديد قواعد البيانات التي يجب إعدادها.
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
الخطوة 4. طبقة آمنة إلى SessionMgr VM وبدء عملية mongo:
ssh sessionmgrXX /usr/bin/systemctl start sessionmgr-XXXXX
الخطوة 5. انتظر حتى يبدأ الأعضاء ومزامنة الأعضاء الثانويين، ثم قم بتشغيل diagnostics.sh— get_replica_status للتحقق من صحة قاعدة البيانات.
الخطوة 6. لاستعادة قاعدة بيانات "مدير جلسة العمل"، أستخدم أحد أوامر الأمثلة التالية استنادا إلى ما إذا كان قد تم إجراء النسخ الاحتياطي باستخدام خيار —mongo-all أو— mongo:
• config_br.py -a import --mongo-all --users /mnt/backup/Name of backup or • config_br.py -a import --mongo --users /mnt/backup/Name of backup
لإعادة نشر مدير السياسة (موازن التحميل) VM:
الخطوة 1. قم بتسجيل الدخول إلى VM الخاص بإدارة نظام المجموعة كمستخدم جذري.
الخطوة 2. لاستيراد بيانات تكوين Backup Policy Builder على "إدارة نظام المجموعة"، قم بتنفيذ هذا الأمر:
config_br.py -a import --network --haproxy --users /mnt/backup/lb_backup_27102016.tar.gz
الخطوة 3. لإنشاء ملفات أرشيف VM على "إدارة المجموعة" باستخدام أحدث التكوينات، قم بتنفيذ هذا الأمر:
/var/qps/install/current/scripts/build/build_svn.sh
الخطوة 4. لنشر الطراز LB01 VM، قم بتنفيذ واحد مما يلي:
في OpenStack، أستخدم قالب الحرارة أو الأمر Nova لإعادة إنشاء الجهاز الظاهري. لمزيد من المعلومات، راجع دليل تثبيت CPS ل OpenStack.
لإعادة نشر VM الخاص بخادم النهج (QNS):
الخطوة 1. قم بتسجيل الدخول إلى VM الخاص بإدارة نظام المجموعة كمستخدم جذري.
الخطوة 2. قم باستيراد بيانات تكوين Backup Policy Builder على "إدارة نظام المجموعة"، كما هو موضح في هذا المثال:
config_br.py -a import --users /mnt/backup/qns_backup_27102016.tar.gz
الخطوة 3. لإنشاء ملفات أرشيف VM على "إدارة المجموعة" باستخدام أحدث التكوينات، قم بتنفيذ هذا الأمر:
/var/qps/install/current/scripts/build/build_svn.sh
الخطوة 4. لنشر QNS VM، قم بتنفيذ واحد مما يلي:
في OpenStack، أستخدم قالب الحرارة أو الأمر Nova لإعادة إنشاء الجهاز الظاهري. لمزيد من المعلومات، راجع دليل تثبيت CPS ل OpenStack.
الإجراء العام لاستعادة قاعدة البيانات.
الخطوة 1. تنفيذ هذا الأمر لاستعادة قاعدة البيانات:
config_br.py –a import --mongo-all /mnt/backup/backup_$date.tar.gz where $date is the timestamp when the export was made.
على سبيل المثال,
config_br.py –a import --mongo-all /mnt/backup/backup_27092016.tgz
الخطوة 2. قم بتسجيل الدخول إلى قاعدة البيانات والتحقق مما إذا كانت قيد التشغيل ويمكن الوصول إليها:
1. تسجيل الدخول إلى مدير الجلسة:
mongo --host sessionmgr01 --port $port
حيث $port هو رقم المنفذ لقاعدة البيانات التي سيتم فحصها. على سبيل المثال، 27718 هو منفذ التوازن الافتراضي.
2. عرض قاعدة البيانات من خلال تنفيذ هذا الأمر:
show dbs
3. تبديل shell mongo إلى قاعدة البيانات من خلال تنفيذ هذا الأمر:
use $db
حيث $db هو اسم قاعدة بيانات معروض في الأمر السابق.
يقوم الأمر use بتبديل shell mongo إلى قاعدة البيانات هذه.
على سبيل المثال,
use balance_mgmt
4. لعرض المجموعات، قم بتنفيذ هذا الأمر:
show collections
5. لعرض عدد السجلات في المجموعة، قم بتنفيذ هذا الأمر:
db.$collection.count() For example, db.account.count()
يمكن للمثال السابق عرض عدد السجلات الموجودة في حساب المجموعة في قاعدة بيانات الرصيد (balance_mgmt).
إستعادة مستودع النسخ الاحتياطية.
لاستعادة بيانات تكوين منشئ النهج من نسخة إحتياطية، قم بتنفيذ هذا الأمر:
config_br.py –a import --svn /mnt/backup/backup_$date.tgz where, $date is the date when the cron created the backup file.
إستعادة لوحة معلومات Grafana.
يمكنك إستعادة لوحة معلومات Grafana باستخدام هذا الأمر:
config_br.py -a import --grafanadb /mnt/backup/
التحقق من صحة الاستعادة.
بعد إستعادة البيانات، تحقق من نظام العمل من خلال تنفيذ هذا الأمر:
/var/qps/bin/diag/diagnostics.sh
محفوظات المراجعة
| المراجعة | تاريخ النشر | التعليقات |
|---|---|---|
2.0 |
20-Mar-2024 |
عنوان، مقدمة، نص بديل، ترجمة آلية، متطلبات نمط، وتنسيق محدث. |
1.0 |
21-Sep-2018 |
الإصدار الأولي |
تمت المساهمة بواسطة مهندسو Cisco
- Aaditya DeodharCisco Advanced Services
 التعليقات
التعليقاتاتصل بنا
- فتح حالة دعم

- (تتطلب عقد خدمة Cisco)